Your AI Agents Are Autonomous. But Are They Accountable?
Why accountability, not capability, is the real bottleneck for enterprise agentic AI, and what security leaders need to do about it before regulators force the issue.
Every enterprise is building AI agents. Marketing has one summarizing campaign performance. Engineering has one triaging incidents. Customer support has one resolving tickets. Finance has one processing invoices. And increasingly, those agents are talking to each other: calling tools, accessing databases, delegating tasks across complex multi-hop chains.
But here’s the question nobody wants to hear at 3 a.m. when something goes wrong: who authorized that action, what policy permitted it, and what’s the full chain of events?
For most enterprises, the honest answer is: nobody knows. That’s not a governance problem — it’s an AI agent accountability crisis.
Agents Are Scaling Faster Than Governance
The data paints a stark picture. McKinsey research found that 80% of organizations have already encountered risky behavior from AI agents. These actions were unintended, unauthorized, or outside acceptable guardrails. Yet only about one-third of organizations report meaningful governance maturity. Gartner predicts that over 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, or inadequate risk controls.
This Continue reading
Deployed Is Not the Same as Ready: How Mature Is Your Kubernetes Environment?
Kubernetes adoption is no longer the challenge it once was. More than 82% of enterprises run containers in production, most of them on multiple Kubernetes clusters. Adoption, however, does not mean operational maturity. These are two very different things. It is one thing to deploy workloads to a cluster or two and quite another to do it securely, efficiently and at scale.
This distinction matters because the gap between adoption and Kubernetes operational maturity is where risk accumulates. Operationally mature organizations ship faster, recover from incidents in minutes instead of hours and consistently pass compliance audits. They spend less time dealing with outages and more time delivering new services to their customers.
So what separates maturity from adoption? It comes down to a handful of foundational capabilities that, when done well, result in measurable business impact. Operational maturity — the ability to run Kubernetes workloads securely, efficiently, and at scale, with consistent policy enforcement, cross-cluster observability, and automated incident recovery — is not a destination; it is a continuous process of strengthening the architectural pillars that keep your Kubernetes environment production-ready.
What does operational maturity look like?
Operational maturity spans several interconnected areas from Kubernetes security best practices to observability Continue reading
Beyond the Prompt: AI Agent Design Patterns and the New Governance Gap
If you are treating Large Language Models (LLMs) like simple question-and-answer machines, you are leaving their most transformative potential on the table. The industry has officially shifted from zero-shot prompting to structured AI agent design patterns and agentic workflows where AI iteratively reasons, uses external tools, and collaborates to solve complex engineering problems. These design patterns are the architectural blueprints that determine how autonomous Agentic AI systems work and interact with your infrastructure.
But as these systems proliferate faster than organizations can govern them, they introduce a critical AI agent security risk: By the end of 2026, 40% of enterprise applications will feature embedded AI agents, and those teams will urgently need purpose-built strategies to govern this new autonomous workforce before it becomes the next major shadow IT crisis.
Before you can secure these autonomous systems, you have to understand how they are built. Here is a technical breakdown of the current AI Agent design patterns you need to know, and the specific security blind spots each design pattern creates.
1. The Foundational Execution Patterns
Building reliable AI systems comes down to how you route the cognitive load. Here are the three baseline structural patterns:
A. The Single Agent Continue reading
How to Stub LLMs for AI Agent Security Testing and Governance
Note: The core architecture for this pattern was introduced by Isaac Hawley from Tigera.
If you are building an AI agent that relies on tool calling, complex routing, or the Model Context Protocol (MCP), you’re not just building a chatbot anymore. You are building an autonomous system with access to your internal APIs.
With that power comes a massive security and governance headache, and AI agent security testing is where most teams hit a wall. How do you definitively prove that your agent’s identity and access management (IAM) actually works?
The scale of the problem is hard to overstate. Microsoft’s telemetry shows that 80% of Fortune 500 companies now run active AI agents, yet only 47% have implemented specific AI security controls. Most teams are deploying agents faster than they can test them.
If an agent is hijacked via prompt injection, or simply hallucinates a destructive action, does your governance layer stop it? Testing this usually forces engineers into a frustrating trade-off:
- Use the real API (Gemini, OpenAI): Real models are heavily RLHF’d to be safe and polite. It is incredibly difficult (and non-deterministic) to intentionally force a real model to “go rogue” and consistently output malicious tool Continue reading
Introducing AI Assistant for Calico, Calico Load Balancer, and Seamless VM-to-Kubernetes Migration
SAN JOSE, Calif., March 23, 2026 — Tigera, the creator and maintainer of Project Calico, today announced a major expansion of its Unified Network Security Platform for Kubernetes, aimed at helping enterprises consolidate infrastructure and accelerate the migration of legacy workloads to cloud-native platforms.
The new capabilities include:
- Al Assistant for Calico: A proactive, conversational intelligence layer that replaces complex manual log analysis with natural-language troubleshooting and proactive security audits.
- Calico Load Balancer: A high-performance, eBPF-based, software-defined load balancer that replaces expensive, rigid hardware appliances with a Kubernetes-native solution.
- Seamless VM-to-Kubernetes Migration: Advanced Layer 2 (L2) networking support eliminates migration friction by allowing virtual machines to move into Kubernetes clusters without changing their original IP addresses or existing VLAN dependencies.
These innovations help organizations tackle the rising “complexity tax” in managing high-scale Kubernetes clusters and provide a high-velocity path to consolidate virtual machines and containers into a single, standardized platform.
“The industry is at a breaking point where the operational overhead of managing legacy hardware and fragmented VM silos is no longer sustainable. By building a distributed load balancer into the fabric of Calico, launching an Al assistant that ‘troubleshoots at the speed of thought,’ Continue reading
Secure and Scale VMware VKS with Calico Kubernetes Networking
Co-authors
Abhishek Rao | Tigera
Ka Kit Wong, Charles Lee, & Christian Rauber | Broadcom
VMware vSphere Kubernetes Service (VKS) is the CNCF-certified Kubernetes runtime built directly into VMware Cloud Foundation (VCF), which delivers a single platform for both virtual machines and containers. VKS enables platform engineers to deploy, manage, and scale Kubernetes clusters while leveraging a comprehensive set of cloud services. And with VKS v3.6, that foundation just got significantly more powerful: VKS now natively supports Calico Enterprise — part of the Calico Unified Platform — as a validated, lifecycle-managed networking add-on through the new VKS Addon Framework. This integration is a key milestone in VMware’s expanded partnerships across the Kubernetes ecosystem, ensuring customers have access to best-in-class networking and security tools.
Even better, VKS natively integrates Calico Open Source by Tigera as a supported, out-of-the-box Container Network Interface (CNI). This gives organizations a powerful open source baseline right from day one:
- Pluggable Data Planes: The flexibility to run high-performance eBPF, standard Linux iptables, modern nftables, or Windows data planes based on specific workload needs.
- Wire-Speed Routing: Direct BGP peering with the underlying VMware NSX infrastructure, eliminating the performance overhead of traditional overlay networks.
- Foundational Zero-Trust: Global Continue reading
Calico Load Balancer: Simplifying Network Traffic Management with eBPF
Authors: Alex O’Regan, Aadhil Abdul Majeed
Ever had a load balancer become the bottleneck in an on-prem Kubernetes cluster? You are not alone. Traditional hardware load balancers add cost, create coordination overhead, and can make scaling painful. A Kubernetes-native approach can overcome many of those challenges by pushing load balancing into the cluster data plane. Calico Load Balancer is an eBPF powered Kubernetes-native load balancer that uses consistent hashing (Maglev) and Direct Server Return (DSR) to keep sessions stable while allowing you to scale on-demand.
Below is a developer-focused walkthrough: what problem Calico Load Balancer solves, how Maglev consistent hashing works, the life of a packet with DSR, and a clear configuration workflow you can follow to roll it out.
Why a Kubernetes-native load balancer matters
On-prem clusters often rely on dedicated hardware or proprietary appliances to expose services. That comes with a few persistent problems:
- Cost and scaling friction – You have to scale the network load balancer vertically as the size and throughput requirements of your Kubernetes cluster/s grows.
- Operational overhead – Virtual IPs (VIPs) are often owned by another team, so simple service changes require coordination.
- Stateful failure modes – Kube-proxy load balancing is stateful per node, Continue reading
Lift-and-Shift VMs to Kubernetes with Calico L2 Bridge Networks
Why lift-and-shift migration is challenging
In a traditional hypervisor environment:
- A VM connects to a network the rest of the data center already understands.
- Its IP address is a first-class citizen of the network.
- Firewalls, routers, monitoring tools, and peer applications know how to reach it.
- Existing application dependencies are often built around that network identity.
Default Kubernetes pod networking works very differently:
- Pod IPs usually come from a cluster-managed pod CIDR.
- Those IPs are mainly meaningful inside the Kubernetes cluster.
- The upstream network usually does not have direct visibility into pod networks.
- The original network segments from the VM world are not preserved by default.
This creates a major problem for VM migration:
- The workload can no longer keep the same network presence it had before.
- Teams often need to introduce VIPs or reconfigure the networking settings of the Continue reading
AI Assistant for Calico: Troubleshooting at the Speed of Thought
Despite the wealth of data available, distilling a coherent narrative from a Kubernetes cluster remains a challenge for modern infrastructure teams. Even with powerful visualization tools like the Policy Board, Service Graph, and specialized dashboards, users often find themselves spending significant time piecing together context across different screens. Making good use of this data to secure a cluster or troubleshoot an issue becomes nearly impossible when it requires manually searching across multiple sources to find a single “connecting thread.”
Inevitably, security holes happen, configurations conflict causing outages, and teams scramble to find that needle-in-the-haystack cause of cluster instability. A new approach is needed to understand the complex layers of security and the interconnected relationships among numerous microservices. Observability tools need to not only organize and present data in a coherent manner but proactively help to filter and interpret it, cutting through the noise to get to the heart of an issue. As we discussed in our 2026 outlook on the rise of AI agents, this represents a fundamental shift in Kubernetes management.
Key Insight: With AI Assistant for Calico, observability takes a leap forward, providing a proactive, conversational, and context-aware intelligence layer to extract actionable insights from a Continue reading
What Your EKS Flow Logs Aren’t Telling You
If you’re running workloads on Amazon EKS, there’s a good chance you already have some form of network observability in place. VPC Flow Logs have been a staple of AWS networking for years, and AWS has since introduced Container Network Observability, a newer set of capabilities built on Amazon CloudWatch Network Flow Monitor, that adds pod-level visibility and a service map directly in the EKS console.
It’s a reasonable assumption that between these tools, you have solid visibility into what’s happening on your cluster’s network. But for teams focused on Kubernetes security and policy enforcement, there’s a significant gap — and it’s not the one you might expect.
In this post, we’ll break down exactly what EKS native observability gives you, where it falls short for security-focused use cases, and what Calico’s observability tools, Goldmane and Whisker, provide that you simply cannot get from AWS alone.
What EKS Gives You Out of the Box
AWS offers two main sources of network observability for EKS clusters:
VPC Flow Logs capture IP traffic at the network interface level across your VPC. For each flow, you get source and destination IP addresses, ports, protocol, and whether traffic was accepted or rejected at Continue reading
What Your EKS Flow Logs Aren’t Telling You
If you’re running workloads on Amazon EKS, there’s a good chance you already have some form of network observability in place. VPC Flow Logs have been a staple of AWS networking for years, and AWS has since introduced Container Network Observability, a newer set of capabilities built on Amazon CloudWatch Network Flow Monitor, that adds pod-level visibility and a service map directly in the EKS console.
It’s a reasonable assumption that between these tools, you have solid visibility into what’s happening on your cluster’s network. But for teams focused on Kubernetes security and policy enforcement, there’s a significant gap — and it’s not the one you might expect.
In this post, we’ll break down exactly what EKS native observability gives you, where it falls short for security-focused use cases, and what Calico’s observability tools, Goldmane and Whisker, provide that you simply cannot get from AWS alone.
What EKS Gives You Out of the Box
AWS offers two main sources of network observability for EKS clusters:
VPC Flow Logs capture IP traffic at the network interface level across your VPC. For each flow, you get source and destination IP addresses, ports, protocol, and whether traffic was accepted or rejected at Continue reading
How AI Agents Communicate: Understanding the A2A Protocol for Kubernetes
Since the rise of Large Language Models (LLMs) like GPT-3 and GPT-4, organizations have been rapidly adopting Agentic AI to automate and enhance their workflows. Agentic AI refers to AI systems that act autonomously, perceiving their environment, making decisions, and taking actions based on that information rather than just reacting to direct human input. In many ways, this makes AI agents similar to intelligent digital assistants, but they are capable of performing much more complex tasks over time without needing constant human oversight.
What is an AI Agent
An AI Agent is best thought of as a long-lived, thinking microservice that owns a set of perception, decision-making, and action capabilities rather than simply exposing a single API endpoint. These agents operate continuously, handling tasks over long periods rather than responding to one-time requests.
AI Agents in Kubernetes Environments
In Kubernetes environments, each agent typically runs as a pod or deployment and relies on the cluster network, DNS and possibly a service mesh to talk to tools and other agents.
Frameworks like Kagent help DevOps and platform engineers define and manage AI agents as first-class Kubernetes workloads. This means that instead of using custom, ad-hoc scripts to manually manage AI agents, Continue reading
How AI Agents Communicate: Understanding the A2A Protocol for Kubernetes
Since the rise of Large Language Models (LLMs) like GPT-3 and GPT-4, organizations have been rapidly adopting Agentic AI to automate and enhance their workflows. Agentic AI refers to AI systems that act autonomously, perceiving their environment, making decisions, and taking actions based on that information rather than just reacting to direct human input. In many ways, this makes AI agents similar to intelligent digital assistants, but they are capable of performing much more complex tasks over time without needing constant human oversight.
What is an AI Agent
An AI Agent is best thought of as a long-lived, thinking microservice that owns a set of perception, decision-making, and action capabilities rather than simply exposing a single API endpoint. These agents operate continuously, handling tasks over long periods rather than responding to one-time requests.
AI Agents in Kubernetes Environments
In Kubernetes environments, each agent typically runs as a pod or deployment and relies on the cluster network, DNS and possibly a service mesh to talk to tools and other agents.
Frameworks like Kagent help DevOps and platform engineers define and manage AI agents as first-class Kubernetes workloads. This means that instead of using custom, ad-hoc scripts to manually manage AI agents, Continue reading
What’s New in Calico: Winter 2026 Release
AI Powered Intelligence, Unified Traffic Observability and Scalable Infrastructure Management
As anyone managing one or more Kubernetes clusters knows by now, scaling can introduce an exponentially growing number of problems. The sheer volume of metrics, logs and other data can become an obstacle, rather than an asset, to effective troubleshooting and overall cluster management. Fragmented tools and manual troubleshooting processes introduce operational complexity leading to the inevitable security gaps and extended downtime. As the number of clusters grows it becomes more important than ever to find ways of reducing the observability noise, decluttering the monitoring stack and eliminating the bottlenecks that get in the way of keeping your clusters stable and secure.
The Winter 2026 release of Calico Enterprise and Calico Cloud addresses the pain points of scaling clusters with three key enhancements:
1. AI-Powered Intelligence
AI Assistant for Calico: Efficiently navigate disparate data sources to quickly get answers through natural language, or proactively identify problems before they arise.
2. Unified Traffic Observability
- Unified Ingress Gateway Dashboard: Monitor gateway traffic volume, latency, and request behavior alongside east-west traffic observability.
- Last Evaluated Policy Metrics: Identify and decommission unused security policies to maintain a lean, least-privileged posture.
Join Calico at KubeCon Europe 2026: AI Agents, Silent Discos, and Dutch Delights!
The cloud-native community is heading to the historic canals and vibrant tech scene of Amsterdam for KubeCon + CloudNativeCon Europe 2026! From March 23–26, Amsterdam will be buzzing with the latest in Kubernetes, platform engineering, and, of course, all things Calico.
Table of Contents
Whether you’re a long-time Calico user or just starting your cloud-native security journey, Tigera has a packed schedule to make your KubeCon experience both educational and unforgettable.
 Meet Our International Team
Meet Our International Team
 Meet Our International Team
Meet Our International TeamTraveling from Vancouver, San Francisco, Toronto, Cork, London, and Cambridge, our team is excited to come together in Amsterdam to welcome you! Whether you’re a first-time attendee or a KubeCon veteran, our crew has been through the trenches and is ready to share tips on everything from eBPF security to the best bitterballen in the city.
Securing the Future: AI Agent Workshop
The biggest shift in the ecosystem this year? Autonomous AI Agents. But as we move these agents into production, how do we ensure they are secure, compliant, and observed?
Join us for our featured workshop: Securing Autonomous Continue reading
Project Calico 3.30+ Hackathon: Show Us What You Can Build!
Build the Future of Cloud-Native Networking! 

The Calico community moves fast. With the releases of Calico 3.30 and 3.31, brings improvements in scalability, network security, and visibility. Now, we want to see what YOU can do with them!
We’re excited to officially invite you to the Project Calico 3.30+ Community Hackathon.
Whether you’re a seasoned eBPF expert or a newcomer to the Gateway API, we welcome your innovation and your ideas!
Table of Contents
 What’s in the Toolkit?
What’s in the Toolkit?
 What’s in the Toolkit?
What’s in the Toolkit?We’ve packed Calico 3.30+ with powerful features ready for you to hack on:
 Goldmane & Whisker: High-performance flow insights meets a sleek, operator-friendly UI.
Goldmane & Whisker: High-performance flow insights meets a sleek, operator-friendly UI.- Staged Policies: The “Safety First” way to test Zero Trust before enforcing it.
- Calico Ingress Gateway: Modern, Envoy-powered traffic management via the Gateway API.
- Calico Cloud Ready: Connect open-source clusters to a free-forever, read-only tier for instant visualization and troubleshooting.
- IPAM for Load Balancers: Consistent IP strategies for MetalLB and beyond.
- Advanced QoS: Fine-grained bandwidth and packet rate controls.
 Goldmane & Whisker: High-performance flow insights meets a sleek, operator-friendly UI.
Goldmane & Whisker: High-performance flow insights meets a sleek, operator-friendly UI. Inspiration: What Can You Build?
Inspiration: What Can You Build?
 Inspiration: What Can You Build?
Inspiration: What Can You Build?Whether you’re a networking guru or an automation Continue reading
Kubernetes Network Observability: Comparing Calico, Cilium, Retina, and Netobserv
Calico, Cilium, Retina, and Netobserv: Which Observability Tool is Right for Your Kubernetes Cluster? Network observability is a tale as old as the OSI model itself and anyone who has managed a network or even a Kubernetes cluster knows the feeling: a service suddenly can’t reach its dependency, a pod is mysteriously offline, and the Slack alerts start rolling in. Investigating network connectivity issues in these complex, distributed environments can be incredibly time consuming. Without the right tools, the debugging process often involves manually connecting to each node, running tcpdump on multiple machines, and piecing together logs to find the root cause. A path that often leads to frustration and extended downtime.
This is the problem that Kubernetes Network Observability was built to solve. By deploying distributed observers, these cloud-native solutions take the traditional flow entries and enrich them with Kubernetes flags and labels to allow Kubernetes users to get insight into the inner workings of their clusters.
This blog post aims to give you a rundown of the leading solutions in the CNCF ecosystem, and compare how they track a packet’s journey across your cluster.
Feature Comparison Matrix
Before diving into the specifics, let’s look at how these four Continue reading
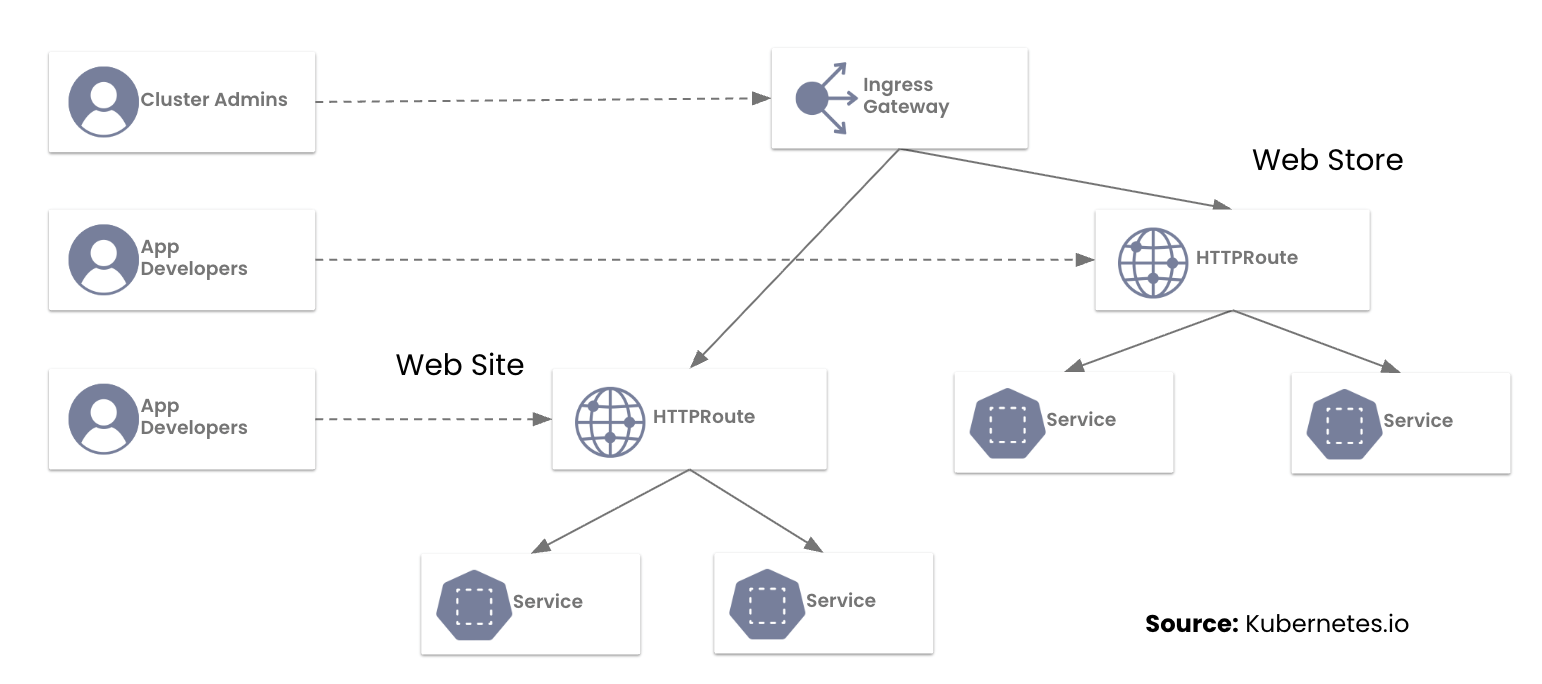
Migrating from NGINX Ingress to Calico Ingress Gateway: A Step-by-Step Guide
From Ingress NGINX to Calico Ingress Gateway
In our previous post, we addressed the most common questions platform teams are asking as they prepare for the retirement of the NGINX Ingress Controller. With the March 2026 deadline fast approaching, this guide provides a hands-on, step-by-step walkthrough for migrating to the Kubernetes Gateway API using Calico Ingress Gateway. You will learn how to translate NGINX annotations into HTTPRoute rules, run both models side by side, and safely cut over live traffic.
A Brief History
The announced retirement of the NGINX Ingress Controller has created a forced migration path for the many teams that relied on it as the industry standard. While the Ingress API is not yet officially deprecated, the Kubernetes SIG Network has designated the Gateway API as its official successor. Legacy Ingress will no longer receive enhancements and exists primarily for backward compatibility.
Why the Industry is Standardizing on Gateway API
While the Ingress API served the community for years, it reached a functional ceiling. Calico Ingress Gateway implements the Gateway API to provide:
- Role-Oriented Design: Clear separation between the infrastructure (managed by SREs) and routing logic (managed by Developers).
- Native Expressiveness: Features like URL rewrites and header manipulation Continue reading
Calico Ingress Gateway: Key FAQs Before Migrating from NGINX Ingress Controller
What Platform Teams Need to Know Before Moving to Gateway API
We recently sat down with representatives from 42 companies to discuss a pivotal moment in Kubernetes networking: the NGINX Ingress retirement.
With the March 2026 retirement of the NGINX Ingress Controller fast approaching, platform teams are now facing a hard deadline to modernize their ingress strategy. This urgency was reflected in our recent workshop, “Switching from NGINX Ingress Controller to Calico Ingress Gateway” which saw an overwhelming turnout, with engineers representing a cross-section of the industry, from financial services to high-growth tech startups.
During the session, the Tigera team highlighted a hard truth for platform teams: the original Ingress API was designed for a simpler era. Today, teams are struggling to manage production traffic through “annotation sprawl”—a web of brittle, implementation-specific hacks that make multi-tenancy and consistent security an operational nightmare.
The move to the Kubernetes Gateway API isn’t just a mandatory update; it’s a graduation to a role-oriented, expressive networking model. We’ve previously explored this shift in our blogs on Understanding the NGINX Retirement and Why the Ingress NGINX Controller is Dead.
Introducing the New Tigera & Calico Brand
Same community. A clearer, more unified look.
Today, we are excited to share a refresh of the Tigera and Calico visual identity!
This update better reflects who we are, who we serve, and where we are headed next.

If you have been part of the Calico community for a while, you know that change at Tigera is always driven by substance, not style alone. Since the early days of Project Calico, our focus has always been clear: Build powerful, scalable networking and security for Kubernetes, and do it in the open with the community.
Built for the Future, With the Community
Tigera was founded by the original Project Calico engineering team and remains deeply committed to maintaining Calico Open Source as the leading standard for container networking and network security.
“Tigera’s story began in 2016 with Project Calico, an open-source container networking and security project. Calico Open Source has since become the most widely adopted solution for containers and Kubernetes. We remain committed to maintaining Calico Open Source as the leading standard, while also delivering advanced capabilities through our commercial editions.”
—Ratan Tipirneni, President & CEO, Tigera
A Visual Evolution
This refresh is an evolution, not a reinvention. You Continue reading