Cloudflare incident on February 6, 2025
Multiple Cloudflare services, including our R2 object storage, were unavailable for 59 minutes on Thursday, February 6, 2025. This caused all operations against R2 to fail for the duration of the incident, and caused a number of other Cloudflare services that depend on R2 — including Stream, Images, Cache Reserve, Vectorize and Log Delivery — to suffer significant failures.
The incident occurred due to human error and insufficient validation safeguards during a routine abuse remediation for a report about a phishing site hosted on R2. The action taken on the complaint resulted in an advanced product disablement action on the site that led to disabling the production R2 Gateway service responsible for the R2 API.
Critically, this incident did not result in the loss or corruption of any data stored on R2.
We’re deeply sorry for this incident: this was a failure of a number of controls, and we are prioritizing work to implement additional system-level controls related not only to our abuse processing systems, but so that we continue to reduce the blast radius of any system- or human- action that could result in disabling any production service at Cloudflare.
Cloudflare’s commitment to advancing Public Sector security worldwide by pursuing FedRAMP High, IRAP, and ENS
Today, we announced our commitment to achieving the US Federal Risk and Authorization Management Program (FedRAMP) - High, Australian Infosec Registered Assessors Program (IRAP), and Spain’s Esquema Nacional de Seguridad (ENS) as part of Cloudflare for Government. As more and more essential services are being shifted to the Internet, ensuring that governments and regulated industries have industry standard tools is critical for ensuring their uptime, reliability and performance.
Cloudflare’s network spans more than 330 cities in over 120 countries, where we interconnect with approximately 13,000 network providers in order to provide a broad range of services to millions of customers. Our network is our greatest strength to provide resiliency, security, and performance. So instead of creating a siloed government network that has limited access to our products and services, we decided to build the unique government compliance capabilities directly into our platform from the very beginning. We accomplished this by delivering critical controls in three key areas: traffic processing, management, and metadata storage.
The benefit of running the same software across our entire network is that it enables us to leverage our global footprint, and then make smart choices about how to Continue reading
No hallucinations here: track the latest AI trends with expanded insights on Cloudflare Radar
During 2024’s Birthday Week, we launched an AI bot & crawler traffic graph on Cloudflare Radar that provides visibility into which bots and crawlers are the most aggressive and have the highest volume of requests, which crawl on a regular basis, and more. Today, we are launching a new dedicated “AI Insights” page on Cloudflare Radar that incorporates this graph and builds on it with additional metrics that you can use to understand AI-related trends from multiple perspectives. In addition to the traffic trends, the new section includes a view into the relative popularity of publicly available Generative AI services based on 1.1.1.1 DNS resolver traffic, the usage of robots.txt directives to restrict AI bot access to content, and open source model usage as seen by Cloudflare Workers AI.
Below, we’ll review each section of the new AI Insights page in more detail.
Tracking traffic trends for AI bots can help us better understand their activity over time. Initially launched in September 2024 on Radar’s Traffic page, the AI bot & crawler traffic graph has moved to the AI Insights page and provides visibility into traffic trends gathered globally over Continue reading
Preserving content provenance by integrating Content Credentials into Cloudflare Images
Today, we are thrilled to announce the integration of the Coalition for Content Provenance and Authenticity (C2PA) provenance standard into Cloudflare Images. Content creators and publishers can seamlessly preserve the entire provenance chain — from how an image was created and by whom, to every subsequent edit — across the Cloudflare network.
When you hear the word provenance, you might have flashbacks to your high school Art History class. In that context, it means that the artwork you see at the Met in New York really came from the artist in question and isn’t a fake. Its provenance is how that piece of physical art changed possession over time, from the original artist all the way to the museum.
Digital content provenance builds upon this concept. It helps you understand how a piece of digital media — images, videos, PDFs, and more — was created and subsequently edited. The provenance of a photo I posted on Instagram might look like this: I took the picture with my iPhone, performed an auto-magic edit using Apple Photos’ editing tools, uploaded it to Instagram, cropped it using Instagram’s editing tools, and then posted Continue reading
A diversity of downtime: the Q4 2024 Internet disruption summary
Cloudflare’s network spans more than 330 cities in over 120 countries, where we interconnect with over 13,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions at both a local and national level, as well as at a network level.
As we have noted in the past, this post is intended as a summary overview of observed and confirmed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter. A larger list of detected traffic anomalies is available in the Cloudflare Radar Outage Center.
In the third quarter we covered quite a few government-directed Internet shutdowns, including many intended to prevent cheating on exams. In the fourth quarter, however, we only observed a single government-directed shutdown, this one related to protests. Terrestrial cable cuts impacted connectivity in two African countries. As we have seen multiple times before, both unexpected power outages and rolling power outages following military action resulted in Internet disruptions. Violent storms and an earthquake Continue reading
Cloudflare meets new Global Cross-Border Privacy standards
Cloudflare proudly leads the way with our approach to data privacy and the protection of personal information, and we’ve been an ardent supporter of the need for the free flow of data across jurisdictional borders. So today, on Data Privacy Day (also known internationally as Data Protection Day), we’re happy to announce that we’re adding our fourth and fifth privacy validations, and this time, they are global firsts! Cloudflare is the first organisation to announce that we have been successfully audited against the brand new Global Cross-Border Privacy Rules (Global CBPRs) for data controllers and the Global Privacy Rules for Processors (Global PRP). These validations demonstrate our support and adherence to global standards that provide for privacy-respecting data flows across jurisdictions. Organizations that have been successfully audited will be formally certified when the certifications officially launch, which we expect to happen later in 2025.
Our participation in the Global CBPRs and Global PRP joins our roster of privacy validations: we were one of the first cybersecurity organizations to certify to the international privacy standard ISO 27701:2019 when it was published, and in 2022 we also certified to the cloud privacy certification, ISO 27018:2019. In 2023, we added our third Continue reading
Cloudflare thwarts over 47 million cyberthreats against Jewish and Holocaust educational websites
January 27 marks the International Holocaust Remembrance Day — a solemn occasion to honor the memory of the six million Jews who perished in the Holocaust, along with countless others who fell victim to the Nazi regime's campaign of hatred and intolerance. This tragic chapter in human history serves as a stark reminder of the catastrophic consequences of prejudice and extremism.
The United Nations General Assembly designated January 27 — the anniversary of the liberation of Auschwitz-Birkenau — as International Holocaust Remembrance Day. This year, we commemorate the 80th anniversary of the liberation of this infamous extermination camp.
As the world reflects on this dark period, a troubling resurgence of antisemitism underscores the importance of vigilance. This growing hatred has spilled into the digital realm, with cyberattacks increasingly targeting Jewish and Holocaust remembrance and educational websites — spaces dedicated to preserving historical truth and fostering awareness.
For this reason, here at Cloudflare, we began to publish annual reports covering cyberattacks that target these organizations. These cyberattacks include DDoS attacks as well as bot and application attacks. The insights and trends are based on websites protected by Cloudflare. This is our fourth report, and you can view our previous Holocaust Continue reading
Over 700 million events/second: How we make sense of too much data
Cloudflare's network provides an enormous array of services to our customers. We collect and deliver associated data to customers in the form of event logs and aggregated analytics. As of December 2024, our data pipeline is ingesting up to 706M events per second generated by Cloudflare's services, and that represents 100x growth since our 2018 data pipeline blog post.
At peak, we are moving 107 GiB/s of compressed data, either pushing it directly to customers or subjecting it to additional queueing and batching.
All of these data streams power things like Logs, Analytics, and billing, as well as other products, such as training machine learning models for bot detection. This blog post is focused on techniques we use to efficiently and accurately deal with the high volume of data we ingest for our Analytics products. A previous blog post provides a deeper dive into the data pipeline for Logs.
The pipeline can be roughly described by the following diagram.
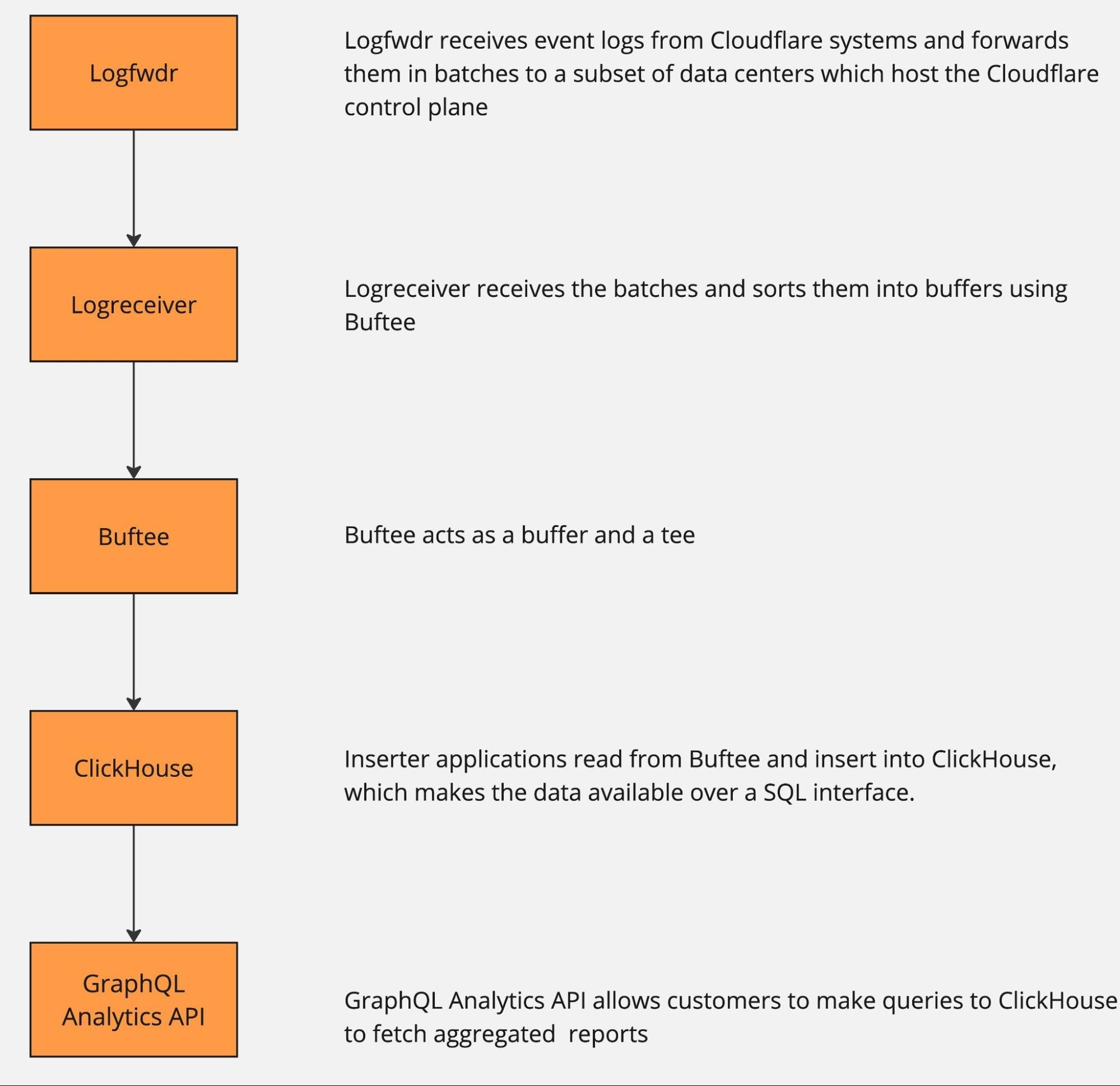
The data pipeline has multiple stages, and each can and will naturally break or slow down because of hardware failures or misconfiguration. And when that happens, there is just too much data to be able to Continue reading
Record-breaking 5.6 Tbps DDoS attack and global DDoS trends for 2024 Q4
Welcome to the 20th edition of the Cloudflare DDoS Threat Report, marking five years since our first report in 2020.
Published quarterly, this report offers a comprehensive analysis of the evolving threat landscape of Distributed Denial of Service (DDoS) attacks based on data from the Cloudflare network. In this edition, we focus on the fourth quarter of 2024 and look back at the year as a whole.
When we published our first report, Cloudflare’s global network capacity was 35 Terabits per second (Tbps). Since then, our network’s capacity has grown by 817% to 321 Tbps. We also significantly expanded our global presence by 65% from 200 cities in the beginning of 2020 to 330 cities by the end of 2024.
Using this massive network, we now serve and protect nearly 20% of all websites and close to 18,000 unique Cloudflare customer IP networks. This extensive infrastructure and customer base uniquely positions us to provide key insights and trends that benefit the wider Internet community.
In 2024, Cloudflare’s autonomous DDoS defense systems blocked around 21.3 million DDoS attacks, representing a 53% increase compared to 2023. On average, in 2024, Cloudflare blocked 4,870 Continue reading
The fall and rise of TikTok (traffic)
The United States ban on TikTok went into effect on January 19, 2025, and although service began to be restored after just 14 hours, it was only close to the inauguration of Donald Trump as the 47th President of the United States that associated DNS traffic started to recover to closer to previous levels. In this post, we analyze the events of January 19 and 20, and what they meant for TikTok-related DNS traffic, but also other competitors (including their growth outside the US).
For context, we wrote an initial blog post about the TikTok ban on Sunday, January 19, 2025. The ban was part of the "Protecting Americans from Foreign Adversary Controlled Applications Act," proposed in Congress, which ordered ByteDance to divest due to alleged security concerns. The bill was signed into law by Congress and President Biden in April 2024, and was upheld by the Supreme Court on January 17, 2025.
Aggregated data from our 1.1.1.1 DNS resolver shows — as we’ve posted on social media — that the TikTok shutdown in the US began to impact DNS traffic to TikTok-related domains on January 19, just after 03:30 UTC (22:30 ET on January Continue reading
TikTok ban takes hold: data reveals sharp traffic decline and rapid shift to alternatives
The United States ban on TikTok went into effect on January 19, 2025, and our data showed a clear impact starting after 03:30 UTC (10:30 PM ET on January 18, 2025). The ban was part of the "Protecting Americans from Foreign Adversary Controlled Applications Act," proposed in Congress, which ordered ByteDance to divest due to alleged security concerns. The bill was signed into law by Congress and President Biden in April 2024, and was upheld by the Supreme Court.
Aggregated data from our 1.1.1.1 DNS resolver shows — as we’ve posted on X — that the TikTok shutdown in the US began to impact DNS traffic to TikTok-related domains on January 19, just after 03:30 UTC (22:30 ET on January 18). This includes DNS traffic not only for TikTok, but also for other ByteDance-owned platforms, such as the CapCut video editor. Traffic dropped by as much as 85% compared to the previous week and showed signs of further decline in the following hours.

Around that time, a message indicating the TikTok ban began appearing for US users.

Analyzing data from autonomous systems or networks, traffic from TikTok owner ByteDance’s network (AS396986) in the US Continue reading
Demonstrating reduction of vulnerability classes: a key step in CISA’s “Secure by Design” pledge
In today’s rapidly evolving digital landscape, securing software systems has never been more critical. Cyber threats continue to exploit systemic vulnerabilities in widely used technologies, leading to widespread damage and disruption. That said, the United States Cybersecurity and Infrastructure Agency (CISA) helped shape best practices for the technology industry with their Secure-by-Design pledge. Cloudflare signed this pledge on May 8, 2024, reinforcing our commitment to creating resilient systems where security is not just a feature, but a foundational principle.
We’re excited to share an update aligned with one of CISA’s goals in the pledge: To reduce entire classes of vulnerabilities. This goal aligns with the Cloudflare Product Security program’s initiatives to continuously automate proactive detection and vigorously prevent vulnerabilities at scale.
Cloudflare’s commitment to the CISA pledge reflects our dedication to transparency and accountability to our customers. This blog post outlines why we prioritized certain vulnerability classes, the steps we took to further eliminate vulnerabilities, and the measurable outcomes of our work.
Cloudflare’s core security philosophy is to prevent security vulnerabilities from entering production environments. One of the goals for Cloudflare’s Product Security team is to champion this philosophy and ensure Continue reading
Open source all the way down: Upgrading our developer documentation
At Cloudflare, we treat developer content like a product, where we take the user and their feedback into consideration. We are constantly iterating, testing, analyzing, and refining content. Inspired by agile practices, treating developer content like an open source product means we approach our documentation the same way an open source software project is created and maintained. Open source documentation empowers the developer community because it allows anyone, anywhere, to contribute content. By making both the content and the framework of the documentation site publicly accessible, we provide developers with the opportunity to not only improve the material itself but also understand and engage with the processes that govern how the documentation is built, approved, and maintained. This transparency fosters collaboration, learning, and innovation, enabling developers to contribute their expertise and learn from others in a shared, open environment. We also provide feedback to other open source products and plugins, giving back to the same community that supports us.
Great documentation empowers users to be successful with a new product as quickly as possible, showing them how to use the product and describing its benefits. Relevant, timely, and accurate content can save Continue reading
Multi-Path TCP: revolutionizing connectivity, one path at a time
The Internet is designed to provide multiple paths between two endpoints. Attempts to exploit multi-path opportunities are almost as old as the Internet, culminating in RFCs documenting some of the challenges. Still, today, virtually all end-to-end communication uses only one available path at a time. Why? It turns out that in multi-path setups, even the smallest differences between paths can harm the connection quality due to packet reordering and other issues. As a result, Internet devices usually use a single path and let the routers handle the path selection.
There is another way. Enter Multi-Path TCP (MPTCP), which exploits the presence of multiple interfaces on a device, such as a mobile phone that has both Wi-Fi and cellular antennas, to achieve multi-path connectivity.
MPTCP has had a long history — see the Wikipedia article and the spec (RFC 8684) for details. It's a major extension to the TCP protocol, and historically most of the TCP changes failed to gain traction. However, MPTCP is supposed to be mostly an operating system feature, making it easy to enable. Applications should only need minor code changes to support it.
There is a caveat, however: MPTCP is still fairly immature, and while it can Continue reading
Behind the scenes with Stream Live, Cloudflare’s live streaming service
Cloudflare announced Stream Live for open beta in 2021, and in 2022 we went GA. While we talked about the experience of using it and the value it delivers to customers, we didn’t talk about how we built it. So let’s talk about Stream Live’s design, and how it leverages the distributed nature of Cloudflare’s network, rather than centralized locations as many other live services do. Ultimately, our goals are to keep our content ingest as close to broadcasters as possible, our content delivery as close to viewers as possible, and to retain our ability to handle unexpected use cases.
At a high level, Stream Live accepts audio/video content from broadcasters and makes that content available to viewers around the world in real time through the Cloudflare network, which reaches more than 330 cities in over 120 countries. Hence, there are two sides to this: ingesting data from broadcasters and delivering encoded content to viewers. Both sides are built on a combination of internal systems and Cloudflare products, including Cloudflare Workers, Durable Objects, Spectrum, and, of course, Cache.
Let’s start on the ingest side.
Broadcasters generate content in real time, as a Continue reading
The forecast is clear: clouds on e-paper, powered by the cloud
I’ve noticed that many shops are increasingly using e-paper displays. They’re impressive: high contrast, no backlight, and no visible cables. Unlike most electronics, these displays are seamlessly integrated and feel very natural. This got me wondering: is it possible to use such a display for a pet project? I want to experiment with this technology myself.

(source)
My main goal in this project is to understand the hardware and its capabilities. Here, I'll be using an e-paper display to show the current weather, but at its core, I’m simply feeding data from a website to the display. While it sounds straightforward, it actually requires three layers of software to pull off. Still, it’s a fun challenge and a great opportunity to work with both embedded hardware and Cloudflare Workers.
For this project, I'm using components from Waveshare. They offer a variety of e-paper displays, ranging from credit card-sized to A4-sized models. I chose the 7.5-inch, two-color "e-Paper (G)" display. For the controller, I'm using a Waveshare ESP32-based universal board. With just these two components — a display and a controller — I was ready to get started.

When the components arrived, I carefully Continue reading
Open sourcing h3i: a command line tool and library for low-level HTTP/3 testing and debugging
Have you ever built a piece of IKEA furniture, or put together a LEGO set, by following the instructions closely and only at the end realized at some point you didn't quite follow them correctly? The final result might be close to what was intended, but there's a nagging thought that maybe, just maybe, it's not as rock steady or functional as it could have been.
Internet protocol specifications are instructions designed for engineers to build things. Protocol designers take great care to ensure the documents they produce are clear. The standardization process gathers consensus and review from experts in the field, to further ensure document quality. Any reasonably skilled engineer should be able to take a specification and produce a performant, reliable, and secure implementation. The Internet is central to everyone's lives, and we depend on these implementations. Any deviations from the specification can put us at risk. For example, mishandling of malformed requests can allow attacks such as request smuggling.
h3i is a binary command line tool and Rust library designed for low-level testing and debugging of HTTP/3, which runs over QUIC. h3i is free and open source as part of Cloudflare's quiche project. In this post we'll Continue reading
What’s new in Cloudflare: MASQUE now powers 1.1.1.1 & WARP apps, DEX now generally available with Remote Captures
At Cloudflare, we are constantly innovating and launching new features and capabilities across our product portfolio. Today’s roundup blog post shares two exciting updates across our platform: our cross-platform 1.1.1.1 & WARP applications (consumer) and device agents (Zero Trust) now use MASQUE, a cutting-edge HTTP/3-based protocol, to secure your Internet connection. Additionally, DEX is now available for general availability.

We’re excited to announce that as of today, our cross-platform 1.1.1.1 & WARP apps now use MASQUE, a cutting-edge HTTP/3-based protocol, to secure your Internet connection.
As a reminder, our 1.1.1.1 & WARP apps have two main functions: send all DNS queries through 1.1.1.1, our privacy-preserving DNS resolver, and protect your device’s network traffic via WARP by creating a private and encrypted tunnel to the resources you’re accessing, preventing unwanted third parties or public Wi-Fi networks from snooping on your traffic.
There are many ways to encrypt and proxy Internet traffic — you may have heard of a few, such as IPSec, WireGuard, or OpenVPN. There are many tradeoffs Continue reading
Sometimes I cache: implementing lock-free probabilistic caching
HTTP caching is conceptually simple: if the response to a request is in the cache, serve it, and if not, pull it from your origin, put it in the cache, and return it. When the response is old, you repeat the process. If you are worried about too many requests going to your origin at once, you protect it with a cache lock: a small program, possibly distinct from your cache, that indicates if a request is already going to your origin. This is called cache revalidation.
In this blog post, we dive into how cache revalidation works, and present a new approach based on probability. For every request going to the origin, we simulate a die roll. If it’s 6, the request can go to the origin. Otherwise, it stays stale to protect our origin from being overloaded. To see how this is built and optimised, read on.
Let's take the example of an online image library. When a client requests an image, the service first checks its cache to see if the resource is present. If it is, it returns it. If it is not, the image server processes the request, places the response into the Continue reading
Un experimento rápido: translating Cloudflare Stream captions with Workers AI
Cloudflare Stream launched AI-powered automated captions to transcribe English in on-demand videos in March 2024. Customers' immediate next questions were about other languages — both transcribing audio from other languages, and translating captions to make subtitles for other languages. As the Stream Product Manager, I've thought a lot about how we might tackle these, but I wondered…
What if I just translated a generated VTT (caption file)? Can we do that? I hoped to use Workers AI to conduct a quick experiment to learn more about the problem space, challenges we may find, and what platform capabilities we can leverage.
There is a sample translator demo in Workers documentation that uses the “m2m100-1.2b” Many-to-Many multilingual translation model to translate short input strings. I decided to start there and try using it to translate some of the English captions in my Stream library into Spanish.
I started with my short demo video announcing the transcription feature. I wanted a Worker that could read the VTT captions file from Stream, isolate the text content, and run it through the model as-is.
The first step was parsing the input. A VTT file is a text file that Continue reading