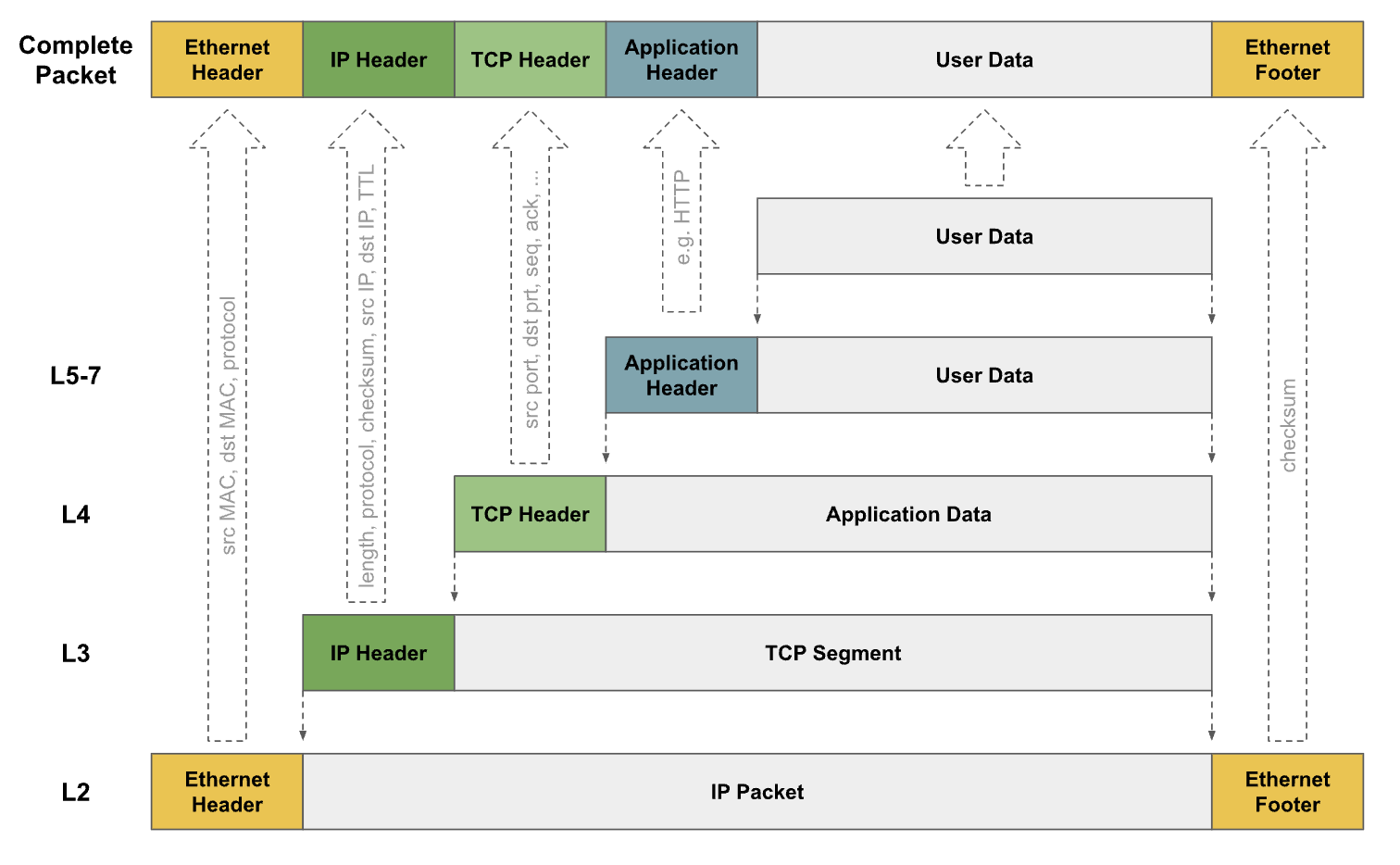
Network Labs on a Budget

"Can you suggest some specs for a server for my network labs?" is probably the question I get asked the most. People reach out all the time asking for recommendations. The thing is, I never really know their exact situation or what they’re trying to do in their lab. So, I usually just share what I have and what worked best for me, and let them decide what fits their setup.
In this post, I’ll go over the cheapest way to build your own network lab without spending too much.
💡
Disclaimer - This post is based on my personal experience and is meant to be general advice only. Everyone’s situation is different, so please do your own research before buying anything. I’m not responsible if you end up purchasing something that doesn’t suit your needs or expectations.
What We Will Cover?
- Buying a used mini PC
- Proxmox as the hypervisor (optional)
- Linux as a VM
- Containerlab/Netlab, EVE-NG, Cisco CML
- Proxmox Backup Server (optional)
- Simplest Option for Absolute Beginners

TL;DR
You don’t need expensive hardware to build a solid network lab. A used mini PC with decent specs is more than enough to run tools like Proxmox, Continue reading
 which brings a wave of new features and improvements.
which brings a wave of new features and improvements.