0
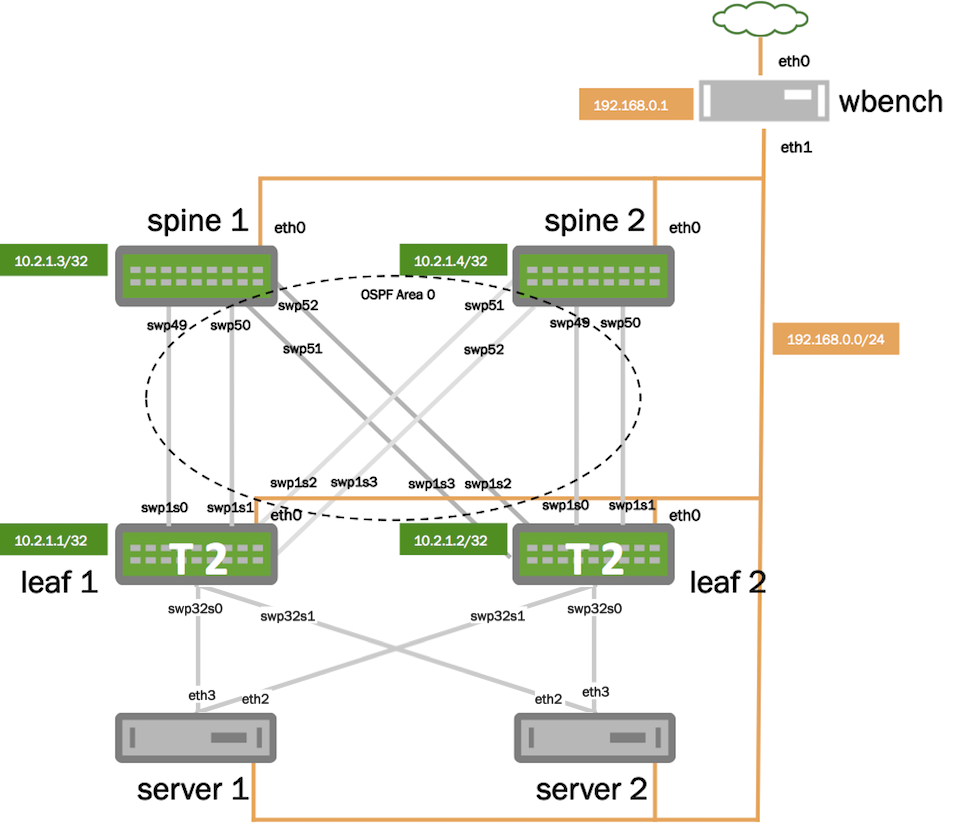
Real-time network and system metrics as a service describes how to use data captured from the network shown above to explore the functionality of
sFlow-RT real-time analytics software. This article builds on the previous article to show how knowledge of network topology can be used to enhance analytics, see
Topology for documentation.
First, follow the instructions in the
previous example and start an instance of sFlow-RT using the captured sFlow.
curl -O https://raw.githubusercontent.com/sflow-rt/fabric-view/master/demo/topology.json
Then, download the topology file for the example.
curl -X PUT -H "Content-Type: application/json" -d @topology.json \
http://localhost:8008/topology/json
Install the topology using the sFlow-RT REST API.
curl http://localhost:8008/topology/json
Retrieve the topology.
{
"version": 0,
"links": {
"L1": {
"node2": "spine1",
"node1": "leaf1",
"port1": "swp1s0",
"port2": "swp49"
},
"L2": {
"node2": "spine1",
"node1": "leaf1",
"port1": "swp1s1",
"port2": "swp50"
},
"L3": {
"node2": "spine2",
"node1": "leaf1",
"port1": "swp1s2",
"port2": "swp51"
},
"L4": {
"node2": "spine2",
"node1": "leaf1",
"port1": "swp1s3",
"port2": "swp52"
},
"L5": {
"node2": "spine2",
"node1": "leaf2",
"port1": "swp1s0",
"port2": "swp49"
},
"L6": {
"node2": "spine2",
"node1": "leaf2",
"port1": "swp1s1",
"port2": "swp50"
},
"L7": {
"node2": "spine1",
"node1": "leaf2",
"port1": "swp1s2",
"port2": "swp51"
},
"L8": {
"node2": "spine1",
"node1": "leaf2",
"port1": "swp1s3",
"port2": Continue reading