0
iPhone 7 Rumor Rollup: beyond WWDC; Deep Blue; sharp-dressed thieves
The really shocking iPhone 7 news this week would be if anything related to Apple’s next big smartphone were announced at the company’s annual Worldwide Developers Conference in San Francisco. Yes, big improvements to iOS and Siri are expected to be unveiled, and they will be important for iPhone 7, but we’re talking iPhone developments beyond that that might hit the market in the fall.We’re talking about really crucial stuff, like phone color…Goodbye gray, hello blue iPhone 7? Speculation swirled late last week that Apple is plotting to ditch its Space Gray iPhone color for deep blue (undoubtedly with some grabby qualifier attached). To read this article in full or to leave a comment, please click here
 Let’s PLAY!
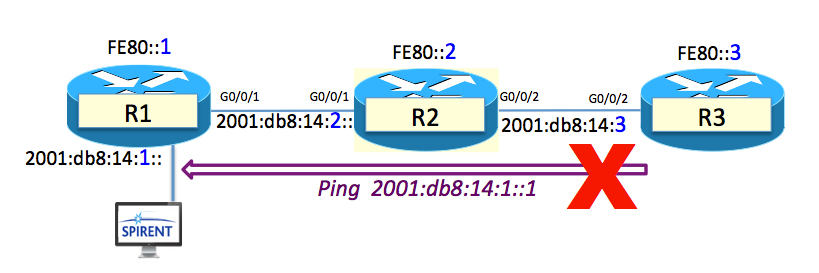
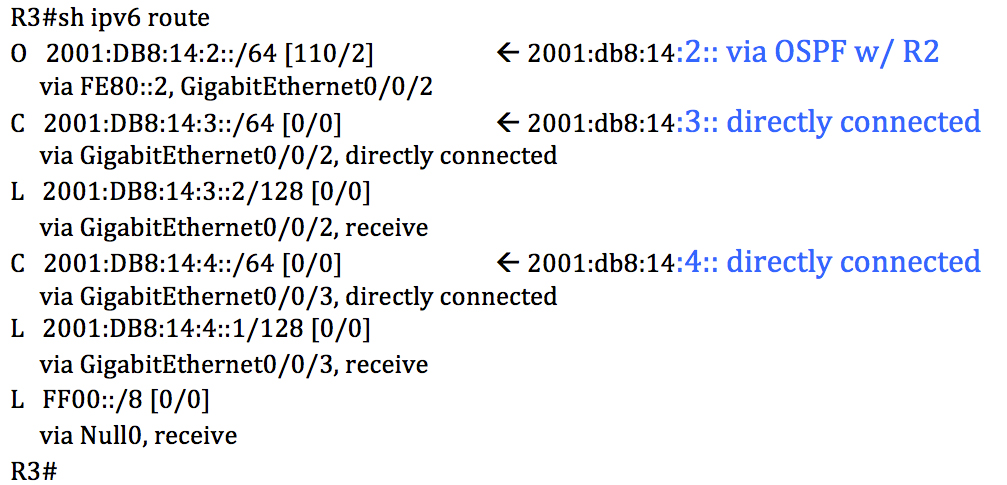
Let’s PLAY!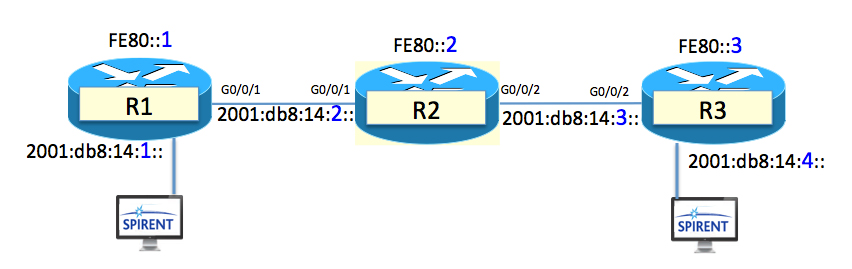




 DigitalOcean's CTO, Simplivity's latest, and more.
DigitalOcean's CTO, Simplivity's latest, and more. The plan is to automate the WAN.
The plan is to automate the WAN. Staying relevant in a world of containers.
Staying relevant in a world of containers. The open source platform could be used by commercial buildings.
The open source platform could be used by commercial buildings.