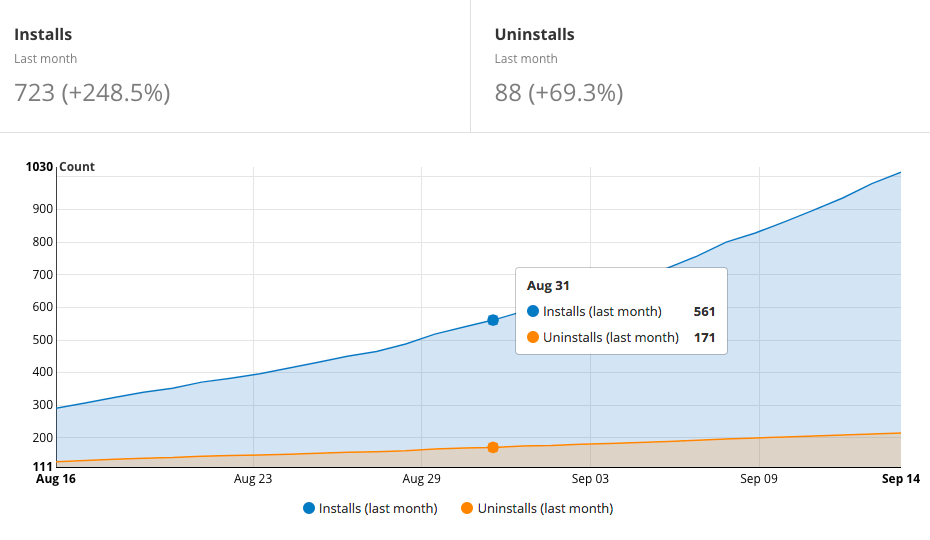
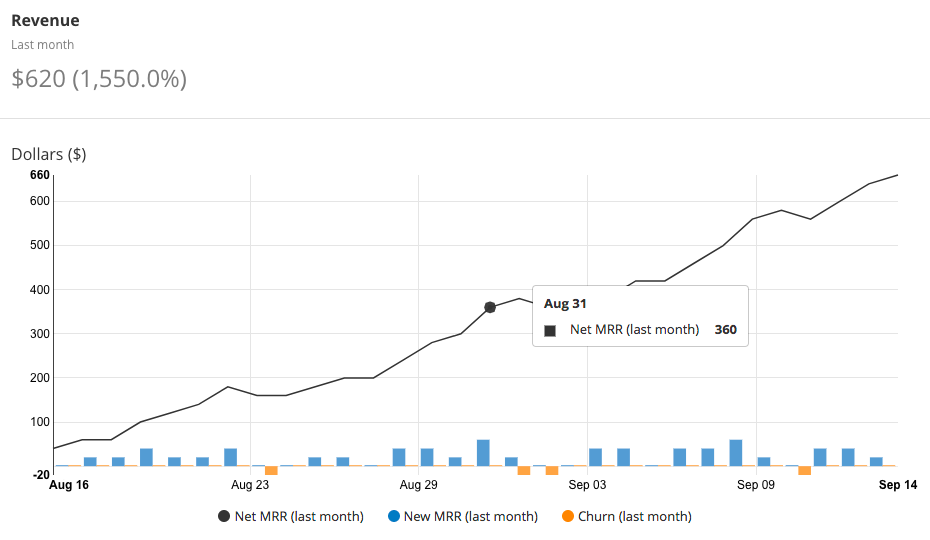
Buy-in from management and employee training is key.
Buy-in from management and employee training is key.Recently, California farmer Craig Thompson got a pretty nifty upgrade for his irrigation: a broadband-connected Hydrawise control system that would automatically manage and monitor the irrigation of his olive and grape fields and collect data to alert him if there was a problem. He woke up the next morning to fields he could have assumed were appropriately hydrated, but the Hydrawise system quickly proved its worth when he looked at the data coming out of it. He found that the water pressure had been much lower than expected. With that information, he was able to figure out that one of the drip irrigation wires was loose. This small detail revealed from his Wifi-enabled device could have meant the difference between success and failure for his entire season.
Many farmers across the world are realizing the benefits of streamlining their businesses with broadband-enabled devices. According to a 2017 report by MarketsandMarkets, the precision farming market is expected to grow from USD 3.20 Billion in 2015 to USD 7.87 Billion by 2022. It goes way beyond irrigation: there are farms using broadband-enabled devices for security, employee management, fertilizer and spray control, real-time access to specialists and Continue reading