On Centrality and Fragmentation
There seem to be two dominant themes in the enumeration of potential perils that face the Internet these days, and oddly enough they seem to me to be opposite in nature.AWS Advanced Networking Speciality 1.3 : Configuration options for load balancer target groups (for example, TCP, GENEVE, IP compared with instance)
Advanced Network Speciality Exam — Blogs
<MEDIUM : https://towardsaws.com/aws-advanced-networking-speciality-1-3-5484de6c8da >
A Target group routes requests to one or more registered targets. They can be EC2 Instances, IP addresses, Kubernetes Cluster, Lambda Functions etc. Target groups are specified when you create a listener rule. You can also define various health checks and associate them with each target-groups.
Typical load-balancer components



What is Geneve, and what is the context with ELB: Generic Network Virtualisation Encapsulation
In the context of Gateway Load Balancer, a flow can be associated with either 5-Tuple or 3-Tuple.A flow can be associated with either a 5-tuple or 3-tuple flow in load balancers.
A 5-tuple flow includes the source IP address, destination IP address, source port, destination port, and protocol number. This is used for TCP, UDP, and SCTP protocols.
A 3-tuple flow includes the source IP address, destination IP address, and protocol number. This is used for ICMP and ICMPv6 protocols.
Gateway Load balancers and their registered virtual appliances use GENEVE protocol to exchange application traffic on port 6081

References :
https://docs.aws.amazon.com/elasticloadbalancing/latest/application/introduction.html
https://datatracker.ietf.org/doc/html/rfc8926 Continue reading
Speciality 1.3 : Integrations of load balancers and other AWS services (for example, Global Accelerator, CloudFront, AWS WAF, Route 53, Amazon Elastic Kubernetes Service [Amazon EKS], AWS Certificate Manager [ACM])
< MEDIUM : https://raaki-88.medium.com/aws-advanced-networking-speciality-1-3-deedc0217ea6 >
Advanced Network Speciality Exam — Blogs
https://medium.com/@raaki-88/list/aws-advanced-network-speciality-24009c3d8474
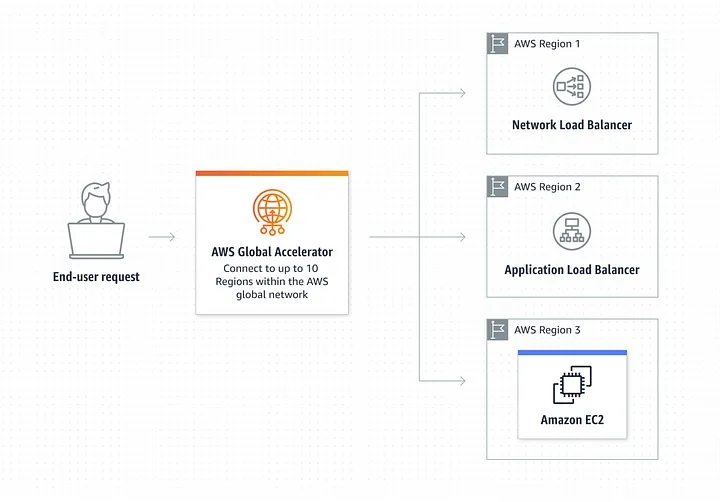
Global Accelerator — A service that provides static ip addresses with your accelerator. These IP addresses are Anycast from the AWS edge network, meaning the global accelerator diverts your application’s traffic to the nearest region to the client.
Two types of Global Accelerators — Standard Accelerators and Custom Routing accelerators.
{kind=link}
{kind=link}
{kind=link}
Standard Accelerators uses aws global network to route traffic to the optimal regional endpoint based on health, client location and policies that the user configures, increasing availability and decreasing latency to the end users. Standard-accelerator endpoints can be Network Load balancers, Application load balancers from load balancing context. Custom routing accelerators do not support load balancer endpoints as of today.
When using accelerators and Load-balancers, update DNS records so that application traffic uses accelerator end-point, redirecting the traffic to load-balancer endpoints.
CloudFront and AWS-WAF with ELB:
When using an application load balancer in ELB, cloud-front meant to cache the objects can reduce the load on ALBs and improve performance. CF can also protect ALB and internal services from DDOS attacks, as with AWS WAF. But for this to succeed, administrators Continue reading
AWS Advanced Networking Speciality 1.3 AWS Advanced Networking: Connectivity patterns that apply to load balancing based on the use case
< MEDIUM: https://raaki-88.medium.com/aws-advanced-networking-speciality-1-3-23eb011b74df >
Previous posts :
https://towardsaws.com/aws-advanced-networking-task-statement-1-3-c457fa0ed893
https://raaki-88.medium.com/aws-advanced-networking-speciality-1-3-3ffe2a43e2f3
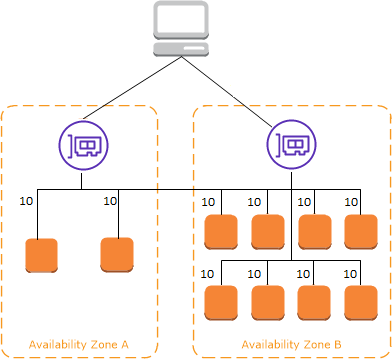
Internal ELB — An internal Load balancer is not exposed to the internet and is deployed in a private subnet. A DNS record gets created, which will have a private-IP address of the load-balancer. It’s worth noting to know DNS records will be publicly resolvable. The main intention is to distribute traffic to EC2 instances. Across availability zones, provided all of them have access to VPCs.
External ELB — Also called an Internet-Facing Load Balancer and deployed in the Public subnet. Similar to Internal ELB, this can also be used to distribute and balance traffic across two availability zones.
Example Architecture Reference — https://docs.aws.amazon.com/prescriptive-guidance/latest/patterns/deploy-an-amazon-api-gateway-api-on-an-internal-website-using-private-endpoints-and-an-application-load-balancer.html?did=pg_card&trk=pg_card
– Rakesh
AWS Advanced Networking Speciality 1.3 AWS Advanced Networking: Different types of load balancers and how they meet requirements for network design, high availability, and security
< MEDIUM: https://raaki-88.medium.com/aws-advanced-networking-speciality-1-3-3ffe2a43e2f3 >
https://medium.com/towards-aws/aws-advanced-networking-task-statement-1-3-c457fa0ed893 — Has intro details for the speciality exam topic

Different types of Load-Balancers
- CLB — Classic Load Balancer
- ALB — Application Load Balancer
- NLB — Network Load Balancer
- GLB — Gateway Load Balancer
High Availability Aspect: ELB (Can be any load-balancing) can distribute traffic across various different targets, including EC2-Instances, Containers, and IP addresses in either a single AZ or multiple AZs within a region.

Health Checks: An additional health check can be included to ensure that the end hos serving the application is healthy. This is typically done through HTTP status codes, with a return value 200 indicating a healthy host. If discrepancies are found during the health check, the ELB can gracefully drain traffic and divert it to another host in the target group. If auto-scaling is set up, it can also auto-scale as needed.
Network Design: Depending on the type of traffic and Application traffic pattern, the load and burst-rate choice of load-balancer will differ.
Various Features — High-Availability, High-Throughput, Health-Checks, Sticky-Sessions, Operational-Monitoring and Logging, Delete-Protection.
TLS Termination — You can also have integrated certificate management and SSL decryption which offloads end-host CPU load and acts as a central Continue reading
AWS Advanced Networking — Task Statement 1.3: How load balancing works at Layer 3, layer 4, and Layer 7 of the OSI model
< MEDIUM: https://towardsaws.com/aws-advanced-networking-task-statement-1-3-c457fa0ed893 >
Ref: https://aws.amazon.com/elasticloadbalancing/
Why Elastic Load Balancer?
- To Distribute incoming application traffic across EC2 instances / Containers / IP Addresses and these entities, generally, can be called targets and grouped as Target-Groups.
- Another advantage is performing health checks, such as packet-loss or high-latency, and can be integrated with Auto-scaling, hence Elastic.
- Depending on the ELB type and its operational requirement, this can further be subdivided into CLB, ALB, GLB, and NLB.
CLB — Classic Load Balancer
– AWS Recommends ALB today instead of CLB
– Intended for EC2 instances which are built in EC2-Classic Network
– Layer 4 or Layer 7 Load Balancing
– Provides SSL Offloading and IPv6 support for Classic Networks
ALB — Application Load Balancer
- Works at the 7th Layer of the OSI Model.
- Supports applications that run in Containers
- Supports Content-based Routing
- HTTP/HTTPS, Mobile Apps, Containers in EC2, and Microservices benefit greatly from ALB
Why Elastic Load Balancer?
- To Distribute incoming application traffic across EC2 instances / Containers / IP Addresses and these entities, generally, can be called targets and grouped as Target-Groups.
- Another advantage is performing health checks, such as packet-loss or high-latency, and can be integrated with Auto-scaling, Continue reading
Set up your Own wireguard-based Cloud VPN server without installing software on your laptop — GL-A1300 Slate Plus Wireless Router
Note: This requires the purchase of a wireless router which is capable of running a Wireguard package in this case it’s Slate-Plus GL-A1300 and I do not have any affiliate or ads program with them, I simply liked it for its effectiveness and low cost.

The Need :
For one reason many of us want a VPN server which does decent encryption but won’t charge us a lot of money, in some cases, it can be done free of cost and in others for not want us to install a variety of software which messes up with internal client routing and also against some of the IT-Policies, even if it’s a browser-based plugin.
The Choice :
Wireguard: https://www.wireguard.com/ — VPN Software, Software-based encryption, extremely fast and light-weight.
GL-A1300 Slate-Plus — Wireless Router with support for Wireguard which is not a feature in many of the current market routers, had OpenWrt as the installed software.
Features
The GL-A1300 Slate Plus wireless VPN encrypted travel router comes packed with features that will make your life easier while travelling. Here are just a few of the most important:
- VPN Encryption — The GL-A1300 Slate Plus Continue reading
AWS Rekognition — A simple classifier without having to build a lot of in-house or Cloud Environments — Sample Bird-Project
A few weeks ago, I set up a bird feeder and used it to capture bird images, the classifier itself was not that accurate but was doing a decent job, what I have realised is that not every time we end up with highly accurate on-board edge classification especially while learning how to implement them.
So after a few weeks, there were a lot of images some of them sure enough had birds while some of them were taken in Pitch Dark and am not even sure what made the classifier figure out a birdie in the snapshot from the camera.
Now for me in order to make an Image, I have to rely on a re-classifier doing the job for me, initially, I thought I will write a lambda-based classifier as a learning experiment, but then I thought it was a one-time process every 6 months or so, so I went ahead with a managed service option and in this case, its AWS Rekognition, which is quite amazing.
https://aws.amazon.com/rekognition/
Code Snippet used for Classification
import os
import concurrent.futures
import boto3
def detect_birds(image_path):
# Configure AWS credentials and region
session Continue reading
Heavy Networking 690: LACP Is Not Link Aggregation – With Tony Bourke
On today’s Heavy Networking we talk LACP and link aggregation. While bonding two or more links together to act as a single virtual link has been done for decades, LACP and link aggregation aren't the same thing, and the distinction matters. Our guest to get into the differences is network instructor Tony Bourke.
The post Heavy Networking 690: LACP Is Not Link Aggregation – With Tony Bourke appeared first on Packet Pushers.