Human Generated Questions About AI Assistants

I’ve taken a number of briefings in the last few months that all mention how companies are starting to get into AI by building an AI virtual assistant. In theory this is the easiest entry point into the technology. Your network already has a ton of information about usage patterns and trouble spots. Network operations and engineering teams have learned over the years to read that information and provide analysis and feedback.
If marketing is to be believed, no one in the modern world has time to learn how to read all that data. Instead, AI provides a natural language way to ask simple questions and have the system provide the data back to you with proper context. It will highlight areas of concern and help you grasp what’s going on. Only you don’t need to get a CCNA to get there. Or, more likely, it’s more useful for someone on the executive team to ask questions and get answers without the need to talk to the network team.
I have some questions that I always like to ask when companies start telling me about their new AI assistant that help me understand how it’s being built.
Question 1: Laying Continue reading
Ansible Set Operations Do Not Preserve List Order
Here’s another Ansible quirk, this time caused by Python set behavior.
When I created the initial device configuration deployment playbook in netlab, I wanted to:
- Be able to specify a list of modules to provision.1
- Provision just the modules used in the topology and specified in the list of modules.
This allows you to use netlab initial to deploy all configuration modules used in a lab topology or netlab initial -m ospf to deploy just OSPF while surviving netlab initial -m foo (which would do nothing).
Ansible Set Operations Do Not Preserve List Order
Here’s another Ansible quirk, this time caused by Python set behavior.
When I created the initial device configuration deployment playbook in netlab, I wanted to:
- Be able to specify a list of modules to provision.1
- Provision just the modules used in the topology and specified in the list of modules.
This allows you to use netlab initial to deploy all configuration modules used in a lab topology or netlab initial -m ospf to deploy just OSPF while surviving netlab initial -m foo (which would do nothing).
Bridging Packet Walk In VXLAN/EVPN Network
In this post I walk you through all the steps and packets involved in two hosts communicating over a L2 VNI in a VXLAN/EVPN network. The topology below is the one we will be using:
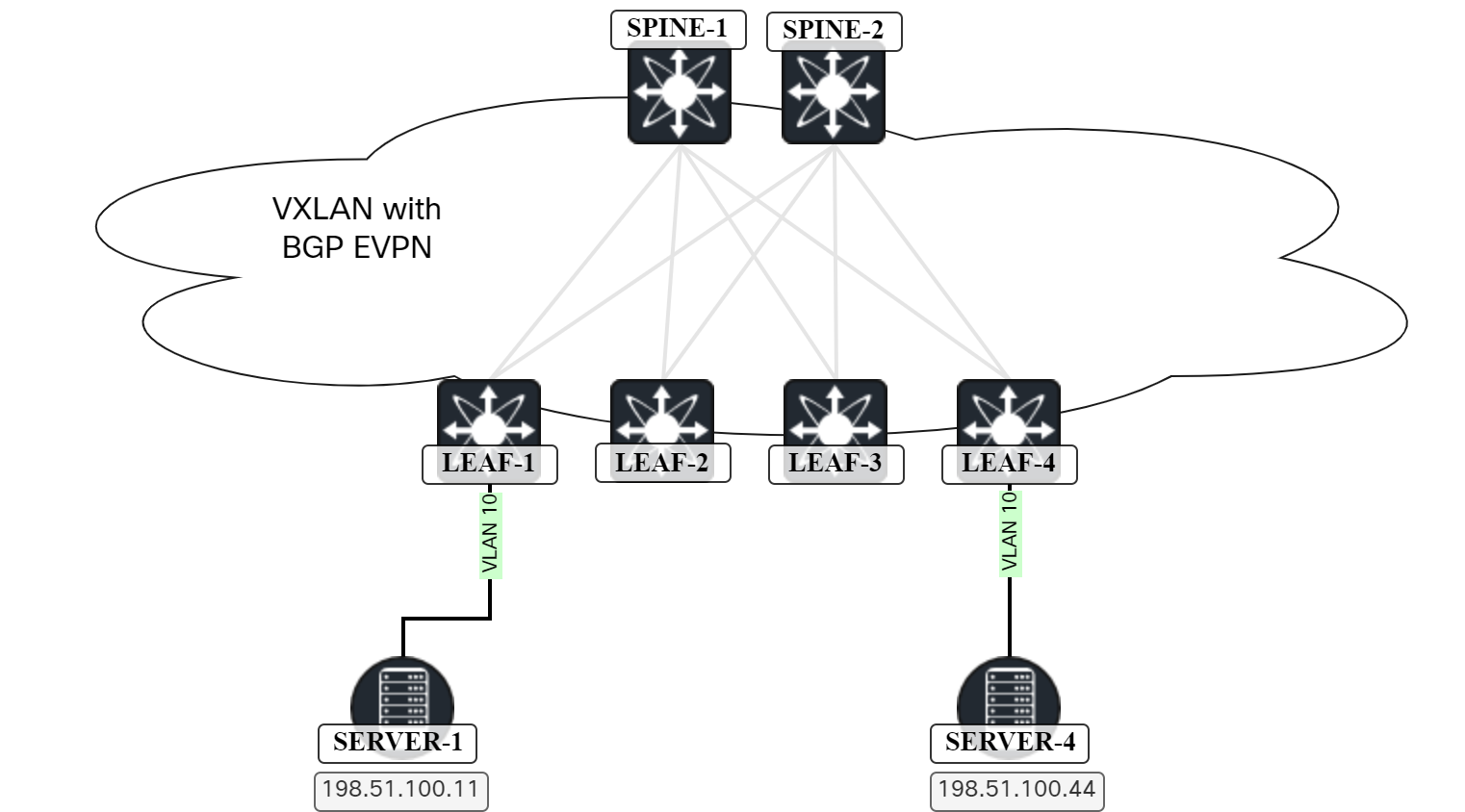
The lab has the following characteristics:
- OSPF in the underlay.
- Ingress replication for BUM traffic through the use of EVPN.
- ARP suppression is enabled.
- ARP cache is cleared on Server-1 and Server-4 before initating the packet capture.
- Server-1 is the host sourcing traffic by pinging Server-4.
Server-1 clears the ARP entry for Server-4 and initiates the ping:
sudo ip neighbor del 198.51.100.44 dev ens160 ping 198.51.100.44 PING 198.51.100.44 (198.51.100.44) 56(84) bytes of data. 64 bytes from 198.51.100.44: icmp_seq=1 ttl=64 time=6.38 ms 64 bytes from 198.51.100.44: icmp_seq=2 ttl=64 time=4.56 ms 64 bytes from 198.51.100.44: icmp_seq=3 ttl=64 time=4.60 ms
Below is packet capture showing the ARP request from Server-1:
Frame 7854: 60 bytes on wire (480 bits), 60 bytes captured (480 bits) on interface ens257, id 4
Ethernet II, Src: 00:50:56:ad:85:06, Dst: ff:ff:ff:ff:ff:ff
Address Resolution Protocol (request)
Hardware type: Ethernet (1)
Protocol type: Continue reading
DNS and Truncation in UDP
I’ll press on with another item within an overall theme of some current work in DNS behaviours with a report of a recent measurement on the level of compliance of DNS resolvers with one aspect of standard-defined DNS behaviour: truncation of DNS over UDP responses.DNS and Truncation in UDP
I’ll press on with another item within an overall theme of some current work in DNS behaviours with a report of a recent measurement on the level of compliance of DNS resolvers with one aspect of standard-defined DNS behaviour: truncation of DNS over UDP responses.Boat build phase – part2
You can only live for so long on laughing cow, pot noodles, soup and beans on toast, the boat diet is good for losing weight but not for your wellbeing. I got lucky with the weather as winter was pretty mild up until late October but when it turned you certainly did feel the cold on the boat. You would have to be crazy to try and survive on a boat in winter without a stove or some form of heating.
Why Businesses Should Watch Wi-Fi-7 Closely
Industry experts predict a rapid emergence for the latest Wi-Fi version. Streaming and dense device use cases are seen as fits.SuzieQ Network Observability

In today’s post, we’re exploring SuzieQ, an open-source network observability platform that’s making waves in the way we monitor and understand our networks. It supports a wide array of devices from top vendors like Arista, Cisco, and Juniper, among others. We’ll start with the fundamentals and finish with a practical example to clearly illustrate how SuzieQ sets itself apart from other automation tools.
What We Will Cover?
- What exactly is SuzieQ?
- How does SuzieQ work?
- How to install SuzieQ?
- SuzieQ terminology (Configuration, Inventory, suzieq-cli, poller)
- Configuration and Inventory files
- Examples using OSPF Topology
- Path Analysis
What Exactly is SuzieQ?
I first came across SuzieQ a while back but didn't dive deep into it because tools like Netmiko or Napalm were fitting my needs just fine. That changed when I tuned into a recent Packet Pushers podcast featuring Dinesh Dutt, the brain behind SuzieQ. Hearing him talk about it got me really interested.
After the podcast, I couldn't hold back from giving SuzieQ a try. There have been many times when I found myself writing custom scripts to get things done, only to discover that SuzieQ could have handled those tasks much more smoothly.
So, what is SuzieQ? In simple Continue reading
WEKA, NexGen Partner on a SuperCloud to Make AI More Sustainable
WEKA and NexGen are working to generate the GPU power to make AI workloads run more efficiently in the cloud.How do we overcome Imposter Syndrome?

I was thinking of writing about Imposter Syndrome for so long but I didn't because I thought someone might figure out I don't know what I am talking about.
This is so real, I'm not even kidding. The feeling of doubting your abilities and feeling like a fraud. It's something many of us experience, especially when we're stepping out of our comfort zones or tackling new challenges. So, I decided to face this head-on and share some ways to deal with it. First, it's important to recognize when we're being too hard on ourselves. We often set unrealistically high standards and then beat ourselves up when we don't meet them. It's okay to not know everything – after all, we're all learning as we go.
Talking to others can also be a big help. You'll often find that many people feel the same way and have their own experiences with Imposter Syndrome. This can be a huge relief to know you're not alone in this.
What Exactly is Imposter Syndrome?
In plain terms, it's when you feel like you're not as competent as others perceive you to be. You might think you're not good enough, despite there being clear signs Continue reading
HN722: Ivan Pepelnjak’s Netlab Eliminates the Tedious Bits of Labbing
One dark day, Ivan Pepelnjak stopped labbing. He just couldn’t make himself yet again go through assigning addresses, building links, putting devices in place, setting up OSPF, BGP, VXLAN, EVPN, etc. before even being able to start whatever simulation or test he wanted to do. But from that darkness arose netlab. Ivan created netlab to... Read more »Making IT Equipment Easier to Use With Gen AI: A Guide
Many network equipment vendors are incorporating Generative AI (Gen AI) technology into their offerings to make them easier to use, automate some routine tasks, and analyze patterns to make recommendations. Find out what is new and how to maximize efficiencies!HS066: The Holy Grail: A Functioning Tech Strategy
It’s rare for strategists, executives, and technologists to all get on the same page in order to create, execute, and adjust an organization’s tech strategy, much less do it well. But it is possible. Johna and Greg discuss their experiences of seeing through some consultants’ smoke and mirrors, honestly evaluating an organization’s capability to implement... Read more »Worth Reading: Popular git config options
Another must-explore gem by Julia Evans: Popular git config options.
Side note: I keep collecting links to insightful Git articles in the Git and GitHub section of the Network Automation Tools webinar.
Worth Reading: Popular git config options
Another must-explore gem by Julia Evans: Popular git config options.
Side note: I keep collecting links to insightful Git articles in the Git and GitHub section of the Network Automation Tools webinar.