Intel’s Chips No Longer Pay More Than Their Fair Share Of Foundry Costs
The biggest benefit that is coming from the separation of the Intel chip design and marketing business from its foundry operations is that Intel’s chip product groups no longer have to shoulder the totality of the immense costs of its manufacturing operations. …
Intel’s Chips No Longer Pay More Than Their Fair Share Of Foundry Costs was written by Timothy Prickett Morgan at The Next Platform.
Hedge 220: The Cost of the Cloud
Cloud services are all the rage right now, but are they worth it? There are many aspects to the question, and the answer is almost always going to be “it depends.” Do you really need to spin up capacity more quickly than you can buy hardware and get it running? Do you really need to be able to spin capacity down without leaving any hardware behind? Is cloud really the best use of your team’s time and talent?
David Heinemeier Hansson joins Tom and Russ to talk about the economics and uses of cloud, and why his company has moved away from public cloud services.
IPB148: Microsoft to Expand CLAT Support in Windows 11
Today Tom, Scott, and Ed discuss the exciting announcement in IPv6 world: Microsoft is expanding its CLAT support in Windows 11. This means enterprises can be even more comfortable transitioning to a IPv6-only network: Now not only do they have DNS64 and NAT64 to translate IPv4 to IPv6, but they have CLAT for any apps... Read more »Celestial AI Wants To Break The Memory Wall, Fuse HBM With DDR5
In 2024, there is no shortage of interconnects if you need to stitch tens, hundreds, thousands, or even tens of thousands of accelerators together. …
Celestial AI Wants To Break The Memory Wall, Fuse HBM With DDR5 was written by Tobias Mann at The Next Platform.
New tools for production safety — Gradual deployments, Source maps, Rate Limiting, and new SDKs
This post is also available in 简体中文, 繁體中文, 日本語, 한국어, Deutsch, Español and Français.
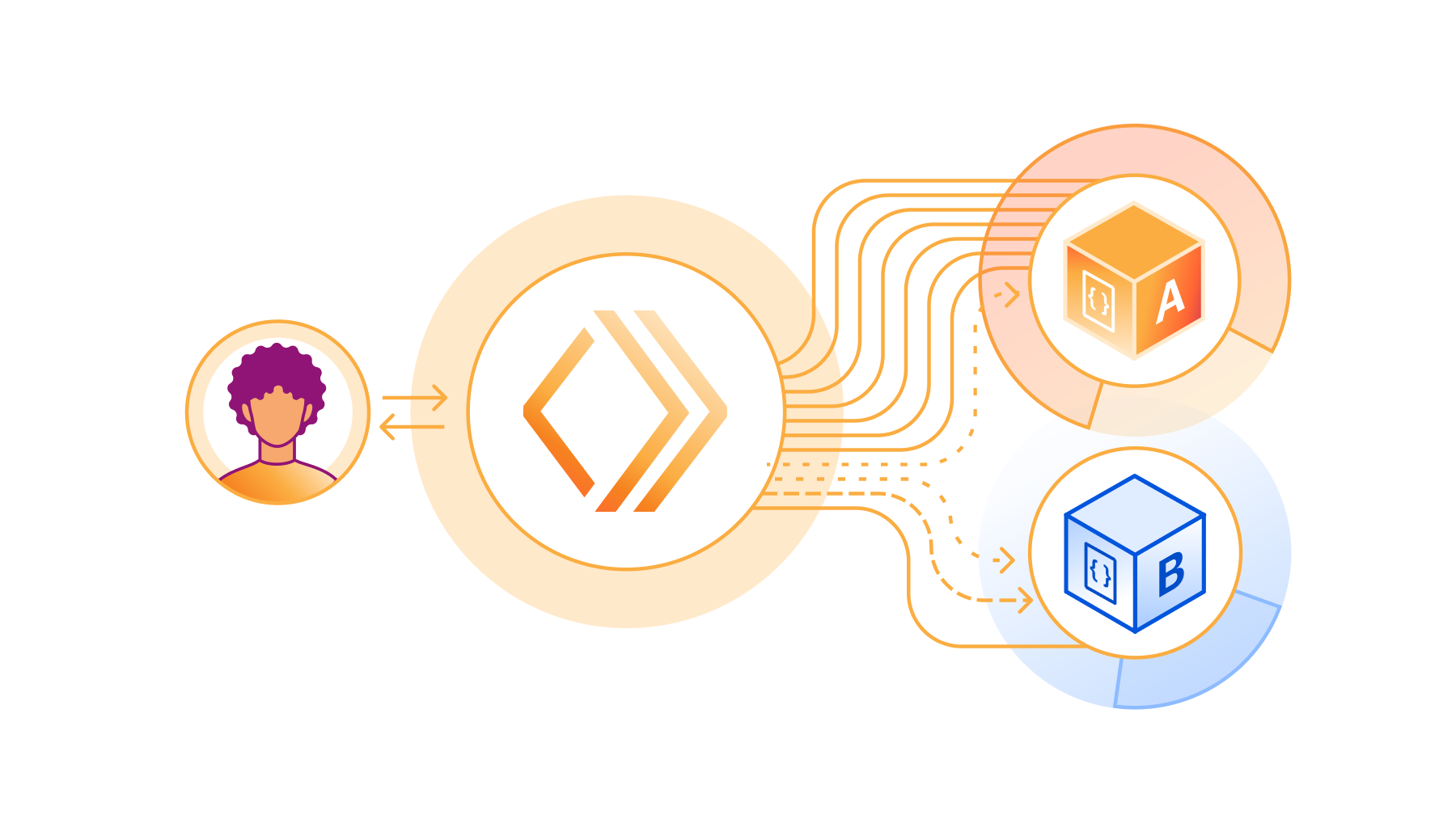
2024’s Developer Week is all about production readiness. On Monday. April 1, we announced that D1, Queues, Hyperdrive, and Workers Analytics Engine are ready for production scale and generally available. On Tuesday, April 2, we announced the same about our inference platform, Workers AI. And we’re not nearly done yet.
However, production readiness isn’t just about the scale and reliability of the services you build with. You also need tools to make changes safely and reliably. You depend not just on what Cloudflare provides, but on being able to precisely control and tailor how Cloudflare behaves to the needs of your application.
Today we are announcing five updates that put more power in your hands – Gradual Deployments, source mapped stack traces in Tail Workers, a new Rate Limiting API, brand-new API SDKs, and updates to Durable Objects – each built with mission-critical production services in mind. We build our own products using Workers, including Access, R2, KV, Waiting Room, Vectorize, Queues, Stream, and more. We rely on each of these Continue reading
What’s new with Cloudflare Media: updates for Calls, Stream, and Images

Our customers use Cloudflare Calls, Stream, and Images to build live, interactive, and real-time experiences for their users. We want to reduce friction by making it easier to get data into our products. This also means providing transparent pricing, so customers can be confident that costs make economic sense for their business, especially as they scale.
Today, we’re introducing four new improvements to help you build media applications with Cloudflare:
- Cloudflare Calls is in open beta with transparent pricing
- Cloudflare Stream has a Live Clipping API to let your viewers instantly clip from ongoing streams
- Cloudflare Images has a pre-built upload widget that you can embed in your application to accept uploads from your users
- Cloudflare Images lets you crop and resize images of people at scale with automatic face cropping
Build real-time video and audio applications with Cloudflare Calls
Cloudflare Calls is now in open beta, and you can activate it from your dashboard. Your usage will be free until May 15, 2024. Starting May 15, 2024, customers with a Calls subscription will receive the first terabyte each month for free, with any usage beyond that charged at $0.05 per real-time gigabyte. Additionally, there are no charges for Continue reading
Announcing Pages support for monorepos, wrangler.toml, database integrations and more!
Pages launched in 2021 with the goal of empowering developers to go seamlessly from idea to production. With built-in CI/CD, Preview Deployments, integration with GitHub and GitLab, and support for all the most popular JavaScript frameworks, Pages lets you build and deploy both static and full-stack apps globally to our network in seconds.
Pages has superpowers like these that Workers does not have, and vice versa. Today you have to choose upfront whether to build a Worker or a Pages project, even though the two products largely overlap. That’s why during 2023’s Developer Week, we started bringing both products together to give developers the benefit of the best of both worlds. And it’s why we announced that like Workers, Pages projects can now directly access bindings to Cloudflare services — using workerd under-the-hood — even when using the local development server provided by a full-stack framework like Astro, Next.js, Nuxt, Qwik, Remix, SolidStart, or SvelteKit. Today, we’re thrilled to be launching some new improvements to Pages that bring functionality previously restricted to Workers. Welcome to the stage: monorepos, wrangler.toml, new additions to Next.js support, and database integrations!
Pages now supports monorepos
Many Continue reading
Cloudflare Calls: millions of cascading trees all the way down

Following its initial announcement in September 2022, Cloudflare Calls is now in open beta and available in your Cloudflare Dashboard. Cloudflare Calls lets developers build real-time audio/video apps using WebRTC, and it abstracts away the complexity by turning the Cloudflare network into a singular SFU. In this post, we dig into how we make this possible.
WebRTC growing pains
WebRTC is the only way to send UDP traffic out of a web browser – everything else uses TCP.
As a developer, you need a UDP-based transport layer for applications demanding low latency and real-time feedback, such as audio/video conferencing and interactive gaming. This is because unlike WebSocket and other TCP-based solutions, UDP is not subject to head-of-line blocking, a frequent topic on the Cloudflare Blog.
When building a new video conferencing app, you typically start with a peer-to-peer web application using WebRTC, where clients exchange data directly. This approach is efficient for small-scale demos, but scalability issues arise as the number of participants increases. This is because the amount of data each client must transmit grows substantially, following an almost exponential increase relative to the number of participants, as each client needs to send data to n-1 other clients.
NAN059: Python for Network Engineering with Kirk Byers
The intersection of Python and network engineering is Kirk Byers’ sweet spot. Today, the creator of the Netmiko library and core maintainer of NAPALM joins the show to tell us about his network automation journey. We also discuss Kirk’s experience on the business side of things, both the ups and downs. This is Part 1... Read more »BGP Challenge: Build BGP-Free MPLS Core Network
Here’s another challenge for BGP aficionados: build an MPLS-based transit network without BGP running on core routers.

That should be an easy task if you configured MPLS in the past, so try to spice it up a bit:
- Use SR/MPLS instead of LDP
- Do it on a platform you’re not familiar with (hint: Arista vEOS is a bit different from Cisco IOS)
- Try to get it running on FRR containers.
BGP Challenge: Build BGP-Free MPLS Core Network
Here’s another challenge for BGP aficionados: build an MPLS-based transit network without BGP running on core routers.
That should be an easy task if you configured MPLS in the past, so try to spice it up a bit:
- Use SR/MPLS instead of LDP
- Do it on a platform you’re not familiar with (hint: Arista vEOS is a bit different from Cisco IOS)
- Try to get it running on FRR containers.
Fortinet Upgrades FortiOS with Threat Analysis and Enhancements to Its Security Fabric
Fortinet announced updates to FortiOS and its security fabric. Interestingly, the company bucked the trend and did not lead with GenAI in this announcement.Creating a Global Connectivity Development Strategy: Driving Growth with Low Latency Networks
Amid ongoing regional uncertainties, telecom infrastructure in the Middle East has expand to include terrestrial low-latency network infrastructure, which offers resilience and agility in navigating political complexities without relying solely on undersea networks.R2 adds event notifications, support for migrations from Google Cloud Storage, and an infrequent access storage tier
This post is also available in 简体中文, 繁體中文, 日本語, 한국어,Deutsch, Français and Español.

We’re excited to announce three new features for Cloudflare R2, our zero egress fee object storage platform:
- Event Notifications: Automatically trigger Workers and take action when data in your R2 bucket changes.
- Super Slurper for Google Cloud Storage: Easily migrate data from Google Cloud Storage to Cloudflare R2.
- Infrequent Access Private Beta: Pay less to store data that isn’t frequently accessed. Now in private beta (sign up now).
Event Notifications Open Beta
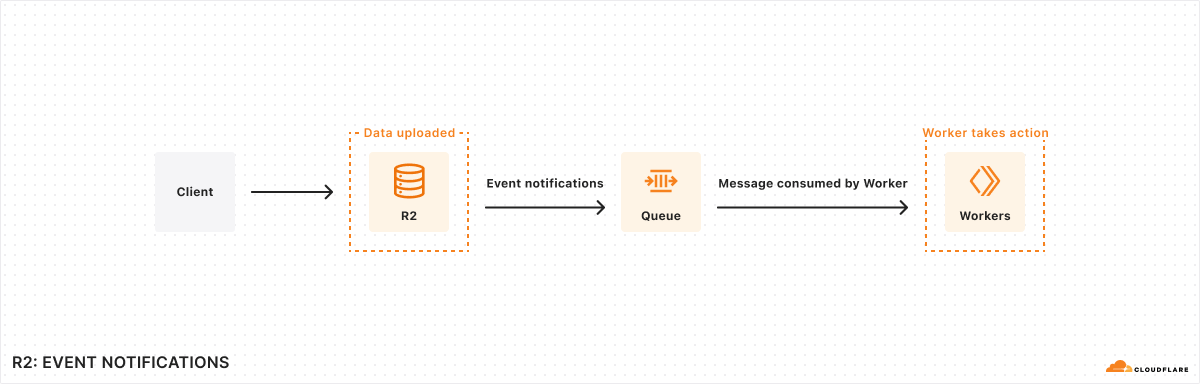
The lifecycle of data often doesn’t stop immediately after upload to an R2 bucket – event data may need to be transformed and loaded into a data warehouse, media files may need to go through a post-processing step, etc. We’re releasing event notifications for R2 in open beta to enable building applications and workflows driven by your changing data.
Event notifications work by sending messages to your queue each time there is a change to your data. These messages are then received by a consumer Worker where you can then define any subsequent action that needs to be taken.
To get started enabling event Continue reading
Improving Cloudflare Workers and D1 developer experience with Prisma ORM

Working with databases can be difficult. Developers face increasing data complexity and needs beyond simple create, read, update, and delete (CRUD) operations. Unfortunately, these issues also compound on themselves: developers have a harder time iterating in an increasingly complex environment. Cloudflare Workers and D1 help by reducing time spent managing infrastructure and deploying applications, and Prisma provides a great experience for your team to work and interact with data.
Together, Cloudflare and Prisma make it easier than ever to deploy globally available apps with a focus on developer experience. To further that goal, Prisma Object Relational Mapper (ORM) now natively supports Cloudflare Workers and D1 in Preview. With version 5.12.0 of Prisma ORM you can now interact with your data stored in D1 from your Cloudflare Workers with the convenience of the Prisma Client API. Learn more and try it out now.
What is Prisma?
From writing to debugging, SQL queries take a long time and slow developer productivity. Even before writing queries, modeling tables can quickly become unwieldy, and migrating data is a nerve-wracking process. Prisma ORM looks to resolve all of these issues by providing an intuitive data modeling language, an automated migration workflow, and Continue reading
Data Anywhere with Pipelines, Event Notifications, and Workflows

Data is fundamental to any real-world application: the database storing your user data and inventory, the analytics tracking sales events and/or error rates, the object storage with your web assets and/or the Parquet files driving your data science team, and the vector database enabling semantic search or AI-powered recommendations for your users.
When we first announced Workers back in 2017, and then Workers KV, Cloudflare R2, and D1, it was obvious that the next big challenge to solve for developers would be in making it easier to ingest, store, and query the data needed to build scalable, full-stack applications.
To that end, as part of our quest to make building stateful, distributed-by-default applications even easier, we’re launching our new Event Notifications service; a preview of our upcoming streaming ingestion product, Pipelines; and a sneak peek into our take on durable execution, Workflows.
Event-based architectures
When you’re writing data — whether that’s new data, changing existing data, or deleting old data — you often want to trigger other, asynchronous work to run in response. That could be processing user-driven uploads, updating search indexes as the underlying data changes, or removing associated rows in your SQL database when Continue reading
How Picsart leverages Cloudflare’s Developer Platform to build globally performant services

Delivering great user experiences with a global user base can be challenging. While serving requests quickly when you start out in a local market is straightforward, doing so for a global audience is much more difficult. Why? Even under optimal conditions, you cannot be faster than the speed of light, which brings single data center solutions to their performance limits.
In this post, we will cover how Picsart improved the performance of one of its most critical services by moving from a centralized architecture to a globally distributed service built on Cloudflare. Our serverless compute platform, Workers, distributed throughout 310+ cities around the world, and our globally distributed Workers KV storage allowed them to improve their performance significantly and drive real business impact.
Success driven by data-driven insights
Picsart is one of the world’s largest digital creation platforms and a long-standing Cloudflare partner. At its core, an advanced tech stack powers its comprehensive features, including AI-driven photo and video editing tools and community-driven content sharing. With its infrastructure spanning across multiple cloud environments and on-prem deployments, Picsart is engineered to handle billions of daily requests from its huge mobile and web user base and API integrations. For over a Continue reading
EVPN Designs: VXLAN Leaf-and-Spine Fabric
In this series of blog posts, we’ll explore numerous routing protocol designs that can be used to implement EVPN-with-VXLAN L2VPNs in a leaf-and-spine data center fabric. Every design will come with a companion netlab topology you can use to create a lab and explore the behavior of leaf- and spine switches.
Our leaf-and-spine fabric will have four leaves and two spines (but feel free to adjust the lab topology fabric parameters to build larger fabrics). The fabric will provide layer-2 connectivity to orange and blue VLANs. Two hosts will be connected to each VLAN to check end-to-end connectivity.
EVPN Designs: VXLAN Leaf-and-Spine Fabric
In this series of blog posts, we’ll explore numerous routing protocol designs that can be used to implement EVPN-with-VXLAN L2VPNs in a leaf-and-spine data center fabric. Every design will come with a companion netlab topology you can use to create a lab and explore the behavior of leaf- and spine switches.
Our leaf-and-spine fabric will have four leaves and two spines (but feel free to adjust the lab topology fabric parameters to build larger fabrics). The fabric will provide layer-2 connectivity to orange and blue VLANs. Two hosts will be connected to each VLAN to check end-to-end connectivity.