Symantec Adds AWS, Microsoft, IBM Security Integrations
 The security vendor also expanded the platform’s capabilities, created an “Innovation...
The security vendor also expanded the platform’s capabilities, created an “Innovation...
The security vendor also expanded the platform’s capabilities, created an “Innovation...
 The APIs are designed to complement ongoing work by 3GPP and other industry groups working for...
The APIs are designed to complement ongoing work by 3GPP and other industry groups working for...

The previous tutorial has covered RasPBX installation on Raspberry Pi 3 board. At the end of the tutorial we have tested local calls between chan_sip extensions 1010 and 1020 that are registered to RasPBX. This time we will go further and connect RasPBX with another FreePBX VOIP system via PJSIP trunk. The FreePBX is running on VirtualBox and it is in version 14 with Asterisk 13. As the last step of the tutorial, we will test VOIP calls between RasPBX with FreePBX that are interconnected by PJSIP trunk.
As we have mentioned, a complete RasPBX and Zoiper softphones installation and configuration is covered in a previous tutorial (except the SIP trunk). Also, the tutorial does not cover installation of FreePBX on VirtualBox VM. So far, our inventory contains RasPBX and FreePBX with the following components.
RasPBX - Asterisk on Raspberry PI board:
- Asterisk 13.22.0
- FreeBPX 14.0.3.13
- Zoiper softphone on Ubuntu 18.0.4, IP 172.17.100.2/16, ext. 1010
- Zoiper softphone on Android 5.1, IP 172.17.100.5/16, ext. 1020
FreePBX - Installed on VirtualBox VM
- Asterisk 13.19.1
- FreeBPX 14.0.3.13
Continue reading

If you weren’t aware, Cloudflare Workers, our serverless programming platform, allows you to deploy code onto our 165 data centers around the world.
Want to automatically deploy Workers directly from a GitHub repository? Now you can with our official GitHub Action. This Action is an extension of our existing integration with the Serverless Framework. It runs in a containerized GitHub environment and automatically deploys your Worker to Cloudflare. We chose to utilize the Serverless Framework within our GitHub Action to raise awareness of their awesome work and to enable even more serverless applications to be built with Cloudflare Workers. This Action can be used to deploy individual Worker scripts as well; the Serverless Framework is being used in the background as the deployment mechanism.
Before going into the details, we’ll quickly go over what GitHub Actions are.
GitHub Actions allow you to trigger commands in reaction to GitHub events. These commands run in containers and can receive environment variables. Actions could trigger build, test, or deployment commands across a variety of providers. They can also be linked and run sequentially (i.e. ‘if the build passes, deploy the app’). Similar to many CI/CD tools, these commands run Continue reading
Welcome to Technology Short Take #111! I’m a couple weeks late on this one; wanted to publish it earlier but work has been keeping me busy (lots and lots of interest in Kubernetes and cloud-native technologies out there!). In any event, here you are—I hope you find something useful for you!
network-engine command parser back in Technology Short Take 102 (July of last year). I’m not sure how I missed that part 2 was published only 2 days later, so I’m rectifying that now. Go check out part 2.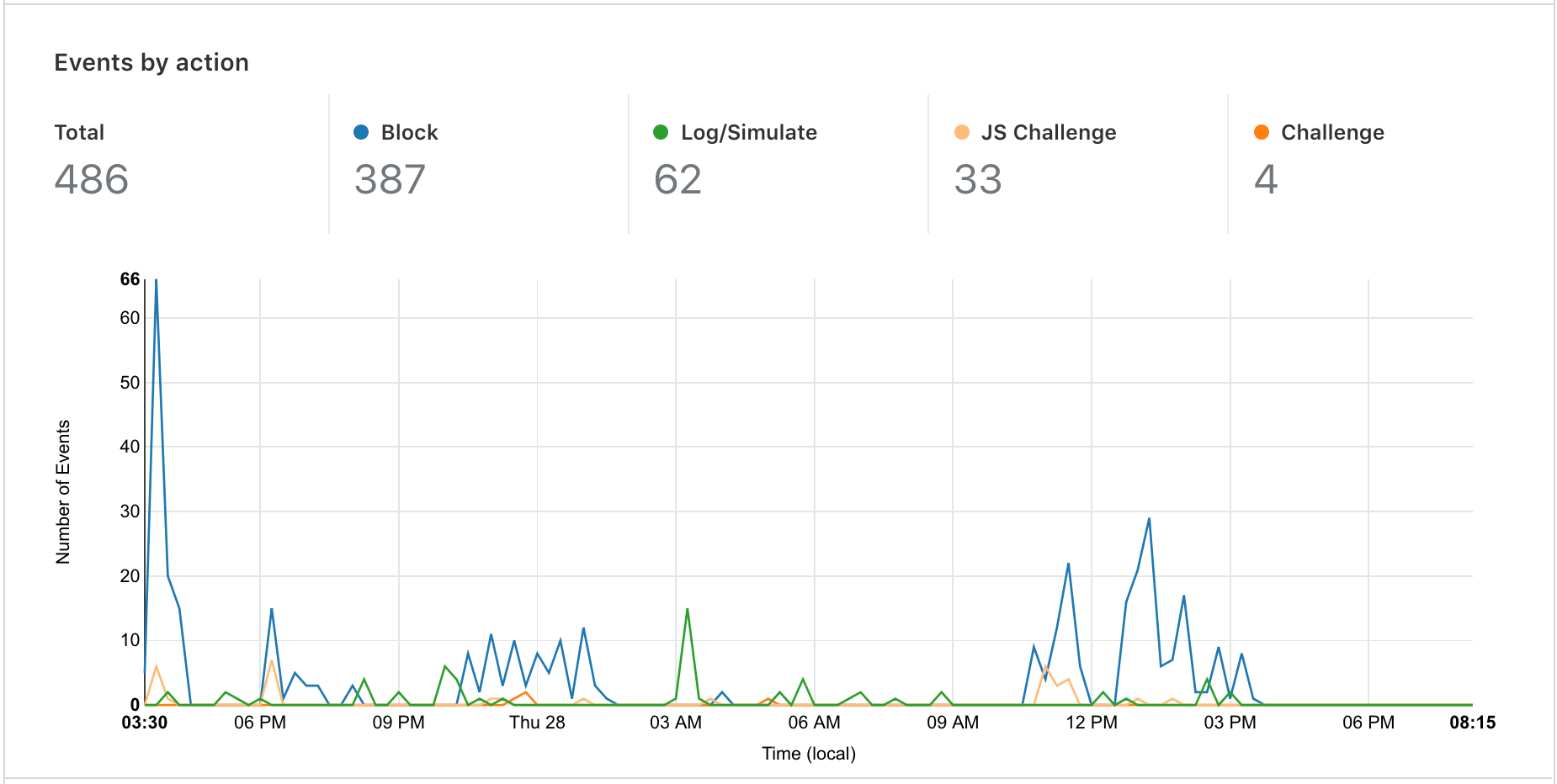
At Cloudflare, one of our top priorities is to make our products and services intuitive so that we can enable customers to accelerate and protect their Internet properties. We're excited to launch two improvements designed to make our Firewall easier to use and more accessible, and helping our customers better manage and visualize their threat-related data.
We have re-organised our features into meaningful pages: Events, Firewall Rules, Managed Rules, Tools, and Settings. Our customers will see an Overview tab, which contains our new Firewall Analytics, detailed below.

All the features you know and love are still available, and can be found in one of the four new tabs. Here is a breakdown of their new locations.
| Feature | New Location |
|---|---|
| Firewall Event Log | Events (Overview for Enterprise only) |
| Firewall Rules | Firewall Rules |
| Web Application Firewall | Managed Ruleset |
| IP Access Rules (IP Firewall | Tools |
| Rate Limiting | Tools |
| User Agent Blocking | Tools |
| Zone Lockdown | Tools |
| Browser Integrity Check | Settings |
| Challenge Passage | Settings |
| Privacy Pass | Settings |
| Security Level | Settings |
If the new sub navigation has not appeared, you may need to re-login to the dashboard or clear your browser’s cookies.
A while ago we did a podcast with Luke Gorrie in which he explained why he’d love to have simple, dumb, and easy-to-work-with Ethernet NICs. What about the other side of the coin – smart NICs with their own CPU, RAM and operating system? Do they make sense, when and why would you use them, and how would you integrate them with Linux kernel?
We discussed these challenges with Or Gerlitz (Mellanox), Andy Gospodarek (Broadcom) and Jiri Pirko (Mellanox) in Episode 99 of Software Gone Wild.
Read more ...Large scale GAN training for high fidelity natural image synthesis Brock et al., ICLR’19
Ian Goodfellow’s tweets showing x years of progress on GAN image generation really bring home how fast things are improving. For example, here’s 4.5 years worth of progress on face generation:
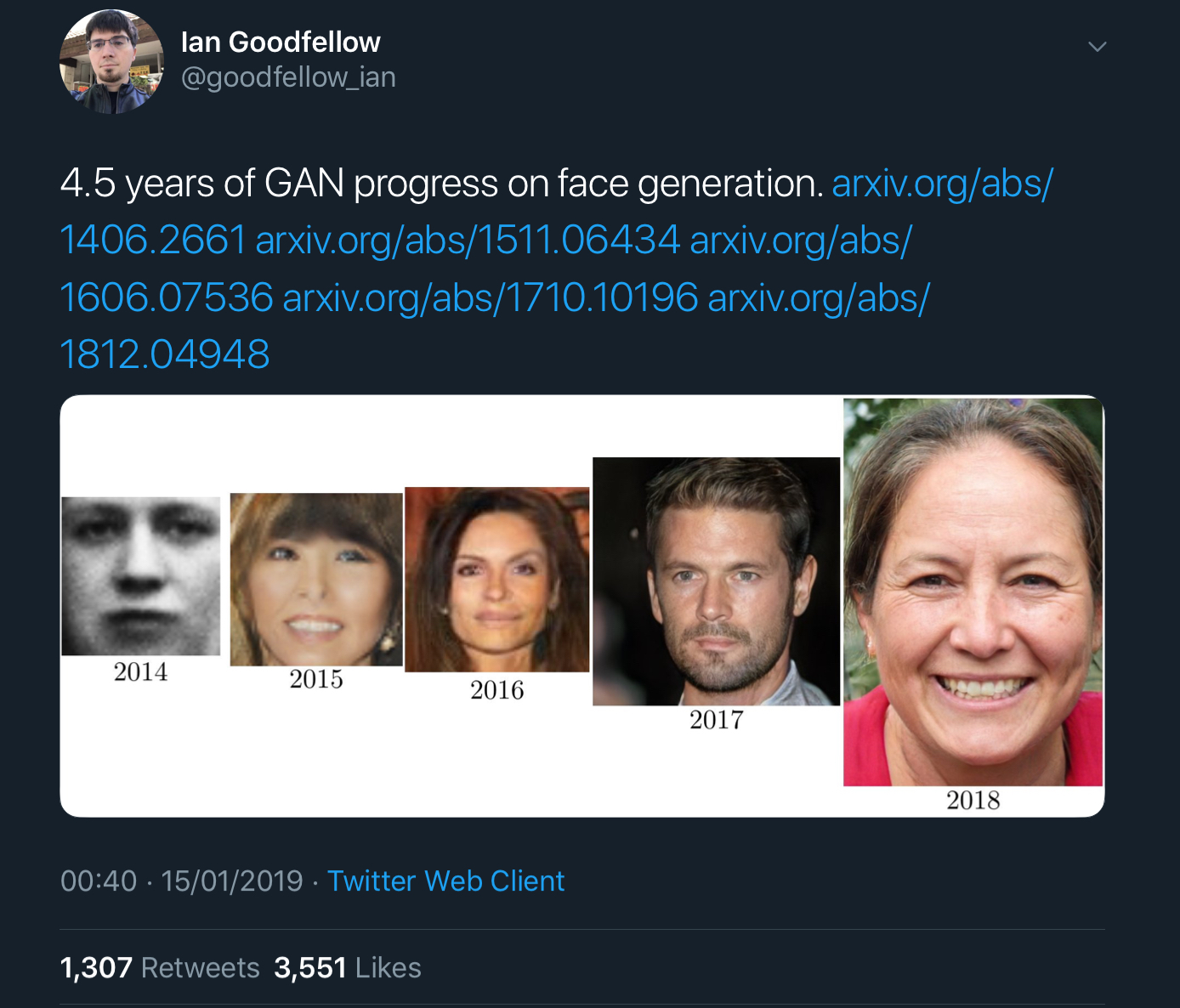
And here we have just two years of progress on class-conditional image generation:

In the case of the faces, that’s a GAN trained just to generate images of faces. The class-conditional GANs are a single network trained to generate images of lots of different object classes. In addition to feeding it some noise (random input), you also feed the generator network the class of image you’d like it to generate (condition it).
I was drawn to this paper to try and find out what’s behind the stunning rate of progress. The large-scale GANs (can I say LS-GAN?) trained here set a new state-of-the-art in class-conditional image synthesis. Here are some images generated at 512×512 resolution.

The class-conditional problem is of course much harder than the single image class problem, so we should expect the images to be not quite so stunning as the pictures of faces. In fact, using a measure called Continue reading
For the past decade, we have documented the attempted rise of ARM processors in the datacenter, specifically in general purpose servers. …
Arm Sharpens Its Edge With The “Helios” Neoverse E1 was written by Timothy Prickett Morgan at .
With the latest release for VMware NSX-T Data Center 2.4, we announced the support for IPv6. Since the advent of IPv4 address space exhaustion, IPv6 adoption has continued to increase around the world. A quick look at the Google IPv6 adoption statistics proves the fact that IPv6 adoption is ramping up. With the advances in IoT space and explosion in number of endpoints (mobile devices), this adoption will continue to grow. IPv6 increases the number of network address bits from its predecessor IPv4 from 32 to 128 bits, providing more than enough globally unique IP addresses for global end-to-end reachability. Several government agencies mandate use of IPv6. In addition to that, IPv6 also provides operational simplification.
NSX-T Data Center 2.4 release introduces the dual stack support for the interfaces on a logical router (now referred as Gateway). You can now leverage all the goodness of distributed routing or distributed firewall in a single tier topology or multi-tiered topology. If you are wondering what dual stack is; it is the capability of a device that can simultaneously originate and understand both IPv4 and IPv6 packets. In this blog, I will discuss the IPv6 features that are made generally available Continue reading
As the definition of high performance computing has morphed into some a lot broader than that just supercomputing, nearly every IT sector is adopting the technology as one of its own. …
AMD Takes High Performance Computing to the Edge was written by Michael Feldman at .