TNO040: From ARPANET to the Stars: Vint Cerf on the Past and Future of the Internet
Vint Cerf, widely recognized as one of the fathers of the Internet, is today’s special guest on Total Network Operations. He currently serves as Vice President and Chief Internet Evangelist at Google. His pioneering work began back in the 1960’s when he was involved in the ARPANET project. Alongside Bob Kahn, Vint co-invented the TCP/IP... Read more »Automating threat analysis and response with Cloudy
Security professionals everywhere face a paradox: while more data provides the visibility needed to catch threats, it also makes it harder for humans to process it all and find what's important. When there’s a sudden spike in suspicious traffic, every second counts. But for many security teams — especially lean ones — it’s hard to quickly figure out what’s going on. Finding a root cause means diving into dashboards, filtering logs, and cross-referencing threat feeds. All the data tracking that has happened can be the very thing that slows you down — or worse yet, what buries the threat that you’re looking for.
Today, we’re excited to announce that we’ve solved that problem. We’ve integrated Cloudy — Cloudflare’s first AI agent — with our security analytics functionality, and we’ve also built a new, conversational interface that Cloudflare users can use to ask questions, refine investigations, and get answers. With these changes, Cloudy can now help Cloudflare users find the needle in the digital haystack, making security analysis faster and more accessible than ever before.
Since Cloudly’s launch in March of this year, its adoption has been exciting to watch. Over 54,000 users have tried Cloudy for custom Continue reading
The crawl-to-click gap: Cloudflare data on AI bots, training, and referrals
In 2025, Generative AI is reshaping how people and companies use the Internet. Search engines once drove traffic to content creators through links. Now, AI training crawlers — the engines behind commonly-used LLMs — are consuming vast amounts of web data, while sending far fewer users back. We covered this shift, along with related trends and Cloudflare features (like pay per crawl) in early July. Studies from Pew Research Center (1, 2) and Authoritas already point to AI overviews — Google’s new AI-generated summaries shown at the top of search results — contributing to sharp declines in news website traffic. For a news site, this means lots of bot hits, but far fewer real readers clicking through — which in turn means fewer people clicking on ads or chances to convert to subscriptions.
Cloudflare's data shows the same pattern. Crawling by search engines and AI services surged in the first half of 2025 — up 24% year-over-year in June — before slowing to just 4% year-over-year growth in July. How is the space evolving? Which crawling purposes are most common, and how is that changing? Spoiler: training-related crawling is leading the way. In this post, we track Continue reading
Troubleshooting network connectivity and performance with Cloudflare AI
Monitoring a corporate network and troubleshooting any performance issues across that network is a hard problem, and it has become increasingly complex over time. Imagine that you’re maintaining a corporate network, and you get the dreaded IT ticket. An executive is having a performance issue with an application, and they want you to look into it. The ticket doesn’t have a lot of details. It simply says: “Our internal documentation is taking forever to load. PLS FIX NOW”.
In the early days of IT, a corporate network was built on-premises. It provided network connectivity between employees that worked in person and a variety of corporate applications that were hosted locally.
The shift to cloud environments, the rise of SaaS applications, and a “work from anywhere” model has made IT environments significantly more complex in the past few years. Today, it’s hard to know if a performance issue is the result of:
An employee’s device
Their home or corporate wifi
The corporate network
A cloud network hosting a SaaS app
An intermediary ISP
A performance ticket submitted by an employee might even be a combination of multiple performance issues all wrapped together into one nasty problem.
Cloudflare built Cloudflare One, Continue reading
Cloudflare is the best place to build realtime voice agents
The way we interact with AI is fundamentally changing. While text-based interfaces like ChatGPT have shown us what's possible, in terms of interaction, it’s only the beginning. Humans communicate not only by texting, but also talking — we show things, we interrupt and clarify in real-time. Voice AI brings these natural interaction patterns to our applications.
Today, we're excited to announce new capabilities that make it easier than ever to build real-time, voice-enabled AI applications on Cloudflare's global network. These new features create a complete platform for developers building the next generation of conversational AI experiences or can function as building blocks for more advanced AI agents running across platforms.
We're launching:
Cloudflare Realtime Agents - A runtime for orchestrating voice AI pipelines at the edge
Pipe raw WebRTC audio as PCM in Workers - You can now connect WebRTC audio directly to your AI models or existing complex media pipelines already built on
Workers AI WebSocket support - Realtime AI inference with models like PipeCat's smart-turn-v2
Deepgram on Workers AI - Speech-to-text and text-to-speech running in over 330 cities worldwide
Today, building voice AI applications is hard. You need to coordinate multiple services such Continue reading
Cloudy Summarizations of Email Detections: Beta Announcement
Organizations face continuous threats from phishing, business email compromise (BEC), and other advanced email attacks. Attackers adapt their tactics daily, forcing defenders to move just as quickly to keep inboxes safe.
Cloudflare’s visibility across a large portion of the Internet gives us an unparalleled view of malicious campaigns. We process billions of email threat signals every day, feeding them into multiple AI and machine learning models. This lets our detection team create and deploy new rules at high speed, blocking malicious and unwanted emails before they reach the inbox.
But rapid protection introduces a new challenge: making sure security teams understand exactly what we blocked — and why.
Cloudflare’s fast-moving detection pipeline is one of our greatest strengths — but it also creates a communication gap for customers. Every day, our detection analysts publish new rules to block phishing, BEC, and other unwanted messages. These rules often blend signals from multiple AI and machine learning models, each looking at different aspects of a message like its content, headers, links, attachments, and sender reputation.
While this layered approach catches threats early, SOC teams don’t always have insight into the specific combination of factors that triggered a Continue reading
iBGP Local-AS Route Propagation
In the previous blog post on this topic, I described the iBGP local-as functionality and explained why we MUST change the BGP next hop on the routes sent over the fake iBGP session (TL&DR: because we’re not running IGP across that link).
That blog post used a simple topology with three routers. Now let’s add a few more routers to the mix and see what happens.
IPB182: IPv6 Transition Technology Options
Transitioning from IPv4 to IPv6, or at least IPv6-mostly, is no easy task. Today’s show provides some education and advice about IPv6 transition mechanisms. We cover options such as NAT64, DNS64, PREF64, and more, as well as use cases. Also, if your technology vendors aren’t offering some of these mechanisms, ask for them – you’re... Read more »Running Palo Alto Firewalls on Proxmox

If you follow me or my blog, you may know that I moved my homelab to Proxmox. Even though I already have a physical Palo Alto firewall, I also needed to set up a Palo Alto VM. After some reading and research, and with the help of a great guide I found, I managed to get Palo Alto running on Proxmox. I thought it would be useful to write a post about it for anyone else trying to do the same.
At a high level, you need to download the Palo Alto QCOW image. I’m using PAN-OS 11.2.5 and downloaded the image called PA-VM-KVM-11.2.5.qcow2. You will also need multiple network interfaces on Proxmox. With Palo Alto, you need at least two to begin with, one for management and one for data.
When I say Proxmox interfaces or NICs, I mean the virtual network adapters that you can assign to your VM. These map to your physical or virtual bridges on the Proxmox host, and they let you connect the firewall VM to different parts of your network.
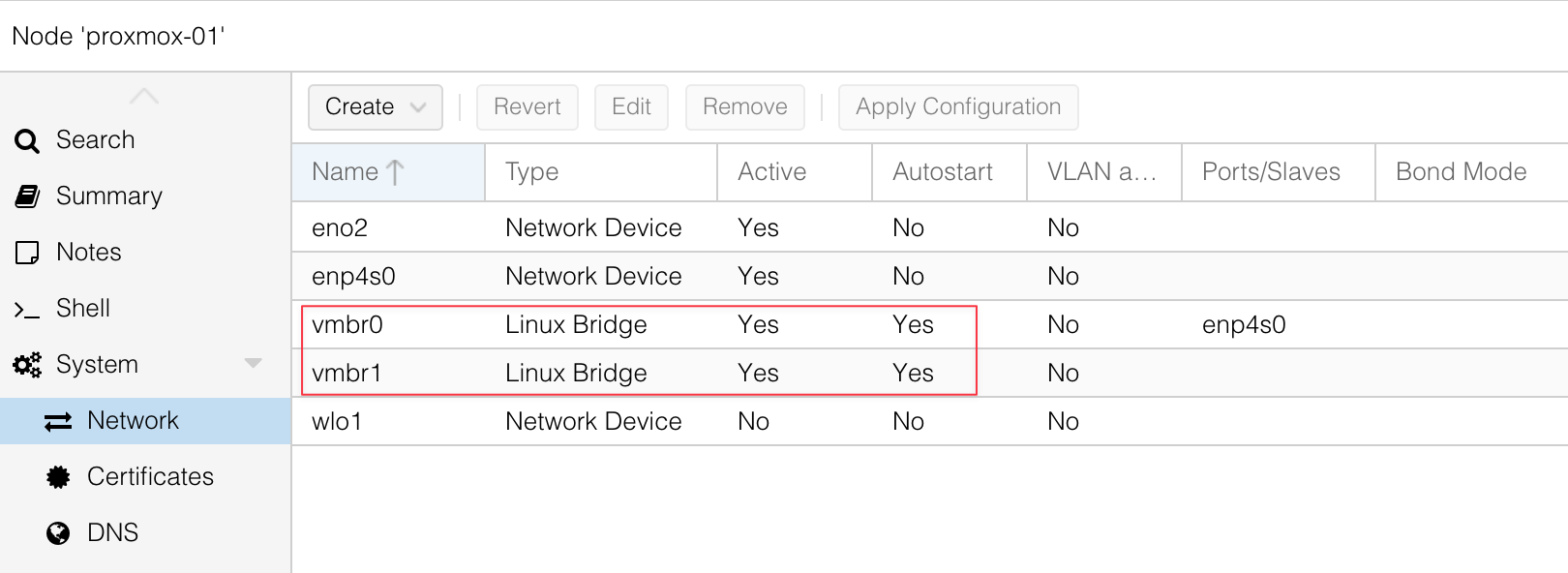
The first step is to copy the Palo Alto QCOW image over to Continue reading
N4N037: IPsec Basics
It’s time to talk crypto. No, not the Bitcoin kind. Ethan and Holly introduce the basics of IPsec, the protocol that authenticates and encrypts traffic between endpoints. They discuss what it is, how it provides trustworthiness and secrecy to IP traffic, and common use cases. They review the different types of IPsec protocols and modes,... Read more »A deeper look at AI crawlers: breaking down traffic by purpose and industry
Search platforms historically crawled web sites with the implicit promise that, as the sites showed up in the results for relevant searches, they would send traffic on to those sites — in turn leading to ad revenue for the publisher. This model worked fairly well for several decades, with a whole industry emerging around optimizing content for optimal placement in search results. It led to higher click-through rates, more eyeballs for publishers, and, ideally, more ad revenue. However, the emergence of AI platforms over the last several years, and the incorporation of AI "overviews" into classic search platforms, has turned the model on its head. When users turn to these AI platforms with queries that used to go to search engines, they often won't click through to the original source site once an answer is provided — and that assumes that a link to the source is provided at all! No clickthrough, no eyeballs, and no ad revenue.
To provide a perspective on the scope of this problem, Radar launched crawl/refer ratios on July 1, based on traffic seen across our whole customer base. These ratios effectively compare the number of crawling requests for HTML pages from the crawler Continue reading
Evaluating image segmentation models for background removal for Images
Last week, we wrote about face cropping for Images, which runs an open-source face detection model in Workers AI to automatically crop images of people at scale.
It wasn’t too long ago when deploying AI workloads was prohibitively complex. Real-time inference previously required specialized (and costly) hardware, and we didn’t always have standard abstractions for deployment. We also didn’t always have Workers AI to enable developers — including ourselves — to ship AI features without this additional overhead.
And whether you’re skeptical or celebratory of AI, you’ve likely seen its explosive progression. New benchmark-breaking computational models are released every week. We now expect a fairly high degree of accuracy — the more important differentiators are how well a model fits within a product’s infrastructure and what developers do with its predictions.
This week, we’re introducing background removal for Images. This feature runs a dichotomous image segmentation model on Workers AI to isolate subjects in an image from their backgrounds. We took a controlled, deliberate approach to testing models for efficiency and accuracy.
Here’s how we evaluated various image segmentation models to develop background removal.
In computer vision, image segmentation is the process of splitting Continue reading
The next step for content creators in working with AI bots: Introducing AI Crawl Control
Empowering content creators in the age of AI with smarter crawling controls and direct communication channels
Imagine you run a regional news site. Last month an AI bot scraped 3 years of archives in minutes — with no payment and little to no referral traffic. As a small company, you may struggle to get the AI company's attention for a licensing deal. Do you block all crawler traffic, or do you let them in and settle for the few referrals they send?
It’s picking between two bad options.
Cloudflare wants to help break that stalemate. On July 1st of this year, we declared Content Independence Day based on a simple premise: creators deserve control of how their content is accessed and used. Today, we're taking the next step in that journey by releasing AI Crawl Control to general availability — giving content creators and AI crawlers an important new way to communicate.
Today, we're rebranding our AI Audit tool as AI Crawl Control and moving it from beta to general availability. This reflects the tool's evolution from simple monitoring to detailed insights and control over how AI systems can access your content.
The Continue reading
Make Your Website Conversational for People and Agents with NLWeb and AutoRAG
Publishers and content creators have historically relied on traditional keyword-based search to help users navigate their website’s content. However, traditional search is built on outdated assumptions: users type in keywords to indicate intent, and the site returns a list of links for the most relevant results. It’s up to the visitor to click around, skim pages, and piece together the answer they’re looking for.
AI has reset expectations and that paradigm is breaking: how we search for information has fundamentally changed.
Users no longer want to search websites the old way. They’re used to interacting with AI systems like Copilot, Claude, and ChatGPT, where they can simply ask a question and get an answer. We’ve moved from search engines to answer engines.
At the same time, websites now have a new class of visitors, AI agents. Agents face the same pain with keyword search: they have to issue keyword queries, click through links, and scrape pages to piece together answers. But they also need more: a structured way to ask questions and get reliable answers across websites. This means that websites need a way to give the agents they trust controlled access, so Continue reading
The age of agents: cryptographically recognizing agent traffic
On the surface, the goal of handling bot traffic is clear: keep malicious bots away, while letting through the helpful ones. Some bots are evidently malicious — such as mass price scrapers or those testing stolen credit cards. Others are helpful, like the bots that index your website. Cloudflare has segmented this second category of helpful bot traffic through our verified bots program, vetting and validating bots that are transparent about who they are and what they do.
Today, the rise of agents has transformed how we interact with the Internet, often blurring the distinctions between benign and malicious bot actors. Bots are no longer directed only by the bot owners, but also by individual end users to act on their behalf. These bots directed by end users are often working in ways that website owners want to allow, such as planning a trip, ordering food, or making a purchase.
Our customers have asked us for easier, more granular ways to ensure specific bots, crawlers, and agents can reach their websites, while continuing to block bad actors. That’s why we’re excited to introduce signed agents, an extension of our verified bots program that gives a new bot Continue reading
Network Automation Reality Check with William Collins
In early August, William Collins invited me to chat about a sarcastic comment I made about a specific automation tool I have a love-hate relationship with on LinkedIn.
We quickly agreed not to go (too deep) into tool-bashing. Instead, we discussed the eternal problems of network automation, from unhealthy obsession with tools to focus on point solutions while lacking the bigger picture or believing in vendor-delivered nirvana.
Troubleshooting OT Security: Why IT-Site1 Can’t Ping OT_Site1R
I’ve been having an absolute blast playing in a lab environment for OT Security. It is this wicked cool setup I got the great fortune to play, I mean work, in. So much more is coming and I admit I... Read More ›
The post Troubleshooting OT Security: Why IT-Site1 Can’t Ping OT_Site1R appeared first on Networking with FISH.
D2DO280: Architect for Your AI Success With F5 and MinIO (Sponsored)
In the changing landscape of AI data infrastructure, F5 and MinIO are partnering on a solution that brings together the best of each company. This solution bookends the AI stack—it uses F5 for reliable, secure, and observable data delivery and MinIO’s AIStor for storage of all data types. The goal is to help organizations be... Read more »AI Gateway now gives you access to your favorite AI models, dynamic routing and more — through just one endpoint
Getting the observability you need is challenging enough when the code is deterministic, but AI presents a new challenge — a core part of your user’s experience now relies on a non-deterministic engine that provides unpredictable outputs. On top of that, there are many factors that can influence the results: the model, the system prompt. And on top of that, you still have to worry about performance, reliability, and costs.
Solving performance, reliability and observability challenges is exactly what Cloudflare was built for, and two years ago, with the introduction of AI Gateway, we wanted to extend to our users the same levels of control in the age of AI.
Today, we’re excited to announce several features to make building AI applications easier and more manageable: unified billing, secure key storage, dynamic routing, security controls with Data Loss Prevention (DLP). This means that AI Gateway becomes your go-to place to control costs and API keys, route between different models and providers, and manage your AI traffic. Check out our new AI Gateway landing page for more information at a glance.
When using an AI provider, you typically have to sign up for Continue reading
How we built the most efficient inference engine for Cloudflare’s network
Inference powers some of today’s most powerful AI products: chat bot replies, AI agents, autonomous vehicle decisions, and fraud detection. The problem is, if you’re building one of these products on top of a hyperscaler, you’ll likely need to rent expensive GPUs from large centralized data centers to run your inference tasks. That model doesn’t work for Cloudflare — there’s a mismatch between Cloudflare’s globally-distributed network and a typical centralized AI deployment using large multi-GPU nodes. As a company that operates our own compute on a lean, fast, and widely distributed network within 50ms of 95% of the world’s Internet-connected population, we need to be running inference tasks more efficiently than anywhere else.
This is further compounded by the fact that AI models are getting larger and more complex. As we started to support these models, like the Llama 4 herd and gpt-oss, we realized that we couldn’t just throw money at the scaling problems by buying more GPUs. We needed to utilize every bit of idle capacity and be agile with where each model is deployed.
After running most of our models on the widely used open source inference and serving engine vLLM, we figured out it Continue reading