PP061: Comparing Breach Reports, RSAC 2025 Highlights, and a Security Awareness Soapbox
New breach reports show threat actor dwell times are dropping significantly. It’s a positive development, but there is a caveat. We discuss this caveat and other findings from the 2025 editions of the Verizon Data Breach Investigations Report and the Google M-Trends Report. We also get highlights from the 2025 RSA Conference, and JJ gets... Read more »HS103: Why IT Is Like Ultimate Frisbee
It’s all well and good to develop a technology strategy, articulate and document the strategy, and agree (supposedly) on that strategy. But what do you do when one or more of the tech teams act in apparent opposition to the strategy? John and Johna discuss why this happens and what questions you need to ask... Read more »OSPF Loop Prevention with Area Range Summary LSAs
In a previous blog post, I described how OSPF route selection rules prevent a summary LSA from being inserted back into an area from which it was generated. That works nicely for area prefixes turned directly into summary LSAs, but how does the loop prevention logic work for summarized prefixes (what OSPF calls area ranges)?
TL&DR: It doesn’t, unless… ;)
NB525: Cisco, IBM Recruit AI for Threat Response; HPE Air-Gaps Private Clouds
Take a Network Break! This week we catch up on the Airborne vulnerabilities affecting Apple’s AirPlay protocol and SDK, and get an update on active exploits against an SAP NetWeaver vulnerability–a patch is available, so get fixing if you haven’t already. Palo Alto Networks launches the AIRS platform to address AI threats in the enterprise,... Read more »Multi-vendor support for dropped packet notifications

The sFlow Dropped Packet Notification Structures extension was published in October 2020. Extending sFlow to provide visibility into dropped packets offers significant benefits for network troubleshooting, providing real-time network wide visibility into the specific packets that were dropped as well the reason the packet was dropped. This visibility instantly reveals the root cause of drops and the impacted connections. Packet discard records complement sFlow's existing counter polling and packet sampling mechanisms and share a common data model so that all three sources of data can be correlated, for example, packet sampling reveals the top consumers of bandwidth on a link, helping to get to the root cause of congestion related packet drops reported for the link.
Today the following network operating systems include support for the drop notification extension in their sFlow agent implementations:
- Arista Dropped packet notifications with Arista Networks
- Cisco Dropped packet notifications with Cisco 8000 Series Routers
- Linux Linux as a network operating systemUsing sFlow to monitor dropped packets
- NVIDIA NVIDIA Cumulus Linux 5.11 for AI / ML
- VyOS VyOS 1.4 LTS released
Two additional sFlow dropped packet notification implementations are in the pipeline and should be available later this year:
- SONiC The Switch Continue reading
Scaling with safety: Cloudflare’s approach to global service health metrics and software releases
Has your browsing experience ever been disrupted by this error page? Sometimes Cloudflare returns "Error 500" when our servers cannot respond to your web request. This inability to respond could have several potential causes, including problems caused by a bug in one of the services that make up Cloudflare's software stack.

We know that our testing platform will inevitably miss some software bugs, so we built guardrails to gradually and safely release new code before a feature reaches all users. Health Mediated Deployments (HMD) is Cloudflare’s data-driven solution to automating software updates across our global network. HMD works by querying Thanos, a system for storing and scaling Prometheus metrics. Prometheus collects detailed data about the performance of our services, and Thanos makes that data accessible across our distributed network. HMD uses these metrics to determine whether new code should continue to roll out, pause for further evaluation, or be automatically reverted to prevent widespread issues.
Cloudflare engineers configure signals from their service, such as alerting rules or Service Level Objectives (SLOs). For example, the following Service Level Indicator (SLI) checks the rate of HTTP 500 errors over 10 minutes returned from a service in our software stack.
sum(rate(http_request_count{code="500"}[10m])) Continue readingIS-IS Behavior on Multi-Access Networks
In many ways, IS-IS is a simpler, and perhaps more elegant, routing protocol than OSPF. However, it often gets misunderstood. Perhaps due to its roots in OSI or perhaps because it’s not as widely deployed as OSPF. Some of the confusion come from how it behaves on multi-access networks. What is a Designated Intermediate System (DIS)? Why do we need a pseudonode? How do we flood Link State PDUs (LSPs)? In this post, I’ll cover all of that and more. This is going to be a deep dive so save this blog for when you have some time to focus.
IS-IS is a link state protocol, which means that we need to build a link state database that describes how all the intermediate systems (routers) are interconnected, and what prefixes they are associated with. Simply put, we need to build a graph. Let’s do a quick recap of graph theory.
A graph consists of vertices (nodes) and edges (links). When referring to a single node, it’s called a vertex. This is shown below:
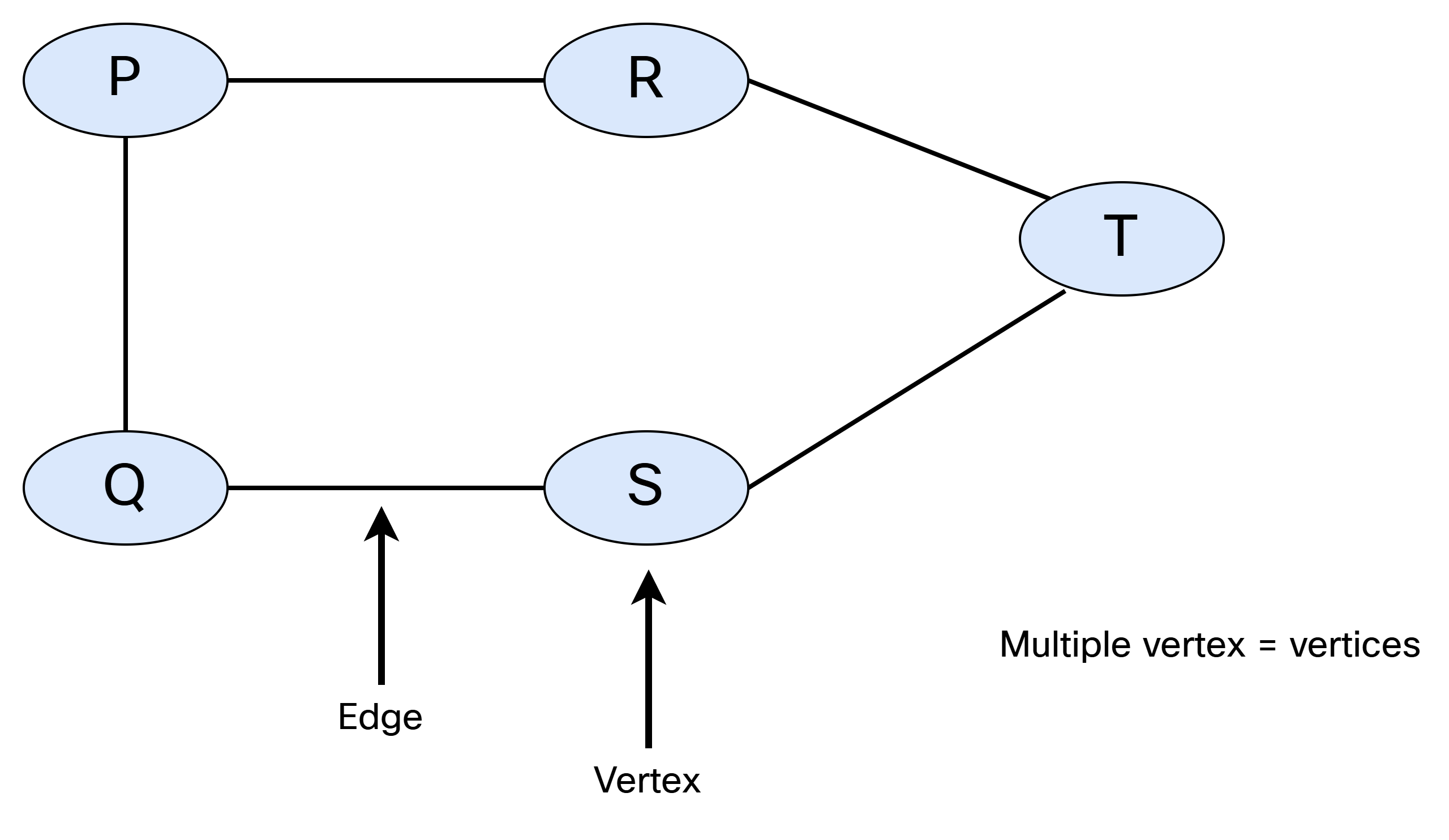
There are different types of graphs. They can be undirected and unweighted:

With this type of graph, there is no weight assigned and there is no way Continue reading
Analysis of a Route Leak
The way we've organised the Internet's routing system seems to be just too informal, too anarchic and too unstable to form the foundation of the world’s communication system. Yet, here we are. And, surprisingly, it works! Well, it mostly works, most of the time. From time to time anomalous things happen. In this article I’d like to analyse just one of the instances when things didn’t go according to plan, showing how the routing anomaly was visible, and how it could be mitigated.AI for Network Engineers: Rail Desings in GPU Fabric
When building a scalable, resilient GPU network fabric, the design of the rail layer, the portion of the topology that interconnects GPU servers via Top-of-Rack (ToR) switches, plays a critical role. This section explores three different models: Multi-rail-per-switch, Dual-rail-per-switch, and Single-rail-per-switch. All three support dual-NIC-per-GPU designs, allowing each GPU to connect redundantly to two separate switches, thereby removing the Rail switch as a single point of failure.
Multi-Rail-per-Switch
In this model, multiple small subnets and VLANs are configured per switch, with each logical rail mapped to a subset of physical interfaces. For example, a single 48-port switch might host four or eight logical rails using distinct Layer 2 and Layer 3 domains. Because all logical rails share the same physical device, isolation is logical. As a result, a hardware or software failure in the switch can impact all rails and their associated GPUs, creating a large failure domain.
This model is not part of NVIDIA’s validated Scalable Unit (SU) architecture but may suit test environments, development clusters, or small-scale GPU fabrics where hardware cost efficiency is a higher priority than strict fault isolation. From a CapEx perspective, multi-rail-per-switch is the most economical, requiring fewer switches.
Figure 13-10 illustrates the Continue reading
From Python to Go 020. Concurrency and Parallelism Of Code Executions.
Hello my friend,
Today’s topic is critical to complete full picture of software development for network automation. Today’s topic is what allows you to conduct your tasks within meaningful time frame, especially when you have a lot of network devices, servers, virtual machines to manage. Today’s topic is concurrency of code execution in Python and Golang.
What Other Programming Languages Makes Sense To Study?
There are more than 100 programming languages out there. Some of them are quite universal and allow development of almost any kind of application. Others are more specific. Python is probably the most universal programming language, from what I’ve worked with or heard of. It can be used in infrastructure management at scale (e.g., OpenStack is written in Python), web applications, data science and many more. Golang is much more low-level compared to Python and, therefore, way more performant. Various benchmarks available online suggests that the same business tasks could be 3-30 times quicker in Golang compared to Python; therefore Golang is suitable for system programing (e.g, Kubernetes and Docker are created in Go). That’s what we cover in our blogs. Apart from them there are a lot of other: C/C++ if you Continue reading
HN779: Do We Really Need the Modern Networking Stack?
On today’s Heavy Networking, a roundtable panel considers whether a modern network needs to be built around underlays and overlays. This isn’t just Ethan yelling at clouds. This is a legitimate question pondering the real-world value of an overlay/underlay approach. Is overlay everywhere overkill, or is that the architecture we need to deliver a safe,... Read more »TNO027: Seeing the Internet With Doug Madory
Doug Madory has been called “The Man Who Can See the Internet.” Doug has developed a reputation for identifying significant developments in the global layout of the internet. He joins us today to discuss his role in analyzing internet data to identify trends and insights. He shares his journey from a data QA position to... Read more »IPB174: How Enterprise IPv6 Requirements Are Shaping Microsoft Windows
Today we talk with Tommy Jensen, a Senior Technical PM Strategist at Microsoft, about IPv6 support in Windows. Tommy shares what he hears from enterprises that are moving toward IPv6-mostly, strategies for dealing with older applications and devices that expect IPv4, and how the customer conversations he’s having about IPv6 now are more engaged and... Read more »Hedge 268: Will AI take our jobs?
One of the “great fears” advancing AI unlocks is that most of our jobs can, and will, be replaced by various forms of AI. Join us on this episode of the Hedge as Jonathan Mast at White Beard Strategies, Tom Ammon, and Russ White discuss whether we are likely to see a net loss, gain, or wash in jobs as companies deploy LLMS, and other potential up- and down-sides.
download
N4N024: DNS Security, Record Types, and Reverse DNS
This week we continue with DNS. In our last episode we covered the basics; today we expand our scope to cover topics such as security for DNS, reverse DNS, and DNS record types. For dessert this week, a serving of Raspberry Pi and Happy Eyeballs. Episode Links: DNS: Turning Names into Numbers – N Is... Read more »Thirteen new MCP servers from Cloudflare you can use today
You can now connect to Cloudflare's first publicly available remote Model Context Protocol (MCP) servers from Claude.ai (now supporting remote MCP connections!) and other MCP clients like Cursor, Windsurf, or our own AI Playground. Unlock Cloudflare tools, resources, and real time information through our new suite of MCP servers including:
| Server | Description |
|---|---|
| Cloudflare Documentation server | Get up to date reference information from Cloudflare Developer Documentation |
| Workers Bindings server | Build Workers applications with storage, AI, and compute primitives |
| Workers Observability server | Debug and get insight into your Workers application’s logs and analytics |
| Container server | Spin up a sandbox development environment |
| Browser rendering server | Fetch web pages, convert them to markdown and take screenshots |
| Radar server | Get global Internet traffic insights, trends, URL scans, and other utilities |
| Logpush server | Get quick summaries for Logpush job health |
| AI Gateway server | Search your logs, get details about the prompts and responses |
| AutoRAG server | List and search documents on your AutoRAGs |
| Audit Logs server | Query audit logs and generate reports for review |
| DNS Analytics server | Optimize DNS performance and debug issues based on current set up |
| Digital Experience Monitoring server | Get quick insight on critical applications for your organization |
| Cloudflare One CASB Continue reading |
MCP Demo Day: How 10 leading AI companies built MCP servers on Cloudflare
Today, we're excited to collaborate with Anthropic, Asana, Atlassian, Block, Intercom, Linear, PayPal, Sentry, Stripe, and Webflow to bring a whole new set of remote MCP servers, all built on Cloudflare, to enable Claude users to manage projects, generate invoices, query databases, and even deploy full stack applications — without ever leaving the chat interface.
Since Anthropic’s introduction of the Model Context Protocol (MCP) in November, there’s been more and more excitement about it, and it seems like a new MCP server is being released nearly every day. And for good reason! MCP has been the missing piece to make AI agents a reality, and helped define how AI agents interact with tools to take actions and get additional context.
But to date, end-users have had to install MCP servers on their local machine to use them. Today, with Anthropic’s announcement of Integrations, you can access an MCP server the same way you would a website: type a URL and go.

At Cloudflare, we’ve been focused on building out the tooling that simplifies the development of remote MCP servers, so that our customers’ engineering teams can focus their time on building out the MCP tools for their Continue reading