Author Archives: Marek Majkowski
Author Archives: Marek Majkowski
At Cloudflare, we do everything we can to avoid interruption to our services. We frequently deploy new versions of the code that delivers the services, so we need to be able to restart the server processes to upgrade them without missing a beat. In particular, performing graceful restarts (also known as "zero downtime") for UDP servers has proven to be surprisingly difficult.
We've previously written about graceful restarts in the context of TCP, which is much easier to handle. We didn't have a strong reason to deal with UDP until recently — when protocols like HTTP3/QUIC became critical. This blog post introduces udpgrm, a lightweight daemon that helps us to upgrade UDP servers without dropping a single packet.
Here's the udpgrm GitHub repo.
In the early days of the Internet, UDP was used for stateless request/response communication with protocols like DNS or NTP. Restarts of a server process are not a problem in that context, because it does not have to retain state across multiple requests. However, modern protocols like QUIC, WireGuard, and SIP, as well as online games, use stateful flows. So what happens to the state associated with a flow when a server process is Continue reading
The Internet is designed to provide multiple paths between two endpoints. Attempts to exploit multi-path opportunities are almost as old as the Internet, culminating in RFCs documenting some of the challenges. Still, today, virtually all end-to-end communication uses only one available path at a time. Why? It turns out that in multi-path setups, even the smallest differences between paths can harm the connection quality due to packet reordering and other issues. As a result, Internet devices usually use a single path and let the routers handle the path selection.
There is another way. Enter Multi-Path TCP (MPTCP), which exploits the presence of multiple interfaces on a device, such as a mobile phone that has both Wi-Fi and cellular antennas, to achieve multi-path connectivity.
MPTCP has had a long history — see the Wikipedia article and the spec (RFC 8684) for details. It's a major extension to the TCP protocol, and historically most of the TCP changes failed to gain traction. However, MPTCP is supposed to be mostly an operating system feature, making it easy to enable. Applications should only need minor code changes to support it.
There is a caveat, however: MPTCP is still fairly immature, and while it can Continue reading
I’ve noticed that many shops are increasingly using e-paper displays. They’re impressive: high contrast, no backlight, and no visible cables. Unlike most electronics, these displays are seamlessly integrated and feel very natural. This got me wondering: is it possible to use such a display for a pet project? I want to experiment with this technology myself.

(source)
My main goal in this project is to understand the hardware and its capabilities. Here, I'll be using an e-paper display to show the current weather, but at its core, I’m simply feeding data from a website to the display. While it sounds straightforward, it actually requires three layers of software to pull off. Still, it’s a fun challenge and a great opportunity to work with both embedded hardware and Cloudflare Workers.
For this project, I'm using components from Waveshare. They offer a variety of e-paper displays, ranging from credit card-sized to A4-sized models. I chose the 7.5-inch, two-color "e-Paper (G)" display. For the controller, I'm using a Waveshare ESP32-based universal board. With just these two components — a display and a controller — I was ready to get started.

When the components arrived, I carefully Continue reading


It's a never-ending effort to improve the performance of our infrastructure. As part of that quest, we wanted to squeeze as much network oomph as possible from our virtual machines. Internally for some projects we use Firecracker, which is a KVM-based virtual machine manager (VMM) that runs light-weight “Micro-VM”s. Each Firecracker instance uses a tap device to communicate with a host system. Not knowing much about tap, I had to up my game, however, it wasn't easy — the documentation is messy and spread across the Internet.
Here are the notes that I wish someone had passed me when I started out on this journey!
A tap device is a virtual network interface that looks like an ethernet network card. Instead of having real wires plugged into it, it exposes a nice handy file descriptor to an application willing to send/receive packets. Historically tap devices were mostly used to implement VPN clients. The machine would route traffic towards a tap interface, and a VPN client application would pick them up and process accordingly. For example this is what our Cloudflare WARP Linux client does. Here's how it looks on my laptop:
$ ip link list
...
18: CloudflareWARP: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> Continue reading


Once my holidays had passed, I found myself reluctantly reemerging into the world of the living. I powered on a corporate laptop, scared to check on my email inbox. However, before turning on the browser, obviously, I had to run a ping. Debugging the network is a mandatory first step after a boot, right? As expected, the network was perfectly healthy but what caught me off guard was this message:
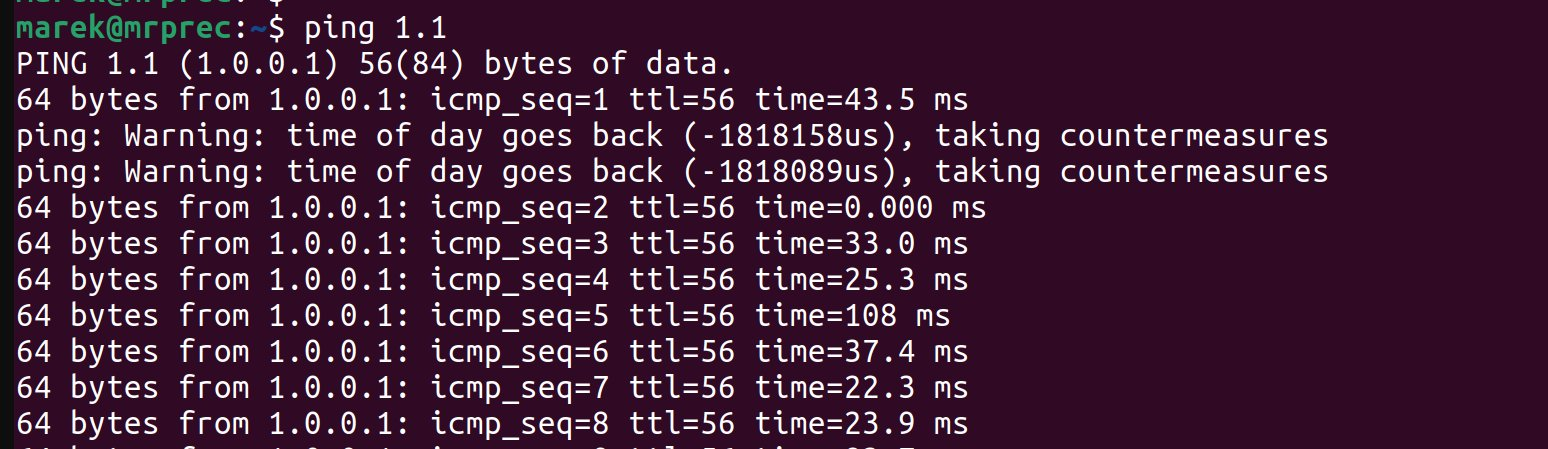
I was not expecting ping to take countermeasures that early on in a day. Gosh, I wasn't expecting any countermeasures that Monday!
Once I got over the initial confusion, I took a deep breath and collected my thoughts. You don't have to be Sherlock Holmes to figure out what has happened. I'm really fast - I started ping before the system NTP daemon synchronized the time. In my case, the computer clock was rolled backward, confusing ping.
While this doesn't happen too often, a computer clock can be freely adjusted either forward or backward. However, it's pretty rare for a regular network utility, like ping, to try to manage a situation like this. It's even less common to call it "taking countermeasures". I would totally expect ping to just print Continue reading


A lot of Cloudflare's technology is well documented. For example, how we handle traffic between the eyeballs (clients) and our servers has been discussed many times on this blog: “A brief primer on anycast (2011)”, "Load Balancing without Load Balancers (2013)", "Path MTU discovery in practice (2015)", "Cloudflare's edge load balancer (2020)", "How we fixed the BSD socket API (2022)".
However, we have rarely talked about the second part of our networking setup — how our servers fetch the content from the Internet. In this blog we’re going to cover this gap. We'll discuss how we manage Cloudflare IP addresses used to retrieve the data from the Internet, how our egress network design has evolved and how we optimized it for best use of available IP space.
Brace yourself. We have a lot to cover.
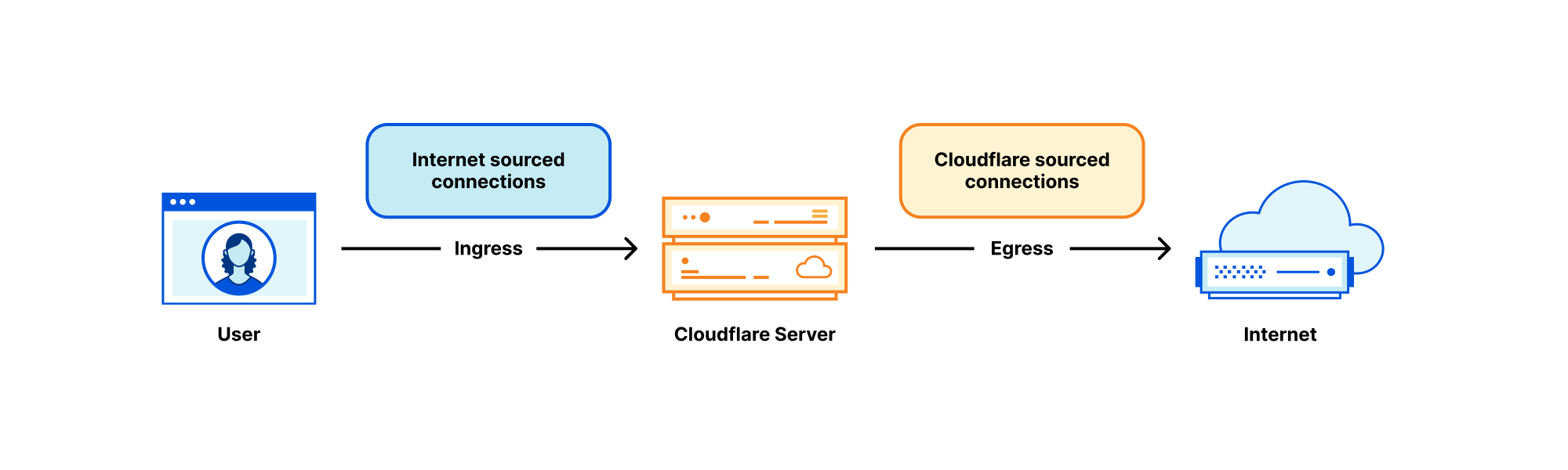
Each Cloudflare server deals with many kinds of networking traffic, but two rough categories stand out:
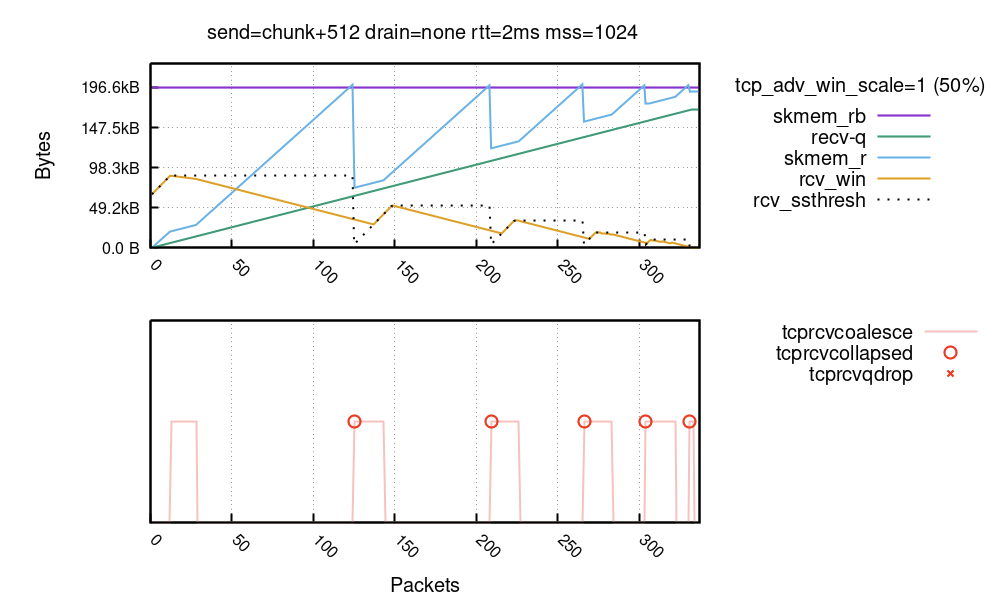
Over the years I've been lurking around the Linux kernel and have investigated the TCP code many times. But when recently we were working on Optimizing TCP for high WAN throughput while preserving low latency, I realized I have gaps in my knowledge about how Linux manages TCP receive buffers and windows. As I dug deeper I found the subject complex and certainly non-obvious.
In this blog post I'll share my journey deep into the Linux networking stack, trying to understand the memory and window management of the receiving side of a TCP connection. Specifically, looking for answers to seemingly trivial questions:
Our exploration focuses on the receiving side of the TCP connection. We'll try to understand how to tune it for the best speed, without wasting precious memory.
To best illustrate the receive side buffer management we need pretty charts! But to grasp all the numbers, we need a bit of theory.
We'll draw charts from a receive side of a TCP flow, Continue reading
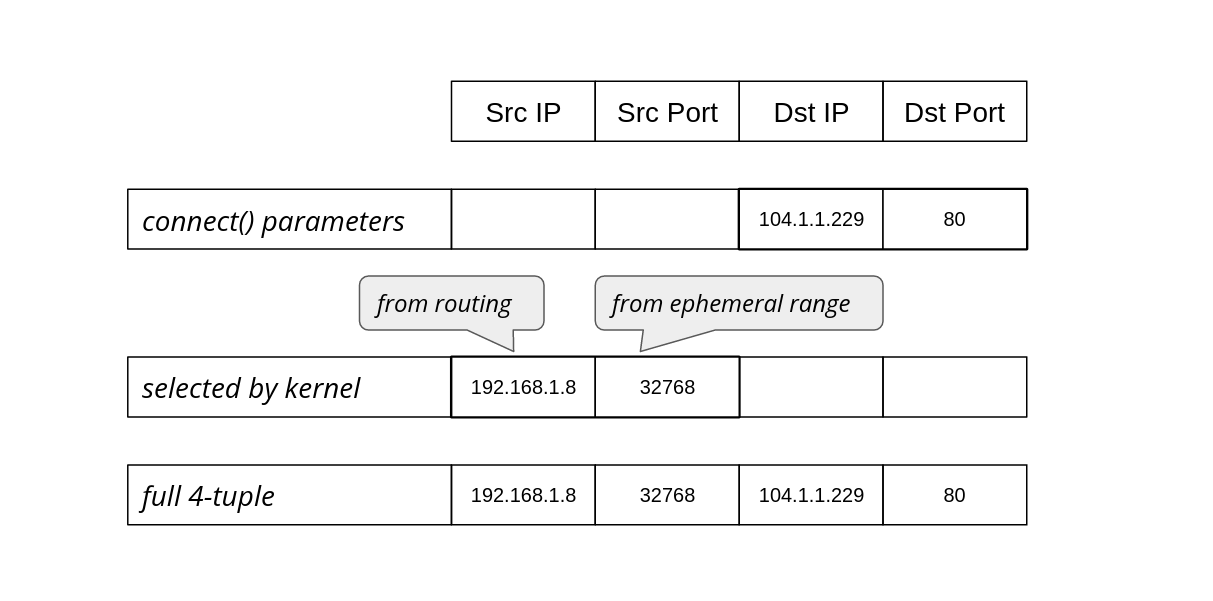
Often programmers have assumptions that turn out, to their surprise, to be invalid. From my experience this happens a lot. Every API, technology or system can be abused beyond its limits and break in a miserable way.
It's particularly interesting when basic things used everywhere fail. Recently we've reached such a breaking point in a ubiquitous part of Linux networking: establishing a network connection using the connect() system call.
Since we are not doing anything special, just establishing TCP and UDP connections, how could anything go wrong? Here's one example: we noticed alerts from a misbehaving server, logged in to check it out and saw:
marek@:~# ssh 127.0.0.1
ssh: connect to host 127.0.0.1 port 22: Cannot assign requested address
You can imagine the face of my colleague who saw that. SSH to localhost refuses to work, while she was already using SSH to connect to that server! On another occasion:
marek@:~# dig cloudflare.com @1.1.1.1
dig: isc_socket_bind: address in use
This time a basic DNS query failed with a weird networking error. Failing DNS is a bad sign!
In both cases the problem was Linux running out of ephemeral ports. When Continue reading
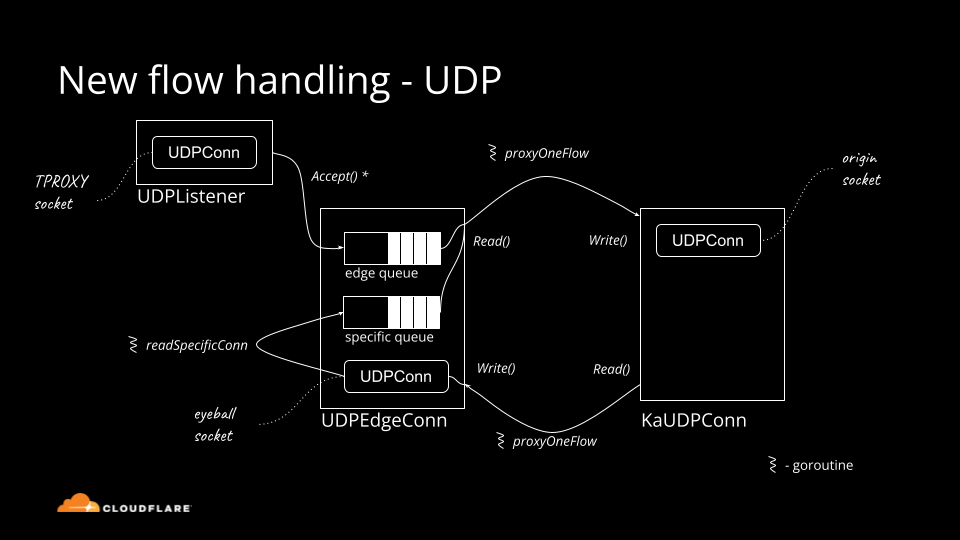
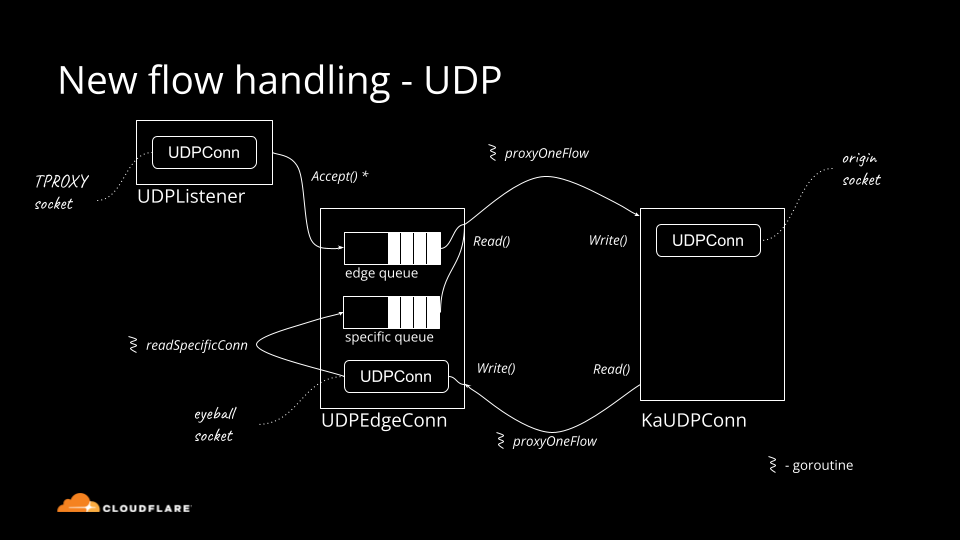
Historically Cloudflare's core competency was operating an HTTP reverse proxy. We've spent significant effort optimizing traditional HTTP/1.1 and HTTP/2 servers running on top of TCP. Recently though, we started operating big scale stateful UDP services.
Stateful UDP gains popularity for a number of reasons:
— QUIC is a new transport protocol based on UDP, it powers HTTP/3. We see the adoption accelerating.
— We operate WARP — our Wireguard protocol based tunneling service — which uses UDP under the hood.
— We have a lot of generic UDP traffic going through our Spectrum service.
Although UDP is simple in principle, there is a lot of domain knowledge needed to run things at scale. In this blog post we'll cover the basics: all you need to know about UDP servers to get started.
How do you "accept" connections on a UDP server? If you are using unconnected sockets, you generally don't.
But let's start with the basics. UDP sockets can be "connected" (or "established") or "unconnected". Connected sockets have a full 4-tuple associated {source ip, source port, destination ip, destination port}, unconnected Continue reading
Some time ago I was looking at a hot section in our code and I saw this:
if (debug) {
log("...");
}
This got me thinking. This code is in a performance critical loop and it looks like a waste - we never run with the "debug" flag enabled[1]. Is it ok to have if clauses that will basically never be run? Surely, there must be some performance cost to that...
if statements?Back in the days the general rule was: a fully predictable branch has close to zero CPU cost.
To what extent is this true? If one branch is fine, then how about ten? A hundred? A thousand? When does adding one more if statement become a bad idea?
At some point the negligible cost of simple branch instructions surely adds up to a significant amount. As another example, a colleague of mine found this snippet in our production code:
const char *getCountry(int cc) {
if(cc == 1) return "A1";
if(cc == 2) return "A2";
if(cc == 3) return "O1";
if(cc == 4) return "AD";
if(cc == 5) return "AE";
if(cc == 6) return "AF";
Continue reading
Late last year I read a blog post about our CSAM image scanning tool. I remember thinking: this is so cool! Image processing is always hard, and deploying a real image identification system at Cloudflare is no small achievement!
Some time later, I was chatting with Kornel: "We have all the pieces in the image processing pipeline, but we are struggling with the performance of one component." Scaling to Cloudflare needs ain't easy!
The problem was in the speed of the matching algorithm itself. Let me elaborate. As John explained in his blog post, the image matching algorithm creates a fuzzy hash from a processed image. The hash is exactly 144 bytes long. For example, it might look like this:
00e308346a494a188e1043333147267a 653a16b94c33417c12b433095c318012
5612442030d14a4ce82c623f4e224733 1dd84436734e4a5d6e25332e507a8218
6e3b89174e30372d
The hash is designed to be used in a fuzzy matching algorithm that can find "nearby", related images. The specific algorithm is well defined, but making it fast is left to the programmer — and at Cloudflare we need the matching to be done super fast. We want to match thousands of hashes per second, of images passing through our network, against a database of millions of known images. To make this work, Continue reading


Another long night. I was working on my perfect, bug-free program in C, when the predictable thing happened:
$ clang skynet.c -o skynet
$ ./skynet.out
Segmentation fault (core dumped)
Oh, well... Maybe I'll be more lucky taking over the world another night. But then it struck me. My program received a SIGSEGV signal and crashed with "Segmentation Fault" message. Where does the "V" come from?
Did I read it wrong? Was there a "Segmentation Vault?"? Or did Linux authors make a mistake? Shouldn't the signal be named SIGSEGF?
I asked my colleagues and David Wragg quickly told me that the signal name stands for "Segmentation Violation". I guess that makes sense. Long long time ago, computers used to have memory segmentation. Each memory segment had defined length - called Segment Limit. Accessing data over this limit caused a processor fault. This error code got re-used by newer systems that used paging. I think the Intel manuals call this error "Invalid Page Fault". When it's triggered it gets reported to the userspace as a SIGSEGV signal. End of story.
Or is it?
Martin Levy pointed me to an ancient Version 6th UNIX documentation on "signal". This is Continue reading
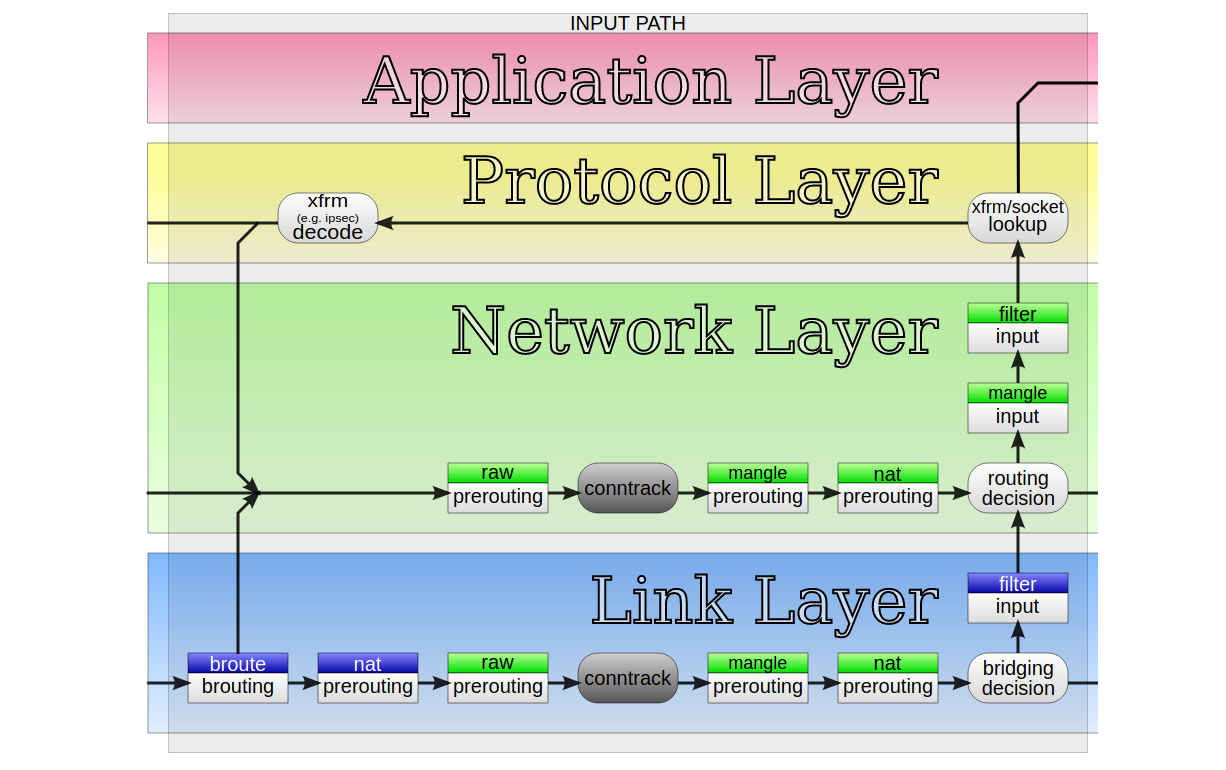
At Cloudflare we develop new products at a great pace. Their needs often challenge the architectural assumptions we made in the past. For example, years ago we decided to avoid using Linux's "conntrack" - stateful firewall facility. This brought great benefits - it simplified our iptables firewall setup, sped up the system a bit and made the inbound packet path easier to understand.
But eventually our needs changed. One of our new products had a reasonable need for it. But we weren't confident - can we just enable conntrack and move on? How does it actually work? I volunteered to help the team understand the dark corners of the "conntrack" subsystem.
"Conntrack" is a part of Linux network stack, specifically part of the firewall subsystem. To put that into perspective: early firewalls were entirely stateless. They could express only basic logic, like: allow SYN packets to port 80 and 443, and block everything else.
The stateless design gave some basic network security, but was quickly deemed insufficient. You see, there are certain things that can't be expressed in a stateless way. The canonical example is assessment of ACK packets - it's impossible to say if an ACK Continue reading
I've known about Bloom filters (named after Burton Bloom) since university, but I haven't had an opportunity to use them in anger. Last month this changed - I became fascinated with the promise of this data structure, but I quickly realized it had some drawbacks. This blog post is the tale of my brief love affair with Bloom filters.
While doing research about IP spoofing, I needed to examine whether the source IP addresses extracted from packets reaching our servers were legitimate, depending on the geographical location of our data centers. For example, source IPs belonging to a legitimate Italian ISP should not arrive in a Brazilian datacenter. This problem might sound simple, but in the ever-evolving landscape of the internet this is far from easy. Suffice it to say I ended up with many large text files with data like this:

This reads as: the IP 192.0.2.1 was recorded reaching Cloudflare data center number 107 with a legitimate request. This data came from many sources, including our active and passive probes, logs of certain domains we own (like cloudflare.com), public sources (like BGP table), etc. The same line would usually be repeated across multiple Continue reading
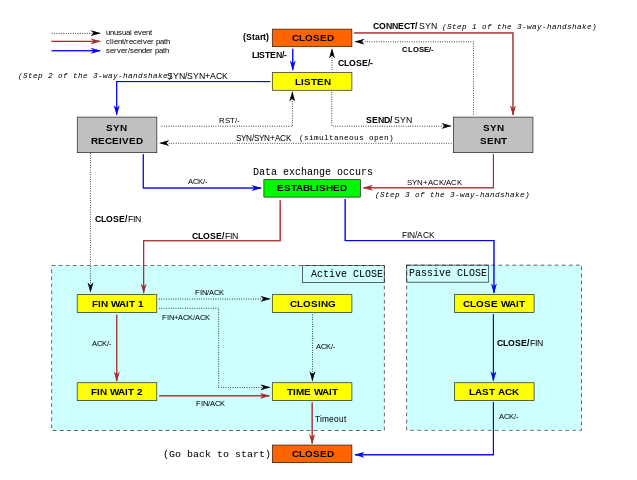
While working on our Spectrum server, we noticed something weird: the TCP sockets which we thought should have been closed were lingering around. We realized we don't really understand when TCP sockets are supposed to time out!
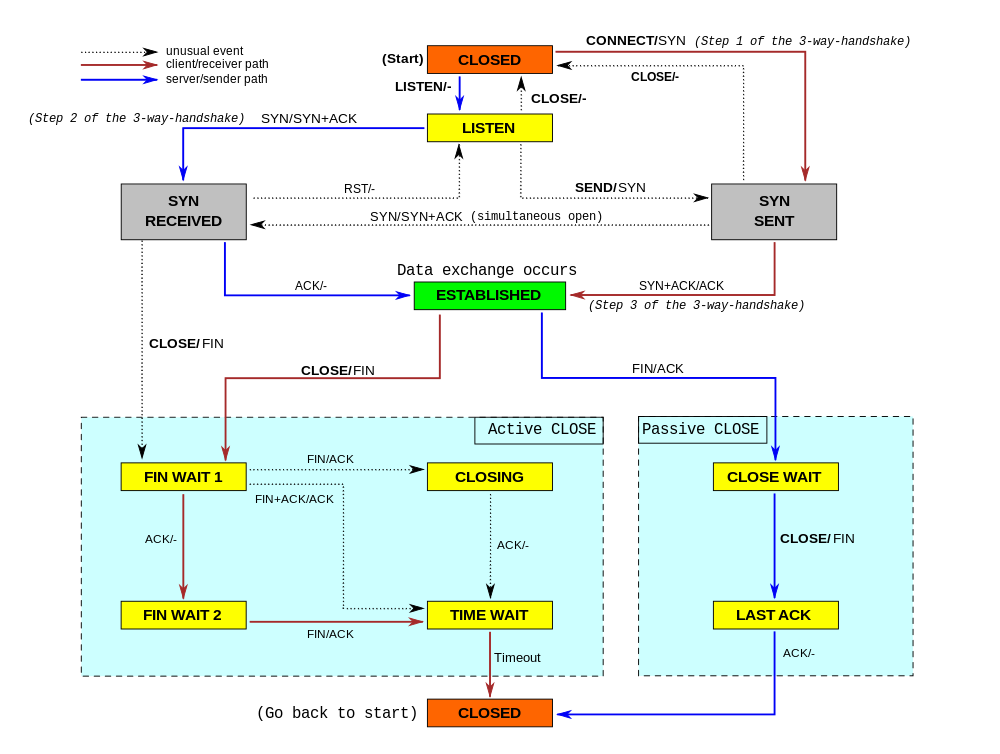
In our code, we wanted to make sure we don't hold connections to dead hosts. In our early code we naively thought enabling TCP keepalives would be enough... but it isn't. It turns out a fairly modern TCP_USER_TIMEOUT socket option is equally as important. Furthermore it interacts with TCP keepalives in subtle ways. Many people are confused by this.
In this blog post, we'll try to show how these options work. We'll show how a TCP socket can timeout during various stages of its lifetime, and how TCP keepalives and user timeout influence that. To better illustrate the internals of TCP connections, we'll mix the outputs of the tcpdump and the ss -o commands. This nicely shows the transmitted packets and the changing parameters of the TCP connections.
Let's start from the simplest case - what happens when one attempts to establish a connection to a server which discards inbound SYN packets?
$ Continue reading
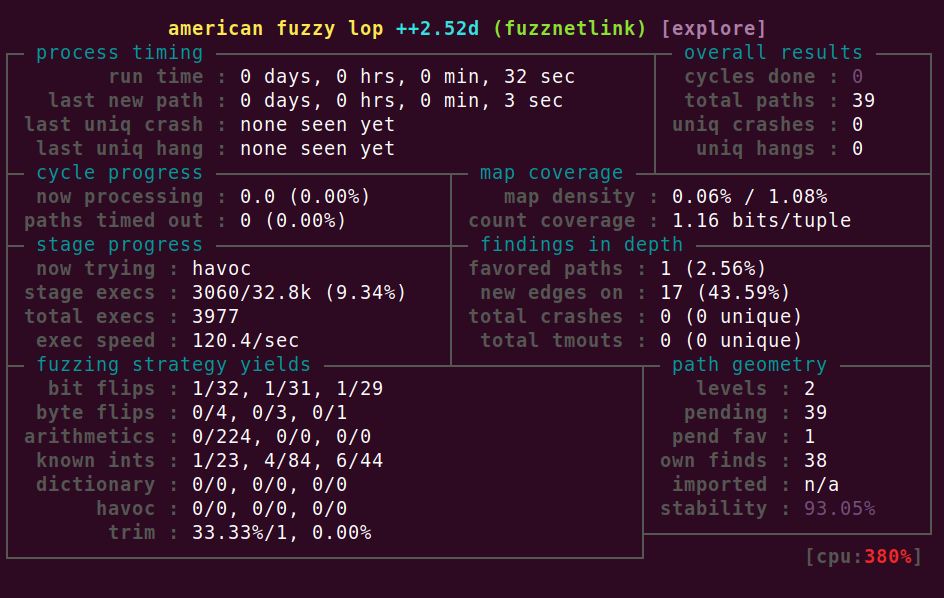
For some time I’ve wanted to play with coverage-guided fuzzing. Fuzzing is a powerful testing technique where an automated program feeds semi-random inputs to a tested program. The intention is to find such inputs that trigger bugs. Fuzzing is especially useful in finding memory corruption bugs in C or C++ programs.

Normally it's recommended to pick a well known, but little explored, library that is heavy on parsing. Historically things like libjpeg, libpng and libyaml were perfect targets. Nowadays it's harder to find a good target - everything seems to have been fuzzed to death already. That's a good thing! I guess the software is getting better! Instead of choosing a userspace target I decided to have a go at the Linux Kernel netlink machinery.
Netlink is an internal Linux facility used by tools like "ss", "ip", "netstat". It's used for low level networking tasks - configuring network interfaces, IP addresses, routing tables and such. It's a good target: it's an obscure part of kernel, and it's relatively easy to automatically craft valid messages. Most importantly, we can learn a lot about Linux internals in the process. Bugs in netlink aren't going Continue reading
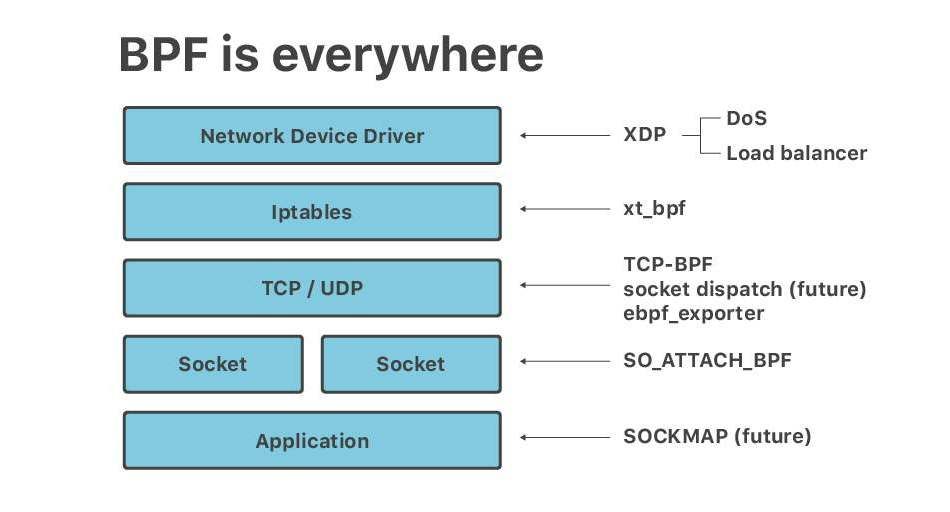
Recently at Netdev 0x13, the Conference on Linux Networking in Prague, I gave a short talk titled "Linux at Cloudflare". The talk ended up being mostly about BPF. It seems, no matter the question - BPF is the answer.
Here is a transcript of a slightly adjusted version of that talk.
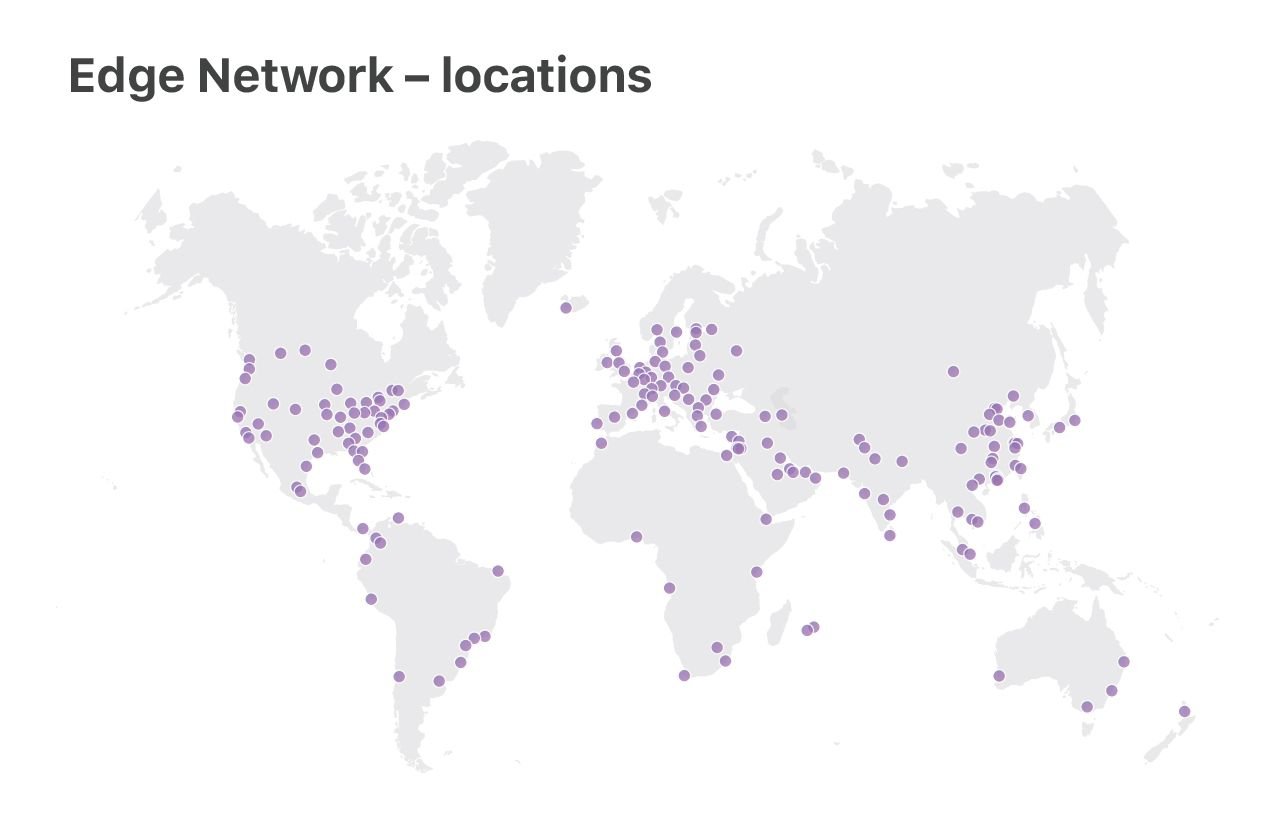
At Cloudflare we run Linux on our servers. We operate two categories of data centers: large "Core" data centers, processing logs, analyzing attacks, computing analytics, and the "Edge" server fleet, delivering customer content from 180 locations across the world.
In this talk, we will focus on the "Edge" servers. It's here where we use the newest Linux features, optimize for performance and care deeply about DoS resilience.
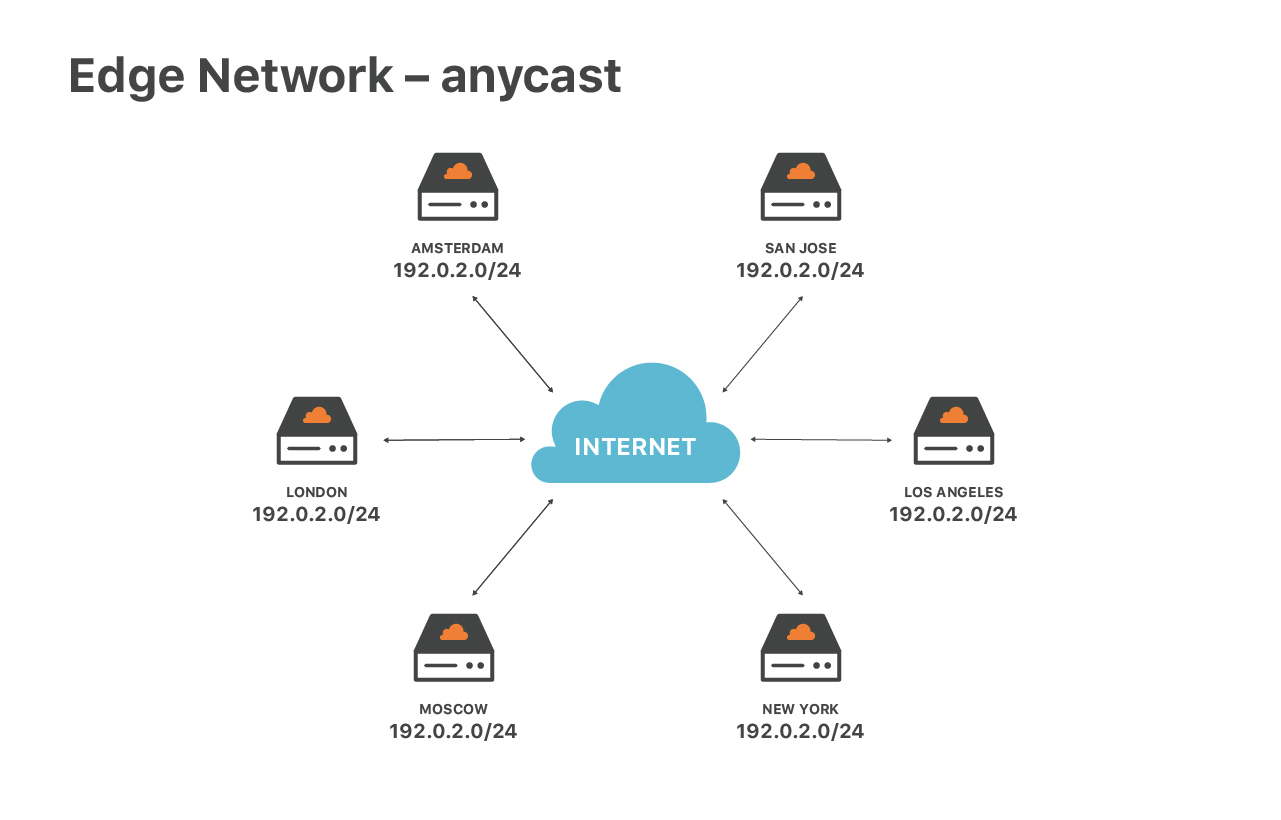
Our edge service is special due to our network configuration - we are extensively using anycast routing. Anycast means that the same set of IP addresses are announced by all our data centers.
This design has great advantages. First, it guarantees the optimal speed for end users. No matter where you are located, you will always reach the closest data center. Then, anycast helps us to spread out DoS traffic. During attacks each of the locations receives a small fraction of Continue reading
Ladies and gentlemen, I would like you to welcome the new shiny RFC8482, which effectively deprecates the DNS ANY query type. DNS ANY was a "meta-query" - think of it as a similar thing to the common A, AAAA, MX or SRV query types, but unlike these it wasn't a real query type - it was special. Unlike the standard query types, ANY didn't age well. It was hard to implement on modern DNS servers, the semantics were poorly understood by the community and it unnecessarily exposed the DNS protocol to abuse. RFC8482 allows us to clean it up - it's a good thing.
But let's rewind a bit.
It all started in 2015, when we were looking at the code of our authoritative DNS server. The code flow was generally fine, but it was all peppered with naughty statements like this:
if qtype == "ANY" {
// special case
}
This special code was ugly and error prone. This got us thinking: do we really need it? "ANY" is not a popular query type - no legitimate software uses it (with the notable exception of qmail).


Recently we stumbled upon the holy grail for reverse proxies - a TCP socket splicing API. This caught our attention because, as you may know, we run a global network of reverse proxy services. Proper TCP socket splicing reduces the load on userspace processes and enables more efficient data forwarding. We realized that Linux Kernel's SOCKMAP infrastructure can be reused for this purpose. SOCKMAP is a very promising API and is likely to cause a tectonic shift in the architecture of data-heavy applications like software proxies.

But let’s rewind a bit.
Transmitting large amounts of data from userspace is inefficient. Linux provides a couple of specialized syscalls that aim to address this problem. For example, the sendfile(2) syscall (which Linus doesn't like) can be used to speed up transferring large files from disk to a socket. Then there is splice(2) which traditional proxies use to forward data between two TCP sockets. Finally, vmsplice can be used to stick memory buffer into a pipe without copying, but is very hard to use correctly.
Sadly, sendfile, splice and vmsplice are very specialized, synchronous and solve only one part Continue reading

My curiosity was piqued by an LWN article about IOCB_CMD_POLL - A new kernel polling interface. It discusses an addition of a new polling mechanism to Linux AIO API, which was merged in 4.18 kernel. The whole idea is rather intriguing. The author of the patch is proposing to use the Linux AIO API with things like network sockets.
Hold on. The Linux AIO is designed for, well, Asynchronous disk IO! Disk files are not the same thing as network sockets! Is it even possible to use the Linux AIO API with network sockets in the first place?
The answer turns out to be a strong YES! In this article I'll explain how to use the strengths of Linux AIO API to write better and faster network servers.
But before we start, what is Linux AIO anyway?

Linux AIO exposes asynchronous disk IO to userspace software.
Historically on Linux, all disk operations were blocking. Whether you did open(), read(), write() or fsync(), you could be sure your thread would stall if the needed data and meta-data was not ready in disk cache. This usually isn't Continue reading
{kind=link}