The Climate and Cloudflare


Power is the precursor to all modern technology. James Watt’s steam engine energized the factory, Edison and Tesla’s inventions powered street lamps, and now both fossil fuels and renewable resources power the trillions of transistors in computers and phones. In the words of anthropologist Leslie White: “Other things being equal, the degree of cultural development varies directly as the amount of energy per capita per year harnessed and put to work.”
Unfortunately, most of the traditional ways to generate power are simply not sustainable. Burning coal or natural gas releases carbon dioxide which directly leads to global warming, and threatens the habitats of global ecosystems, and by extension humans. If we can’t minimize the impact, our world will be dangerously destabilized -- mass extinctions will grow more likely, and mass famines, draughts, migration, and conflict will only be possible to triage rather than avoid.
Is the Internet the primary source of this grave threat? No: all data centers globally accounted for 2-3% of total global power use in recent years, and power consumption isn’t the only contributor to human carbon emissions. Transportation (mostly oil use in cars, trucks, ships, trains, and airplanes) and industrial processing (steel, chemicals, heavy manufacturing, Continue reading
Eating Dogfood at Scale: How We Build Serverless Apps with Workers


You’ve had a chance to build a Cloudflare Worker. You’ve tried KV Storage and have a great use case for your Worker. You’ve even demonstrated the usefulness to your product or organization. Now you need to go from writing a single file in the Cloudflare Dashboard UI Editor to source controlled code with multiple environments deployed using your favorite CI tool.
Fortunately, we have a powerful and flexible API for managing your workers. You can customize your deployment to your heart’s content. Our blog has already featured many things made possible by that API:
These tools make deployments easier to configure, but it still takes time to manage. The Serverless Framework Cloudflare Workers plugin removes that deployment overhead so you can spend more time working on your application and less on your deployment.
Focus on your application
Here at Cloudflare, we’ve been working to rebuild our Access product to run entirely on Workers. The move will allow Access to take advantage of the resiliency, performance, and flexibility of Workers. We’ll publish a more detailed post about that migration once complete, but the experience required that we retool some of our Continue reading
Announcing AMP Real URL


The promise of the AMP (Accelerated Mobile Pages) project was that it would make the web, and, in particular, the mobile web, much more pleasant to surf. The AMP HTML framework was designed to make web pages load quickly, and not distract the user with extraneous content that took them away from focusing on the web page’s content.
It was particularly aimed at publishers (such as news organizations) that wanted to provide the best, fastest web experience for readers catching up on news stories and in depth articles while on the move. It later became valuable for any site which values their mobile performance including e-commerce stores, job boards, and media sites.
As well as the AMP HTML framework, AMP also made use of caches that store copies of AMP content close to end users so that they load as quickly as possible. Although this cache make loading web pages much, much faster they introduce a problem: An AMP page served from Google’s cache has a URL starting with https://google.com/amp/. This can be incredibly confusing for end users.
Users have become used to looking at the navigation bar in a web browser to see what web site Continue reading
China | Silicon Valley | China: A path less traveled
“Real knowledge is to know the extent of one's ignorance.”
― Confucius
Blueprint:

Don’t tell our CEO, Matthew Prince, but the first day I interviewed at Cloudflare I had a $9.00 phone in my pocket, a knock-off similar to a Nokia 5140, but the UI was all in Chinese characters—that phone was a fitting symbol for my technical prowess. At that time in my career I could send emails and use Google, but that was about the extent of my tech skill set. The only code I’d ever seen was in the Matrix, Apple computers confused me, and I was working as a philosophy lecturer at The University of California, Santa Cruz. So, you know, I was pretty much the ideal candidate for a deeply technical, Silicon Valley startup.
This was in 2013. I had just returned from two years of Peace Corps service in the far Southwest of China approaching the Himalayan plateau. That experience gave me the confidence to walk into Cloudflare’s office knowing that I would be good for the job despite the gaps in my knowledge. My early training in philosophy plus my Peace Corps service gave me a blueprint for learning and Continue reading
Help us update the Cloudflare Blog!


As you’ve probably noticed over the years, we’re always evolving and improving the look and feel of different aspects of the Cloudflare experience. Sometimes it’s more about function, other times it’s more about form, and most of the time it’s a combination of both. But there’s one area of the site that many users visit even more frequently than they visit the homepage or their dashboard, and strangely enough it hasn’t really seen any major updates in years. And if you’re reading this, that means you're looking at it.
With more than 150 current contributors, and more than 1,000 posts, we have a lot of people dedicating a lot of their time to writing blog posts. And based on the responses I see in the comments, and on Twitter, there are a lot of people who really like to read what these authors have to say (whether it has much to do with Cloudflare or not).
Well, we’d like to finally give some love to the blog. And we really want to know what you, our loyal (or even occasional) readers, think. There are two options to choose from. Continue reading
Introducing Warp: Fixing Mobile Internet Performance and Security


April 1st is a miserable day for most of the Internet. While most days the Internet is full of promise and innovation, on “April Fools” a handful of elite tech companies decide to waste the time of literally billions of people with juvenile jokes that only they find funny.
Cloudflare has never been one for the traditional April Fools antics. Usually we just ignored the day and went on with our mission to help build a better Internet. Last year we decided to go the opposite direction launching a service that we hoped would benefit every Internet user: 1.1.1.1.
The service's goal was simple — be the fastest, most secure, most privacy-respecting DNS resolver on the Internet. It was our first attempt at a consumer service. While we try not to be sophomoric, we're still geeks at heart, so we couldn't resist launching 1.1.1.1 on 4/1 — even though it was April Fools, Easter, Passover, and a Sunday when every media conversation began with some variation of: "You know, if you're kidding me, you're dead to me."
No Joke
We weren't kidding. In the year that's followed, we've been overwhelmed by the response. Continue reading
Transgender Day of Visibility


My name is Kas. I’m a Cloudflare employee and I wanted to share my story with you on International Transgender Day of Visibility.
I've been different for as long as I can remember. I've been the odd one out not just for the time I've spent in tech, but most of my life.
I'm transgender in that I am gender non-binary. I'm working with the word 'agender' right now, as it is the word that describes me best: I'm not a woman, or a man, just a human. I don't really have a gender, and I certainly don't identify with either binary label.

Being transgender in tech is difficult. There are many times where we have to work harder, smarter, and give up so much to stay afloat. Times where you have to weigh the benefits of correcting your pronouns against the title of the person who is to be corrected (are they a customer? Your bosses' bosses' boss?). Times where you don't know if you can even be 'out' with your coworkers, because you just don't know if, or how, they'll treat you differently, or fairly.
Being agender or outside the Continue reading
? The Wrangler CLI: Deploying Rust with WASM on Cloudflare Workers


Today, we're open sourcing and announcing wrangler, a CLI tool for building, previewing, and publishing Rust and WebAssembly Cloudflare Workers.
If that sounds like some word salad to you, that's a reasonable reaction. All three of the technologies involved are relatively new and upcoming: WebAssembly, Rust, and Cloudflare Workers.
Why WebAssembly?
Cloudflare's mission is to help build a better Internet. We see Workers as an extension of the already incredibly powerful Web Platform, where JavaScript has allowed users to go from building small bits of interactivity, to building full applications. Node.js first extended this from the client to the server- unifying web application development around a single language – JavaScript. By choosing to use V8 isolates (the technology that powers both Node.js and the most popular browser, Chrome), we sought to make its Workers product a fully compatible, new platform for the Web, eliding the distinction between server and client. By leveraging its large global network of servers, Workers allows users to run code as close as possible to end users, eliminating the latency associated server-side logic or large client-side bundles.
But not everyone wants to write Continue reading
When I Knew Cloudflare Was the Right Place For Me

Let’s be honest, interviewing for a new job can be a long, difficult process. Not only is it emotionally draining to handle multiple rejections, slow responses, and prolonged processes, it can be physically exhausting to sit through hours of stale interviews. A former colleague of mine compared interviewing to navigating a jungle; one misstep here, one wrong answer there, and you barely make it out alive. I once had an interviewer set out a 200-piece puzzle for me to complete in order to “evaluate my problem solving skills”. Basically, when it comes to interviews, you never know what you are going to get. As you may be able to tell, my feelings towards finding a new job this past fall were grim, until I interviewed with Cloudflare.
If you truly want to be impressed by Cloudflare, interview with them. Every employee knows the process is deliberate, thoughtful, and diverse in taking the time to get to know a candidate while the candidate gets to know Cloudflare. It is humbling to realize that any employee interviewing has also passed through this challenging process. It all starts with a phone call, as most interviews do, and the process is fairly standard until Continue reading
BoringTun, a userspace WireGuard implementation in Rust
Today we are happy to release the source code of a project we’ve been working on for the past few months. It is called BoringTun, and is a userspace implementation of the WireGuard® protocol written in Rust.
![]()
A Bit About WireGuard
WireGuard is relatively new project that attempts to replace old VPN protocols, with a simple, fast, and safe protocol. Unlike legacy VPNs, WireGuard is built around the Noise Protocol Framework and relies only on a select few, modern, cryptographic primitives: X25519 for public key operations, ChaCha20-Poly1305 for authenticated encryption, and Blake2s for message authentication.
Like QUIC, WireGuard works over UDP, but its only goal is to securely encapsulate IP packets. As a result, it does not guarantee the delivery of packets, or that packets are delivered in the order they are sent.
The simplicity of the protocol means it is more robust than old, unmaintainable codebases, and can also be implemented relatively quickly. Despite its relatively young age, WireGuard is quickly gaining in popularity.
Starting From Scratch
While evaluating the potential value WireGuard could provide us, we first considered the existing implementations. Currently, there are three usable implementations
- The WireGuard kernel module - written in C, it Continue reading
A Full CI/CD Pipeline for Workers with Travis CI
In today’s post we’re going to talk about building a CI/CD pipeline for Cloudflare Worker’s using Travis CI. If you aren’t yet aware, Cloudflare Workers allow you to run Javascript in all 165 of our data centers, and they deploy globally in about 30 seconds. Learn more here.
There are a few steps before we get started. We need to have a Worker script we want to deploy, some optional unit tests for the script, a serverless.yml file to deploy via the Serverless Framework, a .gitignore file to ignore the node_modules folder, and finally, a .travis.yml configuration file. All of these files will live in the same GitHub repository, which should have a final layout like:
----- worker.js
----- serverless.yml
----- test
. worker-test.js
----- node_modules
----- package.json
----- package-lock.json
----- .travis.yml
----- .gitignore
The Worker Script
In a recent post we discussed a method for testing Workers. We’ll reuse this method here to test a really simple Worker script below which simply returns Hello World! in the body of the response. We will name our Worker worker.js.
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
async function handleRequest(request) {
return new Continue readingThe Serverlist Newsletter: Serverless Benchmarks, Workers.dev, security implications of serverless cloud computing, and more
Check out our third edition of The Serverlist below. Get the latest scoop on the serverless space, get your hands dirty with new developer tutorials, engage in conversations with other serverless developers, and find upcoming meetups and conferences to attend.
Sign up below to have The Serverlist sent directly to your mailbox.
Writing an API at the Edge with Workers and Cloud Firestore
We’re super stoked about bringing you Workers.dev, and we’re even more stoked at every opportunity we have to dogfood Workers. Using what we create keeps us tuned in to the developer experience, which takes a good deal of guesswork out of drawing our roadmaps.
Our goal with Workers.dev is to provide a way to deploy JavaScript code to our network of 165 data centers without requiring developers to register a domain with Cloudflare first. While we gear up for general availability, we wanted to provide users an opportunity to reserve their favorite subdomain in a fair and consistent way, so we built a system to allow visitors to reserve a subdomain where their Workers will live once Workers.dev is released. This is the story of how we wrote the system backing that submission process.
Requirements
Of course, we always want to use the best tool for the job, so designing the Workers that would back Workers.dev started with an inventory of constraints and user experience expectations:
Constraints
- We want to limit reservations to one per email address. It’s no fun if someone writes a bot to claim every good Workers subdomain in ten seconds; they Continue reading
Spectrum for UDP: DDoS protection and firewalling for unreliable protocols
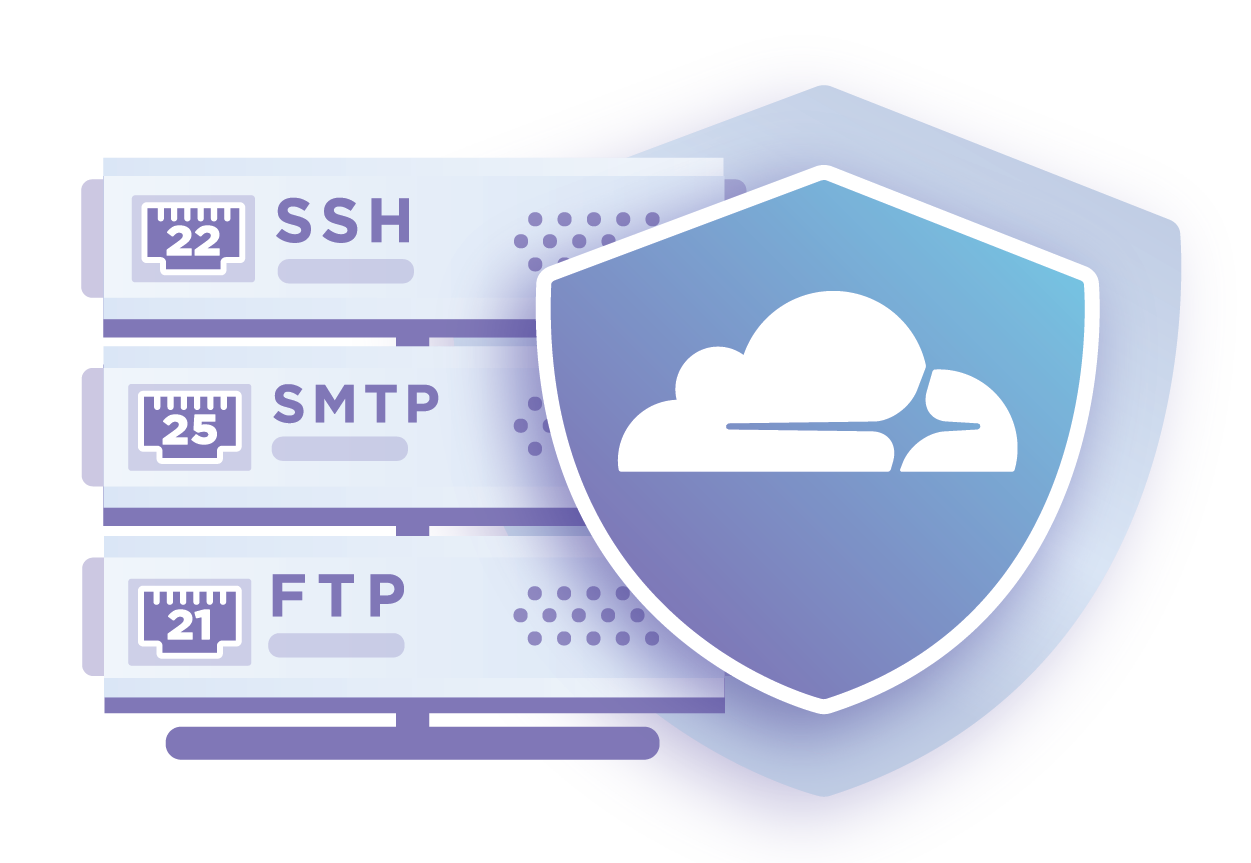
Today, we're announcing Spectrum for UDP. Spectrum for UDP works the same as Spectrum for TCP: Spectrum sits between your clients and your origin. Incoming connections are proxied through, whilst applying our DDoS protection and IP Firewall rules. This allows you to protect your services from all sorts of nasty attacks and completely hides your origin behind Cloudflare.
Last year, we launched Spectrum. Spectrum brought the power of our DDoS and firewall features to all TCP ports and services. Spectrum for TCP allows you to protect your SSH services, gaming protocols, and as of last month, even FTP servers. We’ve seen customers running all sorts of applications behind Spectrum, such as Bitfly, Nicehash, and Hypixel.
This is great if you're running TCP services, but plenty of our customers also have workloads running over UDP. As an example, many multiplayer games prefer the low cost and lighter weight of UDP and don't care about whether packets arrive or not.
UDP applications have historically been hard to protect and secure, which is why we built Spectrum for UDP. Spectrum for UDP allows you to protect standard UDP services (such as RDP over UDP), but can also protect any custom protocol Continue reading
Preventing Request Loops Using CDN-Loop
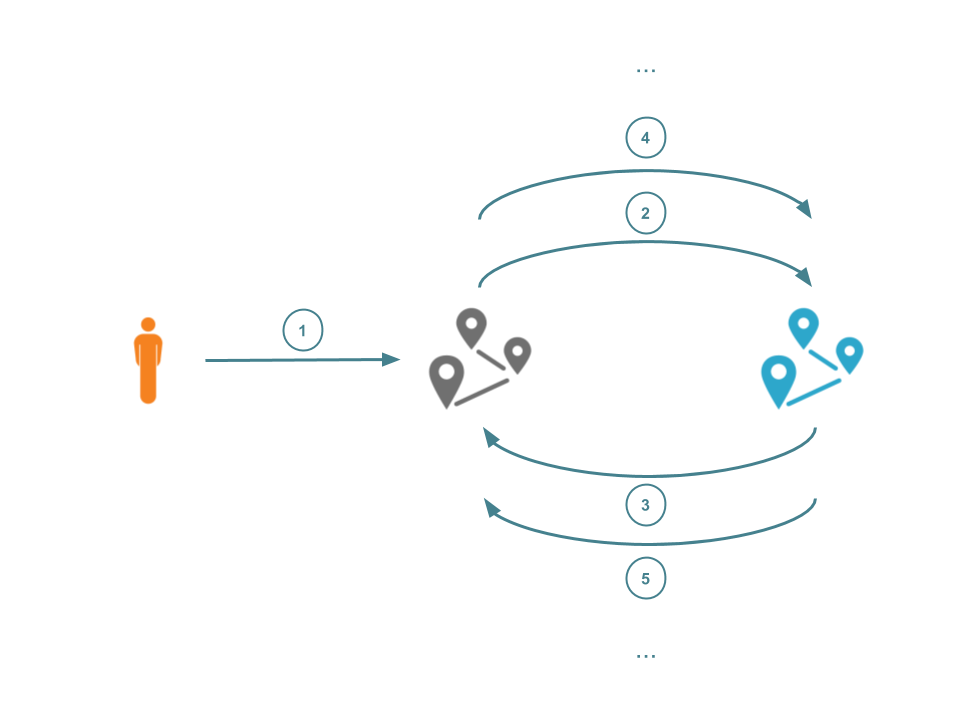
HTTP requests typically originate with a client, and end at a web server that processes the request and returns some response. Such requests may pass through multiple proxies before they arrive at the requested resource. If one of these proxies is configured badly (for instance, back to a proxy that had already processed it) then the request may be caught in a loop.
Request loops, accidental or malicious, can consume resources and degrade user's Internet performance. Such loops can even be observed at the CDN-level. Such a wide-scale attack would affect all customers of that CDN. It's been over three years since Cloudflare acknowledged the power of such non-compliant or malicious request loops. The proposed solution in that blog post was quickly found to be flawed and loop protection has since been implemented in an ad-hoc manner that is specific to each individual provider. This lack of cohesion and co-operation has led to a fragmented set of protection mechanisms.
We are finally happy to report that a recent collaboration between multiple CDN providers (including Cloudflare) has led to a new mechanism for loop protection. This now runs at the Cloudflare edge and is compliant with other CDNs, allowing us to Continue reading
Monsters in the Middleboxes: Introducing Two New Tools for Detecting HTTPS Interception


The practice of HTTPS interception continues to be commonplace on the Internet. HTTPS interception has encountered scrutiny, most notably in the 2017 study “The Security Impact of HTTPS Interception” and the United States Computer Emergency Readiness Team (US-CERT) warning that the technique weakens security. In this blog post, we provide a brief recap of HTTPS interception and introduce two new tools:
- MITMEngine, an open-source library for HTTPS interception detection, and
- MALCOLM, a dashboard displaying metrics about HTTPS interception we observe on Cloudflare’s network.
In a basic HTTPS connection, a browser (client) establishes a TLS connection directly to an origin server to send requests and download content. However, many connections on the Internet are not directly from a browser to the server serving the website, but instead traverse through some type of proxy or middlebox (a “monster-in-the-middle” or MITM). There are many reasons for this behavior, both malicious and benign.
Types of HTTPS Interception, as Demonstrated by Various Monsters in the Middle
One common HTTPS interceptor is TLS-terminating forward proxies. (These are a subset of all forward proxies; non-TLS-terminating forward proxies forward TLS connections without any ability to inspect encrypted traffic). A TLS-terminating forward proxy sits Continue reading
RFC8482 – Saying goodbye to ANY
Ladies and gentlemen, I would like you to welcome the new shiny RFC8482, which effectively deprecates the DNS ANY query type. DNS ANY was a "meta-query" - think of it as a similar thing to the common A, AAAA, MX or SRV query types, but unlike these it wasn't a real query type - it was special. Unlike the standard query types, ANY didn't age well. It was hard to implement on modern DNS servers, the semantics were poorly understood by the community and it unnecessarily exposed the DNS protocol to abuse. RFC8482 allows us to clean it up - it's a good thing.
But let's rewind a bit.
Historical context
It all started in 2015, when we were looking at the code of our authoritative DNS server. The code flow was generally fine, but it was all peppered with naughty statements like this:
if qtype == "ANY" {
// special case
}
This special code was ugly and error prone. This got us thinking: do we really need it? "ANY" is not a popular query type - no legitimate software uses it (with the notable exception of qmail).

ANY is Continue reading
Unit Testing Worker Functions

If you were not aware, Cloudflare Workers lets you run Javascript in all 165+ of our Data Centers. We’re delighted to see some of the creative applications of Workers. As the use cases grow in complexity, the need to sanity check your code also grows.
More specifically, if your Worker includes a number of functions, it’s important to ensure each function does what it’s intended to do in addition to ensuring the output of the entire Worker returns as expected.
In this post, we’re going to demonstrate how to unit test Cloudflare Workers, and their individual functions, with Cloudworker, created by the Dollar Shave Club engineering team.
Dollar Shave Club is a Cloudflare customer, and they created Cloudworker, a mock for the Workers runtime, for testing purposes. We’re really grateful to them for this. They were kind enough to post on our blog about it.
This post will demonstrate how to abstract away Cloudworker, and test Workers with the same syntax you write them in.
Example Script
Before we get into configuring Cloudworker, let’s introduce the simple script we are going to test against in our example. As you can see this script contains two functions, both of Continue reading
Reflecting on my first year as Head of Cloudflare Asia

One year into my role as Head of Asia for Cloudflare, I wanted to reflect on what we’ve achieved, as well as where we are going next.
When I started, I spoke about growing our brand recognition in Asia and optimizing our reach to clients by building up teams and channel partners. I also mentioned a key reason behind my joining was Cloudflare’s mission to help build a better Internet and focus on democratizing Internet tools that were once only available to large companies. I’m delighted to share that we’ve made great progress and are in a strong position to continue our rapid growth. It’s been a wonderful year, and I’m thrilled that I joined the company.
There has been a lot going on in our business, as well as in the region. Let’s start with Cloudflare Asia.
Cloudflare Asia
Our Singapore team has swelled from 40 people from 11 countries to almost 100 people from 19 nations. Our team is as diverse as our client base and keeps the office lively and innovative.

Our Customers
The number of Asian businesses choosing to work with us has more than doubled. You can check out what Continue reading
Employee resource groups aren’t the answer, but they’re a first step
Why employee resource groups are important for building a great company culture but they're not enough.

Diversity and inclusion is a process. To achieve diversity and inclusion, it’s not enough to hire diverse candidates. Once hired, we must be welcomed by a safe and belonging culture, and our diverse perspectives must be honored by our coworkers.
Too many times we are approached by well-meaning companies eager to hire diverse candidates, only to look behind the curtain and discover a company culture where we will not feel safe to be ourselves, and where our perspectives will be ignored. Why would we choose to stay in such an environment? These are the companies where diverse employees leave just as quickly as they join.
Employee Resource Groups (ERGs) are an essential part of diversity and inclusion, especially as companies grow larger. Before being heard, or trying to change someone's mind, you need to feel safe.
ERGs serve as a safe haven for those with perspectives and experiences that are "diverse" compared to the company as a whole. They are a place to share stories, particular plights, and are a source of stress relief. A place where we can safely show up fully as Continue reading