Network Break 450: Cisco, Nutanix Announce HCI Gear; HPE Aruba Releases Wi-Fi 6e Sensor; Amazon Ships Test Satellites Into Orbit
This week's Network Break covers new HCI gear from the Cisco/Nutanix partnership, a sensor to detect Wi-Fi 6e performance, Intel financial engineering, Amazon shipping test satellites for a space broadband service, and more IT news.
The post Network Break 450: Cisco, Nutanix Announce HCI Gear; HPE Aruba Releases Wi-Fi 6e Sensor; Amazon Ships Test Satellites Into Orbit appeared first on Packet Pushers.
Red Hat Insights Collection for Event-Driven Ansible

Event-Driven Ansible became generally available in Ansible Automation Platform 2.4. As part of the release, Red Hat Insights and Ansible teams collaborated to implement and certify a Red Hat Insights collection integrating Insights events as a source of events for Ansible Automation Platform. This provides a consistent way to receive and handle events triggered from Insights to drive and track automation within the Ansible Automation Platform. The collection is available for installation on Ansible automation hub.
In this article, we explore how to get, configure and use the Red Hat Insights collection for Event-Driven Ansible, and provide an end-to-end example of an automation flow using Ansible Automation Platform and its Event-Driven Ansible functionality. Our goal is to automate the creation of a ServiceNow incident ticket with all relevant information when malware is detected by Insights on one of our Red Hat Enterprise Linux (RHEL) systems. We show how we can track and audit all automation from the Event-Driven Ansible controller as part of Ansible Automation Platform.
Introducing a new certified collection for Event-Driven Ansible
In a previous article, we looked at exposing and consuming Insights events to drive automation with Event-Driven Ansible. We validated that events triggered Continue reading
HTTP/2 Rapid Reset: deconstructing the record-breaking attack


Starting on Aug 25, 2023, we started to notice some unusually big HTTP attacks hitting many of our customers. These attacks were detected and mitigated by our automated DDoS system. It was not long however, before they started to reach record breaking sizes — and eventually peaked just above 201 million requests per second. This was nearly 3x bigger than our previous biggest attack on record.
Concerning is the fact that the attacker was able to generate such an attack with a botnet of merely 20,000 machines. There are botnets today that are made up of hundreds of thousands or millions of machines. Given that the entire web typically sees only between 1–3 billion requests per second, it's not inconceivable that using this method could focus an entire web’s worth of requests on a small number of targets.
Detecting and Mitigating
This was a novel attack vector at an unprecedented scale, but Cloudflare's existing protections were largely able to absorb the brunt of the attacks. While initially we saw some impact to customer traffic — affecting roughly 1% of requests during the initial wave of attacks — today we’ve Continue reading
HTTP/2 Zero-Day Vulnerability Results in Record-Breaking DDoS Attacks


Earlier today, Cloudflare, along with Google and Amazon AWS, disclosed the existence of a novel zero-day vulnerability dubbed the “HTTP/2 Rapid Reset” attack. This attack exploits a weakness in the HTTP/2 protocol to generate enormous, hyper-volumetric Distributed Denial of Service (DDoS) attacks. Cloudflare has mitigated a barrage of these attacks in recent months, including an attack three times larger than any previous attack we’ve observed, which exceeded 201 million requests per second (rps). Since the end of August 2023, Cloudflare has mitigated more than 1,100 other attacks with over 10 million rps — and 184 attacks that were greater than our previous DDoS record of 71 million rps.
This zero-day provided threat actors with a critical new tool in their Swiss Army knife of vulnerabilities to exploit and attack their victims at a magnitude that has never been seen before. While at times complex and challenging to combat, these attacks allowed Cloudflare the opportunity to develop purpose-built technology to mitigate the effects of the zero-day vulnerability.
If you are using Cloudflare for HTTP DDoS mitigation, you are protected. And below, we’ve included more information on this vulnerability, and Continue reading
HTTP/2 Zero-Day 漏洞導致破紀錄的 DDoS 攻擊
今天早些時候,Cloudflare 與 Google 和 Amazon AWS 一起披露了一個新型 zero-day 漏洞的存在,名為「HTTP/2 Rapid Reset」攻擊。此攻擊利用 HTTP/2 通訊協定中的弱點來產生巨大的超容量分散式阻斷服務 (DDoS) 攻擊。近幾個月來,Cloudflare 緩解了一系列此類攻擊,其中包括一起比我們之前觀察到的任何攻擊規模大三倍的攻擊,每秒要求數 (rps) 超過 2.01 億。自 2023 年 8 月底以來,Cloudflare 緩解了超過 1,100 起 rps 超過 1000 萬的其他攻擊,其中 184 起攻擊超過了我們之前 7100 萬 rps 的 DDoS 記錄。
這個 zero-day 漏洞為威脅執行者提供了一個重要的新工具,即漏洞中的瑞士軍刀,能夠以前所未有的規模利用和攻擊受害者。雖然這些攻擊有時非常複雜且難以應對,但正是因為它們,Cloudflare 才有機會開發專用技術來減輕 zero-day 漏洞的影響。
如果您使用 Cloudflare 進行 HTTP DDoS 緩解,則會受到保護。我們在下文提供了有關此漏洞的更多資訊,以及有關您可以採取哪些措施來保護自己的資源和建議。
解構攻擊:每個 CSO 需要瞭解的事情
2023 年 8 月下旬,我們的 Cloudflare 團隊注意到一個由未知威脅執行者開發的新 zero-day 漏洞,它所利用的標準 HTTP/2 通訊協定是一種基本通訊協定,對網際網路和所有網站的正常運作至關重要。這種新穎的 zero-day 漏洞攻擊稱為 Rapid Reset,它利用 HTTP/2 的串流取消功能,一次又一次地傳送要求並立即取消它。
透過大規模自動執行這種簡單的「要求、取消、要求、取消」模式,威脅執行者能夠建立阻斷服務並摧毀任何執行 HTTP/2 標準實作的伺服器或應用程式。此外,關於這起破紀錄的攻擊,還有一個重要事項需要注意,它涉及一個中等規模的殭屍網路,由大約 20,000 台機器組成。Cloudflare 會定期偵測比它大幾個數量級的殭屍網路 — 包括數十萬甚至數百萬台機器。對於一個相對較小的殭屍網路來說,輸出如此大量的要求,有可能使幾乎所有支援 HTTP/2 的伺服器或應用程式癱瘓,這凸顯了此漏洞對未受保護的網路的威脅有多大。
威脅執行者將殭屍網路與 HTTP/2 漏洞結合使用,以我們從未見過的速度放大了要求。因此,我們的 Cloudflare 團隊經歷了某種間歇性的邊緣不穩定。雖然我們的系統能夠緩解絕大部分傳入的攻擊,但這些流量會使我們網路中的部分元件過載,從而影響少數客戶的效能,並出現間歇性的 4xx 和 5xx 錯誤,而所有這些錯誤都被迅速解決了。
在我們為所有客戶成功緩解這些問題並阻止潛在攻擊之後,我們的團隊立即開始了負責任的披露程序。我們與業內同行進行了對話,看看我們如何共同努力,幫助推進我們的使命,並在向公眾發布此漏洞之前保護依賴我們網路的大部分網際網路。
我們在另一篇部落格文章中更詳細地介紹了該攻擊的技術細節:HTTP/2 Rapid Reset:解構破紀錄的攻擊。
Cloudflare 和業界如何遏止這種攻擊?
「完美的披露」並不存在。而遏止攻擊和回應新出現的事件需要組織和網路安全團隊以假定違規的心態生活 — 因為總會有另一個 zero-day 漏洞、新發展的威脅執行者團體以及前所未見的新穎攻擊和技術。
這種「假定違規」的心態是資訊分享以及在這種情況下確保網際網路保持安全的重要基礎。在 Cloudflare 遭遇並緩解這些攻擊的同時,我們也與業界合作夥伴合作,以確保整個產業能夠抵禦這種攻擊。
在緩解此攻擊的過程中,我們的 Cloudflare 團隊開發並專門構建了新技術來阻止這些 DDoS 攻擊,並進一步改進了我們自己的緩解措施來應對此攻擊和未來其他大規模攻擊。這些努力顯著提高了我們的整體緩解功能和復原能力。如果您使用 Cloudflare,我們相信您會受到保護。
我們的團隊也提醒正在開發修補程式以確保此漏洞不會被利用的 Web 伺服器軟體合作夥伴 — 請檢查網站以獲取更多資訊。

披露絕不是一勞永逸的事情。Cloudflare 的命脈是確保更好的網際網路,而這源於諸如此類的實例。當我們有機會與業界合作夥伴和政府合作,以確保網際網路不會受到廣泛影響時,我們正在盡自己的一份力量來提高每個組織的網路復原能力,無論其規模多大或類別為何。
若要深入瞭解緩解策略和下一步修補行動,請報名參加我們的網路研討會。
HTTP/2 Rapid Reset 和這些針對 Cloudflare 的破紀錄攻擊的起因是什麼?
奇怪的是,Cloudflare 竟然是最早目睹這些攻擊的公司之一。為什麼威脅執行者會攻擊一間擁有世界上最強大的 DDoS 攻擊防禦能力的公司?
實際情況是,Cloudflare 經常在攻擊轉向更脆弱的目標之前就發現了攻擊。威脅執行者在將工具部署到外部環境之前,需要先進行開發和測試。威脅執行者雖然掌握了破紀錄攻擊方法,但很難測試並瞭解攻擊的規模和有效性,因為他們沒有基礎架構可以承受他們發起的攻擊。由於我們分享網路效能的透明度,而且他們可以從我們的公開效能圖表中收集到攻擊測量結果,因此,威脅執行者很可能針對我們發起攻擊,藉此來瞭解該漏洞利用的功能。
但這項測試以及提早發現攻擊的能力,有助於我們針對攻擊開發緩解措施,從而使我們的客戶和整個產業受益。
從 CSO 到 CSO:您應該怎麼做?
我擔任了 20 多年的 CSO,接受過無數這樣的披露和公告。不過,無論是 Log4J、Solarwinds、EternalBlue WannaCry/NotPetya、Heartbleed 還是 Shellshock,所有這些安全事件都有一個共通性。一場大爆炸在全球蔓延並創造機會,徹底顛覆了我所領導的任何組織,無論產業或規模如何。
其中許多攻擊或漏洞都是我們無法控制的。但無論問題的起因是否在我的控制範圍之內,我所領導的任何成功計畫與那些不利於我們的計畫的區別在於,當識別這樣的 zero-day 漏洞和利用時,我們能夠做出回應。
雖然我希望我可以說這次的 Rapid Reset 可能會有所不同,但事實並非如此。無論你們是像我這樣經歷過數十年安全事件的洗禮,還是第一天從事這項工作,我都呼籲所有的 CSO,此刻正是確保你們受到保護,並支援網路事件回應團隊的時候。
我們直到今天才公開這些資訊,以讓盡可能多的安全廠商有機會做出反應。然而,在某些時候,公開披露這樣的 zero-day 威脅才是真正負責任的行為。而今天就是那一天。這意味著在今天之後,威脅執行者大多會意識到 HTTP/2 漏洞;而且,利用和啟動防禦者與攻擊者之間的競賽將不可避免地變得微不足道 — 先修補與先利用。組織應假設系統會遭受測試,並採取主動措施以確保保護。
對我來說,這會讓我想起像 Log4J 這樣的漏洞,由於每天都出現許多變體,因此,在未來幾週、幾個月甚至幾年內會不斷地取得成果。隨著越來越多的研究人員和威脅執行者對此漏洞進行實驗,我們可能會發現利用週期更短的不同變體,其中包含更高級的繞過方法。
就像 Log4J 一樣,管理此類事件並不像「執行修補程式,現在就完成了」那麼簡單。您需要將事件管理、修補和發展安全保護措施轉變為持續進行的流程,這是因為針對每個漏洞變體的修補程式可以降低您的風險,但並不能消除風險。
我無意危言聳聽,但我會直接說:你必須認真對待此事。將此事視為一個完全活動的事件,以確保您的組織平安無事。
對新變革標準的建議
雖然沒有任何一個安全事件會與下一個完全相同,但我們可以從中汲取一些教訓。CSO 們,以下是我的建議,必須立即實施。不僅在這種情況下,而且在未來的幾年中也一樣:
- 瞭解您的合作夥伴網路的外部連線,來透過以下緩解措施補救任何面向網際網路的系統。
- 瞭解您現有的安全保護措施以及您擁有的用於保護、偵測和回應攻擊的功能,並立即修復您網路中遇到的任何問題。
- 確保將 DDoS 保護部署在您的資料中心外部,因為如果流量到達資料中心,DDoS 攻擊將很難緩解。
- 確保您為應用程式(第 7 層)提供 DDoS 保護,並確保部署了 Web 應用程式防火牆。此外,作為最佳做法,請確保您為 DNS、網路流量(第 3 層)和 API 防火牆提供完整的 DDoS 保護
- 確保在所有面向網際網路的 Web 伺服器上部署 Web 伺服器和作業系統修補程式。此外,請確保所有自動化(例如,Terraform)組建和映像均已完全修補,這樣舊版 Web 伺服器就不會意外地透過安全映像部署到生產環境中。
- 最後一招,請考慮關閉 HTTP/2 和 HTTP/3(可能也易受攻擊)來緩解威脅。這只是萬不得已才能使用的手段,因為如果降級到 HTTP/1.1,將會出現重大的效能問題
- 考慮在邊界使用基於雲端的輔助 DDoS 第 7 層提供者以提高復原能力。
Cloudflare 的使命是幫助構建更好的網際網路。如果您擔心目前的 DDoS 保護狀態,我們非常樂意免費為您提供 DDoS 功能和復原能力,以緩解任何成功的 DDoS 攻擊嘗試。我們知道您所面臨的壓力,因為我們在過去 30 天內擊退了這些攻擊,並使我們本已最佳的系統變得更加完美。
如果您有興趣瞭解更多資訊,請觀看我們的網路研討會,以詳細瞭解 zero-day 漏洞以及如何應對。如果您不確定自己是否受到保護或想瞭解如何受到保護,請與我們聯絡。我們也在另一篇部落格文章中更詳細地介紹了有關該攻擊的更多技術細節: HTTP/2 Rapid Reset:解構破紀錄的攻擊。最後,如果您成為攻擊目標或需要即時保護,請聯絡您當地的 Cloudflare 代表或造訪https://www.cloudflare.com/zh-tw/under-attack-hotline/。
Alle Einzelheiten über HTTP/2 Rapid Reset
Am 25. August 2023 begannen wir, ungewöhnlich große HTTP-Angriffe auf viele unserer Kunden zu bemerken. Diese Angriffe wurden von unserem automatischen DDoS-System erkannt und abgewehrt. Es dauerte jedoch nicht lange, bis sie rekordverdächtige Ausmaße annahmen und schließlich einen Spitzenwert von knapp über 201 Millionen Anfragen pro Sekunde erreichten. Damit waren sie fast dreimal so groß wie der bis zu diesem Zeitpunkt größte Angriff, den wir jemals verzeichnet hatten.
Besorgniserregend ist die Tatsache, dass der Angreifer in der Lage war, einen solchen Angriff mit einem Botnetz von lediglich 20.000 Rechnern durchzuführen. Es gibt heute Botnetze, die aus Hunderttausenden oder Millionen von Rechnern bestehen. Bedenkt man, dass das gesamte Web in der Regel nur zwischen 1 bis 3 Milliarden Anfragen pro Sekunde verzeichnet, ist es nicht unvorstellbar, dass sich mit dieser Methode quasi die Anzahl aller Anfragen im Internet auf eine kleine Reihe von Zielen konzentrieren ließe.
Erkennen und Abwehren
Dies war ein neuartiger Angriffsvektor in einem noch nie dagewesenen Ausmaß, aber die bestehenden Schutzmechanismen von Cloudflare konnten die Wucht der Angriffe weitgehend bewältigen. Zunächst sahen wir einige Auswirkungen auf den Traffic unserer Kunden – Continue reading
HTTP/2 Zero-day 취약성은 이전에 없던 기록적인 DDoS 공격으로 이어집니다
오늘 Cloudflare는 Google, Amazon AWS와 함께 “HTTP/2 Rapid Reset” 공격이라는 새로운 zero-day 취약성의 존재를 공개했습니다. 이 공격은 HTTP/2 프로토콜의 약점을 악용하여 거대 하이퍼 볼류메트릭 분산 서비스 거부 (DDoS) 공격을 생성합니다. Cloudflare는 최근 몇 달간 이런 빗발치는 공격을 완화하였는데, 그중에는 이전에 우리가 목격한 것보다 규모가 3배 큰, 초당 2억 100만 요청(rps)을 넘어서는 공격도 있었습니다. Cloudflare는 2023년 8월 말부터 1,000만 rps가 넘는 기타 공격 1,100건 이상을 완화하였으며, 184건은 이전 DDoS 기록인 7,100만 rps보다도 큰 공격이었습니다.
위협 행위자들은 이러한 zero-day를 통해 취약성이라는 맥가이버 칼에 치명적인 도구를 새로 더하여 이전에 본 적 없는 규모로 피해자를 공격할 수 있게 되었습니다. 때로는 복잡하고 힘든 싸움이었지만, Cloudflare는 이러한 공격을 통해 zero-day 취약성의 영향을 완화하기 위한 기술을 개발할 수 있었습니다.
HTTP DDoS 완화를 위해 Cloudflare를 이용 중이시라면, 여러분은 보호받고 있습니다. 이 취약성에 대해 아래에서 더 알아보고, 스스로를 보호하기 위해 할 수 있는 리소스와 권장 사항을 확인해 보세요.
공격 분석: 모든 CSO가 알아야 할 사항
2023년 8월 말, Cloudflare 팀은 알 수 없는 위협 행위자가 개발한 새로운 zero-day 취약성을 발견하였습니다. 이 취약성은 인터넷 및 모든 웹 사이트의 작동에 필수적인 표준 HTTP/2 프로토콜을 악용합니다. Rapid Reset이라는 별명이 붙은 이 새로운 zero-day 취약성 공격은 요청 전송 후 즉각적 취소를 반복함으로써 HTTP/2 Continue reading
HTTP/2 Rapid Reset: cómo desarmamos el ataque sin precedentes
El 25 de agosto de 2023, empezamos a observar algunos ataques de inundación HTTP inusualmente voluminosos que afectaban a muchos de nuestros clientes. Nuestro sistema DDoS automatizado detectó y mitigó estos ataques. Sin embargo, no pasó mucho tiempo antes de que empezaran a alcanzar tamaños sin precedentes, hasta alcanzar finalmente un pico de 201 millones de solicitudes por segundo, casi el triple que el mayor ataque registrado hasta ese momento.
Lo más inquietante es que el atacante fuera capaz de generar semejante ataque con una botnet de solo 20 000 máquinas. Hoy en día existen botnets formadas por cientos de miles o millones de máquinas. La web suele recibir solo entre 1000 y 3000 millones de solicitudes por segundo, por eso no parece imposible que utilizando este método se pudiera concentrar el volumen de solicitudes de toda una web en un pequeño número de objetivos.
Detección y mitigación
Se trataba de un vector de ataque novedoso a una escala sin precedentes, pero las soluciones de protección de Cloudflare pudieron mitigar en gran medida los efectos más graves de los ataques. Si bien Continue reading
HTTP/2 zero-day脆弱性により史上最大のDDoS攻撃が発生
本日未明、Cloudflareは、GoogleおよびAmazon AWSとともに、「HTTP/2 Rapid Reset」攻撃と名付けられた新種の脆弱性(zero-day )の存在を公表しました。この攻撃は、HTTP/2プロトコルの弱点を悪用し、巨大で超ボリューメトリックな分散サービス妨害(DDoS)攻撃を発生させます。Cloudflareはここ数カ月間、こうした嵐のような攻撃の軽減に取り組んでいました。その中には 、1秒間に2億100万リクエスト(rps)を超える、弊社がこれまでに観測した最大の攻撃の3倍ほどの規模となる攻撃も含まれています。2023年8月末以降、Cloudflareはその他の1,000万rpsを超える攻撃を1,100回以上軽減しましたが、この間DDoSの最大記録である7,100万rpsを超える攻撃が184回にも及びました。
攻撃を受けていますか?それとも、保護を追加したいですか? ヘルプを受けるには、こちらをクリックしてください。
このzero-dayは、脅威アクターたちに、脆弱性の解析ツールであるスイスアーミーナイフを悪用して被害者を攻撃することができる、今までにない全く新しいツールを提供したのです。 これらの攻撃に対する対処は複雑で困難を伴うものでしたが、このような攻撃は、Cloudflareにとって、zero-dayの脆弱性の影響を軽減する特別な技術開発の機会となりました。
Cloudflareを使用しているのであれば、HTTPのDDoSは軽減され、保護されています。 以下、この脆弱性に関する詳細情報と、安全確保のためのリソースと推奨事項を掲載します。
攻撃のデコンストラクション(脱構築):すべてのCSOが知るべきこと
2023年8月下旬、弊社のチーム(Cloudflare zero-day)は、Standard HTTP/2プロトコル(インターネットとすべてのWebサイトが機能するために重要な基本プロトコル)を悪用する、未知の脅威行為者によって開発された新たな脆弱性を観測しました。Rapid Resetと名付けられたこの新しいzero-day 脆弱性攻撃は、HTTP/2のStreamキャンセル機能を利用し、リクエストを送信して即座にキャンセルすることを何度も繰り返すものです。
この単純な「リクエスト、キャンセル、リクエスト、キャンセル」パターンを大規模に自動化することで、脅威アクターはサービス拒否を作り出し、HTTP/2の実装(Standard )を実行しているサーバーやアプリケーションを停止させることができるのです。 さらに、この記録的な攻撃について注目すべき重要な点は、およそ20,000台のマシンで構成される控えめな規模のボットネットが関与していたことです。 Cloudflareは、数十万台から数百万台のマシンで構成される、これよりも桁違いに大規模なボットネットを定期的に検出しています。 比較的小規模なボットネットが、HTTP/2をサポートするほぼすべてのサーバーやアプリケーションを無力化してしまうほどの可能性を秘め、これほど大量のリクエストを出力するという事実は、この脆弱性が無防備なネットワークにとっていかに脅威となるかを強調しています。
脅威アクターはHTTP/2の脆弱性とボットネットを併用し、これまでにない速度でリクエストを増幅させました。 その結果、Cloudflareのチームは、断続的にエッジが不安定になるという体験をしました。 当社のシステムは圧倒的多数の着信攻撃を軽減することができましたが、その量はネットワーク内のいくつかのコンポーネントに過負荷をかけ、断続的に4xxおよび5xxエラーが発生し、少数のお客様のパフォーマンスに影響を与えました。
これらの問題を軽減し、すべての顧客に対する潜在的な攻撃を停止させることに成功した後、弊社のチームは直ちに責任ある情報開示プロセスを開始しました。 この脆弱性を一般に公表する前に、どのように弊社のミッションを前進させ、弊社のネットワークに依存しているインターネットの大部分を保護するために協力できるかについて、同業者と話し合いました。
この攻撃の技術的な詳細については、別のブログ記事で取り上げています。 HTTP/2 Rapid Reset: 記録的な攻撃のデコンストラクション(脱構築)。
Cloudflareと業界はこの攻撃をどのように阻止しているのでしょうか?
「完全な情報開示」というものは存在しません。 攻撃を阻止し、新たなインシデントに対応するためには、組織やセキュリティチームが常に侵害を想定したマインドセットが必要です。なぜなら、zero-day 、新たな進化を遂げる脅威アクターグループ、今までにはないような斬新な攻撃やテクニックが常に存在するからです。
この「違反を想定」するマインドセットは、情報共有のための重要な基盤であり、インターネットの安全性を確保するものとなります。 Cloudflareは、このような攻撃を経験・軽減しつつ、業界全体がこの攻撃に耐えられることを保証するために、業界のパートナーと協力します。
この攻撃を軽減する過程で、弊社のCloudflareチームは、このような DDoS攻撃を阻止するための新技術を開発・構築し、この攻撃のみならず今後発生するその他の大規模な攻撃に対しても、弊社独自の軽減策をさらに改善してきました。 こうした取り組みにより、全体的な軽減能力と回復力が大幅に向上した。 Cloudflareを使用している場合、保護されていると確信しています。
また、この脆弱性を悪用されないようにするためのパッチを開発しているWebサーバーソフトウェアパートナーにも警告を発しました。 — 詳細は同社のWebサイトを参照してください。
情報開示は1回で終わりません。 Cloudflareの生命線は、より良いインターネットを確保することであり、それはこのような事例から生じています。 インターネットに広範な影響が及ばないよう、業界パートナーや政府と協力する機会があれば、規模や業種を問わず、あらゆる組織のサイバー耐性を向上させる弊社の役割を果たします。
パッチを適用する際の緩和策や次のステップに関する理解を深めるために、弊社のウェビナーにご参加ください 。
HTTP/2 Rapid Resetと、Cloudflare に対するこれらの記録的な攻撃のオリジンは何ですか?
Cloudflareが、こうした攻撃を最初に観測した企業のひとつであることは奇妙に思えるかもしれません。 DDoS攻撃に対して世界で最も強固な防御を持つ企業を、なぜ脅威アクターが攻撃するのでしょうか?
実際、Cloudflareは、攻撃がより脆弱なターゲットに向けられる前に、時折攻撃を観測します。 脅威アクターは、ツールを実際の攻撃のためにデプロイする前に、ツールを開発し、テストする必要があります。 記録的な攻撃手法を持つ脅威アクターにとって、その攻撃手法がどれほど大規模で効果的なものかをテストし、把握することは極めて困難といえるでしょう。その攻撃を受け止めるだけのインフラストラクチャがないからです。弊社はネットワークパフォーマンスに関する透明性を共有し、公開されているパフォーマンスチャートから攻撃の測定値を得ることがでるため、この脅威アクターは悪用能力を把握するために弊社をターゲットにしたと考えられます。
しかしこのテストと、攻撃の早期発見能力は、弊社の攻撃緩和策の開発に役立ち、顧客と業界全体の両方に利益をもたらすことになるのです。
CSOからCSOへ:何をすべきですか?
私は20年以上CSOを務めており、このような情報開示や発表を数え切れないほど経験しました。しかし 、 Log4J で あれ、 Solarwindsであれ、 EternalBlue WannaCry/NotPetyaであれ、Heartbleed であれ、 Shellshock であれ、セキュリティインシデントには共通点があります。凄まじい爆発が世界中に波及し、私が率いたあらゆる組織を完全に混乱させるおそれがあるのです—業界や規模に関わりなくです。
これらの多くは、私たちが制御できなかったかもしれない攻撃や脆弱性だったのです。 しかし、この問題が私の制御できるところから生じたか否かにかかわらず、私が主導して成功したイニシアチブを、私たちに有利に傾かなかった多層防御と区別したのは、このようなzero-day脆弱性やエクスプロイトが特定されたときに対応する能力だったのです。
今回のRapid Resetは違うと言いたいところですが、そうではありません。 私はすべてのCSOにこう呼びかけています—私のように何十年もセキュリティインシデントを経験してきた人であっても、今日が勤務初日という人であっても、サイバーインシデント対応チームを立ち上げ、確実な保護対策を取るべきです—今こそその時なのです。
できるだけ多くのセキュリティベンダーに対して対応する機会を与えるため、今日まで情報を制限してきました。 しかし、ある時点で、このようなzero-day脅威を公開する責任が生じました。 今日がその日なのです。 つまり、今日以降、脅威アクターはHTTP/2の脆弱性をかなりの部分把握することになるので、その悪用は必然的に容易になり、防御側と攻撃側の間の競争—パッチを当てるのが先か、悪用するのが先かが始まるのです。 組織は、システムがテストされることを想定し、確実に保護するための事前対策を講じるべきなのです。
これはLog4Jのような脆弱性を思い出させます。多くの亜種が日々出現し、そして今後数週間、数カ月、数年と出現し続けることでしょう。 より多くのリサーチャーや脅威アクターがこの脆弱性を試すようになれば、さらに高度なバイパスを含む、より短い悪用サイクルを持つ別の亜種が見つかるかもしれません。
Log4Jと同様、このようなインシデントの管理は「パッチを当てて完了」というような単純なものではありません。 インシデント管理、パッチ適用、セキュリティ保護の進化を、継続的なプロセスに変える必要があるのです。なぜなら、脆弱性の亜種ごとにパッチを適用してリスクを軽減させることはできても、解消されるわけではないからです。
警鐘を鳴らすつもりはないですが、単刀直入に言います。これを真剣に受け止めてください。 組織に何も起こらないように、必ずアクティブなインシデントとして扱ってください。
新たな変更基準のための推奨事項
セキュリティー上の出来事は、一つとして同じものはなく、またそれらから多くのことが学べます。 CSOの皆さん、すぐに実行に移さなければならない推奨事項をここでお伝えします。 今回だけでなく、この先何年間にも渡って実行してください。
- 外部ネットワークおよびパートナーネットワークの外部接続を理解し、インターネットに接続しているシステムは次の緩和策を実施してください。
- 既存のセキュリティ保護と、保護すべき能力を理解し、攻撃を検出し、対応し、ネットワークに問題があれば直ちに修復します。
- DDoS攻撃対策が、必ずデータセンターの外にあるようにしてください。トラフィックがデータセンターに到達してしまうと、DDoS攻撃を軽減することが難しくなるからです。
- DDoS攻撃対策アプリケーション(レイヤー7)、およびWebアプリケーションファイアウォールを確保してください。 さらに、ベストプラクティスとして、DNS、ネットワークTraffic(レイヤー3)、APIファイアウォールに対する完全なDDoS攻撃対策を確実に保持してください。
- Webサーバーおよびオペレーティングシステムのパッチが、インターネットに接続しているWebサーバーに導入されているようにします。 また、Terraformのビルドやイメージのようなすべての自動化が完全にパッチされていることを確認し、旧バージョンのWebサーバが誤ってセキュアなイメージ上でプロダクションにデプロイされないようにします。
- 最後の手段として、脅威を軽減するためにHTTP/2とHTTP/3(これも脆弱である可能性が高い)をオフにすることを検討してください。 なぜなら、HTTP/1.1にダウングレードすると、パフォーマンスに大きな問題が生じるからです。
- レジリエンスを持たせるために、セカンダリでクラウドベースの DDoS L7 プロバイダーをペリメータ―(境界)で検討してください。
Cloudflareのミッションは、より良いインターネットの構築を支援することです。 DDoS攻撃対策の現状に不安を感じるお客様には、DDoS攻撃を軽減するために、弊社のDDoS能力とレジリエンスを無料で提供させていただきます。この30日間、弊社はこのような攻撃と戦いながら、クラス最高のシステムをさらに向上させてきました。
さらに詳しくお知りになりたい方は、zero-dayの詳細と対応方法に関するウェビナーをご覧ください。保護されているかどうか不明な場合、またはどのように保護されるのか知りたい場合は、お問い合わせください。また、この攻撃の技術的な詳細につきましては、別のブログ記事HTTP/2 Rapid Reset: 記録的な攻撃を脱構築するで詳しく解説しております。最後に、攻撃の標的にされている場合、または早急な保護が必要な場合は、お近くのCloudflare 担当者にお問い合わせいただくか、 https://www.cloudflare.com/ja-jp/under-attack-hotline/をご覧ください。
HTTP/2 Zero-Day 漏洞导致破纪录的 DDoS 攻击
今天早些时候,Cloudflare 与 Google 和 Amazon AWS 一起披露了一个名为 “HTTP/2 Rapid Reset” 攻击的新型 zero-day 漏洞的存在。此攻击利用 HTTP/2 协议中的弱点来生成巨大的超容量分布式拒绝服务 (DDoS) 攻击。近几个月来,Cloudflare 缓解了一系列攻击,其中一次攻击规模是我们之前观察到的任何攻击的三倍,每秒超过 2.01 亿个请求 (rps)。自 2023 年 8 月底以来,Cloudflare 已缓解了超过 1,100 起 RPS 超过 1000 万的其他攻击,其中 184 起攻击超过了我们之前 7100 万 RPS 的 DDoS 记录。
这个 zero-day 漏洞为威胁行为者提供了一个重要的新工具,即漏洞中的瑞士军刀,能够以前所未有的规模利用和攻击受害者。虽然这些攻击有时非常复杂且难以应对,但正是因为它们,Cloudflare 才有机会开发专用技术来缓解 zero-day 漏洞的影响。
如果您使用 Cloudflare 进行 HTTP DDoS 缓解,那么您已经受到保护。下面,我们将提供有关此漏洞的更多信息,以及如何确保自身安全的资源和建议。
解构攻击:每位 CSO 需要了解的内容
2023 年 8 月下旬,我们的 Cloudflare 团队注意到一个新的 zero-day 漏洞,该漏洞由未知威胁行为者开发,它所利用的标准 HTTP/2 协议是一种基本协议,对互联网和所有网站的正常运作至关重要。这种新型 zero-day 漏洞攻击被称为“Rapid Reset”,它利用 HTTP/2 的流取消功能,反复发送请求并立即取消该请求。
透过大规模自动执行这种简单的“请求、取消、请求、取消”模式,威胁行为者能够建立拒绝服务并摧毁任何运行 HTTP/2 标准实施的服务器或应用程序。此外,关于这起破纪录的攻击,还有一个重要事项需要注意,它涉及一个中等规模的僵尸网路,由大约 20,000 台机器组成。 Cloudflare 会定期检测比这大几个数量级的僵尸网路——包括数十万甚至数百万台机器。对于一个相对较小的僵尸网络来说,输出如此大量的请求,有可能使几乎所有支持 HTTP/2 的服务器或应用程序瘫痪,这凸显了此漏洞对未受保护的网络的威胁有多大。
威胁行为者利用僵尸网络和 HTTP/2 漏洞,以前所未有的速度放大请求。因此,我们的 Cloudflare 团队经历了一些间歇性的边缘不稳定。虽然我们的系统能够缓解绝大多数传入攻击,但流量使我们网络中的某些组件过载,从而影响了少数客户的性能并出现间歇性 4xx 和 5xx 错误——所有这些都很快得到了解决。
在我们成功缓解了这些问题并阻止了所有客户的潜在攻击后,我们的团队立即启动了负责任的披露流程。在向公众公布这一漏洞之前,我们与业界同行进行了对话,探讨如何合作才能帮助我们完成使命,并保护依赖我们网络的大部分互联网用户的安全。
我们在另一篇博文中详细介绍了这次攻击的技术细节:HTTP/2 Rapid Reset:解构破纪录的攻击。
Cloudflare 和业界是如何遏止此次攻击的?
没有所谓的“完美披露”。阻止攻击和响应新出现的事件需要组织和安全团队以假定泄露的心态生活——因为总会有另一个 zero-day 漏洞、演变而来的新威胁行为者群体,以及前所未见的新型攻击和技术。
这种“假定泄露”的心态是信息共享和确保在这种情况下互联网保持安全的关键基础。在 Cloudflare 经历并缓解这些攻击的同时,我们还与行业合作伙伴合作,以确保整个行业能够抵御这种攻击。
在缓解此攻击的过程中,我们的 Cloudflare 团队开发并专门构建了新技术来阻止这些 DDoS 攻击,并进一步改进我们针对此攻击和未来其他大规模攻击的缓解措施。这些努力显著提高了我们的整体缓解能力和弹性。如果您正在使用 Cloudflare,我们相信您会受到保护。
我们的团队还提醒正在开发补丁的 Web 服务器软件合作伙伴,以确保此漏洞不会被利用——请查看他们的网站以获取更多信息。
披露绝不是一劳永逸的。Cloudflare 的命脉是确保更好的互联网,这源于诸如此类的实例。我们有机会与行业合作伙伴和政府合作,确保互联网不会受到广泛影响,因此,我们正在尽自己的一份力量来提高每个组织的网络弹性,无论其规模或垂直领域如何。
要进一步了解缓解策略和后续修补措施,请登记参加我们的网络研讨会。
HTTP/2 Rapid Reset 和这些针对 Cloudflare 的破纪录攻击的起源是什么?
Cloudflare 是最先受到这些攻击的公司之一,这似乎有些奇怪。为什么威胁行为者要攻击一家拥有世界上最强大的 DDoS 攻击防御系统的公司?
现实情况是,Cloudflare 经常在攻击转向更脆弱的目标之前就发现了它们。威胁行为者需要先开发和测试他们的工具,然后再将其实际部署。拥有破纪录攻击方法的威胁行为者可能会难以测试和了解它们的规模和有效性,因为他们没有基础结构来承担他们发起的攻击。由于我们分享网络性能的透明度,以及他们可以从我们的公开性能图表中收集到攻击测量结果,该威胁行为者很可能通过攻击我们来了解该漏洞的功能。
但这种测试以及尽早发现攻击的能力可以帮助我们开发针对攻击的缓解措施,从而使我们的客户和整个行业受益。
各位首席安全官的应对措施:您应该怎么做?
我担任首席安全官已有 20 多年,经历过无数次类似的披露和公告。但无论是 Log4J、Solarwinds、EternalBlue WannaCry/NotPetya、Heartbleed,还是 Shellshock,所有这些安全事件都有一个共同点。巨大的爆炸波及全球,并有可能彻底颠覆我所领导的任何组织——无论行业或规模如何。
其中许多是我们可能无法控制的攻击或漏洞。但无论问题的起因是否在我的控制范围之内,我所领导的任何成功计划与不利计划的区别在于,当识别这样的 zero-day 漏洞和利用时,我们能够做出回应。
虽然我希望我可以说这次的 Rapid Reset 可能会有所不同,但事实并非如此。我呼吁所有的首席安全官,无论您是像我一样经历了数十年的安全事件,还是刚刚上任,现在都需要确保您受到保护,并支持您的网络事件响应团队 。
直到今天,我们一直对这些信息进行限制,以便让尽可能多的安全供应商有机会做出反应。不过,在某些时候,公开披露这样的 zero-day 威胁才是负责任的做法。今天就是公开的日子。这意味着今天之后,威胁行为者将在很大程度上意识到 HTTP/2 漏洞;攻击者将能够轻松利用这一漏洞,防御者与攻击者之间的竞赛也将无可避免——是先得到修补还是先被利用。组织应假定系统将受到攻击,并采取主动措施来进行保障。
对我来说,这让人想起像 Log4J 这样的漏洞,因为每天都会出现许多变体,并将在未来几周、几个月和几年内继续发挥作用。随着越来越多的研究人员和威胁行为者对该漏洞进行实验,我们可能会发现具有更短利用周期的不同变体,其中包含更高级的绕过方法。
就像 Log4J 一样,管理此类事件并不像“运行补丁,大功告成”那么简单。您需要将事件管理、修补和发展安全保护转变为持续的流程,因为针对每个漏洞变体的修补程序可以降低您的风险,但并不能消除风险。
我无意危言耸听,但我要直截了当地说:你们必须认真对待这件事。将此视为一个完全活动的事件,以确保您的组织不会发生任何事情。
新变革标准的建议
虽然安全事件各不相同,但还是可以从中吸取教训。首席安全官们,以下是我提出的必须立即实施的建议。不仅是针对此次漏洞,今后几年也是如此:
- 了解您的外部网络和合作伙伴网络的连接情况,利用以下缓解措施修复任何面向互联网的系统。
- 了解您现有的安全保护措施以及保护、检测和应对攻击的能力,并立即修复网络中存在的任何问题。
- 确保 DDoS 防护位于数据中心之外,因为如果流量进入数据中心,将很难缓解 DDoS 攻击。
- 确保您拥有针对应用程序(第 7 层)的 DDoS 防护,并确保您拥有 Web 应用程序防火墙。此外,作为最佳实践,确保您拥有针对 DNS、网络流量(第 3 层)和 API 防火墙的完整 DDoS 防护。
- 确保在所有面向互联网的 Web 服务器上都部署了 Web 服务器和操作系统补丁。此外,请确保所有自动化(例如 Terraform 构建和映像)都已完全修补,以便旧版本的 Web 服务器不会意外地通过安全映像部署到生产环境中。
- 在万不得已的情况下,可以考虑关闭 HTTP/2 和 HTTP/3(可能也容易受到攻击)以减轻威胁。这只是最后的手段,因为如果降级到 HTTP/1.1,会出现严重的性能问题。
- 考虑在周边使用基于云的辅助 DDoS L7 提供商以提高弹性。
Cloudflare 的使命是帮助构建更好的互联网。如果您担心当前的 DDoS 防护状态,我们非常乐意免费为您提供我们的 DDoS 功能和弹性,以缓解任何成功的 DDoS 攻击尝试。我们知道您面临的压力,因为我们在过去 30 天里抵御了这些攻击,并使我们本已一流的系统变得更好。
如果您有兴趣了解更多信息,请观看我们的网络研讨会,了解 zero-day 的详细信息以及应对方式。如果您不确定自己是否受到保护或想了解如何受到保护,请联系我们。我们还在另一篇博文中详细介绍了这次攻击的更多技术细节:HTTP/2 Rapid Reset:解构破纪录的攻击。最后,如果您是攻击目标或需要立即保护,请联系您当地的 Cloudflare 代表或访问 https://www.cloudflare.com/zh-cn/under-attack-hotline/。
HTTP/2 Rapid Reset:記録的勢いの攻撃を無効化
2023年8月25日以降、当社では、多くのお客様を襲った異常に大規模なHTTP攻撃を目撃し始めました。これらの攻撃は当社の自動DDoSシステムによって検知され、軽減されました。しかし、これらの攻撃が記録的な規模に達するまで、それほど時間はかかりませんでした。その規模は、過去に記録された最大の攻撃の約3倍にも達したのです。
懸念となるのは、攻撃者がわずか2万台のボットネットでこの攻撃を実行できたという事実です。今日、数万台から数百万台のマシンで構成されるボットネットが存在しています。Web上では全体として通常1秒間に10億から30億のリクエストしかないことを考えると、この方法を使えば、Webのリクエスト全体を少数のターゲットに集中させることができます。
検出と軽減
これは前例のない規模の斬新な攻撃ベクトルでしたが、Cloudflareの既存の保護システムは攻撃の矛先をほぼ吸収することができました。当初はお客様のトラフィックに若干の影響が見られたものの(攻撃の初期波ではリクエストのおよそ1%に影響)、現在では緩和方法を改良し、当社のシステムに影響を与えることなく、Cloudflareのすべてのお客様に対する攻撃を阻止することができるようになりました。
当社は、業界の最大手であるGoogleとAWSの2社と同時に、この攻撃に気づきました。当社はCloudflareのシステムを強化し、今日ではすべてのお客様がこの新しいDDoS攻撃手法から保護され、お客様への影響がないことを確認しました。当社はまた、グーグルやAWSとともに、影響を受けるベンダーや重要インフラストラクチャプロバイダーへの攻撃に関する協調的な情報開示に参加しました。
この攻撃は、HTTP/2プロトコルのいくつかの機能とサーバー実装の詳細を悪用することで行われました(詳細は、CVE-2023-44487をご覧ください)。この攻撃はHTTP/2プロトコルにおける根本的な弱点を悪用しているため、HTTP/2を実装しているすべてのベンダーがこの攻撃の対象になると考えられます。これには、すべての最新のWebサーバーも含まれます。当社は、GoogleとAWSとともに、Webサーバーベンダーがパッチを実装できるよう、攻撃方法を開示しました。一方で、Webに面したWebやAPIサーバーの前段階に設置されるCloudflareのようなDDoS軽減サービスを利用するのが最善の防御策とります。
この投稿では、HTTP/2プロトコルの詳細、攻撃者がこれらの大規模な攻撃を発生させるために悪用した機能、およびすべてのお客様が保護されていることを保証するために当社が講じた緩和策について詳細を掘り下げて紹介します。これらの詳細を公表することで、影響を受ける他のWebサーバーやサービスが緩和策を実施するために必要な情報を得られることを期待しています。そしてさらに、HTTP/2プロトコル規格チームや、将来のWeb規格に取り組むチームには、こうした攻撃を防ぐためHTTP/2プロトコルの設計改善に役立てていただければと思っています。
RST攻撃の詳細
HTTPは、Webを稼働するにあたって用いられるアプリケーションプロトコルです。HTTPセマンティクスとは、リクエストとレスポンスメッセージ、メソッド、ステータスコード、ヘッダーフィールドとトレーラフィールド、メッセージコンテンツなど、全体的なアーキテクチャ、用語、プロトコルの側面に関し、あらゆるバージョンに共通しています。個々のHTTPバージョンでは、セマンティクスをインターネット上でやりとりするための「ワイヤーフォーマット」に変換する方法を定義しています。例えば、クライアントはリクエストメッセージをバイナリデータにシリアライズして送信し、サーバーがこれを解析して処理可能なメッセージに戻します。
HTTP/1.1は、テキスト形式のシリアライズを使用します。リクエストメッセージとレスポンスメッセージはASCII文字のストリームとしてやりとりされ、TCPのような信頼性の高いトランスポートレイヤーを介して、以下のフォーマットで送信されます(「CRLF」はキャリッジリターンとラインフィードを意味します):
HTTP-message = start-line CRLF
*( field-line CRLF )
CRLF
[ message-body ]
例えば、ワイヤ上の非常に簡単なGETリクエストは、https://blog.cloudflare.com/となります:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
そして、応答は次のようなものになります:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
このフォーマットは、ワイヤ上でメッセージをフレーム化します。つまり、1つのTCP接続を使って複数のリクエストとレスポンスをやり取りすることが可能になります。しかし、このフォーマットでは、各メッセージがまとめて送信される必要があります。さらに、リクエストと応答を正しく関連付けるために、厳密な順序が要求されます。つまり、メッセージは順序だてて交換され、多重化することはできません。https://blog.cloudflare.com/、https://blog.cloudflare.com/page/2/の2つのGETリクエストは、次のようになります:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLFGET /page/2/ HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
レスポンスは、次のようになります:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>CRLFHTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
Webページでは、これらの例よりも複雑なHTTPインタラクションが必要となります。Cloudflareブログにアクセスすると、ブラウザは複数のスクリプト、スタイル、メディアアセットを読み込みます。HTTP/1.1を使ってトップページを訪れ、すぐに2ページ目に移動した場合、ブラウザは2つの選択肢から選ぶことになります。ページ2が始まる前に、ページに対するキューに入れられたものでもう必要のないものすべての応答を待つか、TCP接続を閉じて新しい接続を開くことで、実行中のリクエストをキャンセルすることのいずれかとなります。どちらも、あまり現実的ではありません。ブラウザは、TCP接続のプール(ホストあたり最大6つ)を管理し、プール上で複雑なリクエストディスパッチロジックを実装することによって、これらの制限を回避する傾向があります。
HTTP/2は、HTTP/1.1の多くの問題に対処しています。各HTTPメッセージは、型、長さ、フラグ、ストリーム識別子(ID)と悪意のあるペイロードを持つHTTP/2フレームのセットにシリアライズされます。ストリームIDは、ワイヤ上のどのバイトがどのメッセージに適用されるかを明確にし、安全な多重化と同時実行を可能にします。ストリームは、双方向となります。クライアントはフレームを送信し、サーバーは同じIDを使ったフレームを返信します。
HTTP/2では、https://blog.cloudflare.comへの当社のGETリクエストはストリームID 1でやり取りされ、クライアントは1つのHEADERSフレームを送信し、サーバーは1つのHEADERSフレームと、それに続く1つ以上のDATAフレームで応答します。クライアントのリクエストは常に奇数番号のストリームIDを使用するので、後続のリクエストはストリームID 3、5、...を使用することになります。レスポンスはどのような順番でも提供することができ、異なるストリームからのフレームをインターリーブすることもできます。
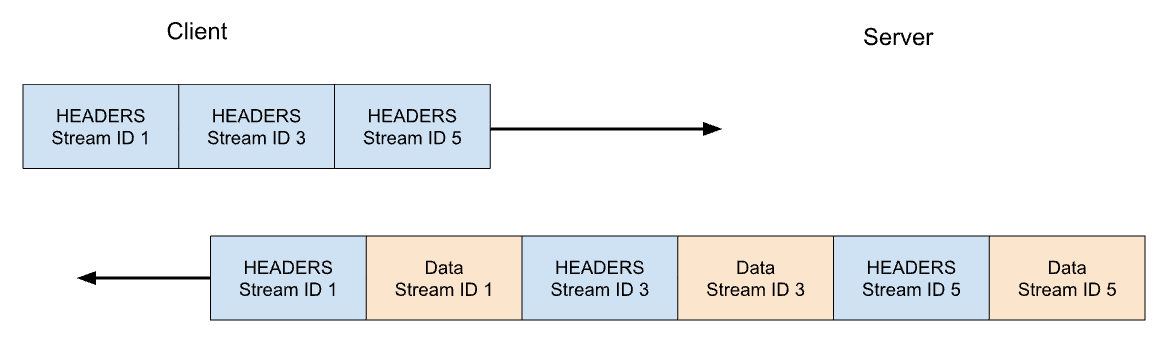
ストリーム多重化と同時実行は、HTTP/2の強力な機能です。これらは、単一のTCP接続をより効率的に使用することを可能にします。HTTP/2は、特に優先順位付けと組み合わせると、リソースの取得を最適化します。反面、クライアントが大量の並列作業を簡単に開始できるようにすることは、HTTP/1.1と比くらべサーバーリソースに対するピーク需要を増加させる可能性があります。これは明らかに、サービス拒否のベクトルです。
複数の防護策を提供するため、HTTP/2は最大アクティブ同時ストリームの概念を活用します。SETTINGS_MAX_CONCURRENT_STREAMSパラメータにより、サーバーは同時処理数の上限をアドバタイズできます。例えば、サーバーが上限を100とした場合、常時アクティブにできるのは100リクエストだけになります。クライアントがこの制限を超えてストリームを開こうとした場合、RST_STREAMフレームを使用してサーバーに拒否される必要があります。ストリーム拒否は、接続中の他のストリームには影響しません。
本当のところはもう少し複雑になります。ストリームには、ライフサイクルがあります。下図はHTTP/2ストリームのステートマシンの図です。クライアントとサーバーはストリームの状態をそれぞれ管理します。HEADERS、DATA、RST_STREAMフレームが送受信されると遷移が発生します。ストリームの状態のビューは独立していますが、同期しています。
HEADERSとDATAフレームはEND_STREAMフラグを含み、このフラグが値1(true)にセットされると、ステート遷移のトリガーとなります。

メッセージコンテンツを持たないGETリクエストの例で説明します。クライアントはまずストリームをアイドル状態からオープン状態に、続いて即座にハーフクローズ状態に遷移させます。クライアントのハーフクローズ状態は、もはやHEADERSやDATAを送信できないことを意味し、WINDOW_UPDATE、PRIORITY、RST_STREAMフレームのみを送信できます。ただし、任意のフレームを受信することができます。
サーバーがHEADERSフレームを受信して解析すると、ストリームの状態をアイドル状態からオープン状態、そしてハーフクローズ状態に遷移させ、クライアントと一致させます。サーバーがハーフクローズ状態であれば、どんなフレームでも送信できますが、WINDOW_UPDATE、PRIORITY、またはRST_STREAMフレームしか受信できないことを意味します。
そのため、サーバーはEND_STREAMフラグを0に設定したHEADERSを送信し、次にEND_STREAMフラグを1に設定したDATAを送信します。DATAフレームは、サーバーでハーフクローズドからクローズドへのストリームの遷移をトリガーします。クライアントがこのフレームを受信すると、ストリームもクローズドに遷移します。ストリームがクローズされると、フレームの送受信はできなくなります。
このライフサイクルを今カレンシーの文脈に当てはめ直し、HTTP/2は次のように記述します:
「オープン」状態にあるストリーム、または「ハーフクローズド」状態のいずれかにあるストリームは、エンドポイントが開くことを許可されるストリームの最大数にカウントされます。これら3つの状態のいずれかにあるストリームは、SETTINGS_MAX_CONCURRENT_STREAMS設定でアドバタイズされる制限にカウントされます。
理論的には、コンカレンシーの制限は、有用です。しかし、その効果を妨げる現実的な要因があります。詳細は、このブログの後半で開設します。
HTTP/2リクエストの取り消し
前段で、クライアントからの実行中のリクエストのキャンセルについて説明しました。HTTP/2は、HTTP/1.1よりもはるかに効率的な方法でこれをサポートしています。接続全体を切断するのではなく、クライアントは1つのストリームに対してRST_STREAMフレームを送信することができます。サーバーにリクエストの処理を中止し、レスポンスを中止するよう指示するものです。これによって、Free 、サーバーのリソースを節約し、帯域幅の浪費を避けることができます。
先ほどの3つのリクエストの例を考えてみます。このときクライアントは、すべてのHEADERSが送信された後に、ストリーム1のリクエストをキャンセルします。サーバーは、応答を提供する準備ができる前にこのRST_STREAMフレームを解析し、代わりにストリーム3と5にのみ応答します:
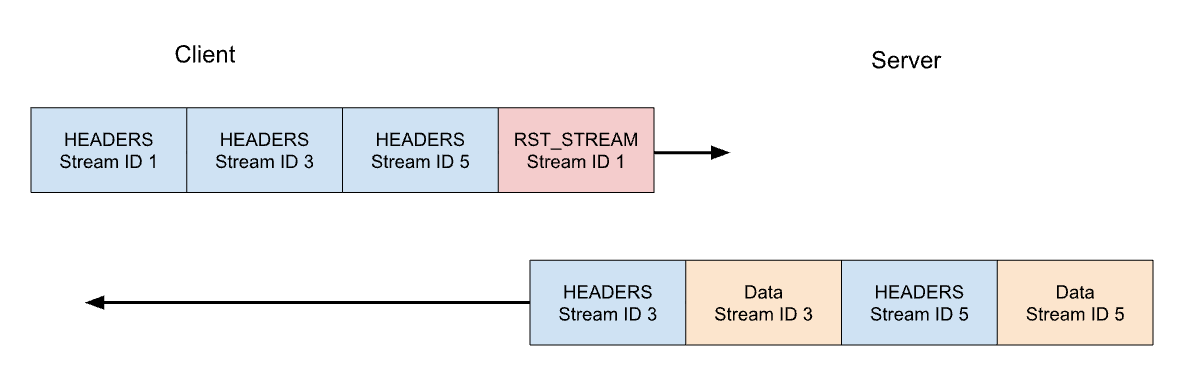
リクエストのキャンセルは、便利な機能です。たとえば、複数の画像を含むウェブページをスクロールするとき、Webブラウザはビューポートの外にある画像をキャンセルすることができ、ビューポートに入る画像をより速く読み込むことができます。HTTP/2は、HTTP/1.1に比べてこの動作をより効率的にしています。
キャンセルされたリクエストストリームは、ストリームのライフサイクルを急速に遷移していきます。END_STREAMフラグが1に設定されたクライアントのHEADERSは、状態をアイドルからオープン、ハーフクローズへと遷移させ、RST_STREAMは直ちにハーフクローズからクローズへと遷移させます。

ストリームの同時実行数制限に寄与するのは、オープン状態またはハーフクローズ状態にあるストリームだけであることを思い出してください。クライアントがストリームをキャンセルすると、そのクライアントは即座に別のストリームをオープンできるようになり、すぐに別のリクエストを送信できるようになります。これがCVE-2023-44487を機能させる要諦なのです。
サービス拒否につながるRapid Reset
HTTP/2リクエストのキャンセルは、制限のない数のストリームを急速にリセットするために悪用される可能性があります。HTTP/2サーバーがクライアントから送信されたRST_STREAMフレームを処理し、十分に迅速に状態を取りやめることができる場合、こうした迅速なリセットは問題を引き起こしません。問題が発生し始めるのは、片付ける際に何らかの遅延やタイムラグがある場合です。クライアントは非常に多くのリクエストを処理するため、作業のバックログが蓄積され、サーバーのリソースを過剰に消費することになります。
一般的なHTTPデプロイメントアーキテクチャは、HTTP/2プロキシやロードバランサーを他のコンポーネントの前で実行することになっています。クライアントのリクエストが到着すると、それはすぐにディスパッチされ、実際の作業は非同期アクティビティとして別の場所で行われます。これにより、プロキシはクライアントのトラフィックを非常に効率的に処理することができます。しかし、このような懸念の層別は、プロキシが処理中のジョブを片付けることを難しくします。そのため、これらのデプロイでは、急速なリセットによる問題が発生しやすくなります。
Cloudflareのリバースプロキシは、HTTP/2クライアントのトラフィックを処理する際、接続ソケットからデータをバッファにコピーし、バッファリングされたデータを順番に処理していきます。各リクエストが読み込まれると(HEADERSとDATAフレーム)、アップストリームサービスにディスパッチされます。RST_STREAMフレームが読み込まれると、リクエストのローカル状態が破棄され、リクエストがキャンセルされたことがアップストリームに通知されます。バッファ全体が消費されるまで、これが繰り返されます。しかしながら、このロジックは悪用される可能性があります。悪意のあるクライアントが膨大なリクエストの連鎖を送信し始め、接続の開始時にリセットされると、当社のサーバーはそれらすべてを熱心に読み込み、新しい着信リクエストを処理できなくなるほどのストレスをアップストリームサーバーにもたらすでしょう。
強調すべき重要な点は、ストリームの同時実行性だけでは急激なリセットを緩和できないということです。サーバーがSETTINGS_MAX_CONCURRENT_STREAMSの値を選んだとしても、クライアントは高いリクエストレートを生成するためにリクエストを繰り返すことができます。
Rapid Resetの全貌
以下、合計1000リクエストを試みる概念実証クライアントを使用して再現された高速リセットの例を示します。軽減策は一切設けず、市販品のサーバーを用いたテスト環境で、443番ポートを用いています。トラフィックはWiresharkを使って分解され、わかりやすくするためにHTTP/2トラフィックだけを表示するようにフィルタリングされています。進めるには、pcapをダウンロードしてください。

コマ数が多いので、ちょっと見づらいかもしれません。WiresharkのStatistics> HTTP2ツールで簡単な要約をまとめています:
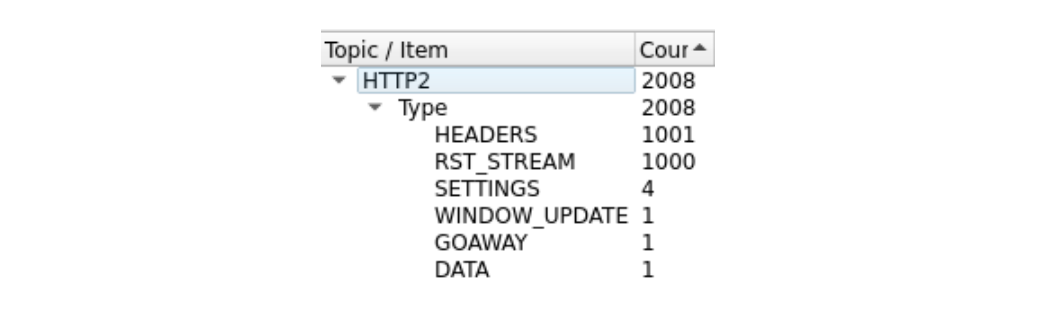
このトレースの最初のフレームであるパケット14はサーバーのSETTINGSフレームであり、最大ストリーム同時実行数100をアドバタイズしています。パケット15では、クライアントはいくつかの制御フレームを送信し、その後、急速にリセットするリクエストを開始します。最初のHEADERSフレームは26バイト長ですが、それ以降のHEADERSはすべて9バイトです。このサイズの違いは、HPACKと呼ばれる圧縮技術によるものです。パケット15は合計で525のリクエストを含み、ストリーム1051まで増やされます。
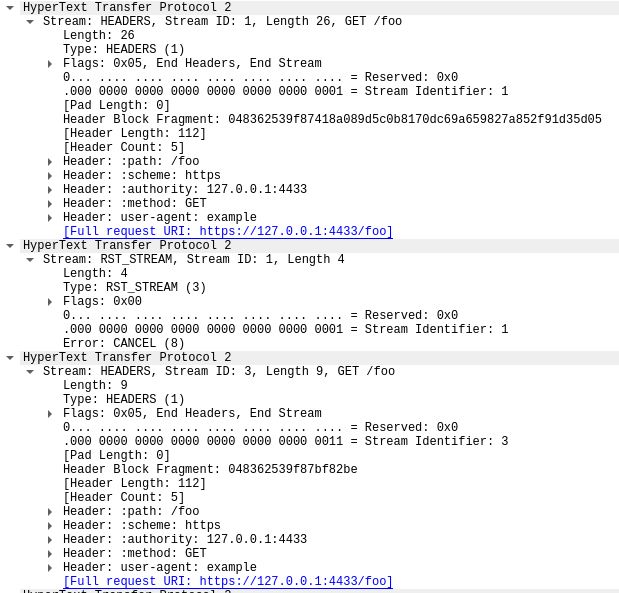
興味深いことに、ストリーム1051のRST_STREAMはパケット15に適合しないため、パケット16ではサーバーが404応答しているのがわかります。その後、残りの475リクエストの送信に移る前に、パケット17でクライアントがRST_STREAMを送信しています。
サーバーは100の同時ストリームをアドバタイズしていますが、クライアントが送信したパケットはいずれも、それよりも多くのHEADERSフレームを送信しています。クライアントはサーバーからの折り返しのトラフィックを待つ必要がなく、送信できるパケットのサイズによってのみ制限されています。このトレースにはサーバーのRST_STREAMフレームは見られず、サーバーは同時ストリーム違反を観測していないことを示しています。
顧客への影響
上述したように、リクエストがキャンセルされると、アップストリームサービスは通知を受け、多くのリソースを浪費する前にリクエストを中止することができます。今回の攻撃では、ほとんどの悪意あるリクエストが配信元サーバーに転送されることはありませんでした。しかし、これらの攻撃の規模が大きいため、何らかの影響が引き起こされます。
まず、リクエストの着信率がこれまでにないピークに達したため、クライアントが目にする502エラーのレベルが上昇したという報告がありました。これは、最も影響を受けたデータセンターで発生しており、すべてのリクエストを処理するのに難儀しました。当社のネットワークは大規模な攻撃にも対応できるようになっているものの、今回の脆弱性は当社のインフラストラクチャの弱点を露呈するものでした。データセンターのひとつに届いたリクエストがどのように処理されるかを中心に、詳細をもう少し掘り下げてみましょう:
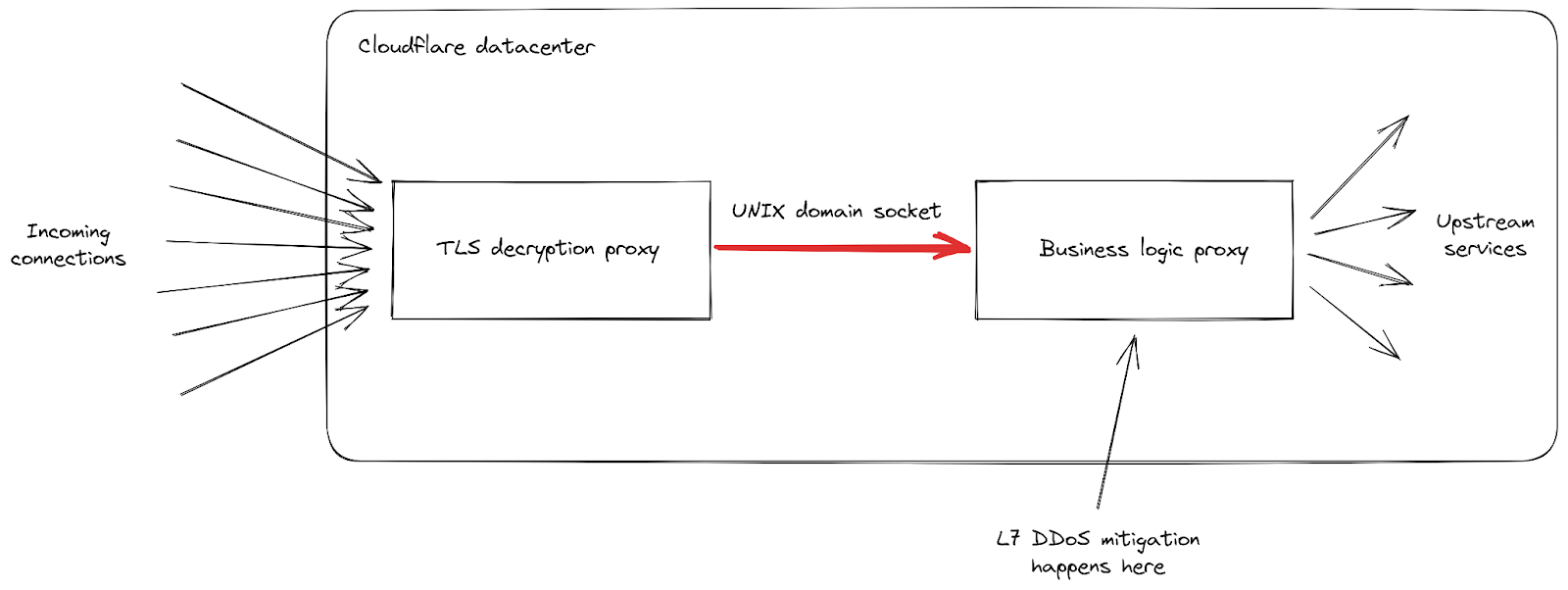
Cloudflareのインフラストラクチャは、役割の異なるプロキシサーバのチェーンで構成されていることがわかります。特に、クライアントがHTTPSトラフィックを送信するためにCloudflareに接続すると、まずTLS復号化プロキシに当たります。このプロキシはTLSトラフィックを復号化し、HTTP 1、2、または3トラフィックを処理した後、「ビジネスロジック」プロキシに転送します。このプロキシは、各顧客のすべての設定をロードし、リクエストを他のアップストリームサービスに正しくルーティングする役割を担っており、さらに当社の場合ではセキュリティ機能も担っています。このプロキシで、L7攻撃緩和の処理が行われます。
この攻撃ベクトルでの問題点は、すべての接続で非常に多くのリクエストを素早く送信することになります。当社がブロックするチャンスを得る前に、そのひとつひとつがビジネスロジックプロキシに転送されなければならなりませんでした。リクエストのスループットがプロキシのキャパシティを上回るようになると、この2つのサービスをつなぐパイプは、いくつかのサーバーで飽和レベルに達しました。
これが起こると、TLSプロキシはアップストリームプロキシに接続できなくなり、最も深刻な攻撃時に「502 Bad Gateway」エラーが表示されるクライアントがあるのは、これが理由です。重要なのは、現在ではHTTP分析の作成に使用されるログは、ビジネスロジックプロキシからも出力されることになります。その結果、これらのエラーはCloudflareのダッシュボードには表示されません。当社内部のダッシュボードによると、(緩和策を実施する前の)最初の攻撃波では、リクエストの約1%が影響を受け、8月29日の最も深刻な攻撃では数秒間で約12%のピークが見られました。次のグラフは、この現象が起きていた2時間にわたるエラーの割合を示したものです:

当社では、この記事の後半で詳述するとおり、その後の数日間でこの数を劇的に減らすことに努めました。当社によるスタックの変更と軽減策により、こうした攻撃の規模が大幅に縮小されたおかげで、この数は今日では事実上ゼロになっています:

499エラーとHTTP/2ストリーム同時実行の課題
一部の顧客から報告されたもう一つの症状に、499エラーの増加がありました。この理由は少し違っており、この投稿で前述したHTTP/2接続の最大ストリームの同時実行数に関連しています。
HTTP/2の設定は、SETTINGSフレームを使用して接続の開始時に交換されます。明示的なパラメータを受け取らない場合、デフォルト値が適用されます。クライアントがHTTP/2接続を確立すると、サーバーの設定を待つ(遅い)か、デフォルト値を想定してリクエストを開始(速い)することになります。SETTINGS_MAX_CONCURRENT_STREAMSでは、デフォルトでは事実上無制限となります(ストリームIDは31ビットの数値空間を使用し、リクエストは奇数を使用するため、実際の制限は1073741824となります)。仕様では、サーバーが提供するストリーム数は100を下回らないようにすることを推奨しています。クライアントは一般的にスピードを重視するため、サーバーの設定を待つ傾向がなく、ちょっとした競合状態が発生します。つまり、クライアントは、サーバーがどのリミットを選択するかという賭けに出ているのです。もし間違ったリミットを選択すれば、リクエストは拒否され、再試行しなければならなくなります。1073741824ストリームに賭けるギャンブルは、賢明ではありません。その代わり、多くのクライアントは、サーバーが仕様の推奨に従うことを期待し、同時ストリーム発行数を100に制限することにしています。サーバーが100以下のものを選んだ場合、このクライアントのギャンブルは失敗し、ストリームはリセットされます。
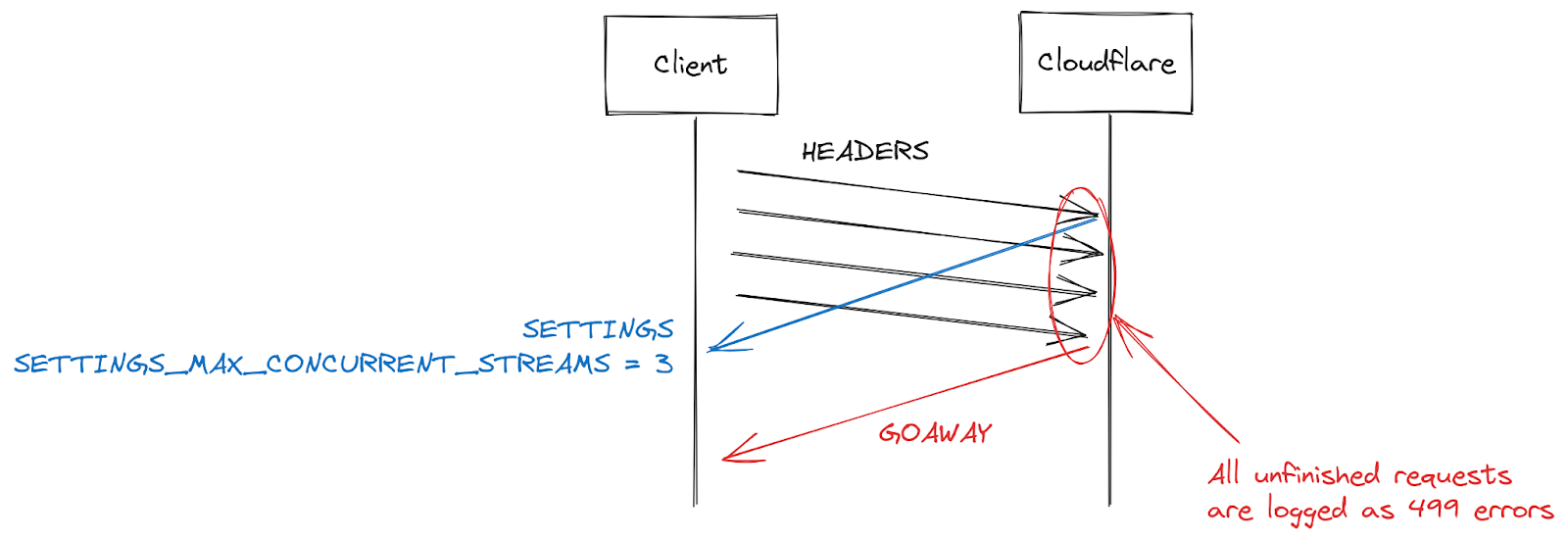
サーバーによるストリームのリセットには、同時実行数の上限を超えた場合など、たくさんの理由があります。HTTP/2は厳格であり、構文解析やロジックエラーが発生した場合はストリームを閉じる必要があります。2019年、CloudflareはHTTP/2のDoS脆弱性に対応して複数の緩和策を開発しました。これらの脆弱性のいくつかは、クライアントが誤動作を起こし、サーバーがストリームをリセットすることによって引き起こされていました。そのようなクライアントを取り締まるための非常に効果的な戦略は、接続中のサーバーリセットの回数をカウントし、それがある閾値を超えたらGOAWAYフレームで接続を閉じることになります。正当なクライアントは、接続中に1つか2つのミスをするかもしれないものの、それは許容範囲内となります。あまりにも多くのミスをするクライアントは、おそらく壊れているか悪意のあるクライアントであり、接続を閉じることで両方のケースに対処できます。
CVE-2023-44487によるDoS攻撃に対応している間、Cloudflareはストリームの最大同時実行数を64に減らしました。この変更を行う前、当社はクライアントがSETTINGSを待たず、代わりに100の同時実行を想定していることを知りませんでした。画像ギャラリーのような一部のWebページでは、接続開始時にブラウザがすぐに100リクエストを送信することがあります。残念ながら、制限を超えた36のストリームはすべてリセットする必要があり、これがカウント緩和のトリガーとなりました。つまり、正当なクライアントの接続を閉じてしまい、ページのロードが完全に失敗してしまったのです。この相互運用性の問題に気づいてすぐに、ストリームの最大同時接続数を100に変更しました。
Cloudflare側での対応
2019年、HTTP/2の実装に関連する複数のDoS脆弱性が発覚しました。Cloudflareはこれを受けて一連の検出と緩和策を開発し、デプロイしました。CVE-2023-44487は、HTTP/2の脆弱性の異なる症状です。しかし、この脆弱性を緩和するために、クライアントから送信されるRST_STREAMフレームを監視し、不正に使用されている場合は接続を閉じるよう、既存の保護を拡張することができました。RST_STREAMの正当なクライアント利用への影響はありませんでした。
直接的な修正に加え、サーバーのHTTP/2フレーム処理とリクエストディスパッチコードにいくつかの改善を実装しました。さらに、ビジネスロジックサーバーではキューイングとスケジューリングを改善し、不要な作業が減り、キャンセルの応答性が向上しました。これらを組み合わせることで、様々な悪用パターンの可能性の影響を軽減し、サーバーに飽和する前にリクエストを処理するための余裕を与えることができました。
攻撃の早期軽減
Cloudflareはすでに、より安価な方法で非常に大規模な攻撃を効率的に軽減するシステムを導入していました。その一つが、「IP Jail」というものです。ハイパー帯域幅消費型攻撃の場合、このシステムは攻撃に参加しているクライアントIPを収集し、攻撃されたプロパティへの接続をIPレベルまたは当社のTLSプロキシで阻止します。この貴重な数秒の間にオリジンはすでに保護されているものの、当社のインフラストラクチャはまだすべてのHTTPリクエストを吸収する必要があります。この新しいボットネットには事実上立ち上がり期間がないため、問題になる前に攻撃を無力化する必要があります。
これを実現するため、当社はIP Jailシステムを拡張してインフラストラクチャ全体を保護しました。IPが「ジェイル」(投獄)されると、攻撃されたプロパティへの接続がブロックされるだけでなく、対応するIPがCloudflare上の他のドメインに対してHTTP/2を使用することも、しばらくの間禁止されます。このようなプロトコルは、HTTP/1.xでの悪用は不可能です。このため、攻撃者による大規模な攻撃の実行は制限されるものの、同じIPを共有する正当なクライアントであればその間のパフォーマンスの低下はごくわずかなものとなります。IPベースの攻撃軽減策は、非常に鈍感なツールです。このため、このような規模で使用する場合、細心の注意を払い、誤検知をできるだけ避けるようにしなければなりません。さらに、ボットネット内の特定のIPの寿命は通常短いため、長期的な緩和策は良いことよりも悪いことの方が多い可能性が高くなります。以下のグラフは、我々が目撃した攻撃におけるIPの入れ替わりを示したものです:
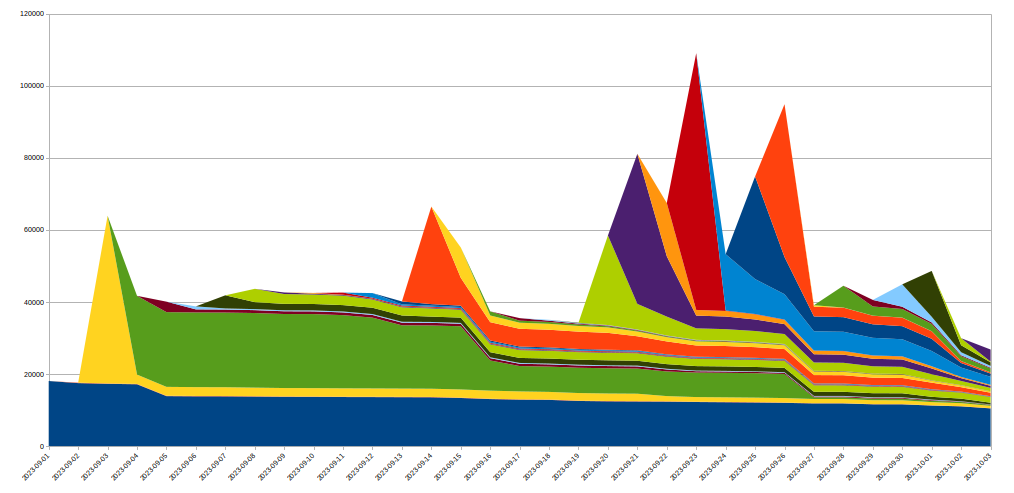
このように、ある日に発見された多くの新規IPは、その後すぐに消えてしまいます。
これらの動作は、すべてHTTPSパイプラインの最初にあるTLSプロキシで行われるため、通常のL7攻撃低減システムと比較してかなりのリソースを節約できます。これにより、これらの攻撃をはるかにスムーズに切り抜けることができるようになり、現在ではこれらのボットネットによって引き起こされるランダムな502エラーの数は、ゼロになりました。
可観測性の向上
当社が変革しようとしているもうひとつの地平に、観測可能性があります。顧客分析で捉えられることなく、クライアントにエラーを返してしまうのは、不満につながります。幸いなことに、今回の攻撃のはるか以前から、これらのシステムをオーバーホールするプロジェクトが進行中でした。最終的には、ビジネスロジックプロキシがログ・データを統合して出力する代わりに、インフラ内の各サービスが独自にデータをログできるようになります。今回の事件は、この取り組みの重要性を浮き彫りにしました。
また、接続レベルのロギングの改善にも取り組んでおり、このようなプロトコルの乱用をより迅速に発見し、DDoS軽減能力を向上させることができます。
まとめ
今回の攻撃は記録的な規模であったものの、これが最後ではないことは明白です。攻撃がますます巧妙化する中、Cloudflareでは新たな脅威を能動的に特定し、当社のグローバル・ネットワークに対策をデプロイすることで、数百万人の顧客が即座に自動的に保護されるようたゆまぬ努力を続けています。
Cloudflareは、2017年以来すべてのお客様に無料、従量制、無制限のDDoS攻撃対策を提供してきました。さらに、あらゆる規模の組織のニーズに合わせて、さまざまな追加のセキュリティ機能を提供しています。保護されているかどうかわからない場合、または保護方法をお知りになりたい場合、当社にお問い合わせください。
HTTP/2 Rapid Reset : anatomie de l'attaque record
À compter du 25 août 2023, nous avons commencé à observer des attaques HTTP inhabituellement volumineuses frappant bon nombre de nos clients. Ces attaques ont été détectées et atténuées par notre système anti-DDoS automatisé. Il n'a pas fallu longtemps pour que ces attaques atteignent des tailles record, pour finir par culminer à un peu plus de 201 millions de requêtes par seconde, soit un chiffre près de trois fois supérieur à la précédente attaque la plus volumineuse que nous ayons enregistrée.
Le fait que l'acteur malveillant soit parvenu à générer une attaque d'une telle ampleur à l'aide d'un botnet de tout juste 20 000 machines s'avère préoccupant. Certains botnets actuels se composent de centaines de milliers ou de millions de machines. Comme qu'Internet dans son ensemble ne reçoit habituellement qu'entre 1 et 3 milliards de requêtes chaque seconde, il n'est pas inconcevable que l'utilisation de cette méthode puisse concentrer l'intégralité du nombre de requêtes du réseau sur un petit nombre de cibles.
Détection et atténuation
Il s'agissait d'un nouveau vecteur d'attaque évoluant à une échelle sans précédent, mais les protections Cloudflare Continue reading