netlab: Test IPv6 IGP Deployment
Imagine you have an IPv4-only network1 and want to try out how to deploy a routing protocol for IPv6. netlab is a pretty good tool for the job as it:
Introducing Calico AI and Istio Ambient Mode
The Complexity of Modern Kubernetes Networking
Kubernetes has transformed how teams build and scale applications, but it has also introduced new layers of complexity. Platform and DevOps teams must now integrate and manage multiple technologies: CNI, ingress and egress gateways, service mesh, and more across increasingly large and dynamic environments. As more applications are deployed into Kubernetes clusters, the operational burden on these teams continues to grow, especially when maintaining performance, reliability, security, and observability across diverse workloads.
To address this complexity and tool sprawl, Tigera is incorporating Istio’s Ambient Service Mesh directly into the Calico Unified Network Security Platform. Service mesh has become the preferred solution for application-level networking, particularly in environments with a large number of services or highly regulated workloads. Among available service meshes, Istio stands out as the most popular and widely adopted, supported by a thriving open-source community. By leveraging the lightweight, sidecarless design of Istio Ambient Mode, Calico delivers all the benefits of service mesh, secure service-to-service communication, mTLS authentication, fine-grained authorization, traffic management, and observability, without the burden of sidecars.
Complementing this addition is Calico AI. Calico AI brings intelligence and automation to Kubernetes networking. It addresses the massive operational burden on teams Continue reading
Advertising Bogons (Or Was I?)
Been a while since I did a “War Stories” post - here’s one about a routing policy I screwed up recently. Gave me a fright that I’d really messed something up, but in the end it was no big deal, and it taught me something about who uses route collector info.
Uh-oh…we’re announcing bogons?
While looking at bgp.he.net/AS32590 for something unrelated, I saw this:

Investigating more, it tells me this:
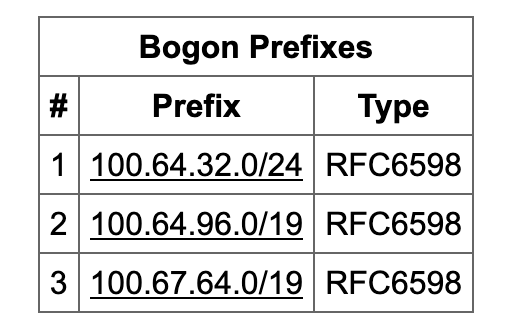
What the hell is going on? We should never be announcing bogon ranges to any peer. I rushed off to check some of our peering sessions, e.g
1
2
3
4
5
6
7
8
lindsayh@rtr> show route advertising-protocol bgp 86.104.125.69
inet.0: 1009955 destinations, 8974886 routes (1008431 active, 2 holddown, 2770 hidden)
Prefix Nexthop MED Lclpref AS path
* 155.133.226.0/24 Self I
* 155.133.229.0/24 Self I
* 155.133.250.0/24 Self I
* 162.254.197.0/24 Self I
We’re just advertising the normal set of prefixes I expect at that site. Defintely not advertising anything unusual to HE. So why do they think we’re advertising bogons?
Hmmm…Cloudflare Radar also says we’re announcing junk. Must Continue reading
Internet Evolution
This article is based on a presentation I made to the ARIN 56 meeting in October 2025. Here I'd like to elevate the typical Regional Internet Registry policy conversations above the day-to-day mundanities of address allocation policies with its vocabulary of address block sizes and needs-based justifications, fairness and efficiency and look more broadly at the context of the industry we operate in, and try to gain an understanding of where we are right now, and speculate on where it's all going.HN804: How Prisma SASE Builds on Public Clouds for Scale, Resiliency (Sponsored)
How do you architect a Secure Access Service Edge (SASE) to provide critical security services to millions of endpoints distributed across the planet? How do you build such a service for scale, performance, and resiliency? One option is to build your own PoPs or use colocation facilities, run your own infrastructure stack, and connect everything... Read more »Hedge 287: IPv6 in Planned Economies
Do planned economies, like China, have an advantage in deploying IPv6? What do the numbers on the DFZ show? George Michaelson joins Russ and Tom to discuss.
TNO049: Automated Network Testing and Validation
What does network testing and validation really mean? How do testing and validation fit within an automation workflow? Is it possible to run meaningful tests without coding skills? Dan Wade from BlueAlly answers these questions and offers practical insights into building trust in automation through test environments, using AI for ideation and problem-solving, and personal... Read more »DIY BYOIP: a new way to Bring Your Own IP prefixes to Cloudflare
When a customer wants to bring IP address space to Cloudflare, they’ve always had to reach out to their account team to put in a request. This request would then be sent to various Cloudflare engineering teams such as addressing and network engineering — and then the team responsible for the particular service they wanted to use the prefix with (e.g., CDN, Magic Transit, Spectrum, Egress). In addition, they had to work with their own legal teams and potentially another organization if they did not have primary ownership of an IP prefix in order to get a Letter of Agency (LOA) issued through hoops of approvals. This process is complex, manual, and time-consuming for all parties involved — sometimes taking up to 4–6 weeks depending on various approvals.
Well, no longer! Today, we are pleased to announce the launch of our self-serve BYOIP API, which enables our customers to onboard and set up their BYOIP prefixes themselves.
With self-serve, we handle the bureaucracy for you. We have automated this process using the gold standard for routing security — the Resource Public Key Infrastructure, RPKI. All the while, we continue to ensure the best quality of service by Continue reading
Lab: Adjust IS-IS Timers
Like any other routing protocol, IS-IS has several timers you can tweak to improve the convergence speed of your network, or make your network unstable (eventually breaking it completely) if you reduce them too much (if you care about fast convergence, you REALLY SHOULD use BFD).
You’ll find more details (and the opportunity to tweak the timers in a safe environment) in the Adjust IS-IS Timers lab exercise.

Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to feature/6-timers and execute netlab up.
What’s New in Calico – Fall 2025 Release
Simplify, Secure, and Scale Your Infrastructure
As organizations scale Kubernetes and hybrid infrastructures, many are realizing that more tools don’t mean better security. A recent Microsoft report found that organizations with 16+ point solutions see 2.8x more data security incidents than those with fewer tools. Yet platform teams are still expected to deliver resilience and performance across containers, VMs, and bare metal, often while juggling fragmented tools that introduce risk, downtime, and complexity.
The Fall 2025 release of Calico Enterprise and Calico Cloud cuts through that complexity. Its new features are designed to make your infrastructure more resilient, performant, and observable—right out of the box. From disaster recovery automation to modern data plane support and application traffic handling, these updates empower platform engineers to simplify operations while meeting strict reliability requirements.
The new features in this release can be grouped into two main categories:
1. Resilient, High-Performance Networking and Improved Quality of Service:
-
- High availability (HA) management planes for VM and bare metal hosts – Increases resiliency and helps reduce downtime.
- The official release (GA) of the nftables dataplane -Delivers faster and more scalable rule-processing than iptables.
- Maglev-Based Session Affinity – Maintain stable network traffic flow during failures Continue reading
IPB187: IPv6 RFC Updates
Today the IPv6 Buzz crew provides updates on the latest in IPv6 standards, RFCs, and best practices. They break down the recent discussions around RFC 6052, explore the options for RFC 8215, and share Nick’s spin on the now defunct testipv6.com site. Episode Links: RFC 6052 RFC 8215 RFC 6598 IPv6.armyN4N042: Meet MACsec
MACsec is a protocol for encrypting Ethernet frames on a local (though not always local) network. Ethan Banks and Holly Metlitzky have an ELI5 (explain like I’m 5) discussion as to what exactly is MACsec and how it differs from IPsec. They talk about when and whether you need to implement MACsec with all the... Read more »Extract audio from your videos with Cloudflare Stream
Cloudflare Stream loves video. But we know not every workflow needs the full picture, and the popularity of podcasts highlights how compelling stand-alone audio can be. For developers, processing a video just to access audio is slow, costly, and complex.
What makes video so expensive? A video file is a dense stack of high-resolution images, stitched together over time. As such, it is not just “one file” — it’s a container of high-dimensional data such as frames per second, resolution, codecs. Analyzing video means traversing time resolution frame rate.
By comparison, an audio file is far simpler. If an audio file consists of only one channel, it is defined as a single waveform. The technical characteristics of this waveform are defined by the sample rate (the number of audio samples taken per second), and the bit depth (the precision of each sample).
With the rise of computationally intensive AI inference pipelines, many of our customers want to perform downstream workflows that require only analyzing the audio. For example:
Power AI and Machine Learning: In addition to translation and transcription, you can feed the audio into Voice-to-Text models for speech recognition or analysis, or AI-powered summaries.
Improve Continue reading
Async QUIC and HTTP/3 made easy: tokio-quiche is now open-source
A little over 6 years ago, we presented quiche, our open source QUIC implementation written in Rust. Today we’re announcing the open sourcing of tokio-quiche, our battle-tested, asynchronous QUIC library combining both quiche and the Rust Tokio async runtime. Powering Cloudflare’s Proxy B in Apple iCloud Private Relay and our next-generation Oxy-based proxies, tokio-quiche handles millions of HTTP/3 requests per second with low latency and high throughput. tokio-quiche also powers Cloudflare Warp’s MASQUE client, replacing our WireGuard tunnels with QUIC-based tunnels, and the async version of h3i.
quiche was developed as a sans-io library, meaning that it implements the state machine required to handle the QUIC transport protocol while not making any assumptions about how its user intends to perform IO. This means that, with enough elbow grease, anyone can write an IO integration with quiche! This entails connecting or listening on a UDP socket, managing sending and receiving UDP datagrams on that socket while feeding all network information to quiche. Given we need this integration to be async, we’d have to do all this while integrating with an async Rust runtime. tokio-quiche does all of that for you, no grease required.
Lowering the barrier to Continue reading
Presentation: Testing Disaster Recovery Designs
Someone asked for my DEEP 2025 presentation (Testing Disaster Recovery Designs). You can download it here (no strings attached). I hope you’ll find it interesting.
The organizers plan to make the recorded videos public after a few months. Of course, I’ll post a link when they do that.
