Worth Reading: Finding Bugs in C and C++ Compilers
Something to keep in mind before you start complaining about the crappy state of network operating systems: people are still finding hundreds of bugs in C and C++ compilers.
One might argue that compilers are even more mission-critical than network devices, they’ve been around for quite a while, and there might be more people using compilers than configuring network devices, so one would expect compilers to be relatively bug-free. Still, optimizing compilers became ridiculously complex in the past decades trying to squeeze the most out of the ever-more-complex CPU hardware, and we’re paying the price.
Keep that in mind the next time a vendor dances by with a glitzy slide deck promising software-defined nirvana.
Worth Reading: Finding Bugs in C and C++ Compilers
Something to keep in mind before you start complaining about the crappy state of network operating systems: people are still finding hundreds of bugs in C and C++ compilers.
One might argue that compilers are even more mission-critical than network devices, they’ve been around for quite a while, and there might be more people using compilers than configuring network devices, so one would expect compilers to be relatively bug-free. Still, optimizing compilers became ridiculously complex in the past decades trying to squeeze the most out of the ever-more-complex CPU hardware, and we’re paying the price.
Keep that in mind the next time a vendor dances by with a glitzy slide deck promising software-defined nirvana.
Video: Finding Paths Across the Network
Regardless of the technology used to get packets across the network, someone has to know how to get from sender to receiver(s), and as always you have multiple options:
- Almighty controller
- On-demand dynamic path discovery (example: probing)
- Participation in a routing protocol
For more details, watch Finding Paths Across the Network video.
The video is part of How Networks Really Work webinar and available with Free ipSpace.net Subscription.
Video: Finding Paths Across the Network
Regardless of the technology used to get packets across the network, someone has to know how to get from sender to receiver(s), and as always, you have multiple options:
- Almighty controller
- On-demand dynamic path discovery (example: probing)
- Participation in a routing protocol
For more details, watch Finding Paths Across the Network video.
The video is part of How Networks Really Work webinar and available with Free ipSpace.net Subscription.
MUST READ: Fast and Simple Disaster Recovery Solution
More than a year ago I was enjoying a cool beer with my friend Nicola Modena who started explaining how he solved the “you don’t need IP address renumbering for disaster recovery” conundrum with production and standby VRFs. All it takes to flip the two is a few changes in import/export route targets.
I asked Nicola to write about his design, but he’s too busy doing useful stuff. Fortunately he’s not the only one using common sense approach to disaster recovery designs (as opposed to flat earth vendor marketectures). Adrian Giacometti used a very similar design with one of his customers and documented it in a blog post.
MUST READ: Fast and Simple Disaster Recovery Solution
More than a year ago I was enjoying a cool beer with my friend Nicola Modena who started explaining how he solved the “you don’t need IP address renumbering for disaster recovery” conundrum with production and standby VRFs. All it takes to flip the two is a few changes in import/export route targets.
I asked Nicola to write about his design, but he’s too busy doing useful stuff. Fortunately he’s not the only one using common sense approach to disaster recovery designs (as opposed to flat earth vendor marketectures). Adrian Giacometti used a very similar design with one of his customers and documented it in a blog post.
Impact of Centralized Control Plane Partitioning
A long-time reader sent me a series of questions about the impact of WAN partitioning in case of an SDN-based network spanning multiple locations after watching the Architectures part of Data Center Fabrics webinar. He therefore focused on the specific case of centralized control plane (read: an equivalent of a stackable switch) with distributed controller cluster (read: switch stack spread across multiple locations).
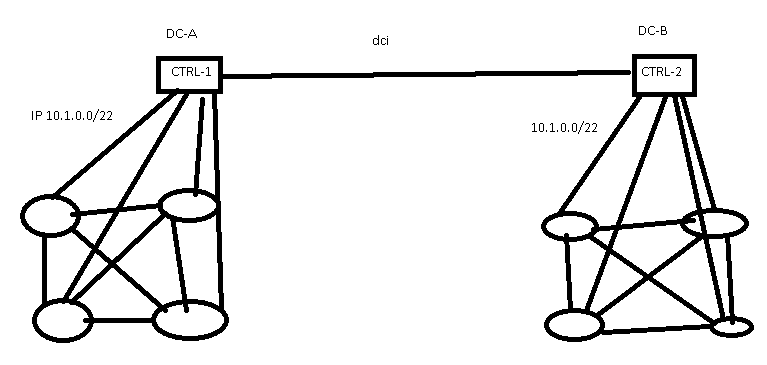
SDN controllers spread across multiple data centers
Impact of Centralized Control Plane Partitioning
A long-time reader sent me a series of questions about the impact of WAN partitioning in case of an SDN-based network spanning multiple locations after watching the Architectures part of Data Center Fabrics webinar. He therefore focused on the specific case of centralized control plane (read: an equivalent of a stackable switch) with distributed controller cluster (read: switch stack spread across multiple locations).
SDN controllers spread across multiple data centers
Rant: Broadcom and Network Operating System Vendors
Minh Ha left the following rant as a comment on my 5-year-old What Are The Problems with Broadcom Tomahawk? blog post. It’s too good to be left gathering dust there. Counterarguments and other perspectives are highly welcome.
So basically a lot of vendors these days are just glorified Broadcom resellers :p. It’s funny how some of them try to up themselves by saying they differentiate their offerings with their Network OS.
Rant: Broadcom and Network Operating System Vendors
Minh Ha left the following rant as a comment on my 5-year-old What Are The Problems with Broadcom Tomahawk? blog post. It’s too good to be left gathering dust there. Counterarguments and other perspectives are highly welcome.
So basically a lot of vendors these days are just glorified Broadcom resellers :p. It’s funny how some of them try to up themselves by saying they differentiate their offerings with their Network OS.
Thank You for All the Great Work Miha
Almost exactly a year ago Miha Markočič joined the ipSpace.net team. He was fresh out of university, fluent in Python, but with no networking or automation background… so I decided to try my traditional method of getting new team members up to speed: throw them into the deep water, observe how quickly they learn to swim, and give them a few tips if it seems like they might be drowning.
It worked out amazingly well. Miha quickly mastered the intricacies of AWS and Azure, and created full-stack automation solutions in Ansible, Terraform, CloudFormation and Azure Resource Manager to support the AWS and Azure webinars, and the public cloud networking online course.
Thank You for All the Great Work Miha
Almost exactly a year ago Miha Markočič joined the ipSpace.net team. He was fresh out of university, fluent in Python, but with no networking or automation background… so I decided to try my traditional method of getting new team members up to speed: throw them into the deep water, observe how quickly they learn to swim, and give them a few tips if it seems like they might be drowning.
It worked out amazingly well. Miha quickly mastered the intricacies of AWS and Azure, and created full-stack automation solutions in Ansible, Terraform, CloudFormation and Azure Resource Manager to support the AWS and Azure webinars, and the public cloud networking online course.
Worth Reading: Understanding Table Sizes on the Arista 7050QX-32
Arista published a blog post describing the details of forwarding table sizes on 7050QX-series switches. The description includes the base mode (fixed tables), unified forwarding tables and even the IPv6 LPM details, and dives deep into what happens when the switch runs out of forwarding table entries.
Too bad they’re describing an ancient Trident-2 ASIC (I last mentioned switches using it in 2017 Data Center Fabrics update). Did NDA expire on that one?
Worth Reading: Understanding Table Sizes on the Arista 7050QX-32
Arista published a blog post describing the details of forwarding table sizes on 7050QX-series switches. The description includes the base mode (fixed tables), unified forwarding tables and even the IPv6 LPM details, and dives deep into what happens when the switch runs out of forwarding table entries.
Too bad they’re describing an ancient Trident-2 ASIC (I last mentioned switches using it in 2017 Data Center Fabrics update). Did NDA expire on that one?
Worth Reading: AAA Deep Dive on Cisco Devices
Decades ago I understood the intricacies of AAA on Cisco IOS. These days I wing it and keep throwing spaghetti at the virtual wall until something sticks and I can log in (after all, it’s all in a lab, and I’m interested in routing protocols not interactions with TACACS+ server).
If you’re experiencing similar challenges you might appreciate AAA Deep Dive on Cisco Devices by the one and only Daniel Dib.
Worth Reading: AAA Deep Dive on Cisco Devices
Decades ago I understood the intricacies of AAA on Cisco IOS. These days I wing it and keep throwing spaghetti at the virtual wall until something sticks and I can log in (after all, it’s all in a lab, and I’m interested in routing protocols not interactions with TACACS+ server).
If you’re experiencing similar challenges you might appreciate AAA Deep Dive on Cisco Devices by the one and only Daniel Dib.
FreeRTR Deep Dive on Software Gone Wild
This podcast introduction was written by Nick Buraglio, the host of today’s podcast.
In today’s evolving landscape of whitebox, brightbox, and software routing, a small but incredibly comprehensive routing platform called FreeRTR has quietly been evolving out of a research and education service provider network in Hungary.
Kevin Myers of IPArchitechs brought this to my attention around March of 2019, at which point I went straight to work with it to see how far it could be pushed.
FreeRTR Deep Dive on Software Gone Wild
This podcast introduction was written by Nick Buraglio, the host of today’s podcast.
In today’s evolving landscape of whitebox, brightbox, and software routing, a small but incredibly comprehensive routing platform called FreeRTR has quietly been evolving out of a research and education service provider network in Hungary.
Kevin Myers of IPArchitechs brought this to my attention around March of 2019, at which point I went straight to work with it to see how far it could be pushed.
Build Virtual Lab Topology: VirtualBox Support
When I blogged about release 0.2 of my lab-building tool, Kristian Larsson was quick to reply: “now do vrnetlab”. You could guess what my reply was (hint: “submit a pull request”), but I did realize I’d have to add multi-provider support before that would make sense.
Release 0.3 adds support for multiple virtualization providers. You can run six different platforms on vagrant-libvirt (assuming you build the boxes), and I added rudimentary support for Vagrant provider for VirtualBox:
Build Virtual Lab Topology: VirtualBox Support
When I blogged about release 0.2 of my lab-building tool, Kristian Larsson was quick to reply: “now do vrnetlab”. You could guess what my reply was (hint: “submit a pull request”), but I did realize I’d have to add multi-provider support before that would make sense.
Release 0.3 adds support for multiple virtualization providers. You can run six different platforms on vagrant-libvirt (assuming you build the boxes), and I added rudimentary support for Vagrant provider for VirtualBox: