Understanding Shortest Path First
Link state protocols like OSPF and IS-IS use the Shortest Path First (SPF) algorithm developed by Edsger Dijkstra. Edsger was a Dutch computer scientist, programmer, software engineer, mathematician, and science essayist. He wanted to solve the problem of finding the shortest distance between two cities such as Rotterdam and Groningen. The solution came to him when sitting in a café and the rest is history. SPF is used in many applications, such as GPS, but also in routing protocols, which I’ll cover today.
To explain SPF, I’ll be working with the following topology:
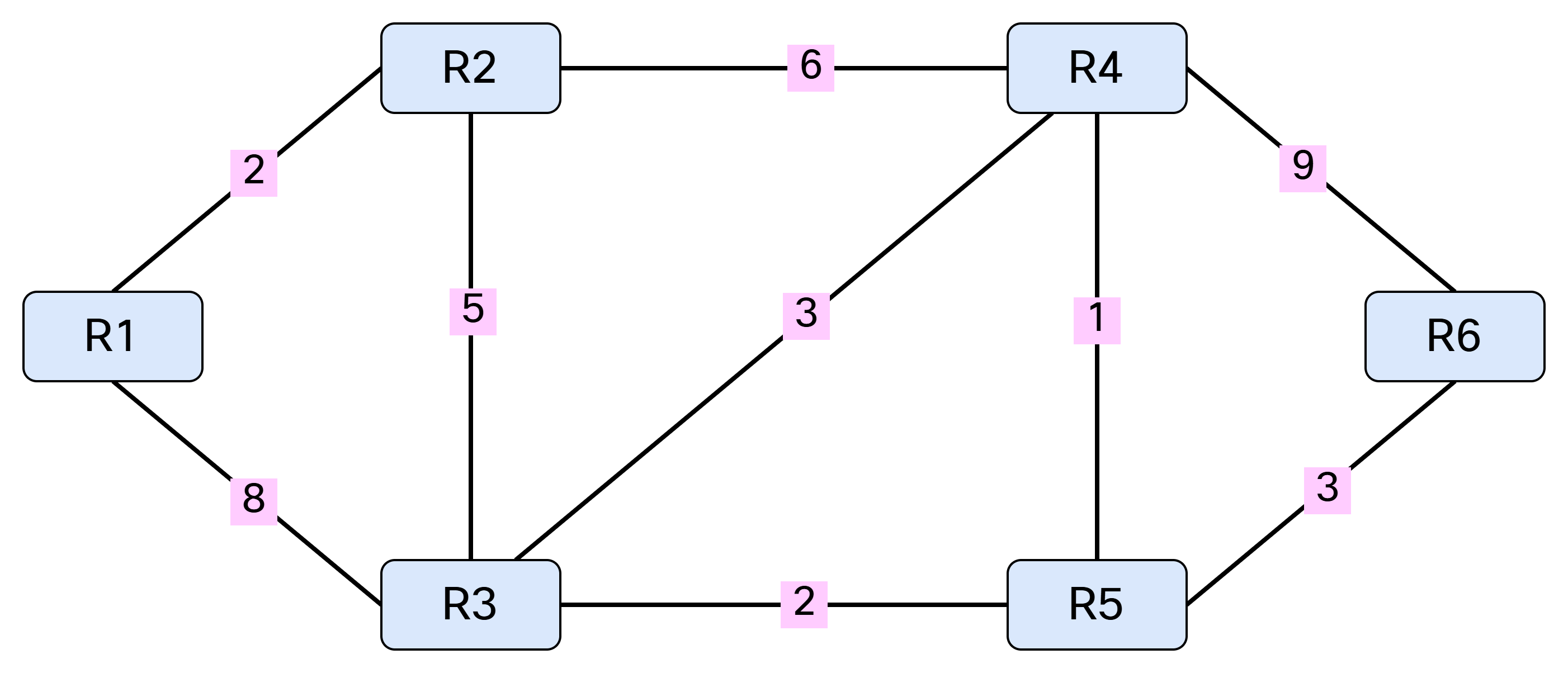
Note that SPF only works with a weighted graph where we have positive weights. I’m using symmetrical costs, although you could have different costs in each direction. Before running SPF, we need to build our Link State Database (LSDB) and I’ll be using IS-IS in my lab for this purpose. Based on the topology above, we can build a table showing the cost between the nodes:
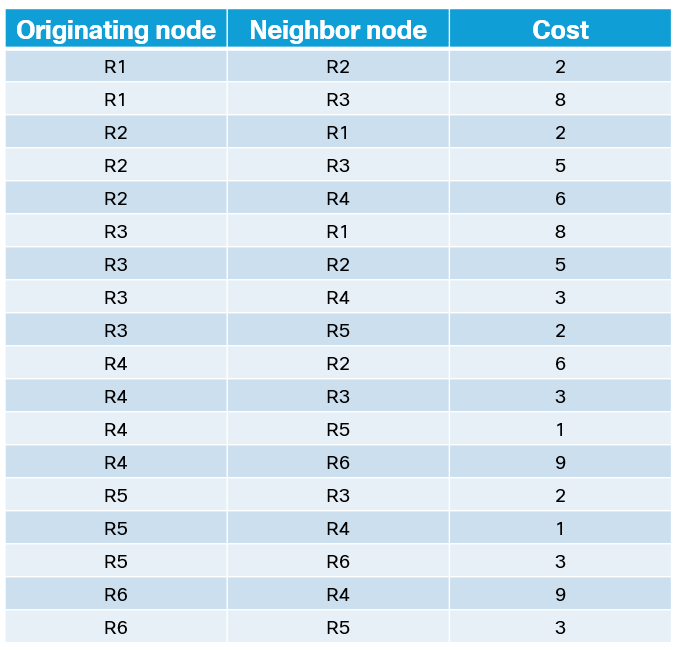
This triplet of information consists of originating node, neighbor node, and cost. It can also be represented as [R1, R2, 2], [R1, R3, 8], [R2, R1, 2], [R2, R3, 5], [R2, R4, 6], [R3, R1, 8], [R3, R2, 5], [R3, R4, Continue reading