Network flow monitoring is GA, providing end-to-end traffic visibility

Network engineers often find they need better visibility into their network’s traffic and operations while analyzing DDoS attacks or troubleshooting other traffic anomalies. These engineers typically have some high level metrics about their network traffic, but they struggle to collect essential information on the specific traffic flows that would clarify the issue. To solve this problem, Cloudflare has been piloting a cloud network flow monitoring product called Magic Network Monitoring that gives customers end-to-end visibility into all traffic across their network.
Today, Cloudflare is excited to announce that Magic Network Monitoring (previously called Flow Based Monitoring) is now generally available to all enterprise customers. Over the last year, the Cloudflare engineering team has significantly improved Magic Network Monitoring; we’re excited to offer a network services product that will help our customers identify threats faster, reduce vulnerabilities, and make their network more secure.
Magic Network Monitoring is automatically enabled for all Magic Transit and Magic WAN enterprise customers. The product is located at the account level of the Cloudflare dashboard and can be opened by navigating to “Analytics & Logs > Magic Monitoring”. The onboarding process for Magic Network Monitoring is self-serve, and all enterprise customers with access can begin Continue reading
BGP Labs: Build Larger Networks with IBGP
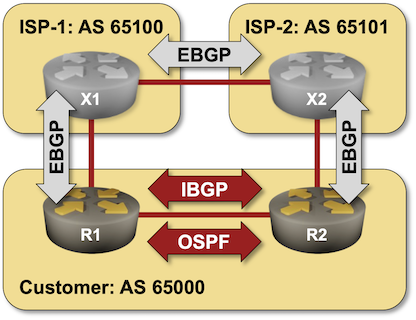
After going through the BGP basics, it’s time to build a network that has more than one BGP router in it, starting with the simplest possible topology: a site with two WAN edge routers.

BGP Labs: Build Larger Networks with IBGP
After going through the BGP basics, it’s time to build a network that has more than one BGP router in it, starting with the simplest possible topology: a site with two WAN edge routers.
Heavy Wireless 013: A University Perspective On Operating Wi-Fi And Testing Vendors
On today's Heavy Wireless episode, Keith Parsons speaks with UMass Amherst CTO Jim Mileski on the history of Wi-Fi at the school. They discuss initial challenges of rolling out wireless, strategic placements of access points, ensuring a good student experience across a myriad of devices, and more. They also discuss how Jim and his team tested their incumbent vendor against a possible replacement, how the replacement won out, and how the transition is going.
The post Heavy Wireless 013: A University Perspective On Operating Wi-Fi And Testing Vendors appeared first on Packet Pushers.
Heavy Wireless 013: A University Perspective On Operating Wi-Fi And Testing Vendors
On today's Heavy Wireless episode, Keith Parsons speaks with UMass Amherst CTO Jim Mileski on the history of Wi-Fi at the school. They discuss initial challenges of rolling out wireless, strategic placements of access points, ensuring a good student experience across a myriad of devices, and more. They also discuss how Jim and his team tested their incumbent vendor against a possible replacement, how the replacement won out, and how the transition is going.Industry Analysts Predict Accelerating Shift to Direct-to-Chip Liquid Cooling for Expanding and New Data Centers
Liquid cooling in data centers is gaining greater interest because has clear advantages over air cooling, enabling greater server density per rack and higher compute performance.Will Network Devices Reject BGP Sessions from Unknown Sources?
TL&DR: Violating the Betteridge’s Law of Headlines, the answer is “Yes, but the devil is in the details.”
It all started with the following observation by Minh Ha left as a comment to my previous BGP session security blog post:
I’d think it’d be obvious for BGP routers to only accept incoming sessions from configured BGP neighbors, right? Because BGP is the most critical infrastructure, the backbone of the Internet, why would you want your router to accept incoming session from anyone but KNOWN sources?
Following my “opinions are good, facts are better” mantra, I decided to run a few tests before opinionating1.
Will Network Devices Reject BGP Sessions from Unknown Sources?
TL&DR: Violating the Betteridge’s Law of Headlines, the answer is “Yes, but the devil is in the details.”
It all started with the following observation by Minh Ha left as a comment to my previous BGP session security blog post:
I’d think it’d be obvious for BGP routers to only accept incoming sessions from configured BGP neighbors, right? Because BGP is the most critical infrastructure, the backbone of the Internet, why would you want your router to accept incoming session from anyone but KNOWN sources?
Following my “opinions are good, facts are better” mantra, I decided to run a few tests before opinionating1.