What Happens to a VM’s IP When It Moves During Migration?
Why VM IP identity needs handling on Kubernetes
A KubeVirt VM runs inside a pod. That is the trick that lets Kubernetes schedule a VM like any other workload. It also means the VM and the pod have different lifecycles. The VM is long-lived and has a stable identity. The pod is disposable. When the VM reboots, gets evicted, or live-migrates, the pod underneath is destroyed and a new one is created.
That matters because a VM’s IP is load-bearing. Firewall rules, load balancer entries, and DNS records all point at it. On Kubernetes, standard pod IPAM ties the address to the pod, so a new pod would mean a new IP, and a changed IP is what breaks those dependencies. KubeVirt on its own does not carry the IP across a migration. Its issue tracker has a user reporting exactly this, with a maintainer confirming sticky IPs were never built into the project. The network identity needs something to carry it. That something is Calico.
The diagram below shows the difference this makes. Default pod networking on the left, Calico on the right.
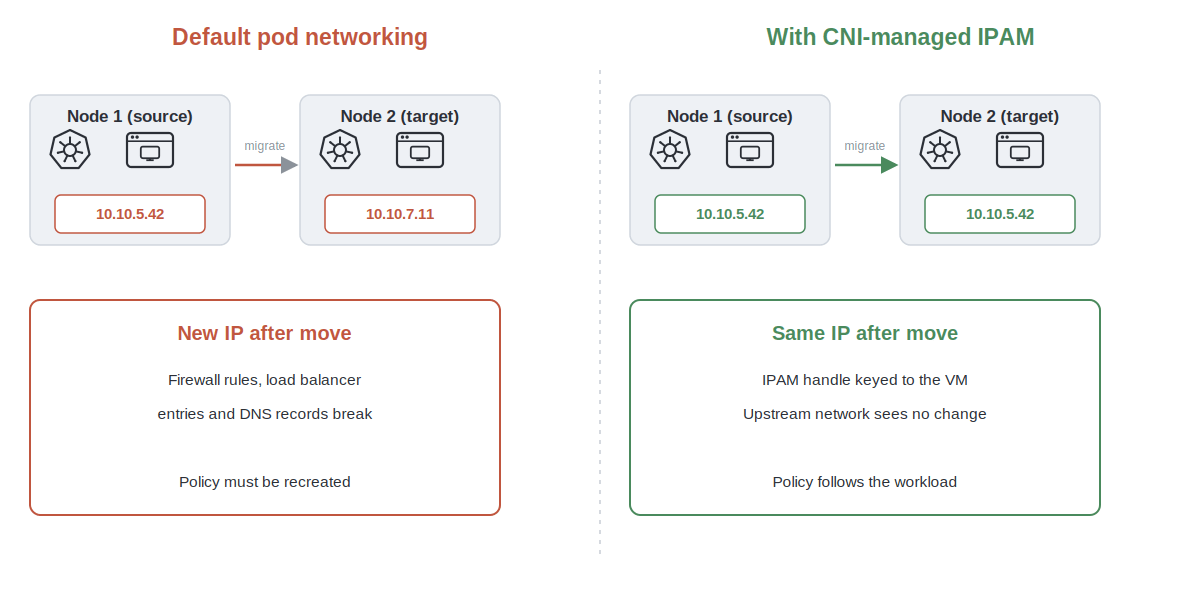
How Calico keeps the IP
Calico’s approach is elegant and specific. Instead of building the IPAM Continue reading
NVIDIA OpenShell Secures the Agent. Who Governs the Fleet?
In short: At GTC 2026, NVIDIA released OpenShell, an open source runtime that sandboxes autonomous AI agents with kernel-level policy: what files they can touch, what processes they can spawn, where their traffic can go. It is a serious piece of engineering and it validates something we have argued all year: agent security belongs in the environment, not in the prompt. But agent identity, agent-to-agent governance, and cross-sandbox communication all sit outside its scope today. This post covers what OpenShell does, where it stops by design, and three integration patterns that close the gap with Tigera Lynx.
Most attempts to control AI agents work at the model layer (alignment, system prompts) or the application layer (guardrail libraries, output filters). Both share a flaw: the thing being secured is also the thing doing the securing. A sufficiently confused or sufficiently compromised agent can talk its way past its own instructions.
OpenShell takes a different position, and it is the right one. Put the controls in the environment, where the agent cannot negotiate with them. An agent inside an OpenShell sandbox cannot leak a credential it never received, and cannot call an endpoint the kernel refuses to route.
If that argument sounds Continue reading
Tiered Network Policy: Scaling Kubernetes Security
As Kubernetes clusters scale from a few development sandboxes to massive, multi-tenant production environments, platform teams often find themselves facing a configuration management crisis. A small number of microservices suddenly demand hundreds of individual Kubernetes NetworkPolicy objects. Managing them becomes operationally expensive, auditing them is difficult, and a single developer misconfiguration can easily drop critical production traffic or open a massive security hole.
To scale cluster security without slowing down engineering velocity, we must abandon the flat, uncoordinated rule planes of the past. The solution lies in establishing a clear, multi-layered framework: a hierarchy of trust powered by tiered network policies.
The Core Problem with Standard Kubernetes NetworkPolicy
Standard Kubernetes NetworkPolicy resources are genuinely useful for basic application microsegmentation, but they have major architectural and organizational bottlenecks when scaled across an enterprise:
- Namespace-Scoped by Design: Standard network policies are inherently scoped to a namespace. If your security team mandates a cluster-wide rule, such as blocking all internal pods from querying the cloud provider’s metadata API (169.254.169.254), you have to copy-paste that policy into every single namespace. If a developer creates a new namespace, that guardrail doesn’t exist until someone manually applies it.
- Organizational Friction: Because anyone with Continue reading
Save the Address, Save the Cloud: A Hands-on KubeVirt Live Migration Workshop
In the previous post in this series, we covered why Virtual Machine (VM) Live Migration in Kubernetes is difficult: a VM’s IP is its identity, and the “new” VM on the destination node has to come up with the same IP, this something that Kubernetes is not known for, and on top of that, traffic has to switch over only after network security policies are in place. Calico v3.32.0 delivers all the above and allows you to Live Migrate a VM without any network disruptions and this post is a short, do-it-yourself workshop to achieve it.
In about 5 minutes you’ll bring up a 3-node cluster, install Calico + KubeVirt, run a VM, and migrate it live.
Requirements
- A Linux or a Windows Machine preferably WSL2 (Mac Is not supported by KubeVirt)
- Docker or Podman with at least 8 GB RAM
- kubectl
- KIND (v0.31.0)
- virtctl (v1.8.2)
Note: In many Linux distros the default for most kernel parameters are too low, for a kind cluster running KubeVirt. Use the following command to temporarily increase these limits.
sudo sysctl -w fs.inotify.max_user_instances=2048
sudo sysctl -w fs.inotify.max_user_watches=1048576If you face any Continue reading
Save the Address, Save the Cloud (KubeVirt VM Migration Story)
Kubernetes is built for containers, and it’s been doing that since it used to run docker as an engine for its containers. But what if you want to add VMs to the mix? After all, containers are ephemeral and don’t require fixed IPs as they shift the identity toward labels, but VMs on the other hand are tied to IP addresses and in some cases MAC addresses.
This brings us to this blog about VM migration and IP preservation. Unlike a pod that can be part of a deployment and run in a swarm of stateless endpoints, a VM is a stateful machine run by hypervisor like QEMU and extended to Kubernetes via KubeVirt Custom Resource Definitions (CRDs).
There Is Something About KubeVirt
KubeVirt is an abstraction layer between the underlying hypervisor (QEMU) on your machine and Kubernetes. Its job is to manage a VM’s lifecycle and provide the necessary requirements for a VM to be a native resident in Kubernetes. These requirements are CPU, Memory, Networking, etc.
KubeVirt does this by wrapping each VM in an ordinary Kubernetes pod called virt-launcher. Inside that pod, KubeVirt runs libvirt and QEMU, and the “VM” is really just a process scheduled, networked, Continue reading
Six AI agent SDKs for enterprise Kubernetes, compared
There’s a question we hear constantly from platform and engineering leaders right now, “which agent SDK should we standardize on for our Kubernetes clusters?”
The honest answer is that the question is slightly wrong, and the rest of this post explains why. But it’s a fair question, so let’s compare the contenders first.
If you’re an enterprise running on-premise or in your own VPC, the SDK you pick has to do two things most of the “build an agent in 20 lines” tutorials skip over. It has to run in a container you control, and it has to talk to a model you can host yourself. That second one rules out a surprising amount.
The six SDKs most people are actually using
These are the ones with the most mindshare in mid-2026. There are others, but these are the names that come up in every conversation. They sit on a rough spectrum of model freedom: most will happily run against a model you host yourself, the OpenAI SDK will too but treats that as a side path, and one of them (Anthropic’s) is tied to a single vendor’s models. I’ve ordered them with the most flexible first.
LangGraph
LangChain’s Continue reading
How Lynx Works: A Technical Walkthrough
We launched Lynx this week. Instead of restating the pitch, I want to explain how it’s built and why we made the architectural choices we did. If you run Kubernetes and you’re starting to put AI agents on it, this is roughly the system you’d end up designing yourself.
Lynx is a control and data plane for all agentic AI traffic, providing a registry, gateway, audit, authentication with token exchange, policy enforcement, agent sandboxing, shadow agent discovery, and advanced AI capabilities such as red team agent and a guardian supervising agent to keep your agents on track. Lynx is single control point in the path of every agent call – agent-to-agent, agent-to-MCP, agent-to-LLM. Every call is authenticated, authorized against policy, and recorded, with no changes to agent code.

The constraints we started from
Four principles shaped the design:
- No agent code changes. Governance has to be applied by the platform, not adopted as a library. If it requires a code change, it won’t land uniformly – and uniformity is the entire point.
- No new database in the control plane. The source of truth is the Kubernetes API server and the data model is custom resources – there’s no separate datastore Continue reading
Why We Built Lynx: Bringing Control to the Age of AI Agents
For a decade, one idea has guided everything we’ve built at Tigera: How do you secure a dynamic system with a lot of moving parts that is changing rapidly, with a programmatic approach? Calico has applied that idea for Global 2000 companies running the largest Kubernetes platforms in the world, securing tens of millions of mission-critical transactions every day. Today I’m excited to announce the next chapter of that work: Lynx, a unified control plane for Kubernetes-native AI agents.
This enables us to apply our deep knowledge of Kubernetes, eBPF, and our expertise in building scalable and highly performant systems to solve the security challenges that come with deploying AI Agents. Before I explain how Lynx addresses these challenges, it’s worth being clear about why AI agents are so hard to secure in the first place.
AI agents broke the assumptions security stacks were built on
The enterprise security tooling most organizations run was designed for workloads that are deterministic. A service does roughly the same thing today that it did yesterday. You can reason about its behavior, define what it’s allowed to touch, and trust that a valid credential maps to expected actions.
AI agents don’t work that way. Continue reading
Five Principles of an Accountable AI Agent Network: How to Evaluate Any Governance Platform
The first post in this series argued that AI agent governance hasn’t kept pace with deployment. The second laid out the five pillars of accountability, and what is required. The third walked through why network policies, API gateways, MCP/A2A protocols, DIY security patterns, and Role-based Access Control (RBAC) each leave critical accountability gaps.
So what does good look like?
The five pillars define what AI agent accountability requires. The principles below define how a governance platform should deliver it. These are the architectural principles your team should evaluate any AI agent governance solution against, whether you build it, buy it, or assemble it from open-source components.
If a vendor pitches you a governance platform that fails any of these five, walk away.
What are the five principles of an accountable AI agent network?
Kubernetes Network Policies are essential for securing any cluster. They restrict which pods can communicate with which other pods at the network level, and they should absolutely be part of your security posture.
- Default-deny: No agent communicates unless a policy explicitly permits it.
- Attribute-based policy: Policies reference agent attributes, not agent names.
- Zero-trust identity: Every request authenticated, every identity verified.
- Audit by design: Every interaction produces a Continue reading
Kubernetes Operational Maturity: Why You Should Modernize Your Ingress with Gateway API
SIG Network introduced Ingress in 2015 as a minimal way to expose HTTP services from a cluster. That simplicity was an advantage at a time when most workloads were HTTP, clusters were single-tenant, and the occasional gap could be papered over with a vendor annotation. As adoption grew and Kubernetes started running serious production workloads across multi-tenant, multi-cluster, multi-protocol environments, the annotations multiplied into incompatible dialects, and most organizations outgrew what Ingress could handle on its own.
The Ingress-NGINX Controller retirement, and the migration conversations that followed, exposed these cracks, but they were never the full story. Ultimately, ingress needed to grow up and the arrival of Gateway API, with SIG Network freezing the Ingress at v1 in favor of this successor, was what that looked like.
Even if migration has not been forced on your organization by the Ingress NGINX retirement, any team trying to reach Kubernetes operational maturity should be considering Gateway API as the next step on that journey.
Three reasons why Gateway API is more than and Ingress replacement
Gateway API is not just a new and improved Ingress with a few additional features bolted on. It re-architects incoming traffic management in three key ways that Continue reading
A field guide to the agents in your cluster
You know every service in your cluster by name. You know which team owns each one, what it talks to, how it scales, where its logs go. The agents are a different story.
That’s not a criticism, it’s an observation, and it’s one we keep running into. Every company we talk to is shipping agents of some kind, from scales of 10s to 1000s. Customer service bots that field tier-one tickets. Internal copilots that draft emails and summarise meetings and write the boring half of every PR. SREs that handle their own incidents at 2am while the team sleeps. What used to be a few experimental builds in a dev cluster is now dozens in some shops and hundreds in the biggest, growing faster than most teams are tracking.
That growth curve is the interesting part. Services tend to come into existence through a fairly heavyweight process. There’s a ticket, a design review, an owner, a runbook. Agents tend to arrive the way side projects do:
- Somebody had an idea on a Tuesday.
- By Friday it was in staging.
- At some point nobody can quite remember when it became part of the actual business.
Who said it could do that?
Multi-Layer Policy for Securing AI Agents
As part of our work at Tigera building products that create secure runtime environments for enterprise agents at scale in the real world, one small part of this puzzle I think about a lot is policy, and runtime enforcement of policy, and how to create a comprehensive secure runtime, configured from one place. The more companies we talk to trying to lock down and secure these platforms at runtime, the more I believe AI Agent security needs policy in multiple places, not just one (e.g., not just at the gateway layer), and ideally expressed in the same policy language.
At the L7 gateway layer, every agent call is observable: who is calling, what they are calling, what attributes both sides carry, what the requested action is. This is where you decide whether an agent should be permitted to talk to a particular MCP server, invoke a particular tool, delegate to another agent, or call a particular LLM. The atoms of policy here are identity, action, resource, and context.
At the agent runtime layer, or kernel layer in a container, what the agent does inside its own runtime is observable: syscalls, file access, library loads, network connections that bypass Continue reading
What’s new in Calico: Spring 2026 Release
Kubernetes has come a long way since its debut in 2014. It’s gone from running a couple of containerized microservices to orchestrating fleets of production workloads spanning everything from AI agents to full scale VMs running in pods. As Kubernetes adoption grows, and its use cases stretch to cover more ground, managing its increasingly complex networking and security landscape demands operational maturity and a platform that supports it.
The Spring 2026 release of Calico provides that support in two key areas:
Unified operations across Kubernetes pods and VMs
- KubeVirt Live Migration in Bridge Mode allows you to migrate VM workloads with IPs preserved, minimal packet loss, and fast route convergence. VMs can move between nodes for planned maintenance, load balancing and to support high availability without interrupting network connectivity.
- Egress Gateway Layer 2 Advertisements (Enterprise exclusive) lets pod traffic egress with IPs from the host’s own subnet so workloads get a stable identity the rest of your network already recognizes eliminating the need for BGP Peering to advertise Egress Gateway IPs.
- Policy recommendations for VMs and hosts (Enterprise exclusive) automates and scales policy authoring for Calico-managed workloads running outside of your Kubernetes clusters.
- OpenStack Live Migration Improvements lets you migrate Continue reading
The AI Agent Accountability Gap: Why Network Policies, API Gateways, And RBAC Are Not Enough
In The Five Pillars of AI Agent Accountability: A Diagnostic Framework for Engineering Leaders, we walked through each pillar of AI agent accountability (traceability, authorization provenance, identity and ownership, policy at scale, and human oversight) and argued that most enterprises today sit at Level 0 or Level 1 of the Accountability Maturity Model.
The most common reaction we get when we share that framework is some version of: “We’re already covered. We have network policies. We have an API gateway. We have RBAC.”
This article is for that reaction.
Enterprises aren’t starting from zero. Most have invested in security, networking, and identity infrastructure that works well for traditional workloads. The problem isn’t a lack of tools. It’s that existing tools were designed for model outputs, not autonomous actions; a world where services are deterministic, communication patterns are predictable, and humans make all the decisions.
Agentic AI breaks every one of those assumptions. Here’s where the most common approaches each leave a critical accountability gap.
Network policies: the wrong abstraction level
Kubernetes Network Policies are essential for securing any cluster. They restrict which pods can communicate with which other pods at the network level, and they should absolutely Continue reading
The Case for VM and Container Consolidation in 2026
Two platforms, two teams, two procurement relationships, all doing one job. There’s a reason it ended up this way. There isn’t a reason it has to stay this way.
Ask anyone at a typical enterprise why the VM platform and the container platform are separate, and they’ll give you a sensible answer. The VM estate has been there for fifteen years. It runs the workloads the business depends on. Kubernetes got stood up later, when application teams started building microservices, and giving them their own environment made more sense than retrofitting one onto VMware. Two platforms, two teams, two roadmaps.
That’s how most enterprises got here.
The reasoning was sound at the time. The question is whether it still is.
This is the consolidation question most enterprises haven’t actually revisited, and it’s the one quietly absorbing more of your budget each year.

Why VM and container platforms ended up separate
If you operate both platforms, you know the shape of this already. There’s a VMware team: vSphere admins, network engineers who know NSX, storage specialists, plus a separate procurement relationship for the underlying virtualisation stack. Then there’s a Kubernetes team: platform Continue reading
Kubernetes Operational Maturity: Secure and Resilient Cluster Federation with Cluster Mesh
Practically no one runs a single Kubernetes cluster in production these days. Maybe that’s how it started but data sovereignty requirements, acquisitions, AI initiatives and the need for edge servers, among other considerations, have pulled most enterprises into multi-cluster territory whether they planned for it or not. Reaching Kubernetes operational maturity—the point at which a fleet of clusters operates as one secure, observable, policy-consistent system—depends entirely on how those clusters are connected. Operating in a multi-cluster environment has evolved into the unspoken standard, one requiring a careful re-evaluation of the network architectures used to link clusters together.
That re-evaluation rarely happens. Most enterprises connect their clusters with the same networking patterns they were using before Kubernetes existed: load balancers fronting internal services, DNS records published to external zones, and IP-based firewall rules. Those patterns were built for north-south traffic moving in and out of a traditional data center perimeter, not for east-west traffic moving between internal workloads.
Running east-west traffic on north-south plumbing
The conventional way to make services in one cluster reachable from another is to expose them externally with a load balancer in front, a DNS name registered in a public zone, a firewall rule allowing traffic in. Continue reading
The Five Pillars of AI Agent Accountability: A Diagnostic Framework for Engineering Leaders
You’re in a board meeting. The CISO is presenting on AI risk. The CFO asks a simple question:
“When that finance agent we deployed last quarter accessed a customer payment record, can we tell who authorized it, what policy permitted it, and produce the full audit trail?”
The CISO looks at the head of the platform. The head of the platform looks at security. Nobody answers.
If you can picture that meeting happening at your company, you’re not alone. McKinsey found that only one-third of organizations have AI agent governance maturity at level 3 or higher. The other two-thirds are exactly the silence in that boardroom.
This post is the diagnostic framework that closes that gap. It’s part 2 of a five-part series on AI agent accountability, and if you only have time to read one post in the series, read this one. By the end you’ll have a five-question assessment to run with your team this week, and a maturity model to score where you stand today.
Not all governance equals AI agent accountability. Many enterprises believe they’re covered because they have network policies or an API gateway, but governance without accountability is a security theater: it Continue reading
KubeVirt Live Migration Done Right: What it Takes to Run VMs on Kubernetes
Running VMs in Kubernetes sounds like a crazy workaround for avoiding vendor lock-in, and standardizing legacy applications and newer containerized workloads on one control plane with one set of security policies to govern them all. It is, however, a rapidly growing pattern, and KubeVirt live migration — moving running VMs between nodes without downtime — is increasingly central to platform engineering use cases that require full VMs, like on-demand CI/CD pipelines.
KubeVirt is gaining traction as a way to bring VMs into Kubernetes as first-class workloads, managed with the same tools and primitives that platform teams already use for containers. It has, however, introduced some unique challenges.
Here’s the uncomfortable truth about that migration: compute and storage are the easy parts. Networking is where migrations stall, roadblock multiple, and platform teams start questioning whether KubeVirt was the right call in the first place.
If your VMs have no fixed IP dependencies, no VLAN memberships, and no upstream firewall rules scoped to specific subnets, you can migrate them into Kubernetes without losing sleep over the networking layer. If you’re running hundreds or thousands of VMs with IP addresses hardcoded into application configs, DNS entries, and firewall ACLs — and you need Continue reading
The AI Agent Accountability Crisis: Why Governance Isn’t Keeping Up With Deployment
Every enterprise is building AI agents. Marketing has one summarizing campaign performance. Engineering has one triaging incidents. Customer support has one resolving tickets. Finance has one processing invoices. Each was built by a different team, using a different framework, with different assumptions about security.
Now those agents are talking to each other through agent-to-agent (A2A) communication. The incident-triage agent calls the customer-support agent to check affected accounts. The invoice agent calls an external payment API. The marketing agent queries a data warehouse with customer records.
When something goes wrong (and at this scale of deployment, it will), can you answer:
- Who authorized the action?
- What policy permitted it?
- What was the full chain of events?
If you can’t, you have an accountability gap.
This is part one of a five-part series on AI agent accountability for engineering and security leaders. We’ll work through the gap between agent deployment and governance, the diagnostic framework that exposes it, why your existing tools won’t close it, and the principles you’ll need to evaluate any solution that claims it can.
What is AI agent accountability?
AI agent accountability is the ability to trace, prove, and audit every action an AI agent takes. This includes Continue reading
What’s New in Calico v3.32
We’re excited to announce the release of Calico Open Source v3.32! 
This release corresponds with Kubernetes v1.36 (Codename Haru) and it goes beyond just sharing a cat as the mascot of the release, it actually extends capabilities and features of Kubernetes to keep you up to date with the latest innovations of the cloud.

This release brings some of the most significant architectural changes in Calico, from live-migrating KubeVirt VMs to eBPF based Maglev load balancer.
Here’s a quick look at everything that’s new:
 Breaking Changes & Deprecations
Breaking Changes & Deprecations
 Breaking Changes & Deprecations
Breaking Changes & Deprecations- ClusterNetworkPolicy (Alpha2) replaces Admin and Baseline Admin Network Policies:
AdminNetworkPolicyandBaselineAdminNetworkPolicyhave been removed. You must migrate toClusterNetworkPolicybefore upgrading to v3.32, as Calico will no longer enforce the old resources. calico-apiserverDeprecated: The aggregated API server is deprecated and will be removed in a future release. It is being replaced by Native v3 CRDs. (Requires MutatingAdmissionPolicy feature gate, Kubernetes 1.30+).
 Key Feature Updates
Key Feature Updates
 Key Feature Updates
Key Feature Updates1. KubeVirt VM Live Migration Support
- What it does: Allows live-migrating KubeVirt VMs between nodes without dropping TCP connections.
- How it works: Achieves IP persistence by binding the IP to the VM name rather than the ephemeral pod.
- Activation: Set
kubeVirtVMAddressPersistence: EnabledContinue reading