Announcing AI Gateway: making AI applications more observable, reliable, and scalable


Today, we’re excited to announce our beta of AI Gateway – the portal to making your AI applications more observable, reliable, and scalable.
AI Gateway sits between your application and the AI APIs that your application makes requests to (like OpenAI) – so that we can cache responses, limit and retry requests, and provide analytics to help you monitor and track usage. AI Gateway handles the things that nearly all AI applications need, saving you engineering time, so you can focus on what you're building.
Connecting your app to AI Gateway
It only takes one line of code for developers to get started with Cloudflare’s AI Gateway. All you need to do is replace the URL in your API calls with your unique AI Gateway endpoint. For example, with OpenAI you would define your baseURL as "https://gateway.ai.cloudflare.com/v1/ACCOUNT_TAG/GATEWAY/openai" instead of "https://api.openai.com/v1" – and that’s it. You can keep your tokens in your code environment, and we’ll log the request through AI Gateway before letting it pass through to the final API with your token.
// configuring AI gateway with the dedicated OpenAI endpoint
const openai = new OpenAI({
apiKey: env.OPENAI_API_KEY,
baseURL: "https://gateway.ai. Continue readingPartnering with Hugging Face to make deploying AI easier and more affordable than ever 🤗


Today, we’re excited to announce that we are partnering with Hugging Face to make AI models more accessible and affordable than ever before to developers.
There are three things we look forward to making available to developers over the coming months:
- We’re excited to bring serverless GPU models to Hugging Face — no more wrangling infrastructure or paying for unused capacity. Just pick your model, and go;
- Bringing popular Hugging Face optimized models to Cloudflare’s model catalog;
- Introduce Cloudflare integrations as a part of Hugging Face’s Inference solutions.
Hosting over 500,000 models and serving over one million model downloads a day, Hugging Face is the go-to place for developers to add AI to their applications.
Meanwhile, over the past six years at Cloudflare, our goal has been to make it as easy as possible for developers to bring their ideas and applications to life on our developer platform.
As AI has become a critical part of every application, this partnership has felt like a natural match to put tools in the hands of developers to make deploying AI easy and affordable.
“Hugging Face and Cloudflare both share a deep focus on making the latest AI innovations as accessible and affordable Continue reading
Vectorize: a vector database for shipping AI-powered applications to production, fast
Vectorize is our brand-new vector database offering, designed to let you build full-stack, AI-powered applications entirely on Cloudflare’s global network: and you can start building with it right away. Vectorize is in open beta, and is available to any developer using Cloudflare Workers.
You can use Vectorize with Workers AI to power semantic search, classification, recommendation and anomaly detection use-cases directly with Workers, improve the accuracy and context of answers from LLMs (Large Language Models), and/or bring-your-own embeddings from popular platforms, including OpenAI and Cohere.
Visit Vectorize’s developer documentation to get started, or read on if you want to better understand what vector databases do and how Vectorize is different.
Why do I need a vector database?
Machine learning models can’t remember anything: only what they were trained on.
Vector databases are designed to solve this, by capturing how an ML model represents data — including structured and unstructured text, images and audio — and storing it in a way that allows you to compare against future inputs. This allows us to leverage the power of existing machine-learning models and LLMs (Large Language Models) for content they haven’t been trained on: which, given the tremendous cost of training models, turns Continue reading
What AI companies are building with Cloudflare


What AI applications can you build with Cloudflare? Instead of us telling you we reached out to a small handful of the numerous AI companies using Cloudflare to learn a bit about what they’re building and how Cloudflare is helping them on their journey.
We heard common themes from these companies about the challenges they face in bringing new products to market in the ever-changing world of AI ranging from training and deploying models, the ethical and moral judgements of AI, gaining the trust of users, and the regulatory landscape. One area that is not a challenge is trusting their AI application infrastructure to Cloudflare.
Azule.ai
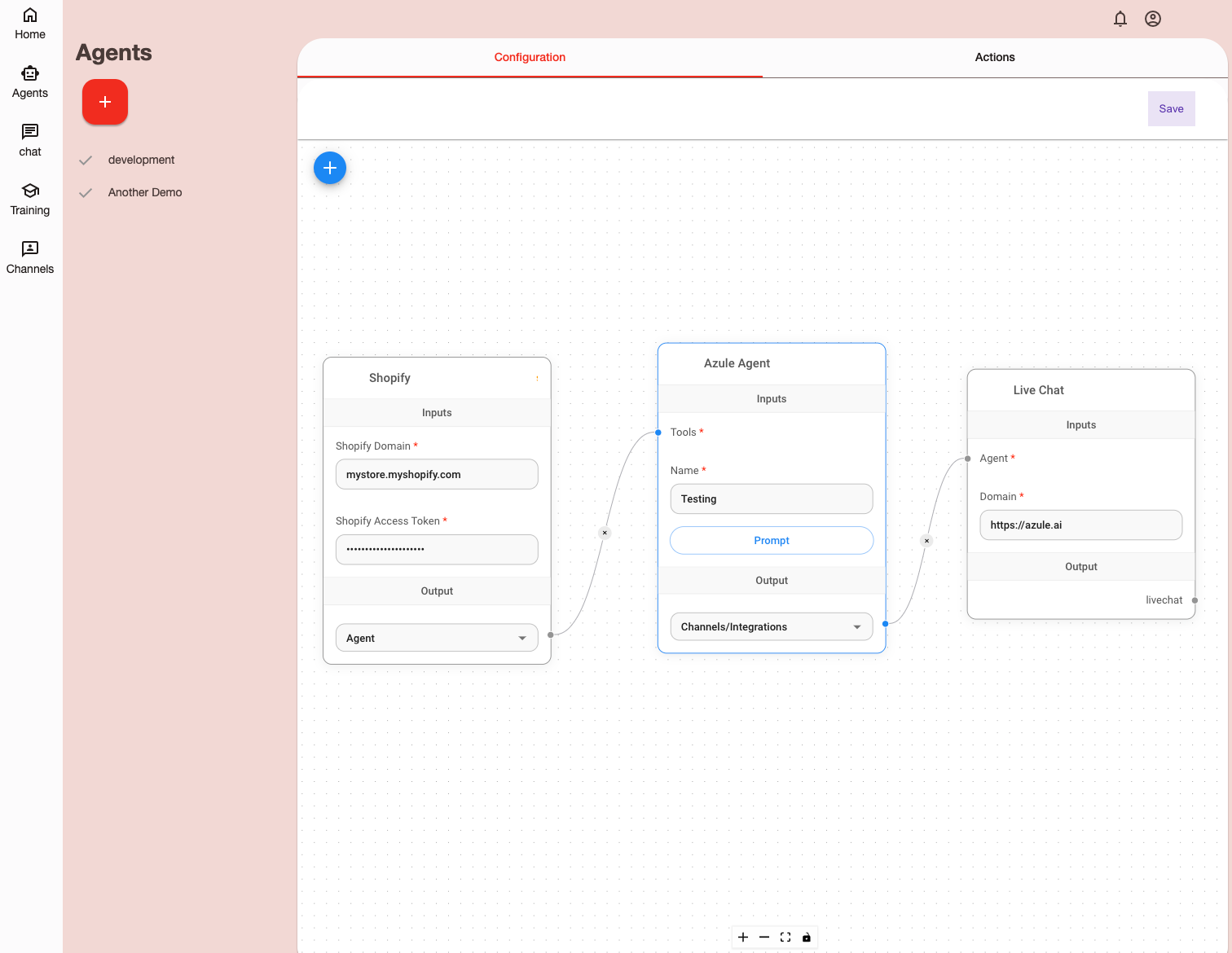
Azule, based in Calgary, Canada, was founded to apply the power of AI to streamline and improve ecommerce customer service. It’s an exciting moment that, for the first time ever, we can now dynamically generate, deploy, and test code to meet specific user needs or integrations. This kind of flexibility is crucial to create a tool like Azule that is designed to meet this demand, offering a platform that can handle complex requirements and provide flexible integration options with other tools.
The AI space is evolving quickly and that applies to the Continue reading
Cloudflare’s 2023 Annual Founders’ Letter


Cloudflare is officially a teenager. We launched on September 27, 2010. Today we celebrate our thirteenth birthday. As is our tradition, we use the week of our birthday to launch products that we think of as our gift back to the Internet. More on some of the incredible announcements in a second, but we wanted to start by talking about something more fundamental: our identity.

Like many kids, it took us a while to fully understand who we are. We chafed at being put in boxes. People would describe Cloudflare as a security company, and we'd say, "That's not all we do." They'd say we were a network, and we'd object that we were so much more. Worst of all, they'd sometimes call us a "CDN," and we'd remind them that caching is a part of any sensibly designed system, but it shouldn't be a feature unto itself. Thank you very much.
And so, yesterday, the day before our thirteenth birthday, we announced to the world finally what we realized we are: a connectivity cloud.
The connectivity cloud
What does that mean? "Connectivity" means we measure ourselves by connecting people and things together. Our job isn't to be the Continue reading
The best place on Region: Earth for inference


Today, Cloudflare’s Workers platform is the place over a million developers come to build sophisticated full-stack applications that previously wouldn’t have been possible.
Of course, Workers didn’t start out that way. It started, on a day like today, as a Birthday Week announcement. It may not have had all the bells and whistles that exist today, but if you got to try Workers when it launched, it conjured this feeling: “this is different, and it’s going to change things”. All of a sudden, going from nothing to a fully scalable, global application took seconds, not hours, days, weeks or even months. It was the beginning of a different way to build applications.
If you’ve played with generative AI over the past few months, you may have had a similar feeling. Surveying a few friends and colleagues, our “aha” moments were all a bit different, but the overarching sentiment across the industry at this moment is unanimous — this is different, and it’s going to change things.
Today, we’re excited to make a series of announcements that we believe will make a similar impact as Workers did in the future of computing. Without burying the lede any further, here they Continue reading
Welcome to connectivity cloud: the modern way to connect and protect your clouds, networks, applications and users


The best part of our job is the time we spend talking to Cloudflare customers. We always learn something new and interesting about their IT and security challenges.
In recent years, something about those conversations has changed. More and more, the biggest challenge customers tell us about isn’t something that’s easy to define. And it’s definitely not something you can address with an individual product or feature.
Rather, what we’re hearing from IT and security teams is that they are losing control of their digital environment.
This loss of control comes in a few flavors. They might express hesitance about adopting a new capability they know they need, because of compatibility concerns. Or maybe they’ll talk about how much time and effort it takes to make relatively simple changes, and how those changes take time away from more impactful work. If we had to sum the feeling up, it would be something like, “No matter how large my team or budget, it’s never enough to fully connect and protect the business.”
Does any of this feel familiar? If so, let us tell you that you are far from alone.
Reasons for loss of control
The rate of change in Continue reading
Sippy helps you avoid egress fees while incrementally migrating data from S3 to R2
Earlier in 2023, we announced Super Slurper, a data migration tool that makes it easy to copy large amounts of data to R2 from other cloud object storage providers. Since the announcement, developers have used Super Slurper to run thousands of successful migrations to R2!
While Super Slurper is perfect for cases where you want to move all of your data to R2 at once, there are scenarios where you may want to migrate your data incrementally over time. Maybe you want to avoid the one time upfront AWS data transfer bill? Or perhaps you have legacy data that may never be accessed, and you only want to migrate what’s required?
Today, we’re announcing the open beta of Sippy, an incremental migration service that copies data from S3 (other cloud providers coming soon!) to R2 as it’s requested, without paying unnecessary cloud egress fees typically associated with moving large amounts of data. On top of addressing vendor lock-in, Sippy makes stressful, time-consuming migrations a thing of the past. All you need to do is replace the S3 endpoint in your application or attach your domain to your new R2 bucket and data will start getting copied Continue reading
Traffic anomalies and notifications with Cloudflare Radar


We launched the Cloudflare Radar Outage Center (CROC) during Birthday Week 2022 as a way of keeping the community up to date on Internet disruptions, including outages and shutdowns, visible in Cloudflare’s traffic data. While some of the entries have their genesis in information from social media posts made by local telecommunications providers or civil society organizations, others are based on an internal traffic anomaly detection and alerting tool. Today, we’re adding this alerting feed to Cloudflare Radar, showing country and network-level traffic anomalies on the CROC as they are detected, as well as making the feed available via API.
Building on this new functionality, as well as the route leaks and route hijacks insights that we recently launched on Cloudflare Radar, we are also launching new Radar notification functionality, enabling you to subscribe to notifications about traffic anomalies, confirmed Internet outages, route leaks, or route hijacks. Using the Cloudflare dashboard’s existing notification functionality, users can set up notifications for one or more countries or autonomous systems, and receive notifications when a relevant event occurs. Notifications may be sent via e-mail or webhooks — the available delivery methods vary according to plan level.
Traffic anomalies
Internet traffic generally follows Continue reading
Amazon’s $2bn IPv4 tax — and how you can avoid paying it


One of the wonderful things about the Internet is that, whether as a consumer or producer, the cost has continued to come down. Back in the day, it used to be that you needed a server room, a whole host of hardware, and an army of folks to help keep everything up and running. The cloud changed that, but even with that shift, services like SSL or unmetered DDoS protection were out of reach for many. We think that the march towards a more accessible Internet — both through ease of use, and reduced cost — is a wonderful thing, and we’re proud to have played a part in making it happen.
Every now and then, however, the march of progress gets interrupted.
On July 28, 2023, Amazon Web Services (AWS) announced that they would begin to charge “per IP per hour for all public IPv4 addresses, whether attached to a service or not”, starting February 1, 2024. This change will add at least \$43 extra per year for every IPv4 address Amazon customers use; this may not sound like much, but we’ve seen back of the napkin analysis that suggests this will result in an approximately \$2bn tax on Continue reading
Image optimization made simpler and more predictable: we’re merging Cloudflare Images and Image Resizing


Starting November 15, 2023, we’re merging Cloudflare Images and Image Resizing.
All Image Resizing features will be available as part of the Cloudflare Images product. To let you calculate your monthly costs more accurately and reliably, we’re changing how we bill to resize images that aren’t stored at Cloudflare. Our new pricing model will cost $0.50 per 1,000 unique transformations.
For existing Image Resizing customers, you can continue to use the legacy version of Image Resizing. When the merge is live, then you can opt into the new pricing model for more predictable pricing.
In this post, we'll cover why we came to this decision, what's changing, and how these changes might impact you.
Simplifying our products
When you build an application with images, you need to think about three separate operations: storage, optimization, and delivery.
In 2019, we launched Image Resizing, which can optimize and transform any publicly available image on the Internet based on a set of parameters. This enables our customers to deliver variants of a single image for each use case without creating and storing additional copies.
For example, an e-commerce platform for furniture retailers might use the same image of a lamp on Continue reading
Gone offline: how Cloudflare Radar detects Internet outages


Currently, Cloudflare Radar curates a list of observed Internet disruptions (which may include partial or complete outages) in the Outage Center. These disruptions are recorded whenever we have sufficient context to correlate with an observed drop in traffic, found by checking status updates and related communications from ISPs, or finding news reports related to cable cuts, government orders, power outages, or natural disasters.
However, we observe more disruptions than we currently report in the outage center because there are cases where we can’t find any source of information that provides a likely cause for what we are observing, although we are still able to validate with external data sources such as Georgia Tech’s IODA. This curation process involves manual work, and is supported by internal tooling that allows us to analyze traffic volumes and detect anomalies automatically, triggering the workflow to find an associated root cause. While the Cloudflare Radar Outage Center is a valuable resource, one of key shortcomings include that we are not reporting all disruptions, and that the current curation process is not as timely as we’d like, because we still need to find the context.
As we announced today in a related blog post, Cloudflare Continue reading
Switching to Cloudflare can cut your network carbon emissions up to 96% (and we’re joining the SBTi)

This post is also available in 简体中文, 日本語, 한국어, Deutsch, Español and Français.

Since our founding, Cloudflare has helped customers save on costs, increase security, and boost performance and reliability by migrating legacy hardware functions to the cloud. More recently, our customers have been asking about whether this transition can also improve the environmental impact of their operations.
We are excited to share an independent report published this week that found that switching enterprise network services from on premises devices to Cloudflare services can cut related carbon emissions up to 96%, depending on your current network footprint. The majority of these gains come from consolidating services, which improves carbon efficiency by increasing the utilization of servers that are providing multiple network functions.
And we are not stopping there. Cloudflare is also proud to announce that we have applied to set carbon reduction targets through the Science Based Targets initiative (SBTi) in order to help continue to cut emissions across our operations, facilities, and supply chain.
As we wrap up the hottest summer on record, it's clear that we all have a part to play in understanding and reducing our carbon footprint. Partnering with Cloudflare Continue reading
Announcing Cloudflare Incident Alerts


A lot of people rely on Cloudflare. We serve over 46 million HTTP requests per second on average; millions of customers use our services, including 31% of the Fortune 1000. And these numbers are only growing.
Given the privileged position we sit in to help the Internet to operate, we’ve always placed a very large emphasis on transparency during incidents. But we’re constantly striving to do better.
That’s why today we are excited to announce Incident Alerts — available via email, webhook, or PagerDuty. These notifications are accessible easily in the Cloudflare dashboard, and they’re customizable to prevent notification overload. And best of all, they’re available to everyone; you simply need a free account to get started.
Lifecycle of an incident

Without proper transparency, incidents cause confusion and waste resources for anyone that relies on the Internet. With so many different entities working together to make the Internet operate, diagnosing and troubleshooting can be complicated and time-consuming. By far the best solution is for providers to have transparent and proactive alerting, so any time something goes wrong, it’s clear exactly where the problem is.
Cloudflare incident response
We understand the importance of proactive and transparent alerting around incidents. We have Continue reading
Cloudflare account permissions, how to use them, and best practices


In the dynamic landscape of modern web applications and organizations, access control is critical. Defining who can do what within your Cloudflare account ensures security and efficient workflow management. In order to help meet your organizational needs, whether you are a single developer, a small team, or a larger enterprise, we’re going to cover two changes that we have developed to make it easier to do user management, and best practices on how to use these features, alongside existing features in order to scope everything appropriately into your account, in order to ensure security while you are working with others.
What are roles?
In the preceding year, Cloudflare has expanded our list of roles available to everyone from 1 to over 60, and we are continuing to build out more, better roles. We have also made domain scoping a capability for all users. This prompts the question, what are roles, and why do they exist?
Roles are a set of permissions that exist in a bundle with a name. Every API call that is made to Cloudflare has a required set of permissions, otherwise an API call will return with a 403. We generally group permissions into a role to Continue reading
Cloudflare Stream Low-Latency HLS support now in Open Beta
Stream Live lets users easily scale their live-streaming apps and websites to millions of creators and concurrent viewers while focusing on the content rather than the infrastructure — Stream manages codecs, protocols, and bit rate automatically.
For Speed Week this year, we introduced a closed beta of Low-Latency HTTP Live Streaming (LL-HLS), which builds upon the high-quality, feature-rich HTTP Live Streaming (HLS) protocol. Lower latency brings creators even closer to their viewers, empowering customers to build more interactive features like chat and enabling the use of live-streaming in more time-sensitive applications like live e-learning, sports, gaming, and events.
Today, in celebration of Birthday Week, we’re opening this beta to all customers with even lower latency. With LL-HLS, you can deliver video to your audience faster, reducing the latency a viewer may experience on their player to as little as three seconds. Low Latency streaming is priced the same way, too: $1 per 1,000 minutes delivered, with zero extra charges for encoding or bandwidth.
Broadcast with latency as low as three seconds.
LL-HLS is an extension of the HLS standard that allows us to reduce glass-to-glass latency — the time between something happening on the broadcast end and a user seeing Continue reading
How Cloudflare’s systems dynamically route traffic across the globe


Picture this: you’re at an airport, and you’re going through an airport security checkpoint. There are a bunch of agents who are scanning your boarding pass and your passport and sending you through to your gate. All of a sudden, some of the agents go on break. Maybe there’s a leak in the ceiling above the checkpoint. Or perhaps a bunch of flights are leaving at 6pm, and a number of passengers turn up at once. Either way, this imbalance between localized supply and demand can cause huge lines and unhappy travelers — who just want to get through the line to get on their flight. How do airports handle this?
Some airports may not do anything and just let you suffer in a longer line. Some airports may offer fast-lanes through the checkpoints for a fee. But most airports will tell you to go to another security checkpoint a little farther away to ensure that you can get through to your gate as fast as possible. They may even have signs up telling you how long each line is, so you can make an easier decision when trying to get through.
At Cloudflare, we have the same problem. We Continue reading
Cloudflare Fonts: enhancing website font privacy and speed


We are thrilled to introduce Cloudflare Fonts! In the coming weeks sites that use Google Fonts will be able to effortlessly load their fonts from the site’s own domain rather than from Google. All at a click of a button. This enhances both privacy and performance. It enhances users' privacy by eliminating the need to load fonts from Google’s third-party servers. It boosts a site's performance by bringing fonts closer to end users, reducing the time spent on DNS lookups and TLS connections.
Sites that currently use Google Fonts will not need to self-host fonts or make complex code changes to benefit – Cloudflare Fonts streamlines the entire process, making it a breeze.
Fonts and privacy
When you load fonts from Google, your website initiates a data exchange with Google's servers. This means that your visitors' browsers send requests directly to Google. Consequently, Google has the potential to accumulate a range of data, including IP addresses, user agents (formatted descriptions of the browser and operating system), the referer (the page on which the Google font is to be displayed) and how often each IP makes requests to Google. While Google states that they do not use this data for targeted Continue reading
Traffic transparency: unleashing the power of Cloudflare Trace
Today, we are excited to announce Cloudflare Trace! Cloudflare Trace is available to all our customers. Cloudflare Trace enables you to understand how HTTP requests traverse your zone's configuration and what Cloudflare Rules are being applied to the request.
For many Cloudflare customers, the journey their customers' traffic embarks on through the Cloudflare ecosystem was a mysterious black box. It's a complex voyage, routed through various products, each capable of introducing modification to the request.
Consider this scenario: your web traffic could get blocked by WAF Custom Rules or Managed Rules (WAF); it might face rate limiting, or undergo modifications via Transform Rules, Where a Cloudflare account has many admins, modifying different things it can be akin to a game of "hit and hope," where the outcome of your web traffic's journey is uncertain as you are unsure how another admins rule will impact the request before or after yours. While Cloudflare's individual products are designed to be intuitive, their interoperation, or how they work together, hasn't always been as transparent as our customers need it to be. Cloudflare Trace changes this.
Running a trace
Cloudflare Trace allows users to set a number of request variables, allowing Continue reading
Welcome to Birthday Week 2023


Having been at Cloudflare since it was tiny it’s hard to believe that we’re hitting our teens! But here we are 13 years on from launch. Looking back to 2010 it was the year of iPhone 4, the first iPad, the first Kinect, Inception was in cinemas, and TiK ToK was hot (well, the Kesha song was). Given how long ago all that feels, I'd have a hard time predicting the next 13 years, so I’ll stick to predicting the future by creating it (with a ton of help from the Cloudflare team).
Building the future is, in part, what Birthday Week is about. Over the past 13 years we’ve announced things like Universal SSL (doubling the size of the encrypted web overnight and helping to usher in the largely encrypted web we all use; Cloudflare Radar shows that worldwide 99% of HTTP requests are encrypted), or Cloudflare Workers (helping change the way people build and scale applications), or unmetered DDoS protection (to help with the scourge of DDoS).
This year will be no different.
Winding back to the year I joined Cloudflare we made our first Birthday Week announcement: our automatic IPv6 gateway. Fast-forward to today and Continue reading