Performance Tuning Apache Storm at Keen IO
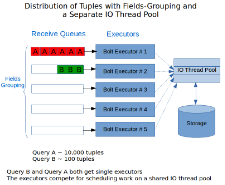
Hi, I'm Manu Mahajan and I'm a software engineer with Keen IO's Platform team. Over the past year I've focused on improving our query performance and scalability. I wanted to share some things we've learned from this experience in a series of posts.
Today, I'll describe how we're working to guarantee consistent performance in a multi-tenant environment built on top of Apache Storm.
tl;dr we were able to make query response times significantly more consistent and improve high percentile query-duration by 6x by making incremental changes that included isolating heterogenous workloads, making I/O operations asynchronous, and using Storm’s queueing more efficiently.
High Query Performance Variability
Keen IO is an analytics API that allows customers to track and send event data to us and then query it in interesting ways. We have thousands of customers with varying data volumes that can range from a handful of events a day to upwards of 500 million events per day. We also support different analysis types like counts, percentiles, select-uniques, funnels, and more, some of which are more expensive to compute than others. All of this leads to a spectrum of query response times ranging from a few milliseconds to a few minutes.
The Continue reading
Stuff The Internet Says On Scalability For February 19th, 2016

- 200K : msgs send per second through iMessage; 750 million : xactions per week in App and iTunes store; 11 million : Apple Music subscribers; .7c : speed of light in silicon; 1.125Tpbs : fastest ever data transmission; 360TB : Superman memory crystal stores data forever; $1bn : Uber’s yearly cost for market share in China;
- Quotable Quotes:
- Joseph Bradley : “Here is the takeaway. Blockchains must be massively more scalable than the current tech that supports Bitcoin. We start scaling slowly or quickly. And if we choose the latter, it will “require fundamental protocol redesign.”
- @sigfpe : Nobody knows how to “program” DNA. They just copy-and-paste bits from other organisms. A bit like how most code is built from stackoverflow.
- @evankirstel : Slack now has 2.3 million daily active users, 675,000 paid seats, and 280 apps in its directory
- Jonas Luster : Money spoiled blogging. Why? Because people moved from doing great things for money and then talking about them on their free blogs, to people doing nothing but talking Continue reading
Stuff The Internet Says On Scalability For March 4th, 2016

- 16 terabytes: new Samsung SSD; 1%: earned income from an on-demand platform; $35: PI 3 has 1.2GHz 64-bit quad-core ARM and WiFi; 1.5 million messages per second: Netflix cache replication;
- Quotable Quotes:
- @jzawodn: all right.. everything on one disk in one computer: 15TB SSD
- @jaykreps: The disadvantage is that the needs of most companies are really different from Google's. Depth vs breadth thing.
- Eliezer Sternberg: The brain tries to maximize the efficiency of our thinking by recognizing familiar patterns and anticipating them.
- david-given: I would love to have a modernised Ada. With case sensitivity. And garbage collection (a lot of the language semantics are obviously intended to be based around having a garbage collector.
- @tyler_treat: You're not even building microservices if you have things operating in lockstep and tightly coupled interactions and data models.
- cognitive electronic warfare: using artificial intelligence to learn in real-time what the adversaries’ radar is doing and then on-the-fly create a new jamming profile. That whole process of sensing, learning and adapting is Continue reading
Asyncio Tarantool Queue, get in the queue

In this article, I’m going to pay specific attention to information processing via Tarantool queues. My colleagues have recently published several articles in Russian on the benefits of queues (Queue processing infrastructure on My World social network and Push messages in REST API by the example of Target Mail.Ru system). Today I’d like to add some info on queues describing the way we solved our tasks and telling more about our work with Tarantool Queue in Python and asyncio.
The task of notifying the entire user base
Malice or Stupidity or Inattention? Using Code Reviews to Find Backdoors
 The temptation to put a backdoor into a product is almost overwhelming. It’s just so dang convenient. You can go into any office, any lab, any customer site and get your work done. No hassles with getting passwords or clearances. You can just solve problems. You can log into any machine and look at logs, probe the box, issue commands, and debug any problem. This is very attractive to programmers.
The temptation to put a backdoor into a product is almost overwhelming. It’s just so dang convenient. You can go into any office, any lab, any customer site and get your work done. No hassles with getting passwords or clearances. You can just solve problems. You can log into any machine and look at logs, probe the box, issue commands, and debug any problem. This is very attractive to programmers.
I’ve been involved in several command line interfaces to embedded products and though the temptation to put in a backdoor has been great, I never did it, but I understand those who have.
There’s another source of backdoors: infiltration by an attacker.
We’ve seen a number of backdoors hidden in code bases you would not expect. Juniper Networks found two backdoors in its firewalls. Here’s Some Analysis of the Backdoored Backdoor. Here’s more information to reaffirm your lack of faith in humanity: NSA Helped British Spies Find Security Holes In Juniper Firewalls. And here are a A Few Thoughts on Cryptographic Engineering.
Juniper is not alone. Here’s a backdoor in AMX AV equipment. A Secret SSH backdoor in Fortinet hardware found in more products. There were Backdoors Found in Barracuda Continue reading
Sponsored Post: zanox Group, Varnish, LaunchDarkly, Swrve, Netflix, Aerospike, TrueSight Pulse, Redis Labs, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7

Who's Hiring?
- The zanox Group are looking for a Senior Architect. We're looking for someone smart and pragmatic to help our engineering teams build fast, scalable and reliable solutions for our industry leading affiliate marketing platform. The role will involve a healthy mixture of strategic thinking and hands-on work - there are no ivory towers here! Our stack is diverse and interesting. You can apply for the role in either London or Berlin.
- Swrve -- In November we closed a $30m funding round, and we’re now expanding our engineering team based in Dublin (Ireland). Our mobile marketing platform is powered by 8bn+ events a day, processed in real time. We’re hiring intermediate and senior backend software developers to join the existing team of thirty engineers. Sound like fun? Come join us.
- Senior Service Reliability Engineer (SRE): Drive improvements to help reduce both time-to-detect and time-to-resolve while concurrently improving availability through service team engagement. Ability to analyze and triage production issues on a web-scale system a plus. Find details on the position here: https://jobs.netflix.com/jobs/434
- Manager - Performance Engineering: Lead the world-class performance team in charge of both optimizing the Netflix cloud stack and developing the performance observability capabilities Continue reading
A Journey Through How Zapier Automates Billions of Workflow Automation Tasks
This is a guest repost by Bryan Helmig, Co-founder & CTO at Zapier, who makes it easy to automate tasks between web apps.

Zapier is a web service that automates data flow between over 500 web apps, including MailChimp, Salesforce, GitHub, Trello and many more.
Imagine building a workflow (or a "Zap" as we call it) that triggers when a user fills out your Typeform form, then automatically creates an event on your Google Calendar, sends a Slack notification and finishes up by adding a row to a Google Sheets spreadsheet. That's Zapier. Building Zaps like this is very easy, even for non-technical users, and is infinitely customizable.
As CTO and co-founder, I built much of the original core system, and today lead the engineering team. I'd like to take you on a journey through our stack, how we built it and how we're still improving it today!
The Teams Behind the Curtains
It takes a lot to make Zapier tick, so we have four distinct teams in engineering:
- The frontend team, which works on the very powerful workflow editor.
- The full stack team, which is cross-functional but focuses on the workflow engine.
- The Continue reading
When Should Approximate Query Processing Be Used?

This is a guest repost by Barzan Mozafari, who is part of a new startup, www.snappydata.io, that recently launched an open source OLTP + OLAP Database built on Spark.
The growing market for Big Data has created a lot of interest around approximate query processing (AQP) as a means of achieving interactive response times (e.g., sub-second latencies) when faced with terabytes and petabytes of data. At the same time, there is a lot of misinformation about this technology and what it can or cannot do.
Having been involved in building a few academic prototypes and industrial engines for approximate query processing, I have heard many interesting statements about AQP and/or sampling techniques (from both DB vendors and end-users):
Myth #1. Sampling is only useful when you know your queries in advance
Myth #2. Sampling misses out on rare events or outliers in the data
Myth #3. AQP systems cannot handle join queries
Myth #4. It is hard for end-users to use approximate answers
Myth #5. Sampling is just like indexing
Myth #6. Sampling will break the BI tools
Myth #7. There is no point approximating if your data fits in memory
Although there is a Continue reading
Google’s Transition from Single Datacenter, to Failover, to a Native Multihomed Architecture
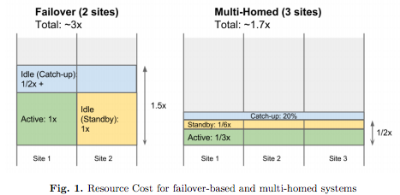
Making a system work in one datacenter is hard. Now imagine you move to two datacenters. Now imagine you need to support multiple geographically distributed datacenters. That’s the journey described in another excellent and thought provoking paper from Google: High-Availability at Massive Scale: Building Google’s Data Infrastructure for Ads.
The main idea of the paper is that the typical failover architecture used when moving from a single datacenter to multiple datacenters doesn’t work well in practice. What does work, where work means using fewer resources while providing high availability and consistency, is a natively multihomed architecture:
Our current approach is to build natively multihomed systems. Such systems run hot in multiple datacenters all the time, and adaptively move load between datacenters, with the ability to handle outages of any scale completely transparently. Additionally, planned datacenter outages and maintenance events are completely transparent, causing minimal disruption to the operational systems. In the past, such events required labor-intensive efforts to move operational systems from one datacenter to another
The use of “multihoming” in this context may be confusing because multihoming usually refers to a computer connected to more than one network. At Google scale perhaps it’s just as natural Continue reading
Stuff The Internet Says On Scalability For February 26th, 2016
- 350,000: new Telegram users per day; 15 billion: messages delivered by Telegram per day; 50 billion suns: max size of a black hole; 10,000x: lower power for Wi-Fi; 400 hours: video uploaded to YouTube every minute;
- Quotable Quotes:
- sharemywin: I don't think consensus scales. So, I think they'll be an ecosystem of block chains.
- @aneel: "There is no failover process other than the continuous dynamic load balancing."
- Jono MacDougall: If you are happy hosting your own solution, use Cassandra. If you want the ease of scaling and operations, Use DynamoDB.
- @plamere: Google’s BigQuery is *da bomb* - I can start with 2.2Billion ‘things’ and compute/summarize down to 20K in < 1 min.
- Haifa Moses: We’re evaluating a totally new software model that allows us to automatically diagnose if a failure occurs during a mission and for messages to be displayed for flight controllers on the ground
- @fmbutt: IBM abstracted analog calculation. MS abstracted HW. Goog abstracted SW. Powerful Mobile AI could abstract clouds.
- Jon Grall Continue reading
Building nginx and Tarantool based services
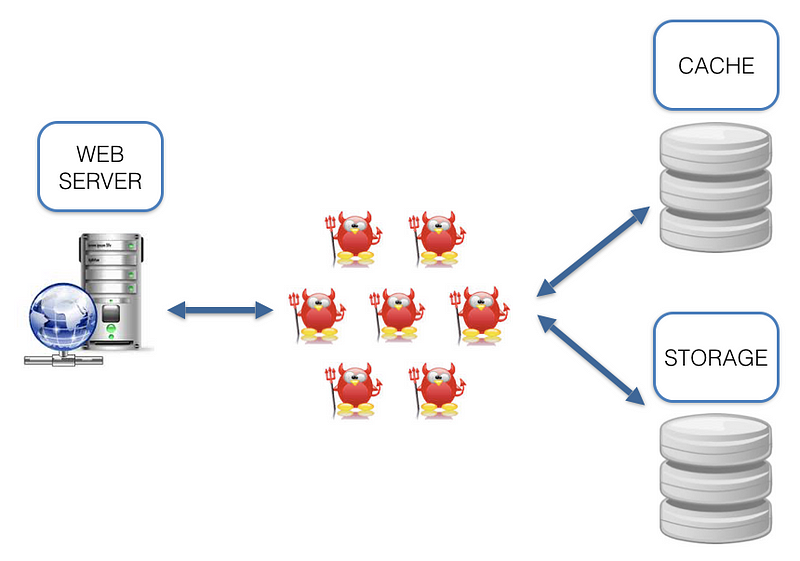
Are you familiar with this architecture? A bunch of daemons are dancing between a web-server, cache and storage.
What are the cons of such architecture? While working with it we come across a number of questions: which language (-s) should we use? Which I/O framework to choose? How to synchronize cache and storage? Lots of infrastructure issues. And why should we solve the infrastructure issues when we need to solve a task? Sure, we can say that we like some X and Y technologies and treat these cons as ideological. But we can’t ignore the fact that the data is located some distance away from the code (see the picture above), which adds latency that could decrease RPS.
The main idea of this article is to describe an alternative, built on nginx as a web-server, load balancer and Tarantool as app server, cache, storage.
Improving cache and storage
Sponsored Post: Swrve, Netflix, Macmillan Learning, Aerospike, TrueSight Pulse, LaunchDarkly, Robinhood, Redis Labs, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- Swrve -- In November we closed a $30m funding round, and we’re now expanding our engineering team based in Dublin (Ireland). Our mobile marketing platform is powered by 8bn+ events a day, processed in real time. We’re hiring intermediate and senior backend software developers to join the existing team of thirty engineers. Sound like fun? Come join us.
- Macmillan Learning, a premier e-learning institute, is looking for VP of DevOps to manage the DevOps teams based in New York and Austin. This is a very exciting team as the company is committed to fully transitioning to the Cloud, using a DevOps approach, with focus on CI/CD, and using technologies like Chef/Puppet/Docker, etc. Please apply here.
- DevOps Engineer at Robinhood. We are looking for an Operations Engineer to take responsibility for our development and production environments deployed across multiple AWS regions. Top candidates will have several years experience as a Systems Administrator, Ops Engineer, or SRE at a massive scale. Please apply here.
- Senior Service Reliability Engineer (SRE): Drive improvements to help reduce both time-to-detect and time-to-resolve while concurrently improving availability through service team engagement. Ability to analyze and triage production issues on a web-scale system a plus. Continue reading
Egnyte Architecture: Lessons Learned in Building and Scaling a Multi Petabyte Distributed System
This is a guest post by Kalpesh Patel, an Architect, who works from home. He and his colleagues spends their productive hours scaling one of the largest distributed file-system out there. He works at Egnyte, an Enterprise File Synchronization Sharing and Analytics startup and you can reach him at @kpatelwork.
Your Laptop has a filesystem used by hundreds of processes, it is limited by the disk space, it can’t expand storage elastically, it chokes if you run few I/O intensive processes or try sharing it with 100 other users. Now take this problem and magnify it to a file-system used by millions of paid users spread across world and you get a roller coaster ride scaling the system to meet monthly growth needs and meeting SLA requirements.
Egnyte is an Enterprise File Synchronization and Sharing startup founded in 2007, when Google drive wasn't born and AWS S3 was cost prohibitive. Our only option was to roll our sleeves and build an object store ourselves, overtime costs for S3 and GCS became reasonable and because our storage layer was based on a plugin architecture, we can now plug-in any storage backend that is cheaper. We have re-architected many of Continue reading
Stuff The Internet Says On Scalability For February 12th, 2016

- 3.96 Million: viewers streaming the Super Bowl; 1000 kilometers: roads made of solar panels in France; 500mg: amount of chlorophyll absorbing photons in a tree;
- Quotable Quotes:
- cmyr: soundcloud actually represents a very important cultural document; there is tons of music that has been created in the past 5+ years that exists exclusively there, and it would be a tremendous cultural loss if it were to disappear.
- aback: we will continue to endure substantial cultural losses for so long as people continue to believe that content can & should be distributed and consumed for free.
- @dotemacs: - We’re moving to Java + Spring. - Why? - Cos of threads… and scaling… - OK … what exactly…? - I’m just going by what I was told.
- @asolove: Chaos Monkey People: every week, one randomly-selected person must take the whole week off regardless of their current work. Org must adapt.
- @waynejwerner: we almost started using them, but couldn't find examples of not Google / Netflix using containers Continue reading
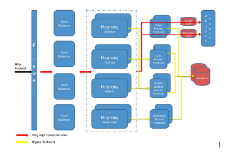
How to build your Property Management System integration using Microservices
This is a guest post by Rafael Neves, Head of Enterprise Architecture at ALICE, a NY-based hospitality technology startup. While the domain is Property Management, it's also a good microservices intro.
In a fragmented world of hospitality systems, integration is a necessity. Your system will need to interact with different systems from different providers, each providing its own Application Program Interface (API). Not only that, but as you integrate with more hotel customers, the more instances you will need to connect and manage this connection. A Property Management System (PMS) is the core system of any hotel and integration is paramount as the industry moves to become more connected.
To provide software solutions in the hospitality industry, you will certainly need to establish a 2-way integration with the PMS providers. The challenge is building and managing these connections at scale, with multiple PMS instances across multiple hotels. There are several approaches you can leverage to implement these integrations. Here, I present one simple architectural design to building an integration foundation that will increase ROI as you grow. This approach is the use of microservices.
What are microservices?
A Smallish List of Parse Migration Guides

Since Parse's big announcement it looks like the release of migration guides from various alternative services has died down.
The biggest surprise is the rise of Parse's own open source Parse Server. Check out its commit velocity on GitHub. It seems to be on its way to becoming a vibrant and viable platform.
The immediate release of Parse Server with the announcement of the closing of Parse was surprising. How could it be out so soon? That's a lot of work. Some options came to mind. Maybe it's a version of an on-premise system they already had in the works? Maybe it's a version of the simulation software they use for internal testing? Or maybe they had enough advanced notice they could make an open source version of Parse?
The winner is...
Charity Majors, formerly of Parse/Facebook, says in How to Survive an Acquisition, tells all:
Massive props to Kevin Lacker and those who saw the writing on the wall and did an amazing job preparing to open up the ecosystem.
That's impressive. It seems clear the folks at Parse weren't on board with Facebook's decision, but they certainly did everything possible to make the best Continue reading
What’s Next? The NFL’s Magic Yellow Line Shows the Way to Augmented Reality
What’s next? Mobile is entering its comforting middle age period of development. Conversational commerce is a thing, a good thing, but is it really a great thing?
What’s next may be what has been next for decades: Augmented reality (AR) (and VR). AR systems will be here sooner than you might think. A matter of years, not decades. Robert Scoble, for example, thinks Meta, an early startup in AR industry, will be bigger than the Macintosh. More on that in a later post. Magic Leap has no product and $1.3 billion in funding. Facebook has Oculus. Microsoft has HoloLens. Google may be releasing a VR system later this year. Apple is working on VR. Becoming the next iPhone is up for grabs.
AR is a Huge Opportunity for Programmers and Startups
This is a technological revolution that will be bigger than mobile. Opportunities in mobile for developers have largely played out. Experience shows the earlier you get in on a revolution the better the opportunity will be. Do you want to be writing free iOS apps forever?
It’s so early we don’t really have an idea what AR is or what the market will be Continue reading
Stuff The Internet Says On Scalability For February 5th, 2016

- 1 billion: WhatsApp users; 3.5 billion: Facebook users in 2030; $3.5 billion: art sold online; $150 billion: China's budget for making chips; 37.5MB: DNA information in a single sperm;
- Quotable Quotes:
- @jeffiel: "But seriously developers, trust us next time your needs temporarily overlap our strategic interests. And here's a t-shirt."
- @feross: Modern websites are the epitome of inefficiency. Using giant multi-MB javascript files to do what static HTML could do in 1999.
- Rob Joyce (NSA): We put the time in …to know [that network] better than the people who designed it and the people who are securing it,' he said. 'You know the technologies you intended to use in that network. We know the technologies that are actually in use in that network. Subtle difference. You'd be surprised about the things that are running on a network vs. the things that you think are supposed to be there.
- @MikeIsaac: i just realized how awkward Facebook's f8 conference is Continue reading
A Case Study: WordPress Migration for Shift.ms
The case study presented involves a migration from custom database to WordPress. The company with the task is Valet and it has a vast portfolio of previously done jobs that included shifts from database to WordPress, multisite-to-multisite, and multisite to single site among others. The client is Shift.ms.
Problem
The client, Shift.ms, presented a taxing problem to the team. Shift.ms had a custom database that they needed migrated to WordPress. They had installed a WordPress/BuddyPress and wanted their data moved into this new installation. All this may seem rather simple. However, there was one problem; the client had some data in the newly installed WordPress that they intended to keep.
Challenges
The main problem was that the schema for the database and that of WordPress are very different in infrastructure. The following issues arose in an effort to deal with the problem:
Sponsored Post: Netflix, Macmillan Learning, Aerospike, TrueSight Pulse, LaunchDarkly, Robinhood, StatusPage.io, Redis Labs, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- Manager - Site Reliability Engineering: Lead and grow the the front door SRE team in charge of keeping Netflix up and running. You are an expert of operational best practices and can work with stakeholders to positively move the needle on availability. Find details on the position here: https://jobs.netflix.com/jobs/398
- Macmillan Learning, a premier e-learning institute, is looking for VP of DevOps to manage the DevOps teams based in New York and Austin. This is a very exciting team as the company is committed to fully transitioning to the Cloud, using a DevOps approach, with focus on CI/CD, and using technologies like Chef/Puppet/Docker, etc. Please apply here.
- DevOps Engineer at Robinhood. We are looking for an Operations Engineer to take responsibility for our development and production environments deployed across multiple AWS regions. Top candidates will have several years experience as a Systems Administrator, Ops Engineer, or SRE at a massive scale. Please apply here.
- Senior Service Reliability Engineer (SRE): Drive improvements to help reduce both time-to-detect and time-to-resolve while concurrently improving availability through service team engagement. Ability to analyze and triage production issues on a web-scale system a plus. Find details on the position here: https://jobs. Continue reading