Ultra Ethernet: Receiver Credit-based Congestion Control (RCCC)
Introduction
Receiver Credit-Based Congestion Control (RCCC) is a cornerstone of the Ultra Ethernet transport architecture, specifically designed to eliminate incast congestion. Incast occurs at the last-hop switch when the aggregate data rate from multiple senders exceeds the egress interface capacity of the target’s link. This mismatch leads to rapid buffer exhaustion on the outgoing interface, resulting in packet drops and severe performance degradation.
The RCCC Mechanism
Figure 8-1 illustrates the operational flow of the RCCC algorithm. In a standard scenario without credit limits, source Rank 0 and Rank 1 might attempt to transmit at their full 100G line rates simultaneously. If the backbone fabric consists of 400G inter-switch links, the core utilization remains a comfortable 50% (200G total traffic). However, because the target host link is only 100G, the last-hop switch (Leaf 1B-1) becomes an immediate bottleneck. The switch is forced to queue packets that cannot be forwarded at the 100G egress rate, eventually triggering incast congestion and buffer overflows.
While "incast" occurs at the egress interface and can resemble head-of-line blocking, it is fundamentally a "fan-in" problem where multiple sources converge on a single receiver. Under RCCC, standard Explicit Congestion Notification (ECN) on the last-hop switch's egress interface is Continue reading
On MPLS Forwarding Performance Myths
Whenever I claim that the initial use case for MPLS was improved forwarding performance (using the RFC that matches the IETF MPLS BoF slides as supporting evidence), someone inevitably comes up with a source claiming something along these lines:
The idea of speeding up the lookup operation on an IP datagram turned out to have little practical impact.
That might be true1, although I do remember how hard it was for Cisco to build the first IP forwarding hardware in the AGS+ CBUS controller. Switching labels would be much faster (or at least cheaper), but the time it takes to do a forwarding table lookup was never the main consideration. It was all about the aggregate forwarding performance of core devices.
Anyhow, Duty Calls. It’s time for another archeology dig. Unfortunately, most of the primary sources irrecoverably went to /dev/null, and personal memories are never reliable; comments are most welcome.
D2DO293: Haskell in the Modern Day
Ned and Kyler sit down with Tikhon Jelvis to discuss Haskell and other niche programming languages. They explore how this decades-old language isn’t just surviving, but thriving. They also break down how Haskell can provide distinct advantages over traditional programming, especially for complex domain modeling and concurrent applications. Episode Links: Copilot Language Haskell Project Haskell... Read more »OMG, After a Decade, VXLAN Is Still Insecure
In 2017 (over eight years ago), I was making fun of the fact that “VXLAN is insecure” was news to some people. Obviously, the message needed to be repeated, as the same author gave a very similar presentation two years later at a security conference.
Unfortunately, it seems that everything old is new again (see also RFC 1925 rules 4 and 11), as proved by a “Using GRE and VXLAN for Fun and Profit” (my summary) presentation at DEFCON 33. Even if you knew that unencrypted tunnels are insecure (duh!) for decades, you might still want to read the summary of the talk (published on APNIC blog) and view the slides.
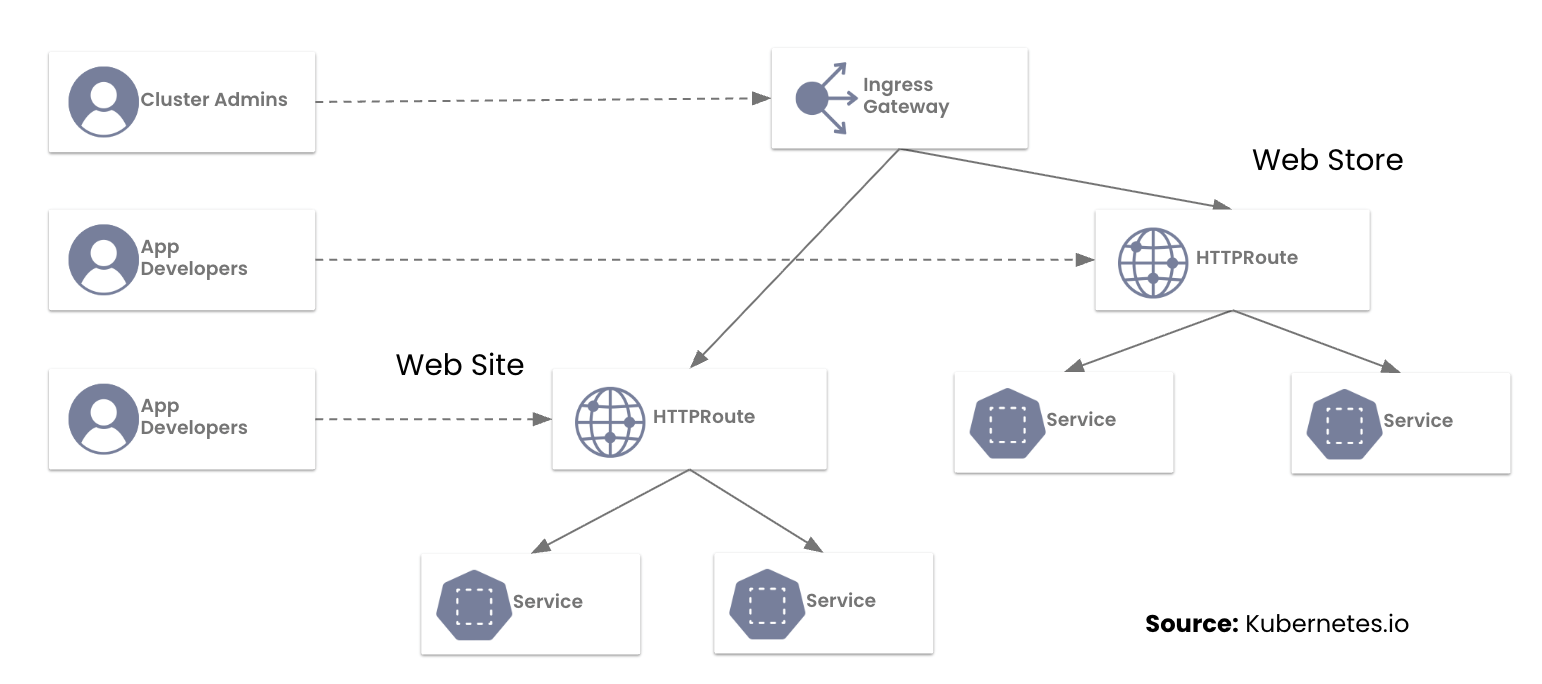
Calico Ingress Gateway: Key FAQs Before Migrating from NGINX Ingress Controller
What Platform Teams Need to Know Before Moving to Gateway API
We recently sat down with representatives from 42 companies to discuss a pivotal moment in Kubernetes networking: the NGINX Ingress retirement.
With the March 2026 retirement of the NGINX Ingress Controller fast approaching, platform teams are now facing a hard deadline to modernize their ingress strategy. This urgency was reflected in our recent workshop, “Switching from NGINX Ingress Controller to Calico Ingress Gateway” which saw an overwhelming turnout, with engineers representing a cross-section of the industry, from financial services to high-growth tech startups.
During the session, the Tigera team highlighted a hard truth for platform teams: the original Ingress API was designed for a simpler era. Today, teams are struggling to manage production traffic through “annotation sprawl”—a web of brittle, implementation-specific hacks that make multi-tenancy and consistent security an operational nightmare.
The move to the Kubernetes Gateway API isn’t just a mandatory update; it’s a graduation to a role-oriented, expressive networking model. We’ve previously explored this shift in our blogs on Understanding the NGINX Retirement and Why the Ingress NGINX Controller is Dead.
PP095: OT and ICS – Where Digital and Physical Risks Meet
Operation Technology (OT) and Industrial Control Systems (ICS) are where the digital world meets the physical world. These systems, which are critical to the operation of nuclear power plants, manufacturing sites, municipal power and water plants, and more, are under increasing attack. On today’s Packet Protector we return to the OT/ICS realm to talk about... Read more »HW070: Better Understand Your Network Performance with NetViews
Every Wi-fi or network professional occasionally struggles with understanding what their endpoints are experiencing. Keith sits down with Bill Bushong, creator of NetViews, a macOS application originally called PingStalker. In this conversation they discuss why he built NetViews, the technical details on how it works, its network monitoring capabilities, and how Wi-Fi professionals can use... Read more »Improve global upload performance with R2 Local Uploads
Today, we are launching Local Uploads for R2 in open beta. With Local Uploads enabled, object data is automatically written to a storage location close to the client first, then asynchronously copied to where the bucket lives. The data is immediately accessible and stays strongly consistent. Uploads get faster, and data feels global.
For many applications, performance needs to be global. Users uploading media content from different regions, for example, or devices sending logs and telemetry from all around the world. But your data has to live somewhere, and that means uploads from far away have to travel the full distance to reach your bucket.
R2 is object storage built on Cloudflare's global network. Out of the box, it automatically caches object data globally for fast reads anywhere — all while retaining strong consistency and zero egress fees. This happens behind the scenes whether you're using the S3 API, Workers Bindings, or plain HTTP. And now with Local Uploads, both reads and writes can be fast from anywhere in the world.
Try it yourself in this demo to see the benefits of Local Uploads.
Ready to try it? Enable Local Uploads in the Cloudflare Dashboard under your bucket's settings, or Continue reading
Interface MAC Address in IOS Layer-2 Images
Here’s another “You can’t make this up, but it sounds too crazy to be true” story: Cisco IOS layer-2 images change the interface MAC address when you change the interface switchport status.
Let me start with a bit of background:
- IOL Layer 2 image starts with interfaces enabled and in bridged (switchport) mode (details)
- netlab has to run a normalize script (applicable to IOLL2, IOSv L2, and Arista EOS) before configuring anything else to ensure all interfaces are shut down.
- The IOLL2
normalizeJinja template had a bug – when setting the interface MAC address, it checkedl.mac_addressinstead ofintf.mac_address. Nevertheless, everything worked because the MAC addresses were also set during the initial device configuration.
NB560: Microsoft Doubles Down on Custom AI Chip; CrowdStrike Brandishes Big Bucks for Browser Security
Take a Network Break! We’ve got Red Alerts for HPE Juniper Session Smart Routers and SolarWinds. In this week’s news, Microsoft debuts its second-generation AI inferencing chip, Mplify rolls out a new Carrier Ethernet certification for supporting AI workloads, and AWS upgrades its network firewall to spot GenAI application traffic and filter Web categories. Google... Read more »Teaching Your AI Assistant to See – Extending RAG with Image Understanding
In the previous article, we built a RAG-powered AI assistant that can answer questions from your personal Obsidian notes. It works great for text – but what about all those … Read MoreHow to create AI generated song for Youtube
Artificial intelligence can do more than just code or write, it can also create music. […]
The post How to create AI generated song for Youtube first appeared on Brezular's Blog.
Fast FRR Container Configuration
After creating the infrastructure that generates the device configuration files within netlab (not in an Ansible playbook), it was time to try to apply it to something else, not just Linux containers. FRR containers were the obvious next target.
netlab uses two different mechanisms to configure FRR containers:
- Data-plane features are configured with bash scripts using ip commands and friends.
- Control-plane features are configured with FRR’s vtysh
I wanted to replace both with Linux scripts that could be started with the docker exec command.
Open-source network simulators and emulators in 2026
In this annual update of my list of open-source network simulators and emulators, I check each project’s development activity, verify the well-maintained projects, identify new projects that deserve attention, and consider projects that may be fading away.
Top Projects
Two open-source network emulation projects stand out in 2026, due to their popularity, functionality, and development velocity.
Containerlab continues its impressive development pace, and seems to have cemented its position as a leading network emulation tool for developers. New features added in 2024 and 2025 include VM snapshot/restore functionality, expanded device support, a system for running labs on Kubernetes clusters, and improved container network configuration.
GNS3 continues steady development and remains a leading network emulation tool for engineers. While the 2.x release is still the default download, the GNS3 team released a 3.0 version that implemented major architectural changes in GNS3. GNS3 continues to be the most popular GUI-based open-source network emulator.
Maintained Projects
Many other open-source network simulation and emulation projects continue to be well maintained in 2026 and may be used with confidence. Each project’s documentation is usable, the developers are responsive to issues and contributions, and the user community is engaged.
ns-3 continues to be the Continue reading
Making AI accessing your personal work notes using RAG mechanism to be your work assistant
Have you ever wished ChatGPT could answer questions about YOUR personal notes? Like “What are my lab credentials?” or “Who do I contact for hardware purchases?” – things only you … Read MoreUltra Ethernet: NSCC Destination Flow Control
Figure 6-14 depicts a demonstrative event where Rank 4 receives seven simultaneous flows (1). As these flows are processed by their respective PDCs and handed over to the Semantic Sublayer (2), the High-Bandwidth Memory (HBM) Controller becomes congested. Because HBM must arbitrate multiple fi_write RMA operations requiring concurrent memory bank access and state updates, the incoming packet rate quickly exceeds HBM’s transactional retirement rate.
This causes internal buffers at the memory interface to fill, creating a local congestion event (3). To prevent buffer overflow, which would lead to dropped packets and expensive RMA retries, the receiver utilizes NSCC to move the queuing "pain" back to the source. This is achieved by using pds.rcv_cwnd_pend parameter of the ACK_CC header (4). The parameter operates on a scale of 0 to 127; while zero is ignored, a value of 127 triggers the maximum possible rate decrement. In this scenario, a value of 64 is utilized, resulting in a 50% penalty relative to the newly acknowledged data.
Rather than directly computing a new transport rate, the mechanism utilizes a three-phase process to define a restricted Congestion Window (CWND). This reduction in CWND inherently forces the source to drain its inflight bucket to Continue reading
Introducing the New Tigera & Calico Brand
Same community. A clearer, more unified look.
Today, we are excited to share a refresh of the Tigera and Calico visual identity!
This update better reflects who we are, who we serve, and where we are headed next.

If you have been part of the Calico community for a while, you know that change at Tigera is always driven by substance, not style alone. Since the early days of Project Calico, our focus has always been clear: Build powerful, scalable networking and security for Kubernetes, and do it in the open with the community.
Built for the Future, With the Community
Tigera was founded by the original Project Calico engineering team and remains deeply committed to maintaining Calico Open Source as the leading standard for container networking and network security.
“Tigera’s story began in 2016 with Project Calico, an open-source container networking and security project. Calico Open Source has since become the most widely adopted solution for containers and Kubernetes. We remain committed to maintaining Calico Open Source as the leading standard, while also delivering advanced capabilities through our commercial editions.”
—Ratan Tipirneni, President & CEO, Tigera
A Visual Evolution
This refresh is an evolution, not a reinvention. You Continue reading
TNO054: AI Skills for CCIEs
Let’s talk about AI for NetOps: It’s not just coming, it’s here. There are tools to use, skills to acquire, and we want to talk about what’s needed for highly certified network engineers to skill up in AI. What certification opportunities or paths exist? What developments do we think we’re going to see here? And... Read more »Google’s AI advantage: why crawler separation is the only path to a fair Internet
Earlier this week, the UK’s Competition and Markets Authority (CMA) opened its consultation on a package of proposed conduct requirements for Google. The consultation invites comments on the proposed requirements before the CMA imposes any final measures. These new rules aim to address the lack of choice and transparency that publishers (broadly defined as “any party that makes content available on the web”) face over how Google uses search to fuel its generative AI services and features. These are the first consultations on conduct requirements launched under the digital markets competition regime in the UK.
We welcome the CMA’s recognition that publishers need a fairer deal and believe the proposed rules are a step into the right direction. Publishers should be entitled to have access to tools that enable them to control the inclusion of their content in generative AI services, and AI companies should have a level playing field on which to compete.
But we believe the CMA has not gone far enough and should do more to safeguard the UK’s creative sector and foster healthy competition in the market for generative and agentic AI.
In January Continue reading