Registration No Longer Needed to Download Free PDFs
I published dozens of free-to-download slide decks on ipSpace.net. Downloading them required the free ipSpace.net subscription which is no longer available because I refuse to play a whack-a-mole game with spammers.
You might like the workaround I had to implement to keep those PDFs accessible: they are no longer behind a regwall.
You can find the list of all the free content ipSpace.net content here. The Conferences and Presentations page is another source of links to public presentations.
Registration No Longer Needed to Download Free PDFs
I published dozens of free-to-download slide decks on ipSpace.net. Downloading them required the free ipSpace.net subscription which is no longer available because I refuse to play a whack-a-mole game with spammers.
You might like the workaround I had to implement to keep those PDFs accessible: they are no longer behind a regwall.
You can find the list of all the free content ipSpace.net content here. The Conferences and Presentations page is another source of links to public presentations.
AI Data Centers Need High-performance Networks: HPE to Acquire Juniper Networks
AI has forced many enterprises to re-evaluate their network infrastructure. HPE’s acquisition of Juniper Networks seeks to focus on meeting the performance needs of AI data centers.HW018: Building a Successful Wi-Fi Consulting Business
Wi-Fi consultant Rowell Dionicio shares his experiences and insights on building a successful consulting practice. He discusses the importance of niche specialization, creating educational content, and using his podcast and blog as marketing tools. Rowell highlights the need for continuous learning, effective communication, and networking. He also addresses the business side of consulting, including handling... Read more »Making Networking Cool Again? (1)
Is network engineering still cool?
It certainly doesn’t seem like it, does it? College admissions seem to be down in the network engineering programs I know of, and networking certifications seem to be down, too. Maybe we’ve just passed the top of the curve, and computer networking skills are just going the way of coopering. Let’s see if we can sort out the nature of this malaise and possible solutions. Fair warning—this is going to take more than one post.
Let’s start here: It could be that computer networking is a solved problem, and we just don’t need network engineers any longer.
I’ve certainly heard people say these kinds of things—for instance, one rather well-known network engineer said, just a few years back, that network engineers would no longer be needed in five years. According to this view, the entire network should be like a car. You get in, turn the key, and it “just works.” There shouldn’t be any excitement or concern about a commodity like transporting packets. Another illustration I’ve heard used is “network bandwidth should just be like computer memory—if you need more, add it.”
Does this really hold, though? Even if we accept the Continue reading
Top 10 Reasons to Consider Replacing Your Existing SD-WAN
If your goal is to evolve to a converged networking and security infrastructure, follow these guidelines and consider upgrading your SD-WAN.Raspberry Pi 5 real-time network analytics
 |
| CanaKit Raspberry Pi 5 Starter Kit - Aluminum |




ssh [email protected]Use ssh to log into Raspberry Pi (having installled the micro SD card).
sudo apt-get update && sudo apt-get -y upgradeUpdate packages and OS to latest version.
curl Continue reading
VXLAN/EVPN – Host mobility
In the previous post VXLAN/EVPN – Host ARP, I talked about how knowing the MAC/IP of endpoints allows for ARP suppression. In this post we’ll take a look at host mobility. The topology used is the same as in the previous post:
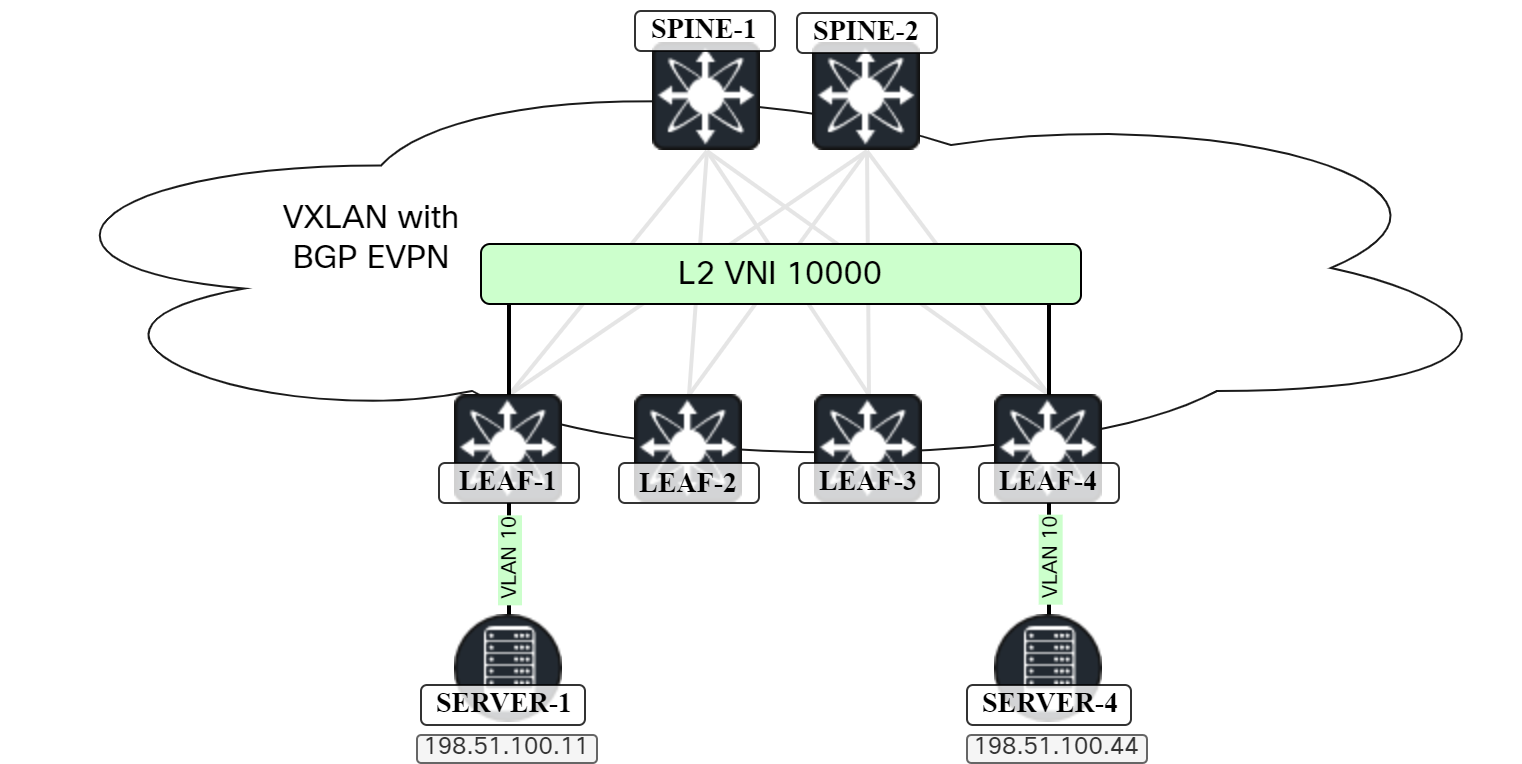
Currently SERVER-1 is connected to LEAF-1. What happens if SERVER-1 moves to LEAF-2? This would be a common scenario for a virtual infrastructure. First let’s take a look at LEAF-4 on what routes we have for SERVER-1:
Leaf4# show bgp l2vpn evpn 0050.56ad.8506
BGP routing table information for VRF default, address family L2VPN EVPN
Route Distinguisher: 192.0.2.3:32777
BGP routing table entry for [2]:[0]:[0]:[48]:[0050.56ad.8506]:[0]:[0.0.0.0]/216, version 662
Paths: (2 available, best #2)
Flags: (0x000202) (high32 00000000) on xmit-list, is not in l2rib/evpn, is not in HW
Path type: internal, path is valid, not best reason: Neighbor Address, no labeled nexthop
AS-Path: NONE, path sourced internal to AS
203.0.113.1 (metric 81) from 192.0.2.12 (192.0.2.2)
Origin IGP, MED not set, localpref 100, weight 0
Received label 10000
Extcommunity: RT:65000:10000 ENCAP:8
Originator: 192.0.2.3 Cluster list: 192.0.2.2
Advertised Continue reading
NB461: 2024 Trends – AI Beyond LLMs, Cisco Vs. Everybody, Next-Gen IT Workers, And More
Take a Network Break! We start the new year by examining major themes and trends that we think will affect IT and networking in 2024. Topics include: AI beyond LLMs Whether open source can remain a viable model in a predatory tech environment Cisco vs. everybody Why IT can’t ignore geopolitics for strategic planning What... Read more »DDoS threat report for 2023 Q4
This post is also available in Deutsch and Français.

Welcome to the sixteenth edition of Cloudflare’s DDoS Threat Report. This edition covers DDoS trends and key findings for the fourth and final quarter of the year 2023, complete with a review of major trends throughout the year.
What are DDoS attacks?
DDoS attacks, or distributed denial-of-service attacks, are a type of cyber attack that aims to disrupt websites and online services for users, making them unavailable by overwhelming them with more traffic than they can handle. They are similar to car gridlocks that jam roads, preventing drivers from getting to their destination.
There are three main types of DDoS attacks that we will cover in this report. The first is an HTTP request intensive DDoS attack that aims to overwhelm HTTP servers with more requests than they can handle to cause a denial of service event. The second is an IP packet intensive DDoS attack that aims to overwhelm in-line appliances such as routers, firewalls, and servers with more packets than they can handle. The third is a bit-intensive attack that aims to saturate and clog the Internet link causing that ‘gridlock’ that we discussed. In this report, we Continue reading
Introducing Cloudflare’s 2024 API security and management report
This post is also available in 日本語, 简体中文, 한국어, Français, 繁體中文, Español, Português.
You may know Cloudflare as the company powering nearly 20% of the web. But powering and protecting websites and static content is only a fraction of what we do. In fact, well over half of the dynamic traffic on our network consists not of web pages, but of Application Programming Interface (API) traffic — the plumbing that makes technology work. This blog introduces and is a supplement to the API Security Report for 2024 where we detail exactly how we’re protecting our customers, and what it means for the future of API security. Unlike other industry API reports, our report isn’t based on user surveys — but instead, based on real traffic data.
If there’s only one thing you take away from our report this year, it’s this: many organizations lack accurate API inventories, even when they believe they can correctly identify API traffic. Cloudflare helps organizations discover all of their public-facing APIs using two approaches. First, customers configure our API discovery tool to monitor for identifying tokens present in their known API traffic. We then use a machine learning model Continue reading
2023年第4四半期DDoS脅威レポート

CloudflareのDDoS脅威レポート第16版へようこそ。本版では、2023年第4四半期および最終四半期のDDoS動向と主要な調査結果について、年間を通じた主要動向のレビューとともにお届けします。
DDoS攻撃とは?
DDoS攻撃(分散型サービス妨害攻撃)とは、Webサイトやオンラインサービスを混乱させることを目的としたサイバー攻撃の一種で、処理能力を超えるトラフィックで圧倒することでユーザーが利用不能になります。DDoS攻撃は、道路を渋滞させ、ドライバーが目的地にたどり着けなくする車の渋滞に似ています。
このレポートで取り上げるDDoS攻撃には、主に3つのタイプがあります。1つ目はHTTPリクエスト集中型DDoS攻撃で、HTTPサーバーを処理能力を超えるリクエストで圧倒し、サービス妨害イベントを引き起こすことを狙います。2つ目はIPパケット集中型のDDoS攻撃で、ルーターやファイアウォール、サーバーなどのインラインアプライアンスを、処理能力を超えるパケットで圧倒することを狙います。3つ目は、ビット集中型の攻撃で、インターネット・リンクを飽和させ、詰まらせることを目的とし、前述の「グリッドロック」(渋滞)を引き起こします。このレポートでは、この3つのタイプの攻撃に関するさまざまなテクニックと洞察を紹介します。
また、このレポートの前の版はこちらまたは当社のインタラクティブハブであるCloudflare Radarでご覧いただけます。Cloudflare Radarは、世界のインターネットトラフィック、攻撃、テクノロジーのトレンドと洞察を紹介し、特定の国、業界、サービスプロバイダーの洞察を掘り下げるための検索・フィルタリング機能を備えています。また、Cloudflare Radarは無料のAPIも提供しており、学者、データ調査者、その他Webの愛好家が世界中のインターネット利用状況を調査することができます。
本レポートの作成方法については、「メソドロジー」を参照してください。
主な調査結果
- 第4四半期には、ネットワーク層のDDoS攻撃が前年同期比で117%増加し、ブラックフライデーとホリデーシーズン前後には、小売、出荷、広報のWebサイトを標的としたDDoS攻撃が全体的に増加しました。
- 第4四半期には、総選挙を控え、中国との緊張が伝えられる中、台湾を標的としたDDoS攻撃トラフィックが前年比3,370%増となりました。イスラエルとハマスの軍事衝突が続く中、イスラエルのWebサイトを標的としたDDoS攻撃トラフィックの割合は前四半期比で27%増加し、パレスチナのWebサイトを標的としたDDoS攻撃トラフィックの割合は前四半期比で1,126%増加しました。
- 第4四半期には、第28回国連気候変動会議(COP28)が開催されたこともあり、環境サービスWebサイトを標的にしたDDoS攻撃トラフィックが前年比61,839%という驚異的な急増を見せました。
これらの主要な調査結果の詳細な分析と、現在のサイバーセキュリティの課題に対する理解を再定義するその他の洞察については、こちらをお読みください!
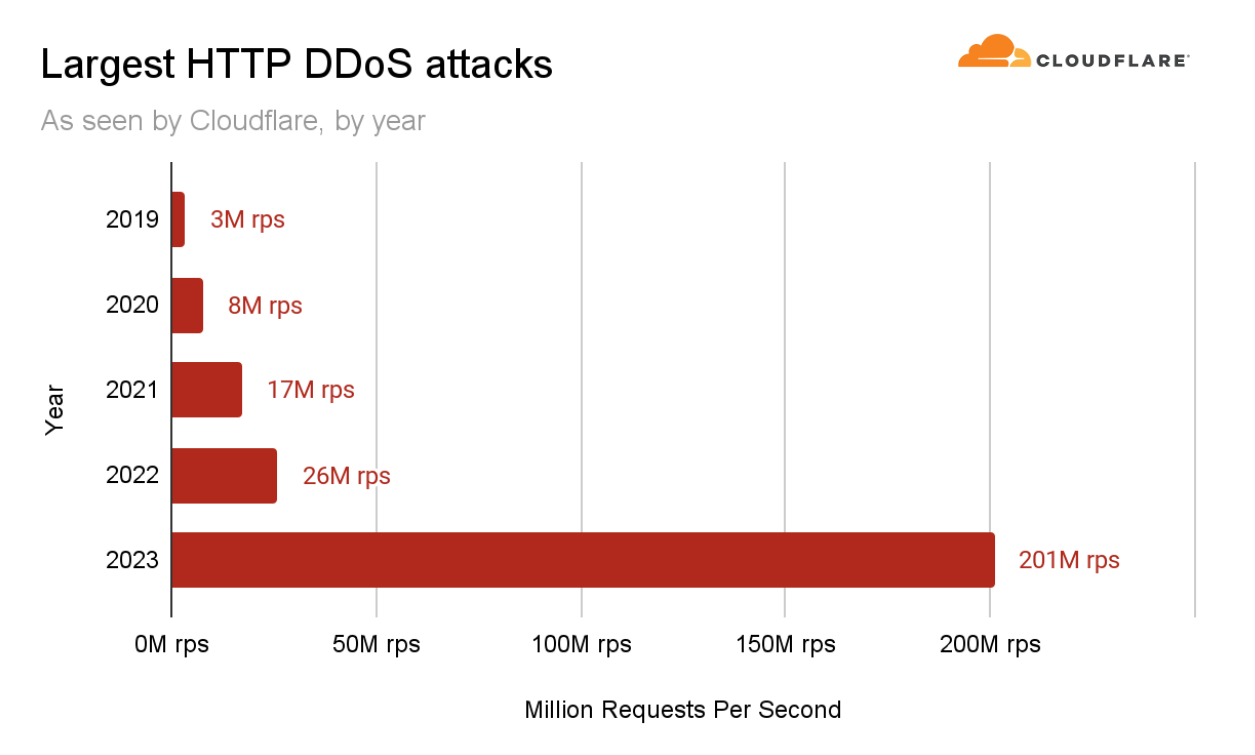
超帯域幅消費型HTTP DDoS攻撃
2023年は未開の領域の年でした。DDoS攻撃は、その規模と巧妙さにおいて、新たな高みに達しました。Cloudflareを含むより広範なインターネットコミュニティは、かつてない速度で何千もの超帯域幅消費型DDoS攻撃を行う、執拗かつ意図的に仕組まれたキャンペーンに直面しました。
これらの攻撃は非常に複雑で、HTTP/2の脆弱性を悪用していました。Cloudflareはこの脆弱性の影響を軽減するために専用の技術を開発し、業界の他の企業と協力して責任を持って公開しました。
このDDoSキャンペーンの一環として、当社のシステムは第3四半期に、1秒当たり2億100万リクエスト(rps)という過去最大の攻撃を軽減しました。これは、これまでの2022年の記録である2,600万RPSの約8倍に相当します。
ネットワーク層DDoS攻撃の増加
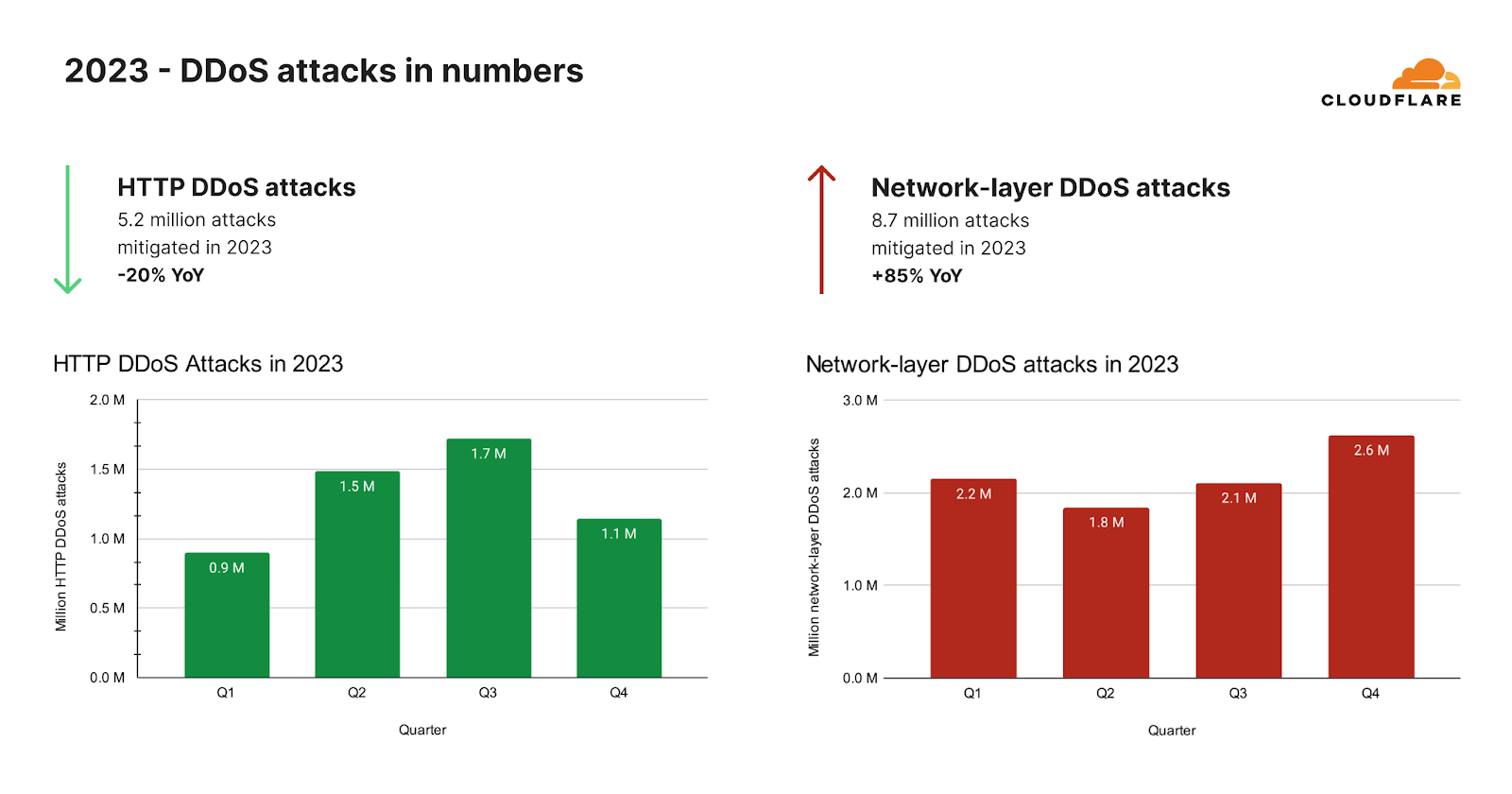
超帯域幅消費型キャンペーンが沈静化した後、HTTP DDoS攻撃が予想外に減少しました。2023年全体では、当社の自動化された防御は、26兆リクエストを超えるHTTP DDoS攻撃を520万回以上軽減しました。これは、毎時平均594件のHTTP DDoS攻撃と30億件の軽減リクエストに相当します。
このような天文学的な数字にもかかわらず、HTTP DDoS攻撃リクエストの量は2022年と比べて20%減少しました。この減少は年間だけでなく、2023年第4四半期にも見られ、HTTP DDoS攻撃リクエスト数は前年比で7%、前四半期比で18%減少しました。
ネットワーク層では、まったく異なる傾向が見られました。当社の自動化された防御は、2023年に870万件のネットワーク層DDoS攻撃を軽減しました。これは2022年と比較して85%の増加です。
2023年第4四半期、Cloudflareの自動化された防御は、80ペタバイトを超えるネットワーク層の攻撃を軽減しました。当社のシステムは、平均して毎時996件のネットワーク層DDoS攻撃、27テラバイトを自動軽減しました。2023年第4四半期のネットワーク層DDoS攻撃数は前年比175%増、前四半期比25%増となりました。
COP28期間中とその前後にDDoS攻撃が増加
2023年最終四半期、サイバー脅威の状況は大きく変化しました。当初、HTTP DDoS攻撃リクエストの量では暗号通貨セクターが主導的な役割を果たしていましたがが、新たな標的が主要な被害者として現れました。環境サービス業界では、HTTP DDoS攻撃がかつてないほど急増し、HTTPトラフィック全体の半分を占めています。これは前年比618倍という驚異的な増加であり、サイバー脅威の状況における不穏な傾向を浮き彫りにしています。
このサイバー攻撃の急増は、2023年11月30日から12月12日まで開催されたCOP28と重なりました。この会議は、多くの人が化石燃料時代の「終わりの始まり」を告げる重要なイベントでした。COP28までの期間、環境サービスWebサイトを標的としたHTTP攻撃が顕著に急増したことが観察されましたが、このパターンはこのイベントだけに限定されたものではありませんでした。
過去のデータを振り返ってみると、特にCOP26やCOP27の際、また他の国連環境関連の決議や発表の際に同じようなパターンが見られます。これらのイベントにはそれぞれ、環境サービスWebサイトを狙ったサイバー攻撃の増加が伴っていました。
2023年2月と3月にかけて、国連の気候正義に関する決議や国連環境プログラムの淡水チャレンジの開始といった重要な環境イベントがあり、環境Webサイトの注目度が高まった可能性があり、これが、これらのサイトに対する攻撃の増加と関連している可能性があります。
このように繰り返されるパターンは、環境問題とサイバーセキュリティの接点が増えつつあることを示しています。サイバーセキュリティは、デジタル時代の攻撃者にとってますます焦点となっています。
DDoS攻撃と鉄の剣
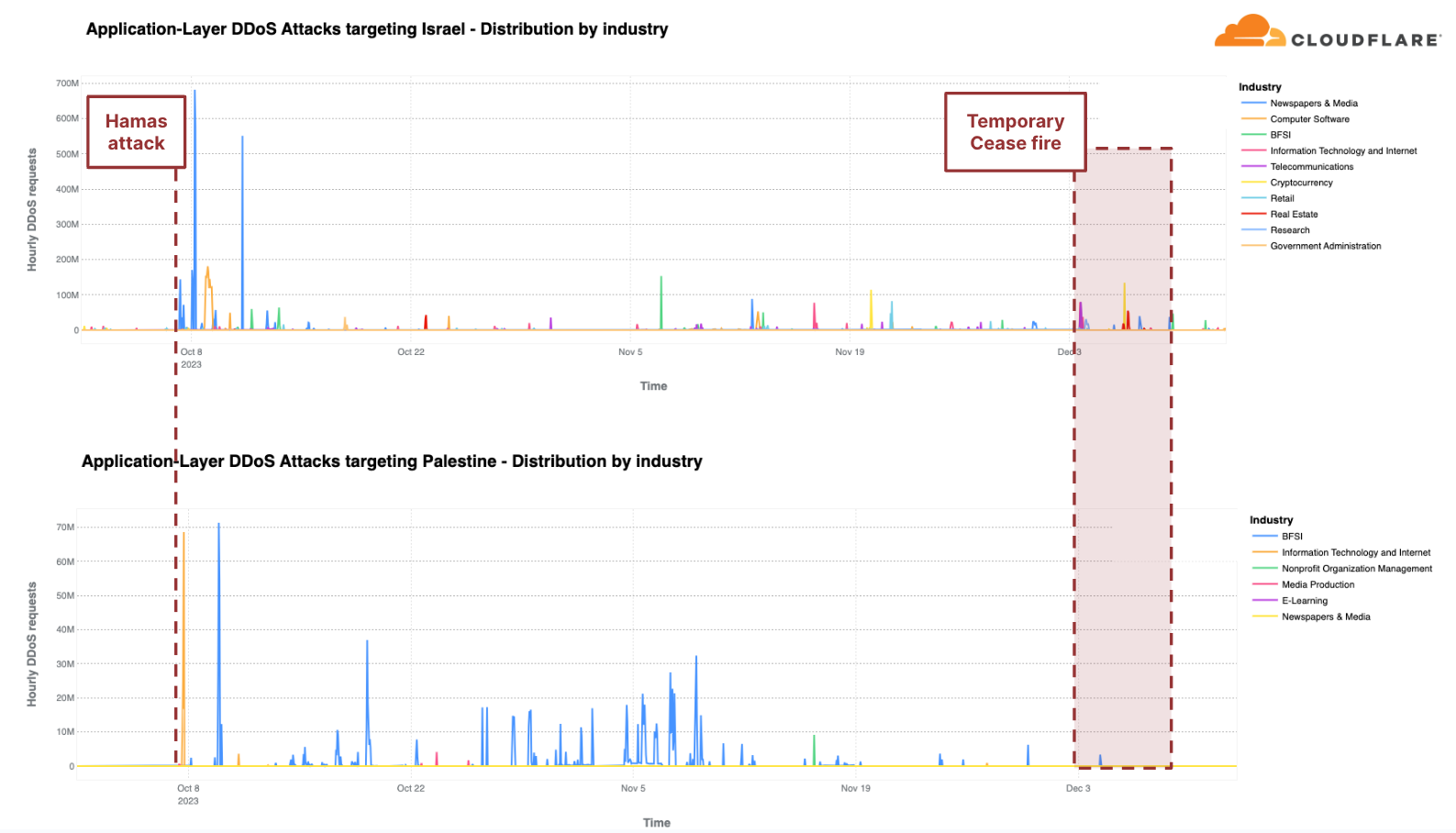
DDoS攻撃の引き金は国連決議だけではない。サイバー攻撃、特にDDoS攻撃は、長い間、戦争や混乱を引き起こす手段となってきました。私たちは、ウクライナとロシアの戦争でDDoS攻撃活動の増加を目の当たりにし、そして今、イスラエルとハマスの戦争でも同様の状態を目撃しています。私たちは、イスラエル・ハマス戦争におけるサイバー攻撃のレポートにおいてサイバー活動を初めて報告しており、第4四半期を通じてその活動を監視し続けました。
「鉄の剣」作戦は、10月7日にハマスによる攻撃を受け、イスラエルがハマスに対して行った軍事攻撃です。この武力紛争が続いている間、私たちは双方を標的にしたDDoS攻撃を観察し続けています。
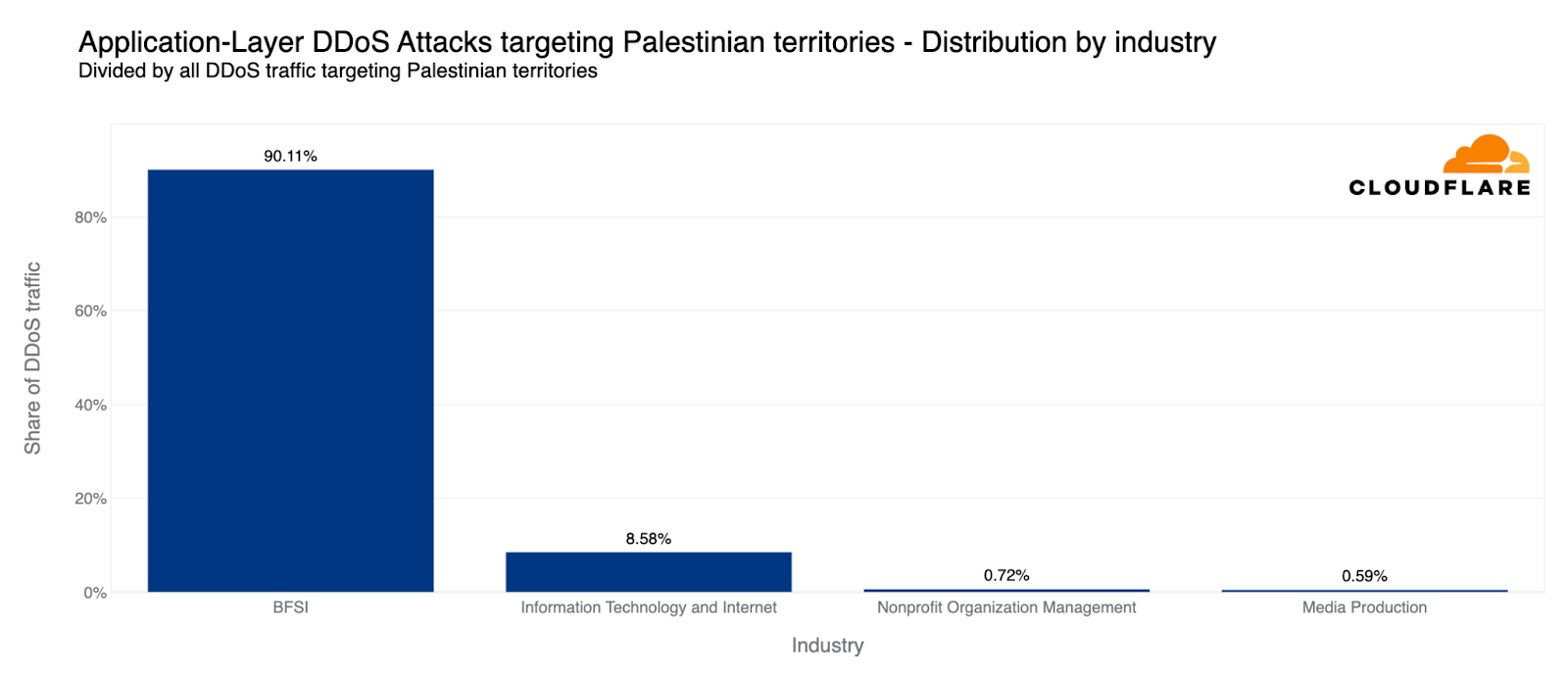
各地域のトラフィックと比較すると、第4四半期にHTTP DDoS攻撃で2番目に攻撃を受けたのはパレスチナ地域でした。パレスチナのWebサイトに対するHTTPリクエストの10%以上がDDoS攻撃であり、合計13億件のDDoSリクエストが前四半期比で1,126%増加しました。これらのDDoS攻撃の90%は、パレスチナの金融機関のWebサイトを標的にしています。別の8%は、情報技術とインターネットプラットフォームを標的としていました。
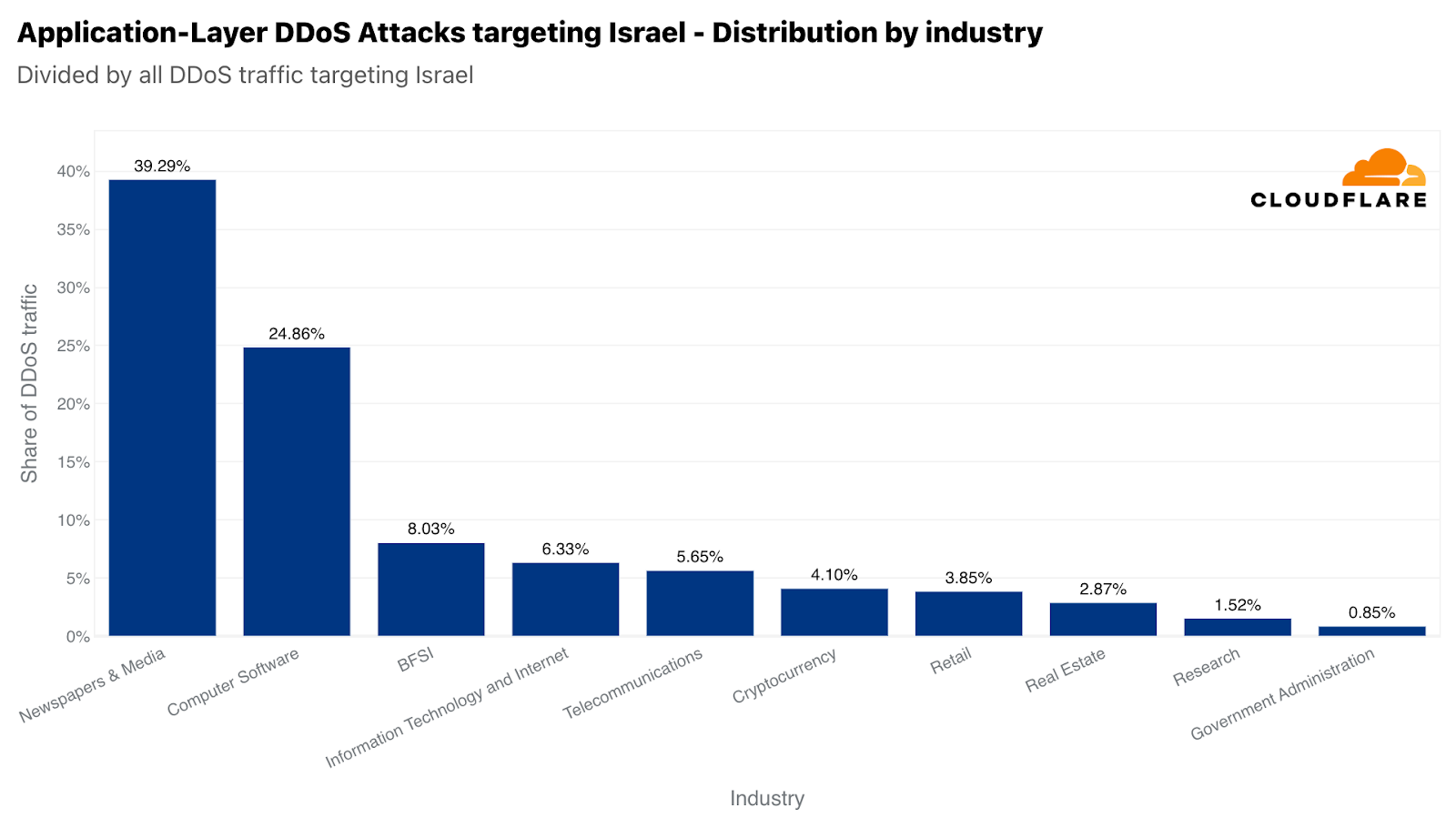
同様に、当社のシステムは、イスラエルのWebサイトを標的とした22億を超えるHTTP DDoSリクエストを自動的に軽減しました。22億件という数は、前四半期や前年と比較すると減少していますが、イスラエル向けのトラフィック全体に占める割合は大きくなっています。この数値は前四半期比では27%増だが、前年比では92%減です。攻撃トラフィックの多さにもかかわらず、イスラエルは自国のトラフィックに対して77番目に多く攻撃された地域でした。また、パレスチナ自治区が42番目だったのに対し、攻撃の総量は33番目に多くなりました。
イスラエルのWebサイトが攻撃を受けたうち、新聞およびメディアが主な標的で、イスラエル向けのHTTP DDoS攻撃のほぼ40%が攻撃対象のトラフィックでした。攻撃対象業界2位は、コンピューター・ソフトウェア業界でした。次いで、3位に銀行・金融機関・保険(BFSI)業界が位置しました。
ネットワーク層でも同じ傾向が見られます。パレスチナのネットワークは、470テラバイトの攻撃トラフィックの標的にされ、パレスチナのネットワークに対する全トラフィックの68%以上を占めています。この数字は、パレスチナ自治区に向かうすべてのトラフィックと比較して、ネットワーク層のDDoS攻撃によって、中国に次いでパレスチナ自治区が世界で2番目に多く攻撃された地域であることを示しています。トラフィックの絶対量では3位でした。この470テラバイトは、Cloudflareが軽減したDDoSトラフィック全体の約1%に相当します。
しかし、イスラエルのネットワークは、わずか2.4テラバイトの攻撃トラフィックの標的にされただけで、正規化した場合にネットワーク層のDDoS攻撃で8位に位置づけました。この2.4テラバイトは、イスラエルのネットワークに向かう全トラフィックのほぼ10%を占めています。
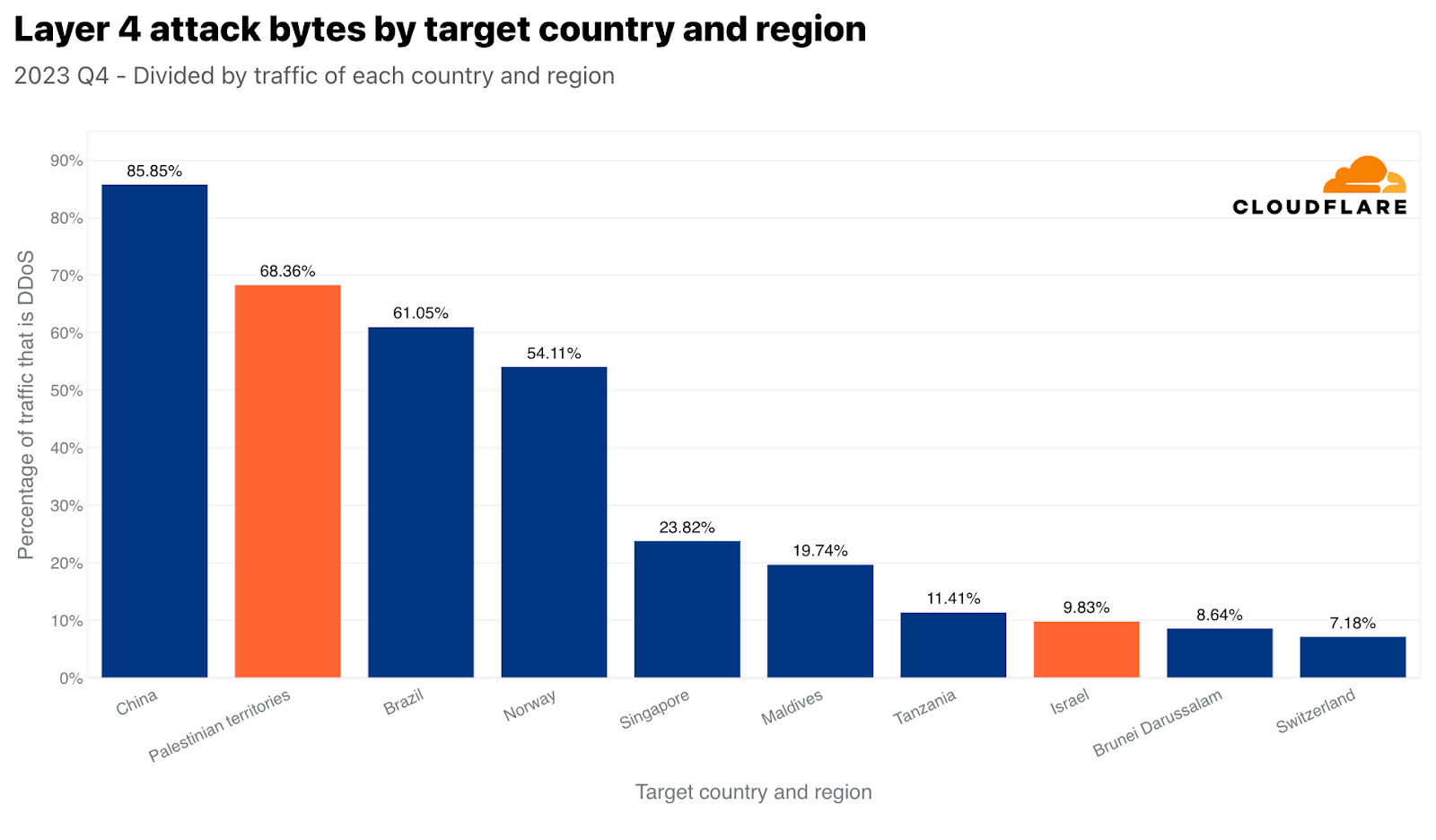
裏を返せば、イスラエルを拠点とするデータセンターで受信された全バイトの3%がネットワーク層のDDoS攻撃だったことが示されました。パレスチナを拠点とするデータセンターでは、この数字はかなり高く、全バイトの約17%となっています。
アプリケーション層では、パレスチナのIPアドレスから発信されたHTTPリクエストの4%がDDoS攻撃であり、イスラエルのIPアドレスから発信されたHTTPリクエストのほぼ2%もDDoS攻撃であることが分かりました。
DDoS攻撃の主な発生源
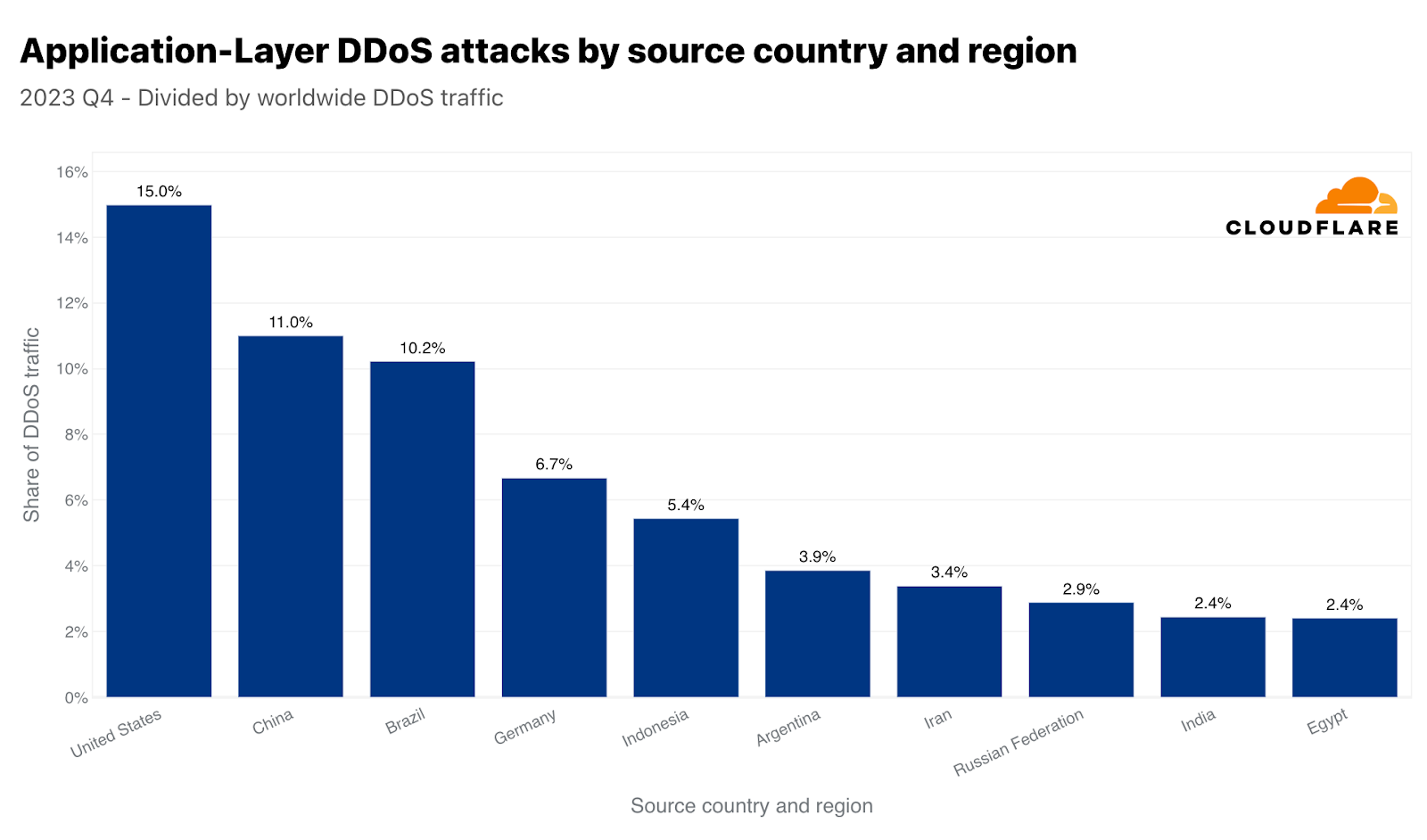
2022年第3四半期には、中国がHTTP DDoS攻撃トラフィックの最大の発生源でした。しかし、2022年第4四半期以降、米国がHTTP DDoS攻撃の最大の発生源として第1位となり、5四半期連続でその好ましくない地位を維持しています。同様に、米国のデータセンターは、ネットワーク層のDDoS攻撃トラフィックを最も多く受診しています。これは、前攻撃バイト数の38%超です。
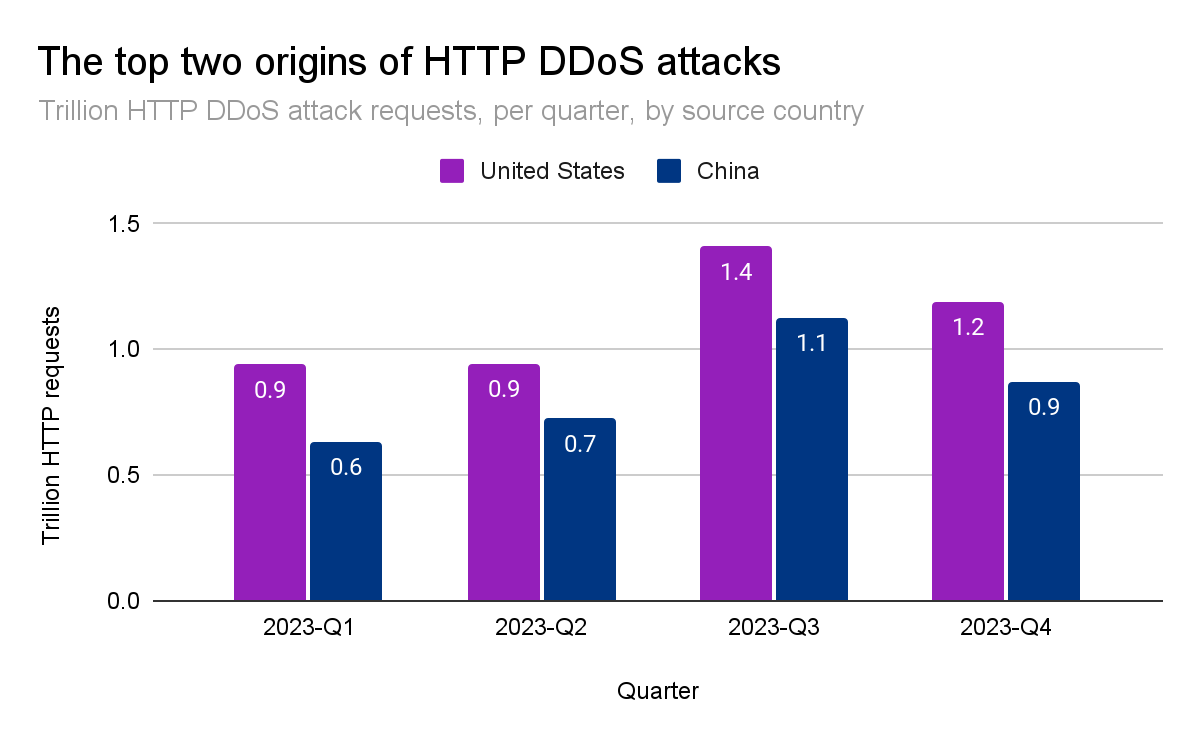
中国と米国は、世界のHTTP DDoS攻撃トラフィックの4分の1強を占めています。次いでブラジル、ドイツ、インドネシア、アルゼンチンが25%を占めています。
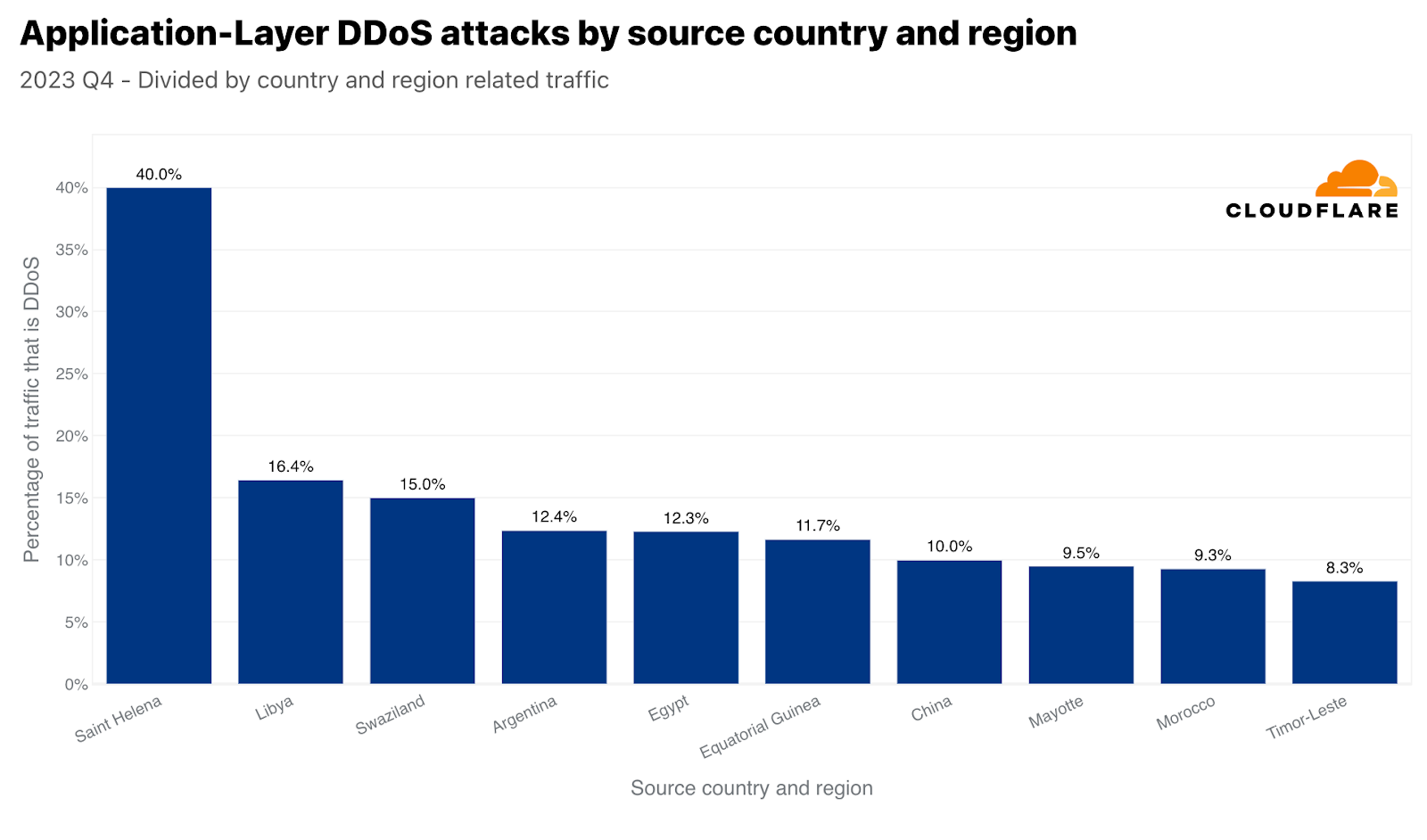
このような大きな数値は通常、大きな市場に対応しています。このため、各国の発信トラフィックを比較することで、各国から発信される攻撃トラフィックも正規化しています。これを行うと、小さな島国や市場の小さい国から不釣り合いな量の攻撃トラフィックが発生することがよくあります。第4四半期には、セントヘレナの発信トラフィックの40%がHTTP DDoS攻撃であり、トップとなりました。「僻地の火山・熱帯地帯の島」に続いて、2位はリビア、3位はスワジランド(エスワティニとしても知られる)でした。4位と5位にはアルゼンチンとエジプトが続いています。
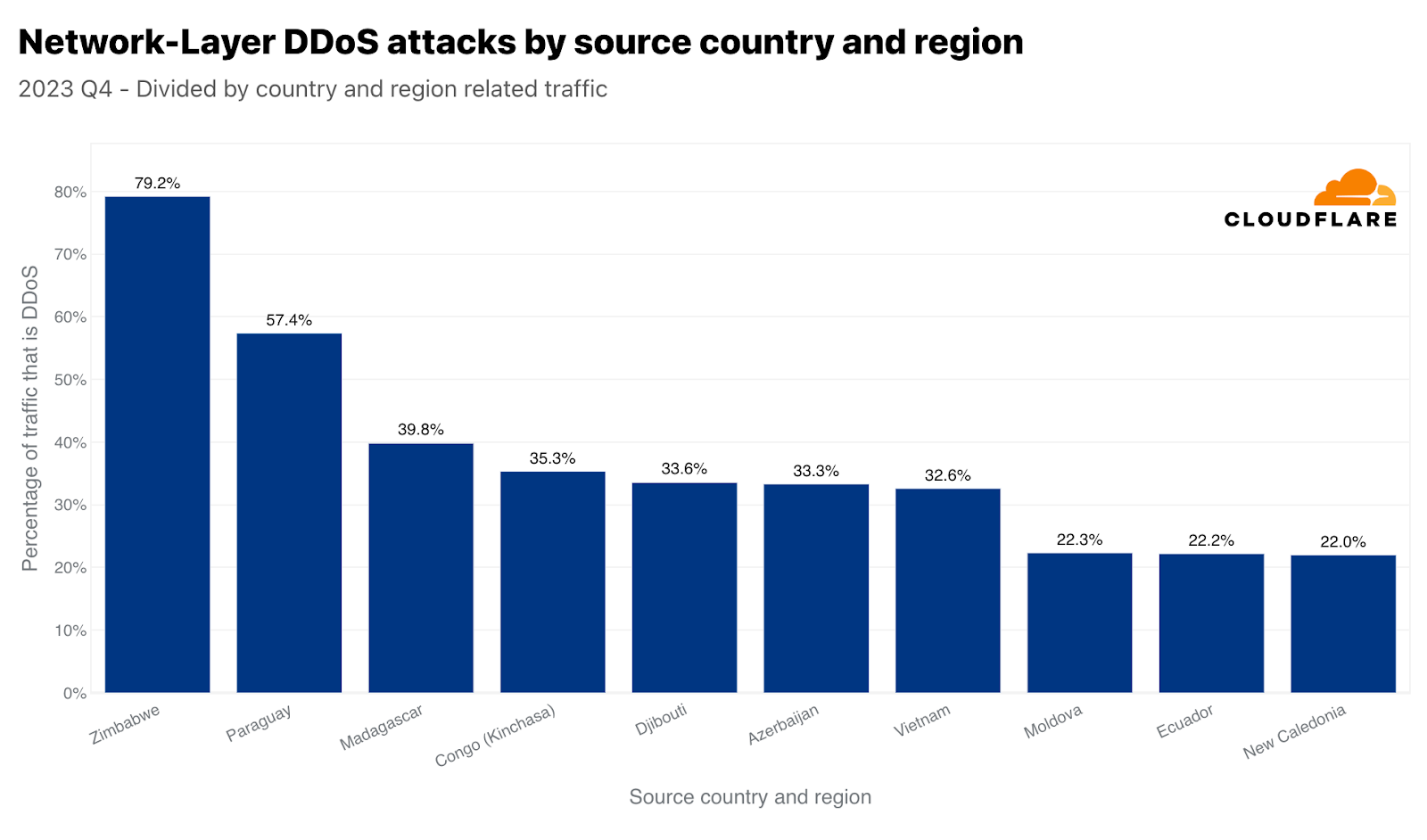
ネットワーク層ではジンバブエが1位となりました。ジンバブエを拠点とするデータセンターで受信したトラフィックのほぼ80%が悪意のあるものでした。それに次いで、2位はパラグアイ、3位はマダガスカルでした。
最も攻撃された業界
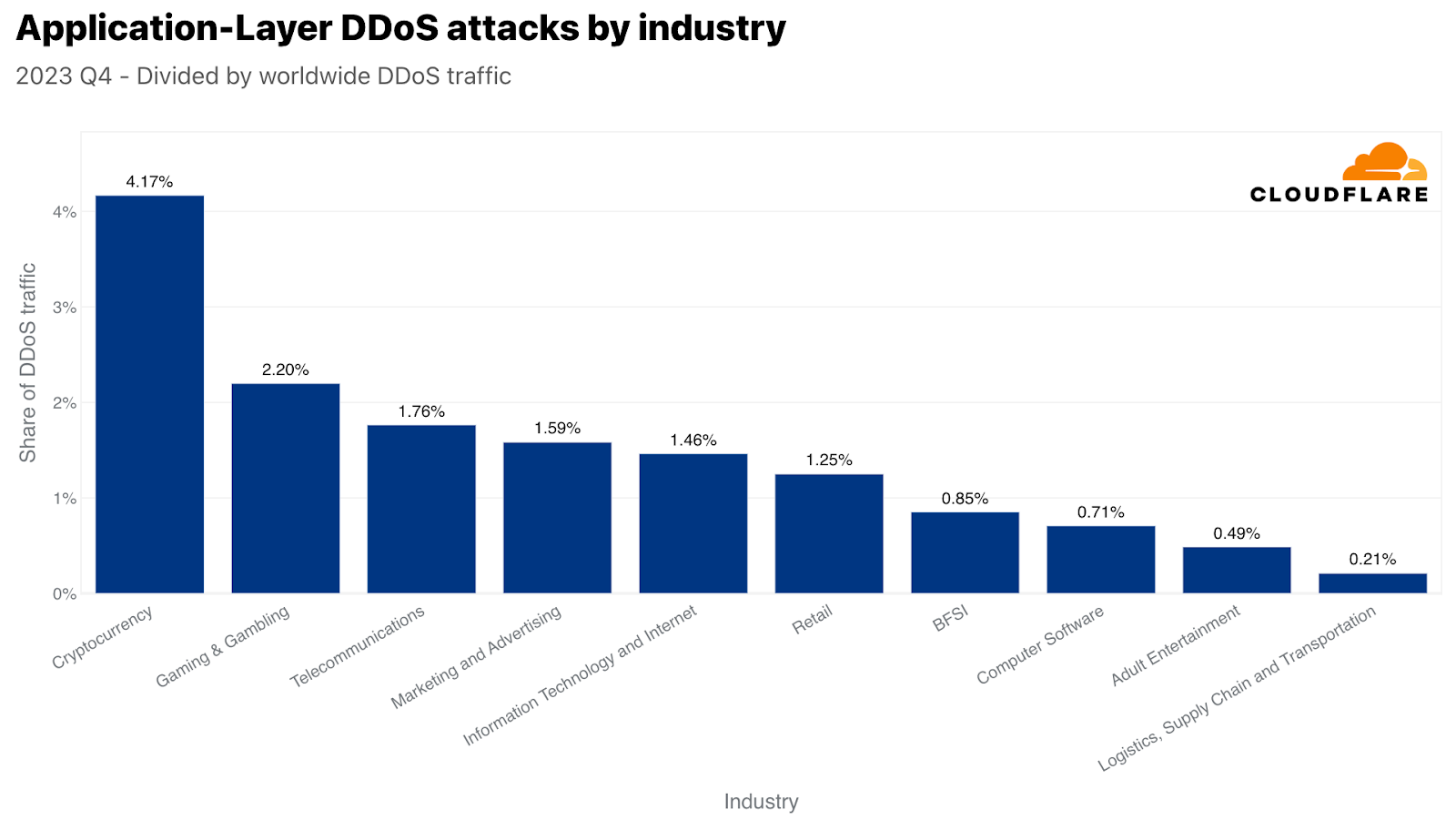
攻撃トラフィック量では、第4四半期に最も攻撃された業界は暗号通貨業界でした。3,300億回を超えるHTTPリクエストが暗号通貨業界を標的としました。この数字は、当四半期のHTTP DDoSトラフィック全体の4%以上を占めています。攻撃対象業界の2位は、ゲーミング&ギャンブルでした。これらの業界は、多くのトラフィックや攻撃を引き付けていることで知られています。
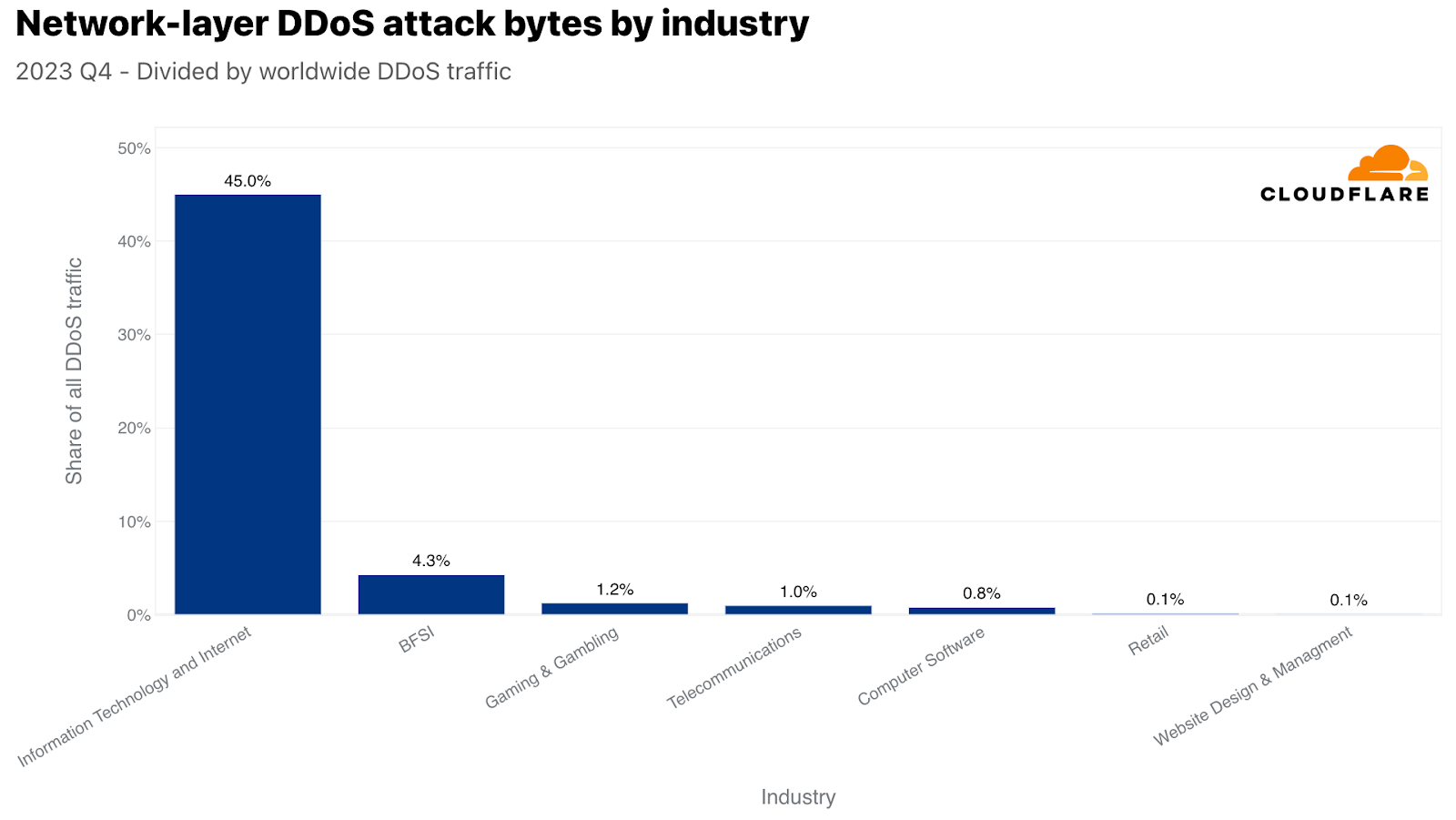
ネットワーク層では、情報技術およびインターネット業界が最も攻撃を受け、ネットワーク層のDDoS攻撃トラフィックの45%以上がこの業界を狙ったものでした。銀行・金融サービス・保険(BFSI)、ゲーミング&ギャンブル、電気通信業界がそれに続きました。
視点を変えるために、ここでも攻撃トラフィックを特定の業界の総トラフィックで正規化しました。そうすることで、私たちは違った見方をすることができるようになります。
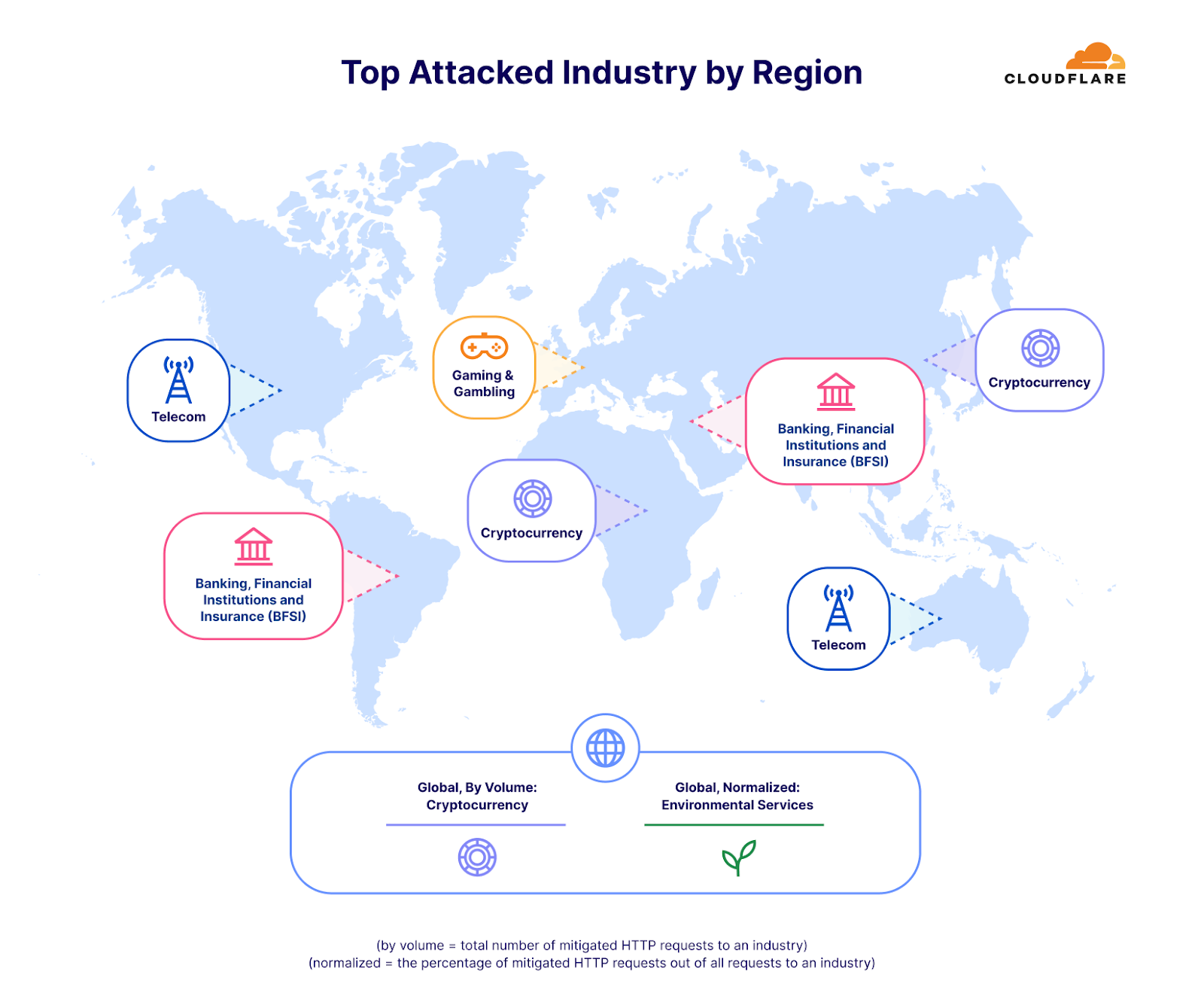
本レポートの冒頭で、環境サービス業界が自社のトラフィックに比して最も攻撃を受けたことを述べました。2位は包装・貨物配送業界で、興味深いことに、ブラックフライデーや冬のホリデーシーズンのオンラインショッピングとのタイムリーな相関関係が見られます。購入したギフトや商品は、どうにかして目的地に届ける必要がありますが、攻撃者たちはそれを妨害しようとしたようです。同様に、小売企業に対するDDoS攻撃も前年比で23%増加が見られました。
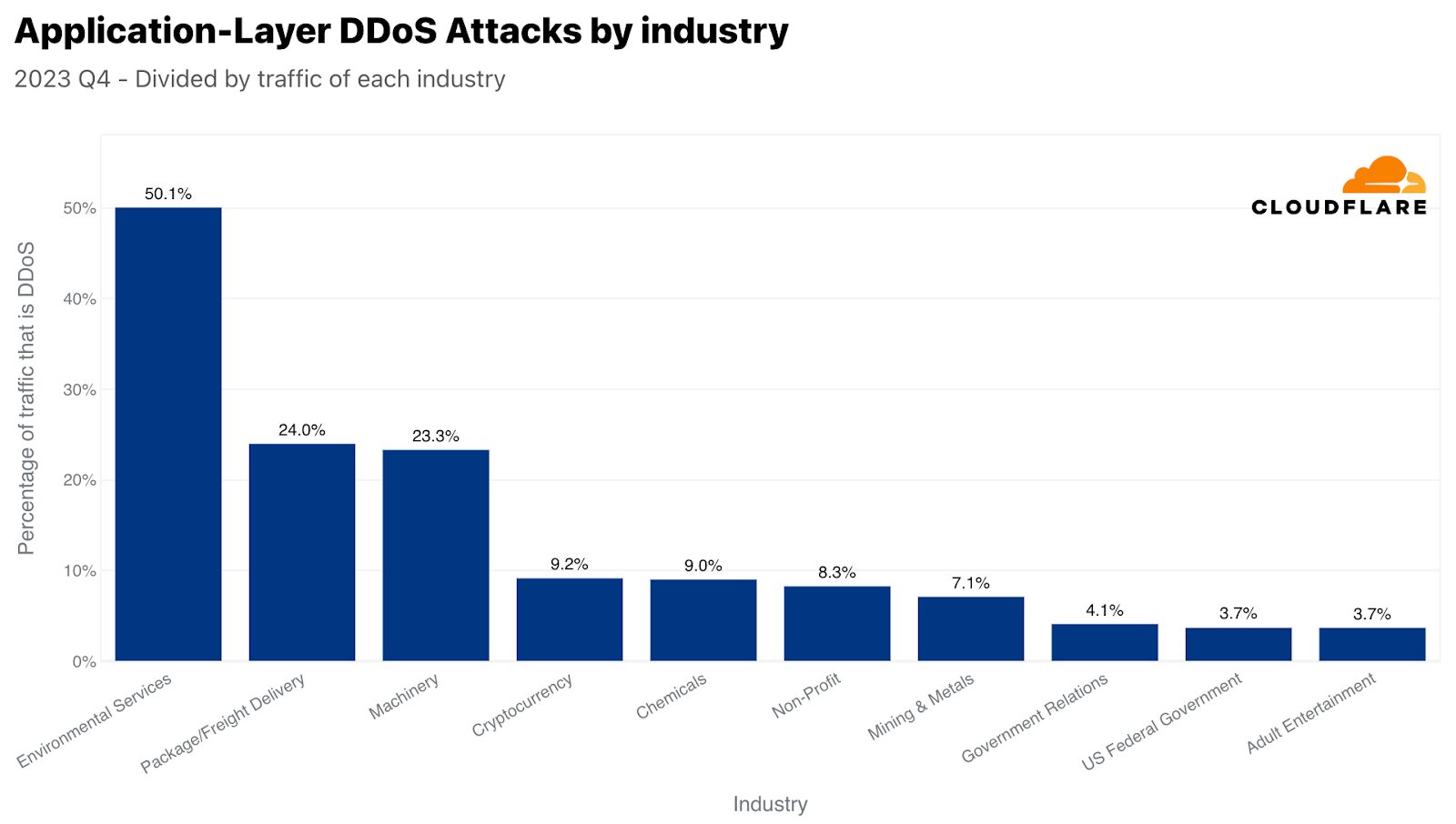
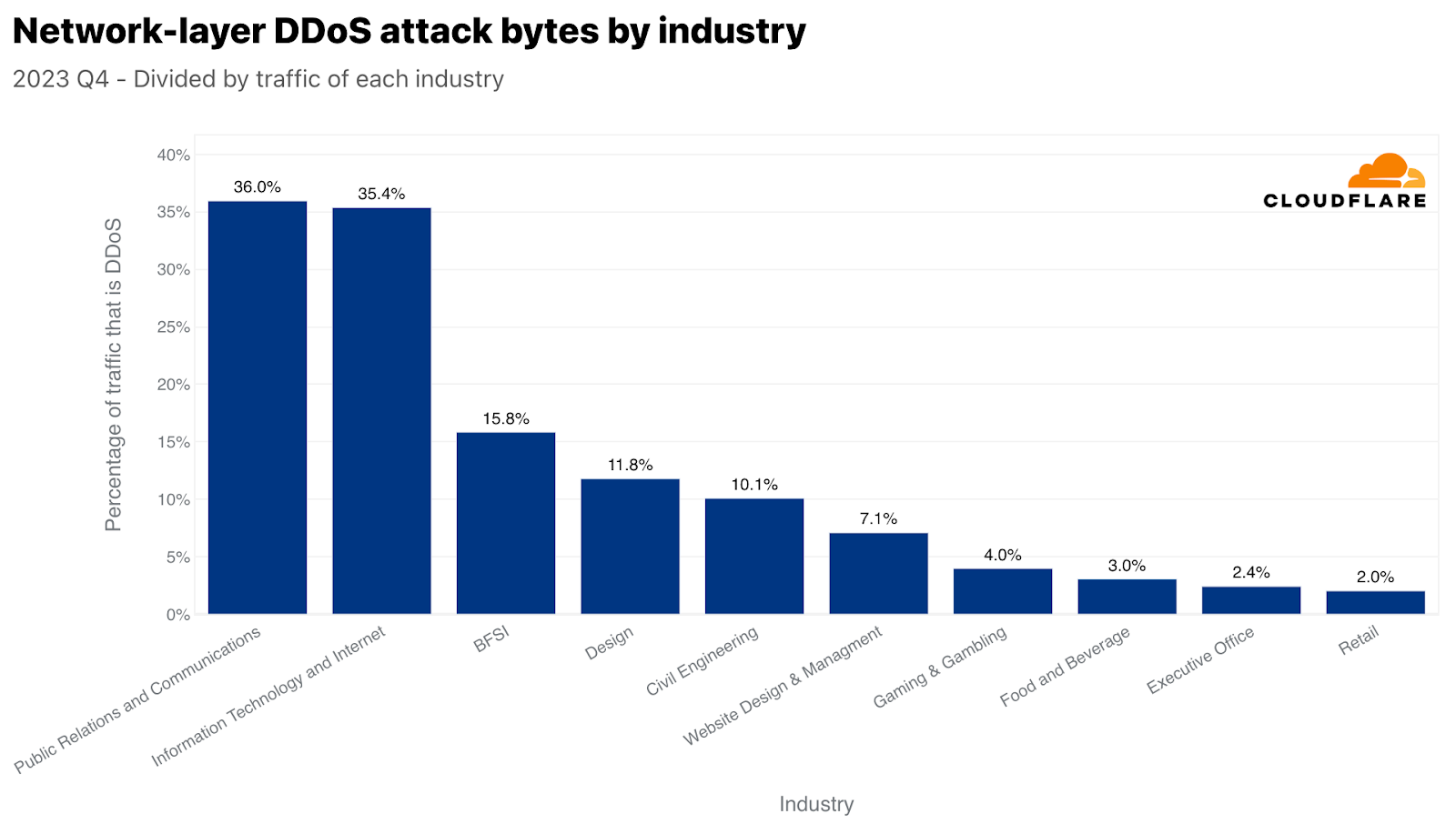
ネットワーク層では、広報・通信が最も標的とされた業種で、トラフィックの36%が悪意あるものでした。このタイミングも非常に興味深いものでした。広報・通信会社は通常、大衆の認識と通信を管理することに関連しています。業務に支障をきたすと、即座に広範囲に風評被害が及ぶ可能性があり、第4四半期のホリデーシーズンにはさらに深刻になります。今四半期は、年末年始の休暇、年度末の総括、新年度の準備のため、PRや通信活動が増加することが多く、重要な業務期間となっています。
最も攻撃された国と地域
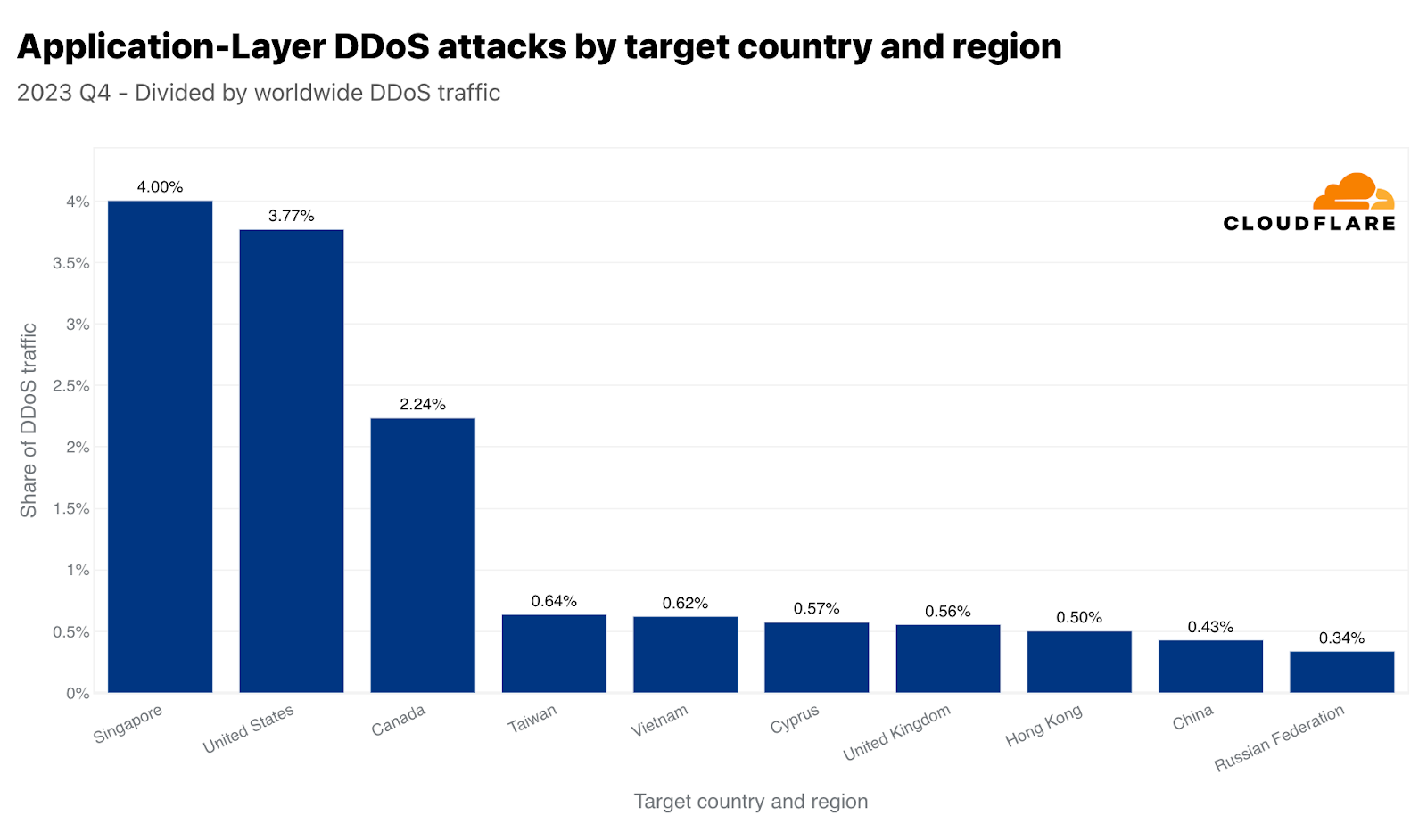
第4四半期はシンガポールがHTTP DDoS攻撃の主な標的となりました。全世界のDDoSトラフィックの4%にあたる3,170億以上のHTTPリクエストがシンガポールのWebサイトを狙ったものでした。米国が2位、カナダが3位と僅差で続きました。台湾は、総選挙を控え、中国との緊張が高まる中、攻撃対象地域の4位となりました。第4四半期の台湾向け攻撃は、前年比で847%、前四半期比で2,858%増加しました。この増加は絶対値だけにとどまりません。正規化すると、全台湾向けトラフィックに対する台湾を標的としたHTTP DDoS攻撃トラフィックの割合も大幅に増加し、前四半期比で624%、前年比で3,370%増加しています。
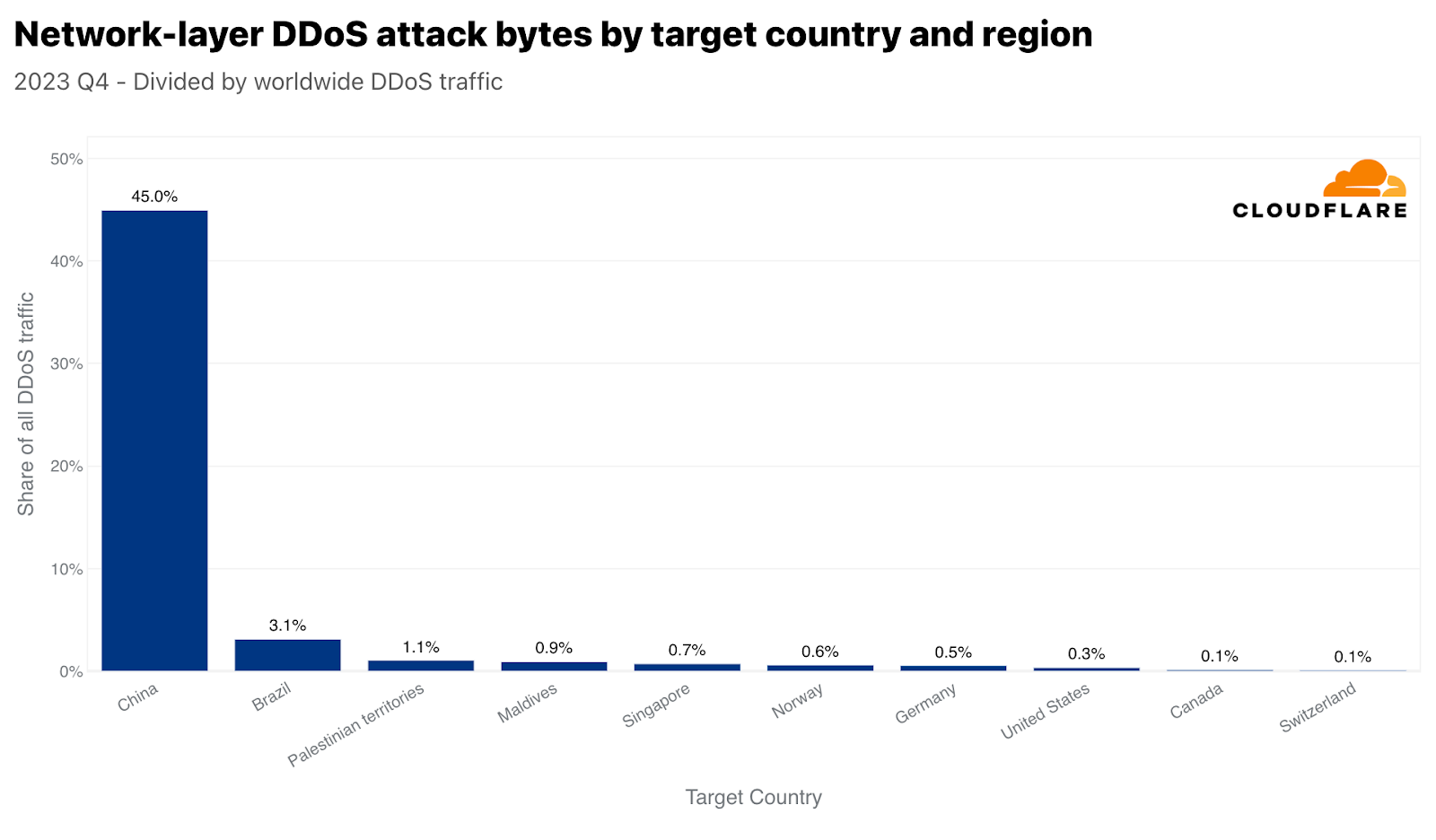
中国はHTTP DDoS攻撃では9位に位置づけていますが、ネットワーク層攻撃では1位となっています。Cloudflareが全世界で軽減したネットワーク層のDDoSトラフィックの45%は中国向けでした。他の国々は、ほとんど無視できるほど中国への攻撃が顕在化しています。
データを正規化すると、イラク、パレスチナ自治区、モロッコが、総受信トラフィックに関して最も攻撃された地域となります。興味深いのは、シンガポールが4位に入っていることです。つまり、シンガポールはHTTP DDoS攻撃トラフィックの最大量に直面しているだけでなく、そのトラフィックはシンガポール行きのトラフィック全体のかなりの量を占めていました。対照的に、米国は(上記のアプリケーション層のグラフによれば)量的には2番目に多く攻撃されたことが示されましたが、米国向けのトラフィック全体に関しては50番目でした。
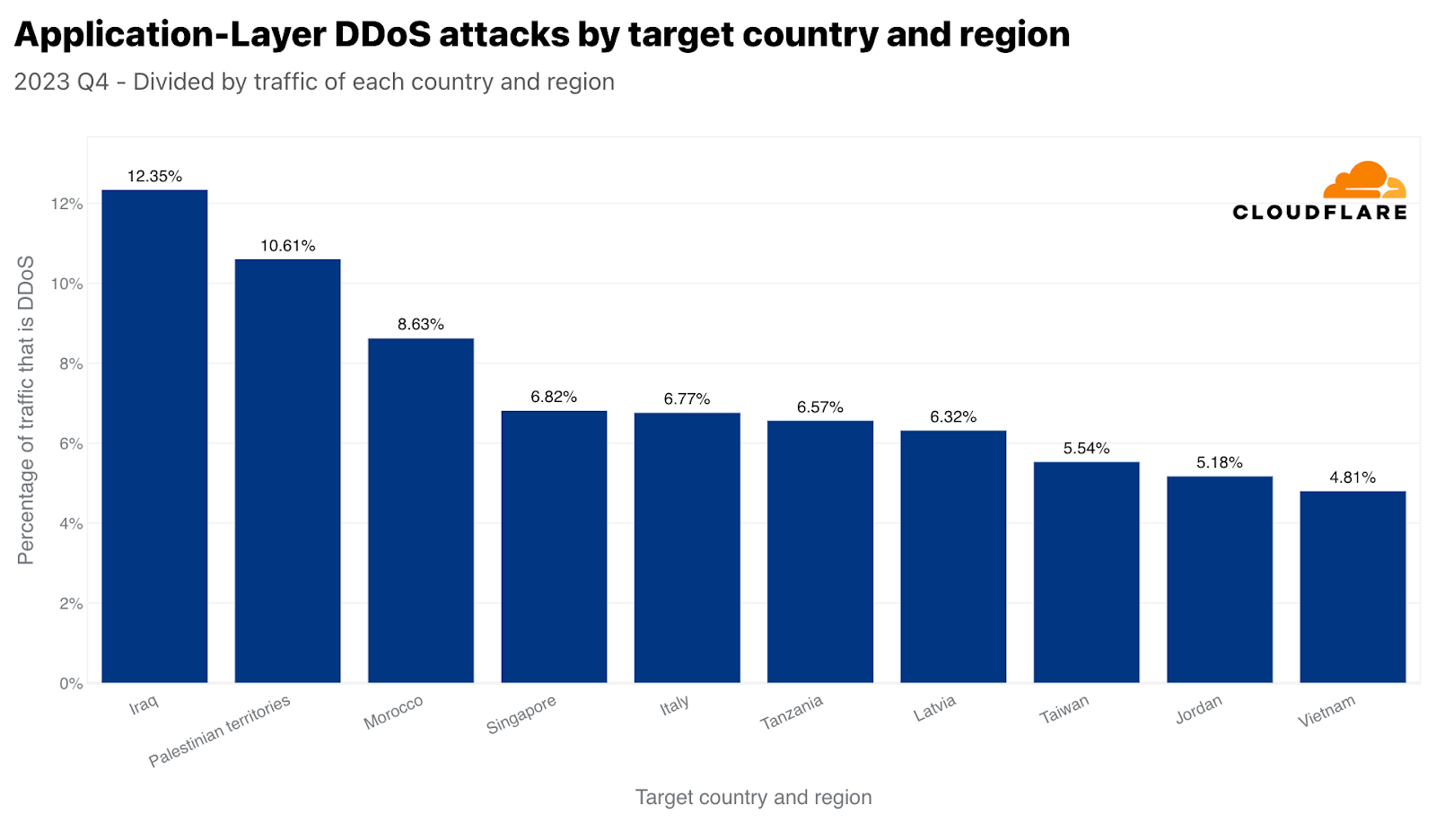
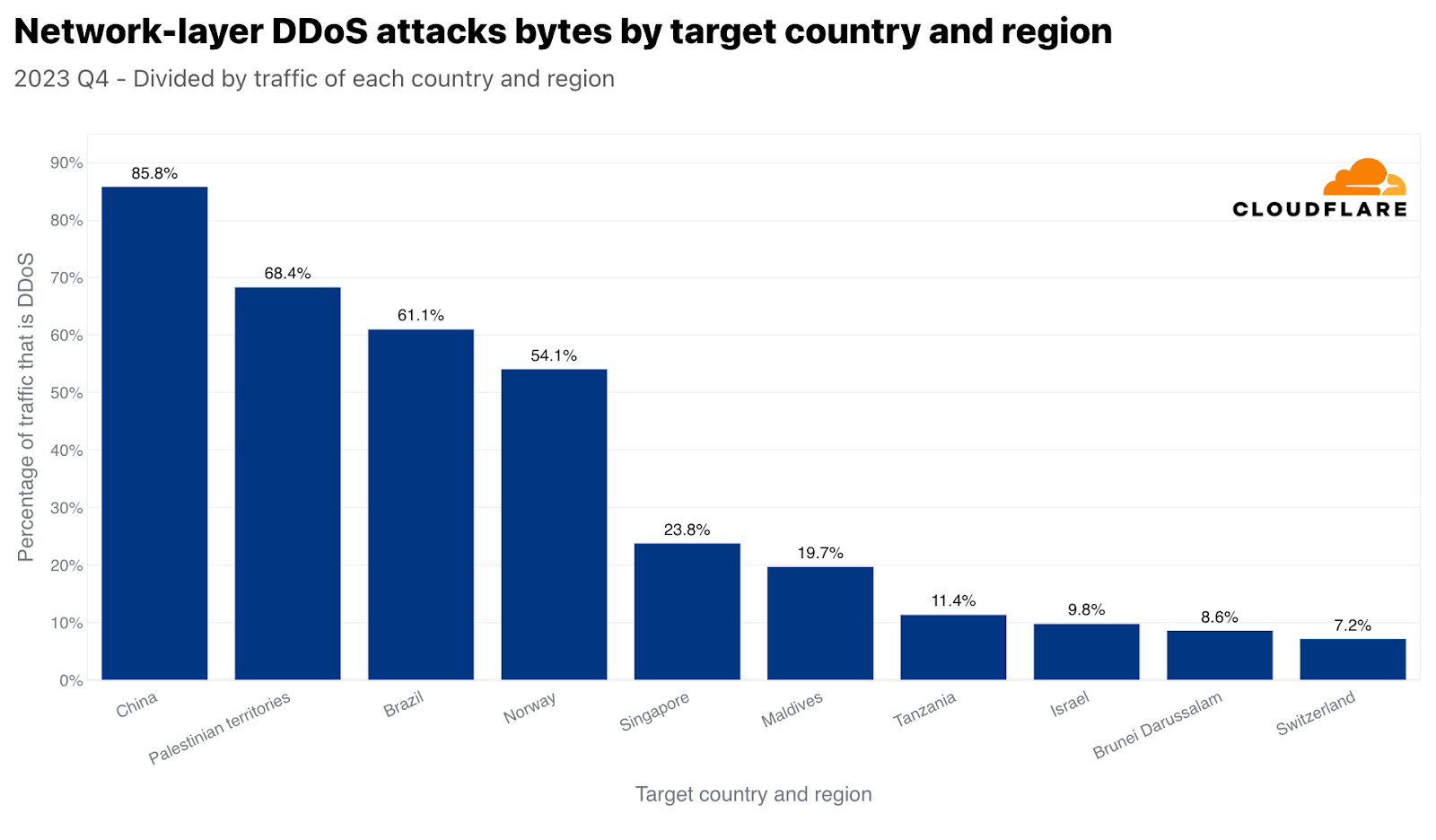
シンガポールと類似していますが、間違いなくもっと劇的なのは、中国がネットワーク層のDDoS攻撃トラフィックならびに中国向けの全トラフィックに関しても最も攻撃されている国であることです。中国向けトラフィックのほぼ86%は、ネットワーク層のDDoS攻撃としてCloudflareによって軽減されました。次いで、パレスチナ自治区、ブラジル、ノルウェー、そしてまたもやシンガポールが攻撃トラフィックで大きな割合を示しました。
攻撃ベクトルと属性
DDoS攻撃の大半は、Cloudflareの規模に比べれば短時間で小規模なものです。しかし、保護されていないWebサイトやネットワークは、適切な自動化されたインライン保護がなければ、短時間の小規模な攻撃によって混乱に見舞われる可能性があり、組織が積極的に堅牢なセキュリティ体制を採用する必要性を強調しています。
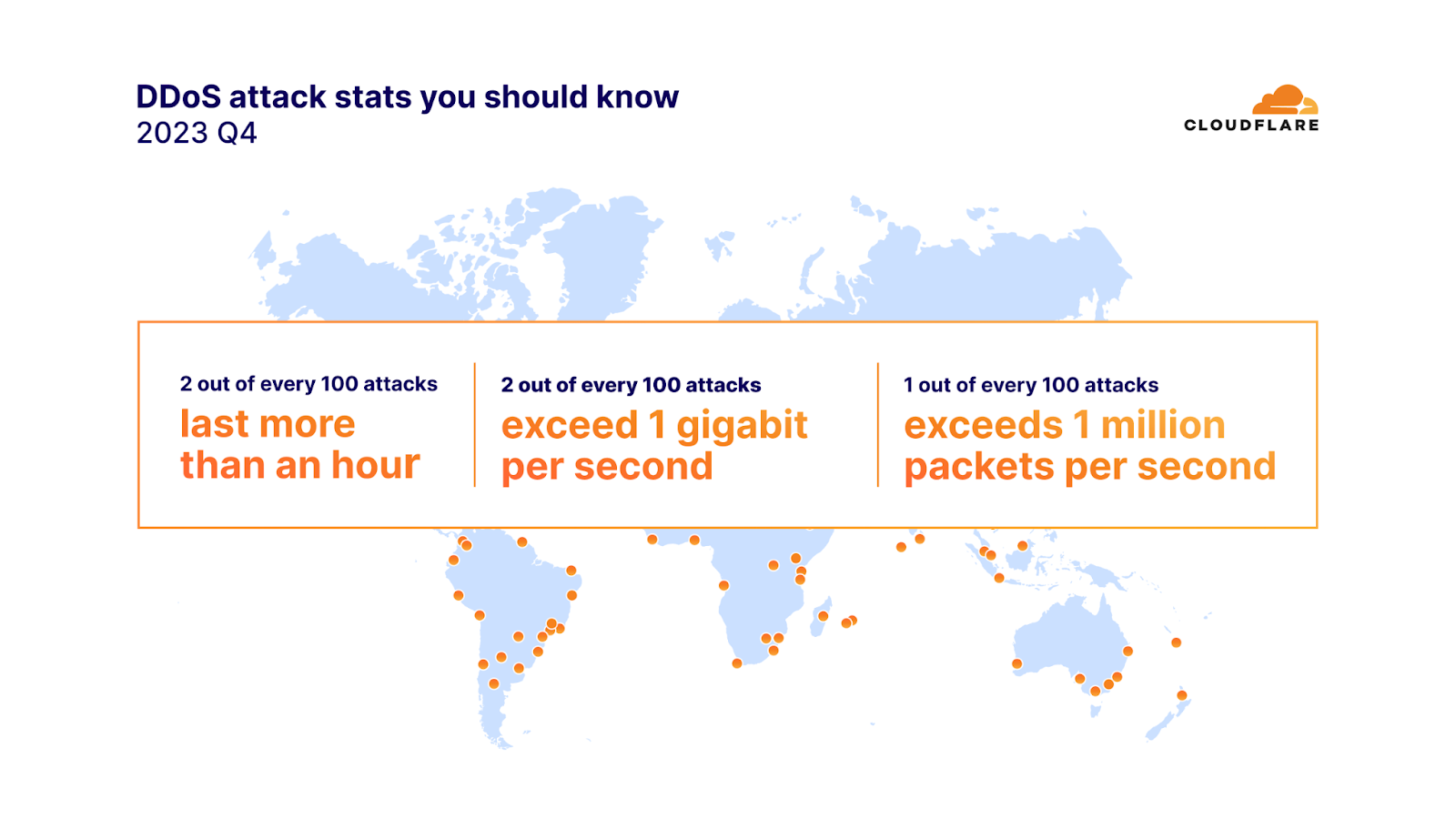
2023年第4四半期には、攻撃の91%が10分以内に終了し、97%がピーク時に毎秒500メガビット(mbps)を下回り、88%が毎秒5万パケット(pps)を超えることはありませんでした。
ネットワーク層のDDoS攻撃の100回に2回は1時間以上続き、毎秒1ギガビット(gbps)を超えました。毎秒100万パケットを超える攻撃は100回に1回でした。さらに、毎秒1億パケットを超えるネットワーク層のDDoS攻撃は、前四半期比で15%増加しました。
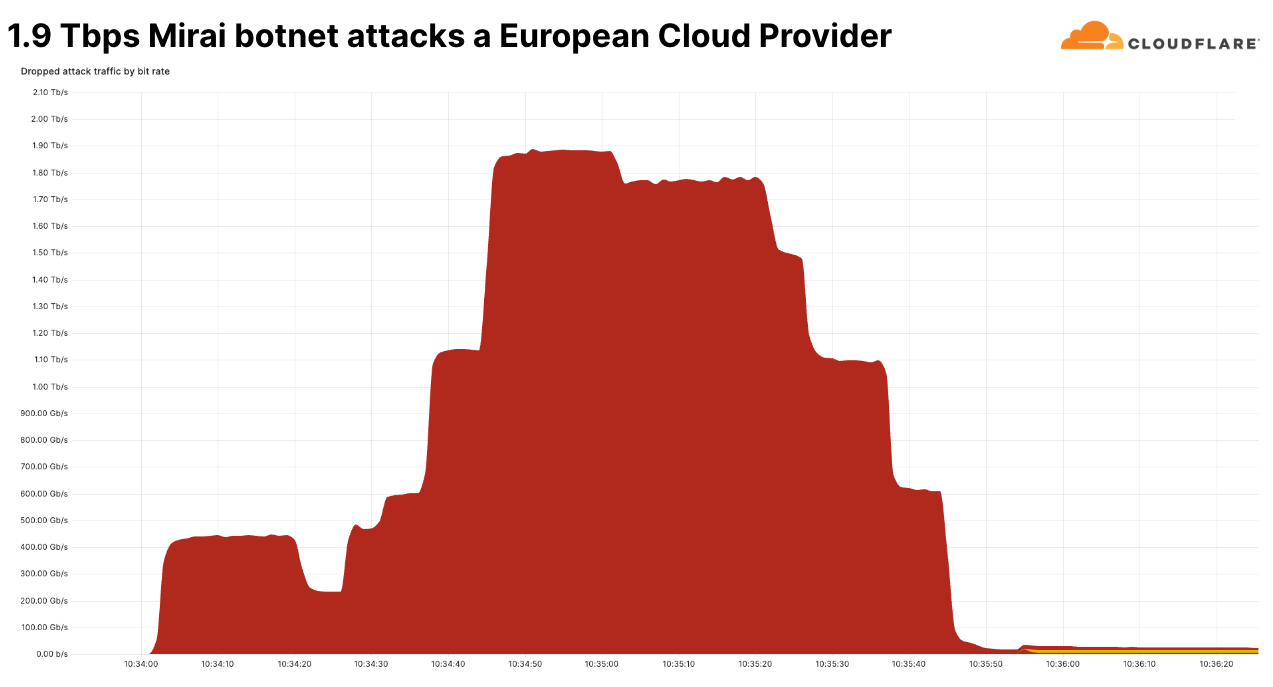
このような大規模な攻撃のひとつが、ピーク時に毎秒1億6,000万パケットを記録したMiraiボットネット攻撃でしたが、1秒あたりのパケット数は、これまでで最大ではありませんでした。過去最大は毎秒7億54,00万パケットでした。この攻撃は2020年に発生したもので、それ以上のものはまだ観察されたことがありません。
しかし、この最近の攻撃は、そのビット/秒の速度においてユニークでした。これは、当社が第4四半期に見た中で最大のネットワーク層DDoS攻撃でした。ピークは毎秒1.9テラビットで、Miraiボットネットが発生源でした。この攻撃はマルチベクトル攻撃で、複数の攻撃手法を組み合わせています。その中には、UDPフラグメントフラッド、UDP/Echoフラッド、SYNフラッド、ACKフラッド、TCPマルフォームドフラッグなどが含まれていました。
この攻撃は欧州の有名なクラウドプロバイダーを標的としており、なりすましと思われる18,000以上のユニークなIPアドレスから送信されていました。この攻撃はCloudflareの防御機能によって自動的に検出され、軽減されました。
このことは、最大規模の攻撃であっても、あっという間に終わってしまうことを物語っています。私たちが過去に経験した大規模な攻撃は数秒以内に終了しており、インラインの自動防御システムの必要性を強調しています。また、まだまれではありますが、テラビット級の攻撃が目立つようになってきています。
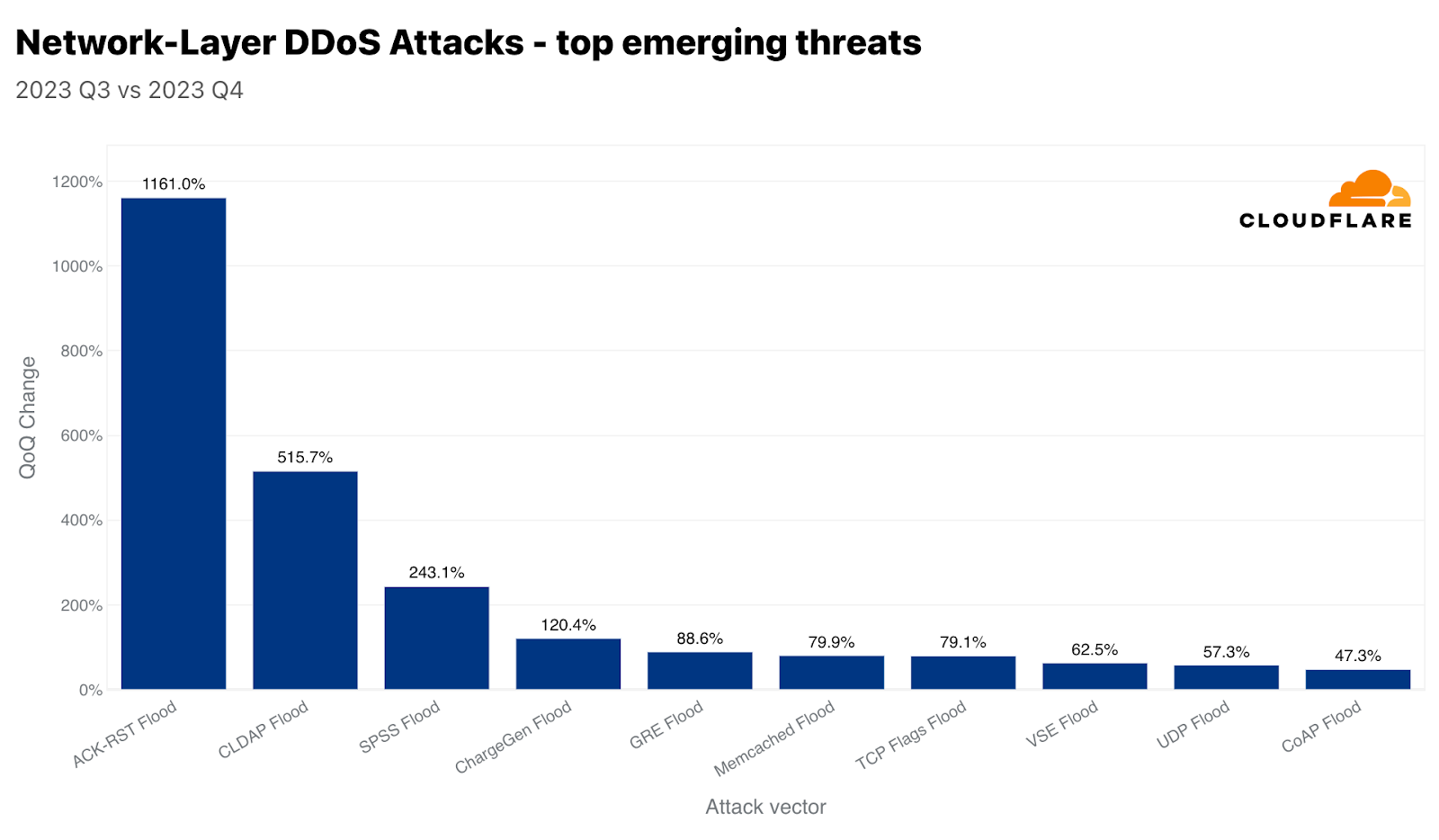
Mirai変種ボットネットの使用は依然として非常に一般的です。第4四半期では、全攻撃のほぼ3%がMiraiから発生しています。しかし、すべての攻撃手法の中で、攻撃者はDNSベースの攻撃を依然として好んでいます。DNSフラッドとDNSアンプ攻撃を合わせると、第4四半期の全攻撃のほぼ53%を占めています。2番目にSYNフラッド、3番目にUDPフラッドが続いています。ここでは、2つのDNS攻撃タイプを取り上げます。UDPフラッドとSYNフラッドについては、ラーニングセンターのハイパーリンクをご覧ください。
DNSフラッドとアンプ攻撃
DNSフラッドとDNSアンプ攻撃はどちらもドメイン名システム(DNS)を悪用しますが、その動作は異なります。DNSはインターネットの電話帳のようなもので、"www.cloudfare.com"のような人間にとって使いやすいドメイン名を、コンピューターがネットワーク上でお互いを識別するために使用する数値のIPアドレスに変換します。
簡単に言えば、DNSベースのDDoS攻撃は、実際にサーバーを「ダウン」させることなく、コンピュータとサーバーがお互いを識別し、停止や中断を引き起こすために使用される方法です。たとえば、サーバーは稼働していても、DNSサーバーがダウンしていることがあります。そのため、クライアントは接続できず、「障害」を経験することになります。
DNSフラッド攻撃は、圧倒的な数のDNSクエリーをDNSサーバーに浴びせます。これは通常、DDoSボットネットを使用して行われます。膨大な量のクエリがDNSサーバーを圧倒し、正当なクエリへの応答が困難または不可能になります。その結果、前述のようなサービスの中断、遅延、あるいはWebサイトや標的となったDNSサーバーに依存するサービスにアクセスしようとする人たちの停止につながる可能性があります。
一方、DNSアンプ攻撃では、DNSサーバーになりすましたIPアドレス(被害者のアドレス)で小さなクエリーを送信します。ここでのトリックは、DNSレスポンスがリクエストよりもかなり大きいことです。次に、サーバーはこの大きなレスポンスを被害者のIPアドレスに送信します。オープンDNSリゾルバーを悪用することで、攻撃者は被害者に送信されるトラフィック量を増幅させ、より大きな影響を与えることができます。このタイプの攻撃は、被害者を混乱させるだけでなく、ネットワーク全体を輻輳させる可能性もあります。
いずれの場合も、攻撃はネットワーク運用におけるDNSの重要な役割を悪用しています。通常、軽減策には、悪用に対するDNSサーバーの保護、トラフィックを管理するためのレート制限の実装、悪意のあるリクエストを特定しブロックするためのDNSトラフィックのフィルタリングなどが含まれます。
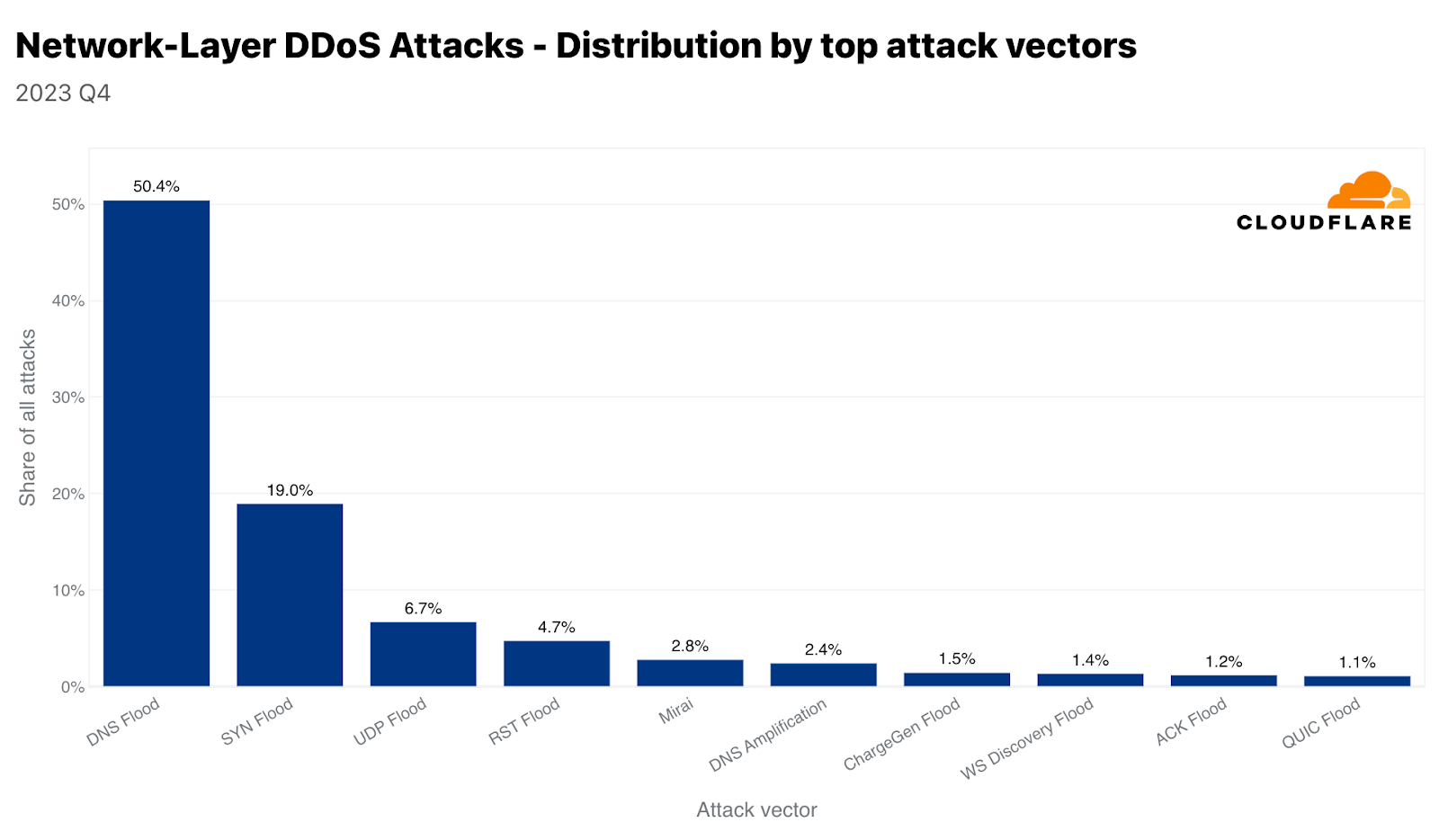
当社が追跡している新たな脅威のうち、ACK-RSTフラッドは前四半期比1,161%増、CLDAPフラッドは同515%増、SPSSフラッドは同243%増を記録しました。このような攻撃と、それがどのように混乱を引き起こすのかを見ていきましょう。
ACK-RSTフラッド
ACK-RSTフラッドは、多数のACKおよびRSTパケットを被害者に送信することで伝送制御プロトコル(TCP)を悪用します。これにより、被害者がこれらのパケットを処理し応答する能力が圧倒され、サービスの中断につながります。ACKパケットやRSTパケットの1つ1つが被害者のシステムからのレスポンスを促し、そのリソースを消費するため、この攻撃は効果的です。ACK-RSTフラッドは、正規のトラフィックを模倣しているため、フィルタリングが困難な場合が多く、検知と軽減を困難にします。
CLDAPフラッド
CLDAP(Connectionless Lightweight Directory Access Protocol)は、LDAPLDAP(Lightweight Directory Access Protocol)の亜種です。これは、IPネットワーク上で動作するディレクトリサービスの照会と変更に使用されます。CLDAPはコネクションレスで、TCPの代わりにUDPを使用するため、高速だが信頼性が低くなります。UDPを使用するため、ハンドシェイクの要件がなく、攻撃者がIPアドレスを詐称できるため、攻撃者はこれをリフレクションベクトルとして悪用できます。これらの攻撃では、小さなクエリーがなりすました送信元IPアドレス(被害者のIP)で送信されるため、サーバーは被害者に大きなレスポンスを送信し、被害者を圧倒します。対策には、異常なCLDAPトラフィックのフィルタリングと監視が含まれます。
SPSSフラッド
SPSS(Source Port Service Sweep)プロトコルを悪用したフラッドは、多数のランダムまたは偽装されたソースポートから、標的となるシステムやネットワーク上のさまざまな宛先ポートにパケットを送信するネットワーク攻撃手法です。この攻撃の目的は2つあります。1つ目は、被害者の処理能力を圧倒し、サービスの中断やネットワークの停止を引き起こすこと、2つ目は、オープンポートをスキャンし、脆弱なサービスを特定することです。フラッドは大量のパケットを送信することで実現され、被害者のネットワークリソースを飽和させ、ファイアウォールや侵入検知システムの能力を使い果たします。このような攻撃を軽減するためには、インラインの自動検知機能を活用することが不可欠です。
Cloudflareは攻撃のタイプ、規模、持続時間にかかわらず、お客様を支援いたします
Cloudflareの使命は、より良いインターネットの構築を支援することです。より良いインターネットとは、安全で、パフォーマンスが高く、誰もが利用できるインターネットであると私たちは考えています。攻撃のタイプ、攻撃規模、攻撃時間、攻撃の背後にある動機にかかわらず、Cloudflareの防御は強固です。2017年に非従量課金型のDDoS攻撃対策のパイオニアとなって以来、私たちはエンタープライズグレードのDDoS攻撃対策をすべての組織で同様に、そしてもちろんパフォーマンスを損なうことなく無料で提供することを約束し、守り続けてきました。これは、当社独自のテクノロジーと堅牢なネットワークアーキテクチャによって実現されています。
セキュリティはプロセスであり、単一の製品やスイッチの切り替えではないことを覚えておくことが重要です。私たちは、自動化されたDDoS攻撃対策システムの上に、ファイアウォール、ボット検知、API保護、キャッシングなどの包括的なバンドル機能を提供し、お客様の防御を強化します。当社の多層的なアプローチは、お客様のセキュリティ体制を最適化し、潜在的な影響を最小限に抑えます。また、DDoS攻撃に対する防御を最適化するのに役立つ推奨事項のリストをまとめましたので、ステップバイステップのウィザードに従ってアプリケーションを保護し、DDoS攻撃を防ぐことができます。また、DDoS攻撃やインターネット上のその他の攻撃に対する、使いやすく業界最高の保護機能をご利用になりたい場合は、Cloudflare.comから無料でご登録いただけます!攻撃を受けている場合は、登録するか、こちらに記載されているサイバー緊急ホットライン番号に電話すると、迅速な対応が受けられます。
2023년 4분기 DDoS 위협 보고서

Cloudflare DDoS 위협 보고서 제16호에 오신 것을 환영합니다. 이번 호에서는 2023년 4분기이자 마지막 분기의 DDoS 동향과 주요 결과를 다루며, 연중 주요 동향을 검토합니다.
DDoS 공격이란 무엇일까요?
DDoS 공격 또는 분산 서비스 거부 공격은 웹 사이트와 온라인 서비스가 처리할 수 있는 트래픽을 초과하여 사용자를 방해하고 서비스를 사용할 수 없게 만드는 것을 목표로 하는 사이버 공격의 한 유형입니다. 이는 교통 체증으로 길이 막혀 운전자가 목적지에 도착하지 못하는 것과 유사합니다.
이 보고서에서 다룰 DDoS 공격에는 크게 세 가지 유형이 있습니다. 첫 번째는 HTTP 서버가 처리할 수 있는 것보다 더 많은 요청으로 서버를 압도하여 서비스 거부 이벤트를 발생시키는 것을 목표로 하는 HTTP 요청집중형 DDoS 공격입니다. 두 번째는 라우터, 방화벽, 서버 등의 인라인 장비에서 처리할 수 있는 패킷보다 많은 패킷을 전송하여 서버를 압도하는 것을 목표로 하는IP 패킷집중형 DDoS 공격입니다. 세 번째는 비트 집중형 공격으로, 인터넷 링크를 포화 상태로 만들어 막히게 함으로써 앞서 설명한 '정체'를 유발하는 것을 목표로 합니다. 이 보고서에서는 세 가지 유형의 공격에 대해 다양한 기법과 인사이트를 중점적으로 다룹니다.
보고서의 이전 버전은 여기에서 확인할 수 있으며, 대화형 허브인Cloudflare Radar에서도 확인할 수 있습니다. Cloudflare Radar는 전 세계 인터넷 트래픽, 공격, 기술 동향, 인사이트를 보여주며, 드릴 다운 및 필터링 기능을 통해 특정 국가, 산업, 서비스 공급자에 대한 인사이트를 확대할 Continue reading
BGP Labs: Reuse BGP AS Number Across Sites
When I published the Bidirectional Route Redistribution lab exercise, some readers were quick to point out that you’ll probably have to reuse the same AS number across multiple sites in a real-life MPLS/VPN deployment. That’s what you can practice in today’s lab exercise – an MPLS/VPN service provider allocated the same BGP AS number to all your sites and expects you to deal with the aftermath.
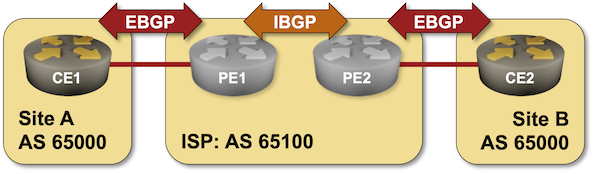
BGP Labs: Reuse BGP AS Number Across Sites
When I published the Bidirectional Route Redistribution lab exercise, some readers were quick to point out that you’ll probably have to reuse the same AS number across multiple sites in a real-life MPLS/VPN deployment. That’s what you can practice in today’s lab exercise – an MPLS/VPN service provider allocated the same BGP AS number to all your sites and expects you to deal with the aftermath.
Tech Bytes: AI-Powered Autonomous Digital Experience Management (Sponsored)
Autonomous Digital Experience Management (ADEM) provides detailed visibility into end user device and application performance. On today’s sponsored episode, we talk with Palo Alto Networks about how it uses AIOps with ADEM to help IT and help desk teams quickly identify and respond to problems for a distributed workforce. We also discuss synthetic transactions, and... Read more »5G Advanced Standards Set Stage for 6G Release
Recent 3GPP work on Releases 18 and 19 in areas such as AI/ML, MIMO, and power savings provide a starting point for future 6G standards.An overview of Cloudflare’s logging pipeline

One of the roles of Cloudflare's Observability Platform team is managing the operation, improvement, and maintenance of our internal logging pipelines. These pipelines are used to ship debugging logs from every service across Cloudflare’s infrastructure into a centralised location, allowing our engineers to operate and debug their services in near real time. In this post, we’re going to go over what that looks like, how we achieve high availability, and how we meet our Service Level Objectives (SLOs) while shipping close to a million log lines per second.
Logging itself is a simple concept. Virtually every programmer has written a Hello, World! program at some point. Printing something to the console like that is logging, whether intentional or not.
Logging pipelines have been around since the beginning of computing itself. Starting with putting string lines in a file, or simply in memory, our industry quickly outgrew the concept of each machine in the network having its own logs. To centralise logging, and to provide scaling beyond a single machine, we invented protocols such as the BSD Syslog Protocol to provide a method for individual machines to send logs over the network to a collector, providing a single pane of glass Continue reading
VXLAN/EVPN – Host ARP
In the last post Advertising IPs In EVPN Route Type 2, I described how to get IPs advertised in EVPN route type 2, but why do we need it? There are three main scenarios where having the MAC/IP mapping is useful:
- Host ARP.
- Host mobility.
- Host routing.
In this post I will cover the first use case and the topology below will be used:
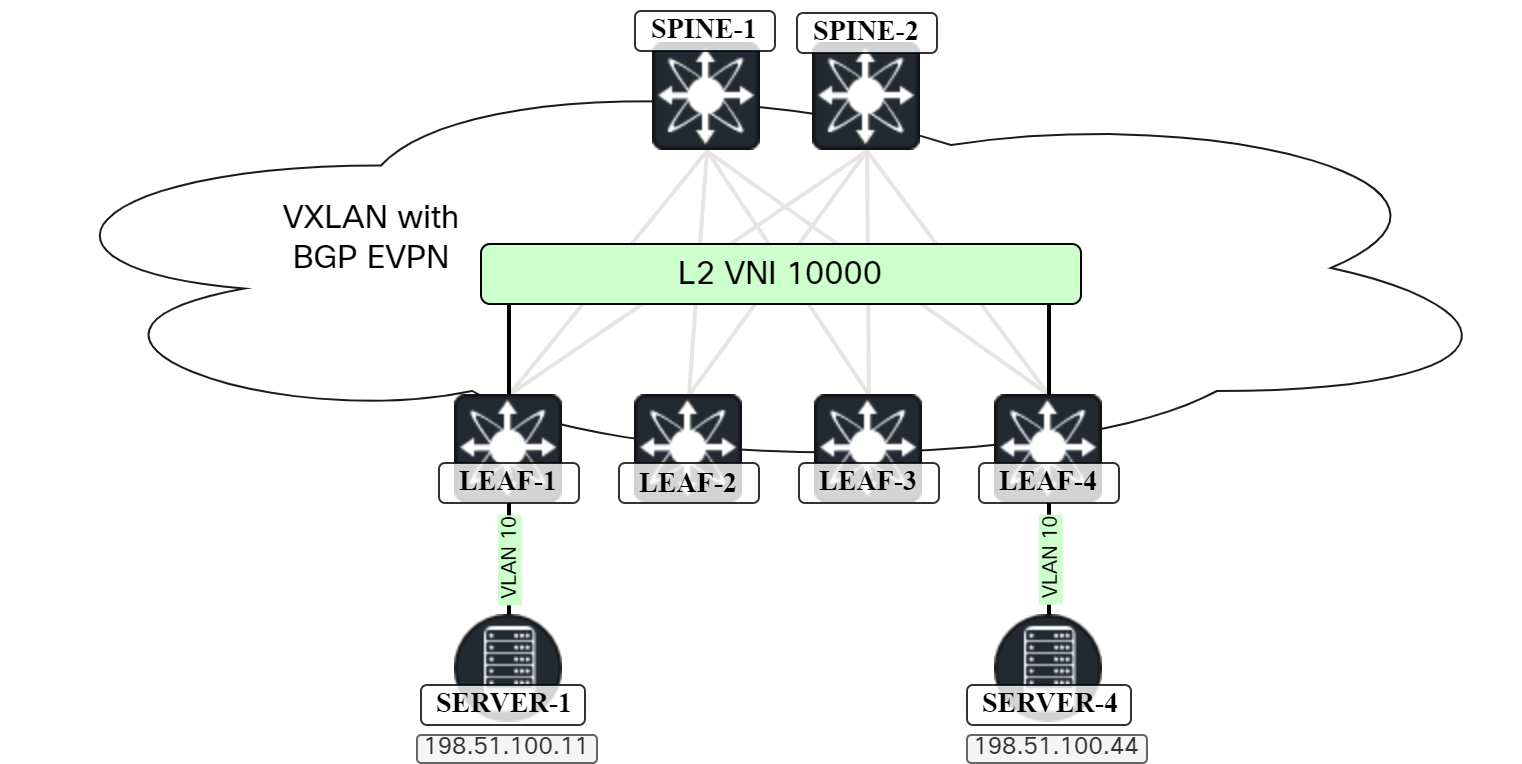
Host ARP
When two hosts in the same subnet want to send Ethernet frames to each other, they will ARP to discover the MAC address of the other host. This is no different in a VXLAN/EVPN network. The ARP frame, which is broadcast, will have to be flooded to other VTEPs either using multicast in the underlay or by ingress replication. Because the frame is broadcast, it will have to go to all the VTEPs that have that VNI. The scenario with ingress replication is shown below:
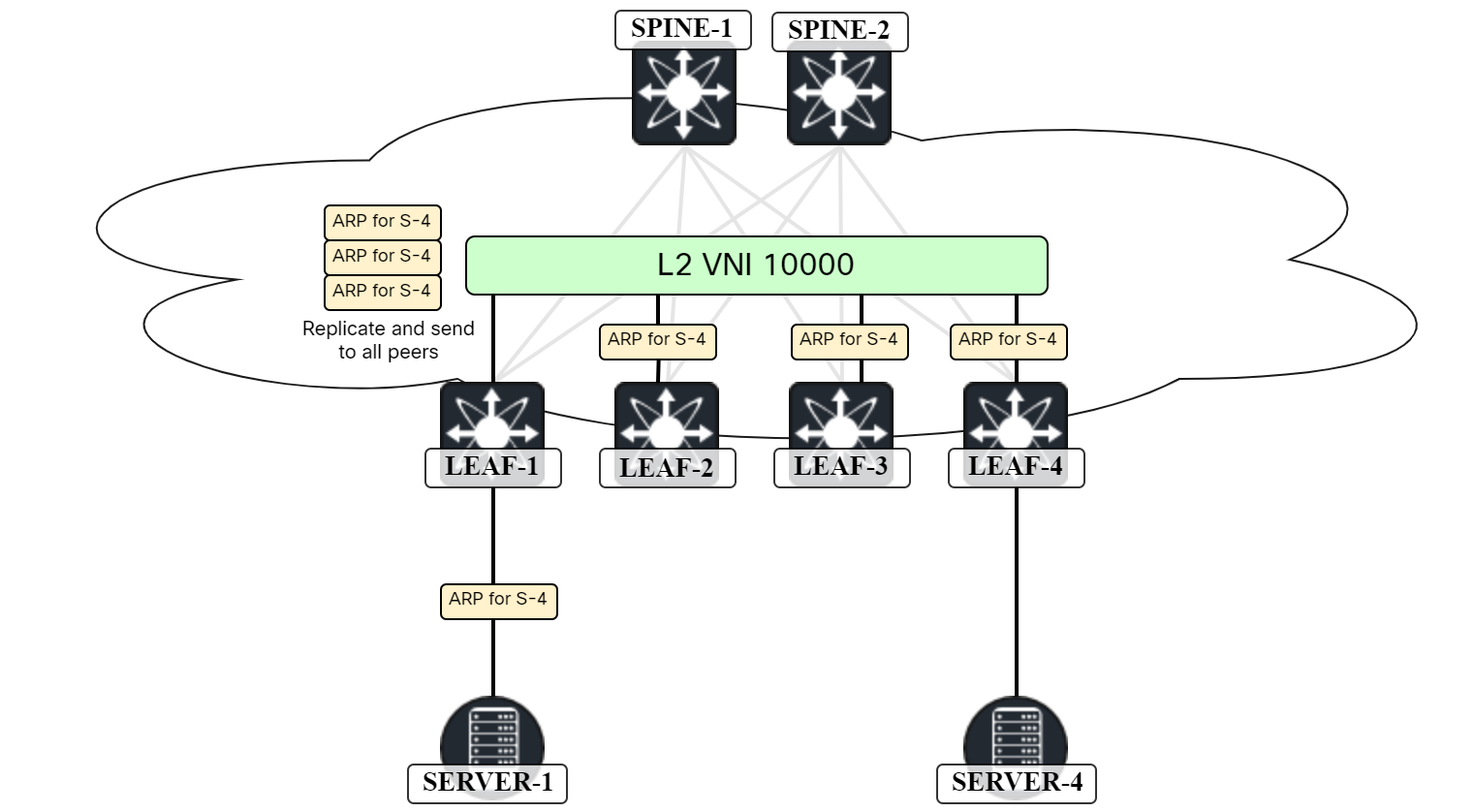
In this scenario, SERVER-1 is sending an ARP request to get the MAC address of SERVER-4. As all leafs are participating in the L2 VNI, LEAF-1 will perform ingress replication and send it to all leafs. However, sending the ARP request to LEAF-2 and LEAF-3 is not needed Continue reading
On Routing Protocol Metrics
This LinkedIn snippet just came in from the someone is not exactly right on the Internet department:
Unlike IGP protocols, BGP is not dependent on a single type of metric to choose the best path.
EIGRP is an immediate counterexample that brought the above quote to my attention, but it’s worth exploring the topic in more detail.