Tech Bytes: High Performance, Scalable Object Storage with MinIO (Sponsored)
Today on the Tech Bytes podcast we talk with Jonathan Symonds, Chief Marketing Officer at MinIO about MinIO’s object storage offering; a software-defined, Amazon S3-compatible object storage that offers high performance and scale for modern workloads and AI/ML. We discuss how MinIO helps customers across industries drive AI innovation and AI architectures, how object storage... Read more »French elections: political cyber attacks and Internet traffic shifts
The 2024 French legislative election runoff on July 7 yielded surprising results compared to the first round on June 30, with the New Popular Front (NPF) gaining the most seats, followed by French President Macron’s Ensemble party, and the National Rally. Coalition negotiations will follow. In this post, we examine the ongoing online attacks against French political parties and how initial election predictions at 20:00 local time led to a noticeable drop in France’s Internet traffic.
This blog post is part of a series tracking the numerous elections of 2024. We have covered elections in South Africa, India, Iceland, Mexico, the European Union, the UK and also the 2024 US presidential debate. We also continuously update our election report on Cloudflare Radar.
Let’s start with the attacks, and then move on to the Internet traffic trends.
Political parties under attack
As we highlighted last week, the first round of the French elections saw specific DDoS (Distributed Denial of Service) attacks targeting French political party websites. While online attacks are common and not always election-related, recent activities in France, the Netherlands, and the UK confirm that DDoS attacks frequently target political parties during election Continue reading
NB486: Chrome Ditches Entrust Certs; Do AI Stocks Mirror the DotCom Bubble?
Take a Network Break! This week we cover why the Google Chrome browser won’t trust a set of Entrust digital certificates come November and what you should do about it, an emergency security patch from Juniper, and the reasons why France’s Competition Authority is scrutinizing Nvidia. A roaming provider in the EU says a massive... Read more »Why Do We Have Native VLANs?
Recently, my friend Andy Lapteff asked an excellent question. Why do we have native VLANs? As in, why allow untagged frames on a trunk link?
There was a time where we didn’t have VLANs. At first there was hubs, then bridges, multi-port bridges, and finally switches. Cisco was one of the first vendors to introduce VLANs, even before it became a standard, through the use of Inter Switch Links (ISL). ISL is long gone and encapsulated the entire Ethernet frame so native VLANs were not relevant there. In 1998, the 802.1Q standard was released.
In 802.1Q, 1.2 VLAN aims and benefits, the following is described:
a) VLANs are supported over all IEEE 802 LAN MAC protocols, and over shared media LANs as well as point-to-point LANs.
b) VLANs facilitate easy administration of logical groups of stations that can communicate as if they were on the same LAN. They also facilitate easier administration of moves, adds, and changes in members of these groups.
c) Traffic between VLANs is restricted. Bridges forward unicast, multicast, and broadcast traffic only
on LAN segments that serve the VLAN to which the traffic belongs.
d) As far as possible, VLANs maintain compatibility Continue reading
BGP Labs: a Year Later
Last summer, I started a long-term project to revive the BGP labs I created in the mid-1990s. I completed the original lab exercises (BGP sessions, IBGP, local preference, MED, communities) in late 2023 but then kept going. This is how far I got in a year:
- Twenty-six deploy BGP exercises, including advanced settings like AS path manipulations, MD5 passwords and BFD, and new technologies like TCP/AO and interface EBGP sessions.
- Fifteen BGP routing policies exercises, covering the basic mechanisms as well as dirty tricks like route disaggregation
- Four load balancing exercises, from EBGP ECMP to BGP Link Bandwidth and BGP Additional Paths.
- Five challenges for everyone who got bored doing the simple stuff ;)
That completes the BGP technologies I wanted to cover. I’ll keep adding the challenge labs and advanced scenarios. Here are some ideas; if you have others, please leave a comment.
blog.ipspace.net Is On Cloudflare Pages
Long story short: Years after migrating my blog to Hugo, I found the willpower to deal with the “interesting” way Cloudflare Pages deal with static HTML files, changed the Hugo URL scheme, and spent two days fixing broken links.
Apart from having the satisfaction of ticking off a long-outstanding project, the blog pages should load faster, and I won’t have to deal with GitLab hiccups anymore.
If you notice anything being broken, please let me know. Thank you!
Hedge 233: Making Heat Productive

Data centers turn large amounts of electricity into heat. Is it possible to recover even some part of this heat rather than throwing it off into the local environment? David Krebs of masterresource.org brings his vast experience with using heat from engines to bear on the problem to propose solutions.

Palo Alto – Remove Unused Address Objects Using Pan-OS-PHP

If you’ve worked with Palo Alto firewalls, you might have noticed they don’t make it easy to get rid of unused address objects. It seems like such a basic feature should be included, right? While you could use Expedition for this, it requires setting up a separate server and learning a new tool, which might be more hassle than it’s worth.
I’ve talked before about using a simple Python script to clean up unused address objects (link below), but it was pretty basic and I didn't take many scenarios into account. Today, I want to show you an even easier more sophisticated way to handle this using Pan-OS-PHP. This tool is fantastic because you can use it directly from the command line. You don’t need to know any PHP to get started. Let’s look at how this can make managing your firewall a lot easier.
Palo Alto Firewall - Find and Remove Unused Address Objects
In this blog post, I’ll show you a very simple Python script to find unused address objects from the Palo Alto firewall or Panorama and remove them if needed.
 Suresh Vina
Suresh Vina
ℹ️
Disclaimer - Please proceed with caution when using automated scripts for configuration Continue reading
Terraform for Network Engineers: Part Two

Before diving in, if you haven’t read the first part of this series, I highly recommend starting there. In the introductory post, we covered the basics of Terraform and explored how network engineers can leverage it.
In part two, we will:
- Explore the provider documentation for Panorama.
- Set up our project and create some resources and go through the Terraform workflow.
- Review the state file.
- Reflect on our achievements so far: Have we made our lives easier?
Provider Documentation
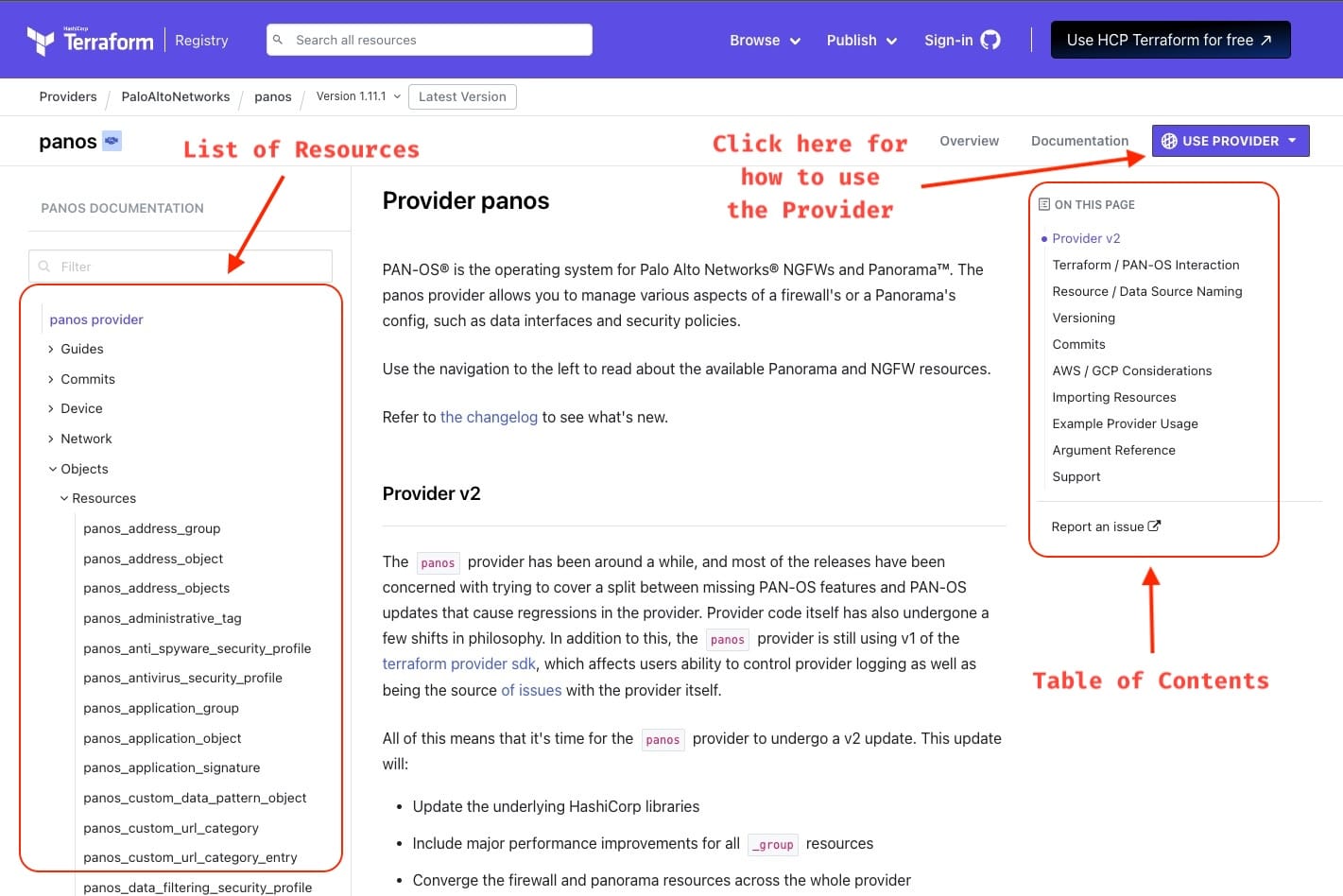
All Terraform providers have their documentation available on the Terraform website, following a similar structure.The Panorama provider documentation can be found here.
Here are a couple of screenshots highlighting the key sections of the Panorama provider documentation.
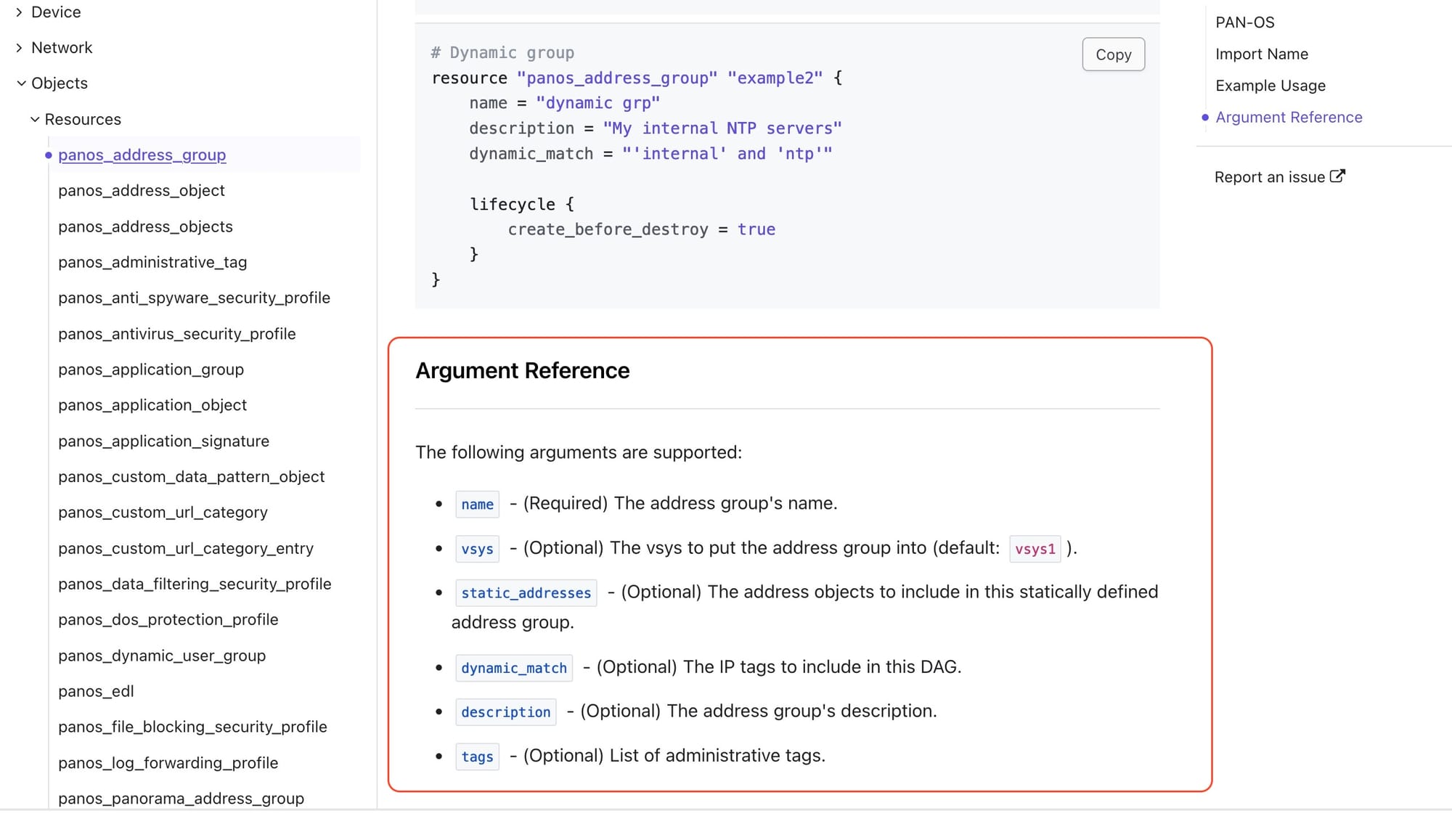
If you drill down into a Resource, you can find how the configuration block would look and what are the arguments you can pass to it.
Project Setup and Workflow
We'll set up all the files and folders needed to create resources on Panorama using Terraform. I prefer to keep my Terraform projects organized. Below is the structure I typically follow for my projects.
mkdir tf-neteng
cd tf-neteng
touch Continue readingCalico monthly roundup: June 2024
Welcome to the Calico monthly roundup: June edition! From open source news to live events, we have exciting updates to share—let’s get into it!
S&P Global 451 Market Insight: Tigera Provides Most Comprehensive CNAPP
Learn how Tigera differentiates itself from competitors by focusing on runtime security, aligning with the rapidly growing market category and how it is one of the strong players in this segment. |
Your Guide to Observability
This guide explains what observability is and shows you how to use Calico’s observability tools. With these tools, you can find and troubleshoot issues with workload communications, performance, and operations in a Kubernetes cluster.Read case study. |
Customer case study: eHealth
Calico helped eHealth gain visibility and implement zero-trust security controls on Amazon EKS. Read the case study to learn more. |
Open source news
Kubernetes network policies: 4 pain points and how to address them – Learn about the challenges of implementing Kubernetes network policies and how to simplify their management and enhance security using Calico. Read blog post.
The power of Kubevirt and Calico – Unlock the combined power of Kubevirt and Calico for your Kubernetes environments. Learn how to streamline VM management, Continue reading
UK election day 2024: traffic trends and attacks on political parties

The 2024 UK general election, the first since Brexit officially began (January 31, 2020) and after 14 years of Conservative leadership, saw the Labour Party secure a majority. This blog post examines Internet traffic trends and cyberattack activity on election day, highlighting notable declines in traffic during the afternoon and evening as well as a DDoS attack on a political party shortly after polls closed.
For context, 2024 is considered “the year of elections,” with elections taking place in over 60 countries. We’ve covered elections in South Africa, India, Iceland, Mexico, the European Union, France, and also the 2024 US presidential debate. We also continuously update our election report on Cloudflare Radar.
The UK’s snap election on Thursday, July 4, 2024, typical of British Thursday weekday elections, contrasts with weekend elections in other countries. Polling stations were open from 07:00 to 22:00.
Generally, election days do not result in drastic changes to Internet traffic. Traffic typically dips during voting hours but not as sharply as during major events like national holidays, and rises in the evening as results are announced.
On July 4, 2024, traffic initially rose slightly from the previous week, then fell around noon Continue reading
Review: R86S (Jasper Lake – N6005)
Introduction

I am always interested in finding new hardware that is capable of running VPP. Of course, a standard
issue 19” rack mountable machine like a Dell, HPE or SuperMicro machine is an obvious choice. They
come with redundant power supplies, PCIe v3.0 or better expansion slots, and can boot off of mSATA
or NVME, with plenty of RAM. But for some people and in some locations, the power envelope or
size/cost of these 19” rack mountable machines can be prohibitive. Sometimes, just having a smaller
form factor can be very useful:
Enter the GoWin R86S!

I stumbled across this lesser known build from GoWin, which is an ultra compact but modern design, featuring three 2.5GbE ethernet ports and optionally two 10GbE, or as I’ll show here, two 25GbE ports. What I really liked about the machine is that it comes with 32GB of LPDDR4 memory and can boot off of an m.2 NVME – which makes it immediately an appealing device to put in the field. I noticed that the height of the machine is just a few millimeters smaller than 1U which is 1.75” (44.5mm), which gives me the bright idea to 3D Continue reading
Cloudflare 1.1.1.1 incident on June 27, 2024

Introduction
On June 27, 2024, a small number of users globally may have noticed that 1.1.1.1 was unreachable or degraded. The root cause was a mix of BGP (Border Gateway Protocol) hijacking and a route leak.
Cloudflare was an early adopter of Resource Public Key Infrastructure (RPKI) for route origin validation (ROV). With RPKI, IP prefix owners can store and share ownership information securely, and other operators can validate BGP announcements by comparing received BGP routes with what is stored in the form of Route Origin Authorizations (ROAs). When Route Origin Validation is enforced by networks properly and prefixes are signed via ROA, the impact of a BGP hijack is greatly limited. Despite increased adoption of RPKI over the past several years and 1.1.1.0/24 being a signed resource, during the incident 1.1.1.1/32 was originated by ELETRONET S.A. (AS267613) and accepted by multiple networks, including at least one Tier 1 provider who accepted 1.1.1.1/32 as a blackhole route. This caused immediate unreachability for the DNS resolver address from over 300 networks in 70 countries was impacted, although the impact on the overall percentage of users was quite Continue reading
MUST READ: ChatGPT Is Bullshit
Bogdan Golab sent me a link to an (open access) article in Ethics and Information Technology arguing why ChatGPT is bullshit. Straight from the introduction:
Because these programs cannot themselves be concerned with truth, and because they are designed to produce text that looks truth-apt without any actual concern for truth, it seems appropriate to call their outputs bullshit.
Have fun!
D2C246: Can Service Level Objectives (SLOs) Help Keep Users Happy?
Service Level Objectives (SLOs) are a set of reliability measurements for customer or user expectations of services; in other words, are people having a good experience with your application or service? Today’s Day Two Cloud explores SLOs, the relevant metrics, and how to measure them. We also talk about how SLOs are a cross-discipline objective... Read more »First round of French election: party attacks and a modest traffic dip
This post is also available in Français.

France is currently electing a new government through early legislative elections that began on Sunday, June 30, 2024, with a second round scheduled for July 7. In this blog, we show how Cloudflare blocked DDoS attacks targeting three different French political parties.
2024 has been dubbed “the year of elections,” with elections taking place in over 60 countries, as we have mentioned before (1, 2, 3). If you regularly follow the Cloudflare blog, you’re aware that we consistently cover election-related trends, including in South Africa, India, Iceland, Mexico, the European Union and the 2024 US presidential debate. We also continuously update our election report on Cloudflare Radar.
Recently in France, as in the early stages of the war in Ukraine and during EU elections in the Netherlands, political events have precipitated cyberattacks. In France, several DDoS (Distributed Denial of Service attack) attacks targeted political parties involved in the elections over the past few days, with two parties hit just before the first round and another on election day itself.

The first political party, shown in yellow in the previous chart, experienced a DDoS attack on Continue reading
Declare your AIndependence: block AI bots, scrapers and crawlers with a single click

To help preserve a safe Internet for content creators, we’ve just launched a brand new “easy button” to block all AI bots. It’s available for all customers, including those on our free tier.
The popularity of generative AI has made the demand for content used to train models or run inference on skyrocket, and, although some AI companies clearly identify their web scraping bots, not all AI companies are being transparent. Google reportedly paid $60 million a year to license Reddit’s user generated content, Scarlett Johansson alleged OpenAI used her voice for their new personal assistant without her consent, and most recently, Perplexity has been accused of impersonating legitimate visitors in order to scrape content from websites. The value of original content in bulk has never been higher.
Last year, Cloudflare announced the ability for customers to easily block AI bots that behave well. These bots follow robots.txt, and don’t use unlicensed content to train their models or run inference for RAG applications using website data. Even though these AI bots follow the rules, Cloudflare customers overwhelmingly opt to block them.

We hear clearly that customers don’t want AI bots visiting their websites, and especially those that do Continue reading
MUST READ: ChatGPT Is Bullshit
Bogdan Golab sent me a link to an (open access) article in Ethics and Information Technology arguing why ChatGPT is bullshit. Straight from the introduction:
Because these programs cannot themselves be concerned with truth, and because they are designed to produce text that looks truth-apt without any actual concern for truth, it seems appropriate to call their outputs bullshit.
Have fun!