Building a To-Do List with Workers and KV
In this tutorial, we’ll build a todo list application in HTML, CSS and JavaScript, with a twist: all the data should be stored inside of the newly-launched Workers KV, and the application itself should be served directly from Cloudflare’s edge network, using Cloudflare Workers.
To start, let’s break this project down into a couple different discrete steps. In particular, it can help to focus on the constraint of working with Workers KV, as handling data is generally the most complex part of building an application:
- Build a todos data structure
- Write the todos into Workers KV
- Retrieve the todos from Workers KV
- Return an HTML page to the client, including the todos (if they exist)
- Allow creation of new todos in the UI
- Allow completion of todos in the UI
- Handle todo updates
This task order is pretty convenient, because it’s almost perfectly split into two parts: first, understanding the Cloudflare/API-level things we need to know about Workers and KV, and second, actually building up a user interface to work with the data.
Understanding Workers
In terms of implementation, a great deal of this project is centered around KV - although that may be the case, it’s useful to break Continue reading
Get ready to write — Workers KV is now in GA!
Today, we’re excited to announce Workers KV is entering general availability and is ready for production use!
What is Workers KV?
Workers KV is a highly distributed, eventually consistent, key-value store that spans Cloudflare's global edge. It allows you to store billions of key-value pairs and read them with ultra-low latency anywhere in the world. Now you can build entire applications with the performance of a CDN static cache.
Why did we build it?
Workers is a platform that lets you run JavaScript on Cloudflare's global edge of 175+ data centers. With only a few lines of code, you can route HTTP requests, modify responses, or even create new responses without an origin server.
// A Worker that handles a single redirect,
// such a humble beginning...
addEventListener("fetch", event => {
event.respondWith(handleOneRedirect(event.request))
})
async function handleOneRedirect(request) {
let url = new URL(request.url)
let device = request.headers.get("CF-Device-Type")
// If the device is mobile, add a prefix to the hostname.
// (eg. example.com becomes mobile.example.com)
if (device === "mobile") {
url.hostname = "mobile." + url.hostname
return Response.redirect(url, 302)
}
// Otherwise, send request to the original hostname.
return await fetch(request)
Continue readingOne night in Beijing


As the old saying goes, good things come in pairs, 好事成双! The month of May marks a double celebration in China for our customers, partners and Cloudflare.
First and Foremost
A Beijing Customer Appreciation Cocktail was held in the heart of Beijing at Yintai Centre Xiu Rooftop Garden Bar on the 10 May 2019, an RSVP event graced by our supportive group of partners and customers.
We have been blessed with almost 10 years of strong growth at Cloudflare - sharing our belief in providing access to internet security and performance to customers of all sizes and industries. This success has been the result of collaboration between our developers, our product team as represented today by our special guest, Jen Taylor, our Global Head of Product, Business Leaders Xavier Cai, Head of China business, and Aliza Knox Head of our APAC Business, James Ball our Head of Solutions Engineers for APAC, most importantly, by the trust and faith that our partners, such as Baidu, and customers have placed in us.


Double Happiness, 双喜

On the same week, we embarked on another exciting journey in China with our grand office opening at WeWork. Beijing team consists of functions from Customer Development Continue reading
One more thing… new Speed Page

Congratulations on making it through Speed Week. In the last week, Cloudflare has: described how our global network speeds up the Internet, launched a HTTP/2 prioritisation model that will improve web experiences on all browsers, launched an image resizing service which will deliver the optimal image to every device, optimized live video delivery, detailed how to stream progressive images so that they render twice as fast - using the flexibility of our new HTTP/2 prioritisation model and finally, prototyped a new over-the-wire format for JavaScript that could improve application start-up performance especially on mobile devices. As a bonus, we’re also rolling out one more new feature: “TCP Turbo” automatically chooses the TCP settings to further accelerate your website.
As a company, we want to help every one of our customers improve web experiences. The growth of Cloudflare, along with the increase in features, has often made simple questions difficult to answer:
- How fast is my website?
- How should I be thinking about performance features?
- How much faster would the site be if I were to enable a particular feature?
This post will describe the exciting changes we have made to the Speed Page on the Cloudflare dashboard to give Continue reading
EU election season and securing online democracy

It’s election season in Europe, as European Parliament seats are contested across the European Union by national political parties. With approximately 400 million people eligible to vote, this is one of the biggest democratic exercises in the world - second only to India - and it takes place once every five years.
Over the course of four days, 23-26 May 2019, each of the 28 EU countries will elect a different number of Members of the European Parliament (“MEPs”) roughly mapped to population size and based on a proportional system. The 751 newly elected MEPs (a number which includes the UK’s allocation for the time being) will take their seats in July. These elections are not only important because the European Parliament plays a large role in the EU democratic system, being a co-legislator alongside the European Council, but as the French President Emmanuel Macron has described, these European elections will be decisive for the future of the continent.
Election security: an EU political priority
Political focus on the potential cybersecurity threat to the EU elections has been extremely high, and various EU institutions and agencies have been engaged in a long campaign to drive awareness among EU Member Continue reading
Cloudflare architecture and how BPF eats the world
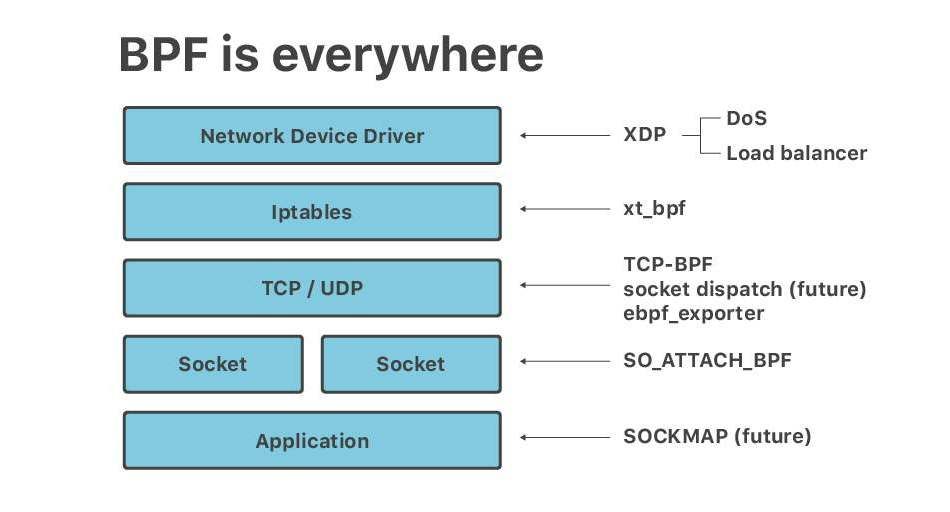
Recently at Netdev 0x13, the Conference on Linux Networking in Prague, I gave a short talk titled "Linux at Cloudflare". The talk ended up being mostly about BPF. It seems, no matter the question - BPF is the answer.
Here is a transcript of a slightly adjusted version of that talk.
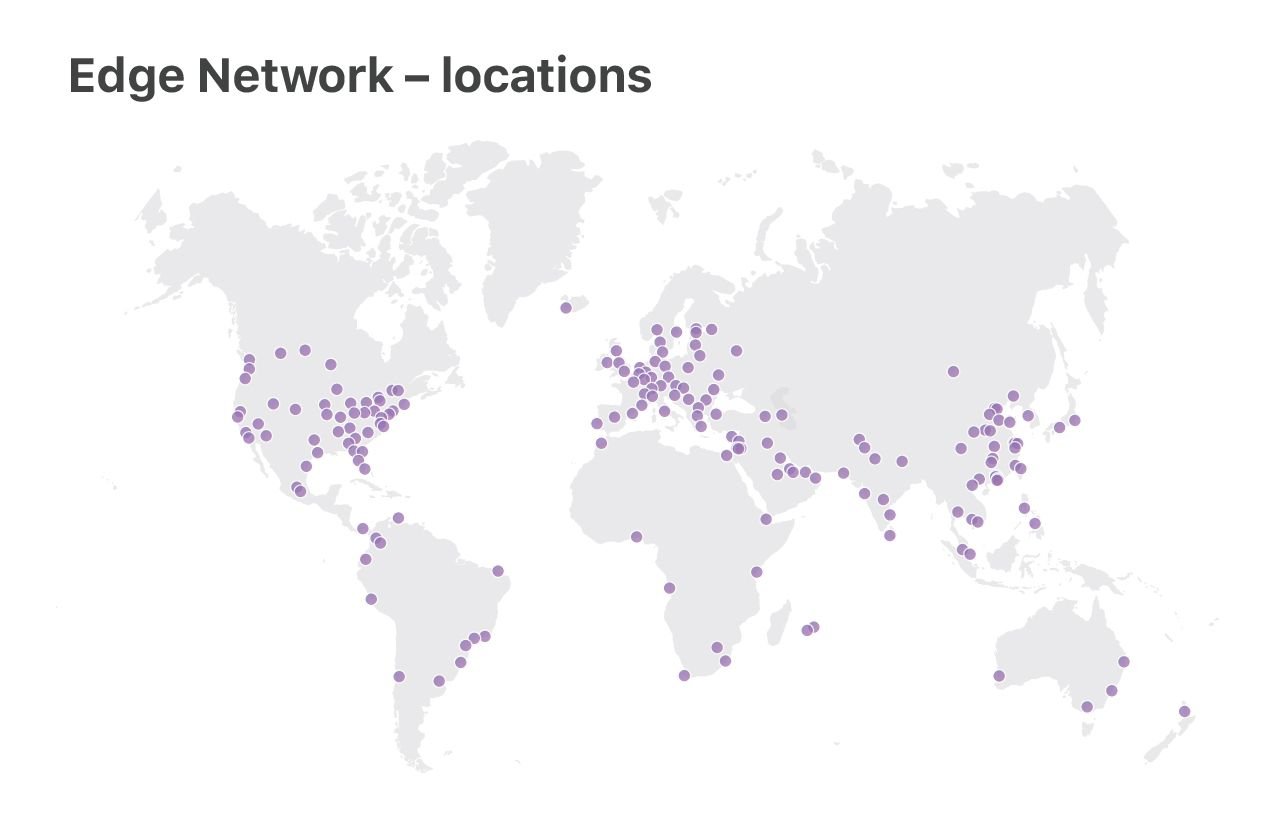
At Cloudflare we run Linux on our servers. We operate two categories of data centers: large "Core" data centers, processing logs, analyzing attacks, computing analytics, and the "Edge" server fleet, delivering customer content from 180 locations across the world.
In this talk, we will focus on the "Edge" servers. It's here where we use the newest Linux features, optimize for performance and care deeply about DoS resilience.
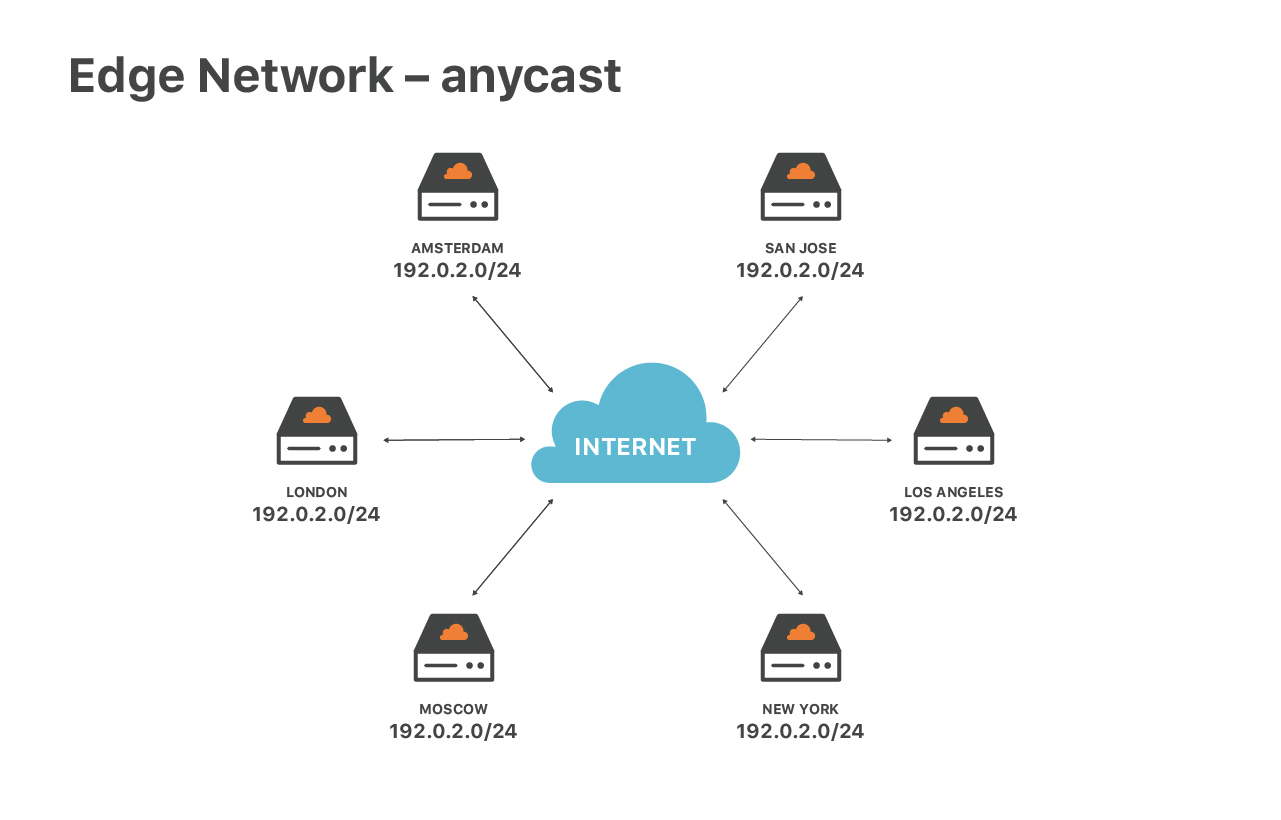
Our edge service is special due to our network configuration - we are extensively using anycast routing. Anycast means that the same set of IP addresses are announced by all our data centers.
This design has great advantages. First, it guarantees the optimal speed for end users. No matter where you are located, you will always reach the closest data center. Then, anycast helps us to spread out DoS traffic. During attacks each of the locations receives a small fraction of Continue reading
Join Cloudflare & Yandex at our Moscow meetup! Присоединяйтесь к митапу в Москве!


Are you based in Moscow? Cloudflare is partnering with Yandex to produce a meetup this month in Yandex's Moscow headquarters. We would love to invite you to join us to learn about the newest in the Internet industry. You'll join Cloudflare's users, stakeholders from the tech community, and Engineers and Product Managers from both Cloudflare and Yandex.
Cloudflare Moscow Meetup
Tuesday, May 30, 2019: 18:00 - 22:00
Location: Yandex - Ulitsa L'va Tolstogo, 16, Moskva, Russia, 119021
Talks will include "Performance and scalability at Cloudflare”, "Security at Yandex Cloud", and "Edge computing".
Speakers will include Evgeny Sidorov, Information Security Engineer at Yandex, Ivan Babrou, Performance Engineer at Cloudflare, Alex Cruz Farmer, Product Manager for Firewall at Cloudflare, and Olga Skobeleva, Solutions Engineer at Cloudflare.
Agenda:
18:00 - 19:00 - Registration and welcome cocktail
19:00 - 19:10 - Cloudflare overview
19:10 - 19:40 - Performance and scalability at Cloudflare
19:40 - 20:10 - Security at Yandex Cloud
20:10 - 20:40 - Cloudflare security solutions and industry security trends
20:40 - 21:10 - Edge computing
Q&A
The talks will be followed by food, drinks, and networking.
View Event Details & Register Here »
We'll Continue reading
Faster script loading with BinaryAST?
JavaScript Cold starts

The performance of applications on the web platform is becoming increasingly bottlenecked by the startup (load) time. Large amounts of JavaScript code are required to create rich web experiences that we’ve become used to. When we look at the total size of JavaScript requested on mobile devices from HTTPArchive, we see that an average page loads 350KB of JavaScript, while 10% of pages go over the 1MB threshold. The rise of more complex applications can push these numbers even higher.
While caching helps, popular websites regularly release new code, which makes cold start (first load) times particularly important. With browsers moving to separate caches for different domains to prevent cross-site leaks, the importance of cold starts is growing even for popular subresources served from CDNs, as they can no longer be safely shared.
Usually, when talking about the cold start performance, the primary factor considered is a raw download speed. However, on modern interactive pages one of the other big contributors to cold starts is JavaScript parsing time. This might seem surprising at first, but makes sense - before starting to execute the code, the engine has to first parse the fetched JavaScript, make sure Continue reading
Live video just got more live: Introducing Concurrent Streaming Acceleration
Today we’re excited to introduce Concurrent Streaming Acceleration, a new technique for reducing the end-to-end latency of live video on the web when using Stream Delivery.
Let’s dig into live-streaming latency, why it’s important, and what folks have done to improve it.
How “live” is “live” video?
Live streaming makes up an increasing share of video on the web. Whether it’s a TV broadcast, a live game show, or an online classroom, users expect video to arrive quickly and smoothly. And the promise of “live” is that the user is seeing events as they happen. But just how close to “real-time” is “live” Internet video?
Delivering live video on the Internet is still hard and adds lots of latency:
- The content source records video and sends it to an encoding server;
- The origin server transforms this video into a format like DASH, HLS or CMAF that can be delivered to millions of devices efficiently;
- A CDN is typically used to deliver encoded video across the globe
- Client players decode the video and render it on the screen

And all of this is under a time constraint — the whole process need to happen in a few seconds, or video experiences Continue reading
Announcing Cloudflare Image Resizing: Simplifying Optimal Image Delivery

In the past three years, the amount of image data on the median mobile webpage has doubled. Growing images translate directly to users hitting data transfer caps, experiencing slower websites, and even leaving if a website doesn’t load in a reasonable amount of time. The crime is many of these images are so slow because they are larger than they need to be, sending data over the wire which has absolutely no (positive) impact on the user’s experience.
To provide a concrete example, let’s consider this photo of Cloudflare’s Lava Lamp Wall:


On the left you see the photo, scaled to 300 pixels wide. On the right you see the same image delivered in its original high resolution, scaled in a desktop web browser. They both look exactly the same, yet the image on the right takes more than twenty times more data to load. Even for the best and most conscientious developers resizing every image to handle every possible device geometry consumes valuable time, and it’s exceptionally easy to forget to do this resizing altogether.
Today we are launching a new product, Image Resizing, to fix this problem once and for all.
Announcing Image Resizing
With Image Resizing, Cloudflare Continue reading
Parallel streaming of progressive images


Progressive image rendering and HTTP/2 multiplexing technologies have existed for a while, but now we've combined them in a new way that makes them much more powerful. With Cloudflare progressive streaming images appear to load in half of the time, and browsers can start rendering pages sooner.
In HTTP/1.1 connections, servers didn't have any choice about the order in which resources were sent to the client; they had to send responses, as a whole, in the exact order they were requested by the web browser. HTTP/2 improved this by adding multiplexing and prioritization, which allows servers to decide exactly what data is sent and when. We’ve taken advantage of these new HTTP/2 capabilities to improve perceived speed of loading of progressive images by sending the most important fragments of image data sooner.
This feature is compatible with all major browsers, and doesn’t require any changes to page markup, so it’s very easy to adopt. Sign up for the Beta to enable it on your site!
What is progressive image rendering?
Basic images load strictly from top to bottom. If a browser has received only half of an image file, it can show only the top Continue reading
Better HTTP/2 Prioritization for a Faster Web


HTTP/2 promised a much faster web and Cloudflare rolled out HTTP/2 access for all our customers long, long ago. But one feature of HTTP/2, Prioritization, didn’t live up to the hype. Not because it was fundamentally broken but because of the way browsers implemented it.
Today Cloudflare is pushing out a change to HTTP/2 Prioritization that gives our servers control of prioritization decisions that truly make the web much faster.
Historically the browser has been in control of deciding how and when web content is loaded. Today we are introducing a radical change to that model for all paid plans that puts control into the hands of the site owner directly. Customers can enable “Enhanced HTTP/2 Prioritization” in the Speed tab of the Cloudflare dashboard: this overrides the browser defaults with an improved scheduling scheme that results in a significantly faster visitor experience (we have seen 50% faster on multiple occasions). With Cloudflare Workers, site owners can take this a step further and fully customize the experience to their specific needs.
Background
Web pages are made up of dozens (sometimes hundreds) of separate resources that are loaded and assembled by the browser into the final displayed content. This includes the Continue reading
Argo and the Cloudflare Global Private Backbone


Welcome to Speed Week! Each day this week, we’re going to talk about something Cloudflare is doing to make the Internet meaningfully faster for everyone.
Cloudflare has built a massive network of data centers in 180 cities in 75 countries. One way to think of Cloudflare is a global system to transport bits securely, quickly, and reliably from any point A to any other point B on the planet.
To make that a reality, we built Argo. Argo uses real-time global network information to route around brownouts, cable cuts, packet loss, and other problems on the Internet. Argo makes the network that Cloudflare relies on—the Internet—faster, more reliable, and more secure on every hop around the world.
We launched Argo two years ago, and it now carries over 22% of Cloudflare’s traffic. On an average day, Argo cuts the amount of time Internet users spend waiting for content by 112 years!
As Cloudflare and our traffic volumes have grown, it now makes sense to build our own private backbone to add further security, reliability, and speed to key connections between Cloudflare locations.
Today, we’re introducing the Cloudflare Global Private Backbone. It’s been in operation for a while now and links Continue reading
Welcome to Speed Week!


Every year, we celebrate Cloudflare’s birthday in September when we announce the products we’re releasing to help make the Internet better for everyone. We’re always building new and innovative products throughout the year, and having to pick five announcements for just one week of the year is always challenging. Last year we brought back Crypto Week where we shared new cryptography technologies we’re supporting and helping advance to help build a more secure Internet.
Today I’m thrilled to announce we are launching our first-ever Speed Week and we want to showcase some of the things that we’re obsessed with to make the Internet faster for everyone.
How much faster is faster?
When we built the software stack that runs our network, we knew that both security and speed are important to our customers, and they should never have to compromise one for the other. All of the products we’re announcing this week will help our customers have a better experience on the Internet with as much as a 50% improvement in page load times for websites, getting the most out of HTTP/2’s features (while only lifting a finger to click the button that enables them), finding the optimal route across Continue reading
eBPF can’t count?!
{kind=link}
It is unlikely we can tell you anything new about the extended Berkeley Packet Filter, eBPF for short, if you've read all the great man pages, docs, guides, and some of our blogs out there.
But we can tell you a war story, and who doesn't like those? This one is about how eBPF lost its ability to count for a while1.
They say in our Austin, Texas office that all good stories start with "y'all ain't gonna believe this… tale." This one though, starts with a post to Linux netdev mailing list from Marek Majkowski after what I heard was a long night:
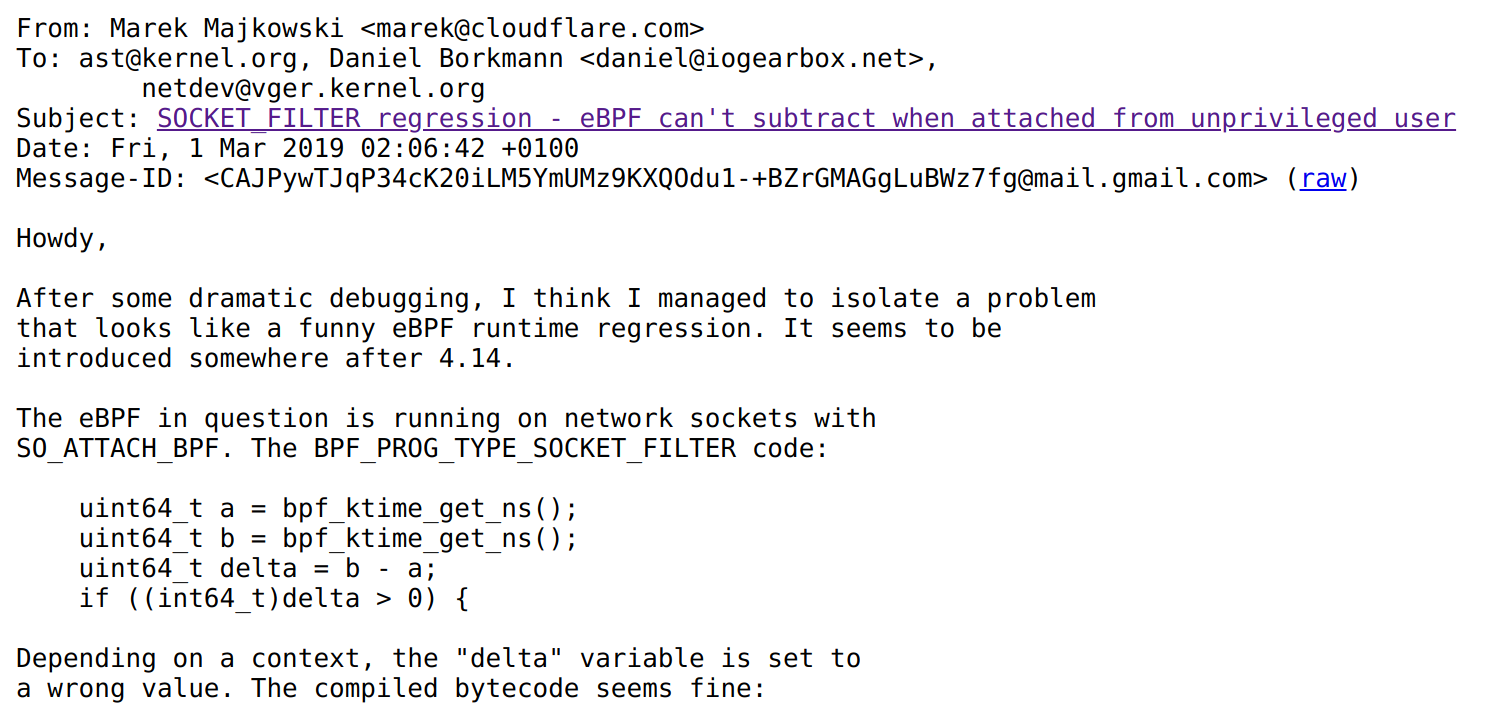
Marek's findings were quite shocking - if you subtract two 64-bit timestamps in eBPF, the result is garbage. But only when running as an unprivileged user. From root all works fine. Huh.
If you've seen Marek's presentation from the Netdev 0x13 conference, you know that we are using BPF socket filters as one of the defenses against simple, volumetric DoS attacks. So potentially getting your packet count wrong could be a Bad Thing™, and affect legitimate traffic.
Let's try to reproduce this bug with Continue reading
Unit Testing Workers, in Cloudflare Workers


We recently wrote about unit testing Cloudflare Workers within a mock environment using CloudWorker (a Node.js based mock Cloudflare Worker environment created by Dollar Shave Club's engineering team). See Unit Testing Worker Functions.
Even though Cloudflare Workers deploy globally within seconds, software developers often choose to use local mock environments to have the fastest possible feedback loop while developing on their local machines. CloudWorker is perfect for this use case but as it is still a mock environment it does not guarantee an identical runtime or environment with all Cloudflare Worker APIs and features. This gap can make developers uneasy as they do not have 100% certainty that their tests will succeed in the production environment.
In this post, we're going to demonstrate how to generate a Cloudflare Worker compatible test harness which can execute mocha unit tests directly in the production Cloudflare environment.
Directory Setup
Create a new folder for your project, change it to your working directory and run npm init to initialise the package.json file.
Run mkdir -p src && mkdir -p test/lib && mkdir dist to create folders used by the next steps. Your folder should look like this:
.
./dist
./src/worker.js
./test
./test/lib
. Continue readingThe Serverlist Newsletter: A big week of serverless announcements, serverless Rust with WASM, cloud cost hacking, and more

Check out our fourth edition of The Serverlist below. Get the latest scoop on the serverless space, get your hands dirty with new developer tutorials, engage in conversations with other serverless developers, and find upcoming meetups and conferences to attend.
Sign up below to have The Serverlist sent directly to your mailbox.
Rapid Development of Serverless Chatbots with Cloudflare Workers and Workers KV


I'm the Product Manager for the Internal Tools team here at Cloudflare. We recently identified a need for a new tool around service ownership. As a fast growing engineering organization, ownership of services changes fairly frequently. Many cycles get burned in chat with questions like "Who owns service x now?
Whilst it's easy to see how a tool like this saves a few seconds per day for the asker and askee, and saves on some mental context switches, the time saved is unlikely to add up to the cost of development and maintenance.
= 5 minutes per day
x 260 work days
= 1300 mins
/ 60 mins
= 20 person hours per year
So a 20 hour investment in that tool would pay itself back in a year valuing everyone's time the same. While we've made great strides in improving the efficiency of building tools at Cloudflare, 20 hours is a stretch for an end-to-end build, deploy and operation of a new tool.
Enter Cloudflare Workers + Workers KV
The more I use Serverless and Workers, the more I'm struck with the benefits of:
1. Reduced operational overhead
When I upload a Worker, it's automatically distributed to 175+ data Continue reading
We want to host your technical meetup at Cloudflare London

Cloudflare recently moved to County Hall, the building just behind the London Eye. We have a very large event space which we would love to open up to the developer community. If you organize a technical meetup, we'd love to host you. If you attend technical meetups, please share this post with the meetup organizers.

About the space
Our event space is large enough to hold up to 280 attendees, but can also be used for a small group as well. There is a large entry way for people coming into our 6th floor lobby where check-in may be managed. Once inside the event space, you will see a large, open kitchen area which can be used to set up event food and beverages. Beyond that is Cloudflare's all-hands space, which may be used for your events.
We have several gender-neutral toilets for your guests' use as well.
Lobby
You may welcome your guests here. The event space is just to the left of this spot.

Event space
This space may be used for talks, workshops, or large panels. We can rearrange seating, based on the format of your meetup.

Food & Continue reading
xdpcap: XDP Packet Capture

Our servers process a lot of network packets, be it legitimate traffic or large denial of service attacks. To do so efficiently, we’ve embraced eXpress Data Path (XDP), a Linux kernel technology that provides a high performance mechanism for low level packet processing. We’re using it to drop DoS attack packets with L4Drop, and also in our new layer 4 load balancer. But there’s a downside to XDP: because it processes packets before the normal Linux network stack sees them, packets redirected or dropped are invisible to regular debugging tools such as tcpdump.
To address this, we built a tcpdump replacement for XDP, xdpcap. We are open sourcing this tool: the code and documentation are available on GitHub.
xdpcap uses our classic BPF (cBPF) to eBPF or C compiler, cbpfc, which we are also open sourcing: the code and documentation are available on GitHub.

{kind=link}
Tcpdump provides an easy way to dump specific packets of interest. For example, to capture all IPv4 DNS packets, one could:
$ tcpdump ip and udp port 53
xdpcap reuses the same syntax! xdpcap can write packets to a pcap file:
$ xdpcap /path/to/hook capture.pcap Continue reading