How to Speed 5G innovation with Telecom SaaS
The ability to develop and deploy new value-added services for customers is a top-line priority for telcos, and telecom SaaS empowers telcos to deliver such services faster.Kubernetes Unpacked 017: Kubernetes In 2023 – 6 Things To Think About
On today's Kubernetes Unpacked podcast, host Michael Levan discusses six big ideas to consider as you build your Kubernetes foundation in 2023. Topics include abstractions, the need to understand what's beneath those abstractions, Kubernetes security, and more.
The post Kubernetes Unpacked 017: Kubernetes In 2023 – 6 Things To Think About appeared first on Packet Pushers.
Kubernetes Unpacked 017: Kubernetes In 2023 – 6 Things To Think About
On today's Kubernetes Unpacked podcast, host Michael Levan discusses six big ideas to consider as you build your Kubernetes foundation in 2023. Topics include abstractions, the need to understand what's beneath those abstractions, Kubernetes security, and more.Introducing Waiting Room Bypass Rules


Leveraging the power and versatility of Cloudflare's Ruleset Engine, Waiting Room now offers customers more fine-tuned control over their waiting room traffic. Queue only the traffic you want to with Waiting Room Bypass Rules, now available to all Enterprise customers with an Advanced Purchase of Waiting Room.
Customers depend on Waiting Room for always-on protection from unexpected and overwhelming traffic surges that would otherwise bring their site down. Waiting Room places excess users in a fully customizable virtual waiting room, admitting new visitors dynamically as spots become available on a customer’s site. Instead of throwing error pages or delivering poorly-performing site pages, Waiting Room empowers customers to take control of their end-user experience during unmanageable traffic surges.
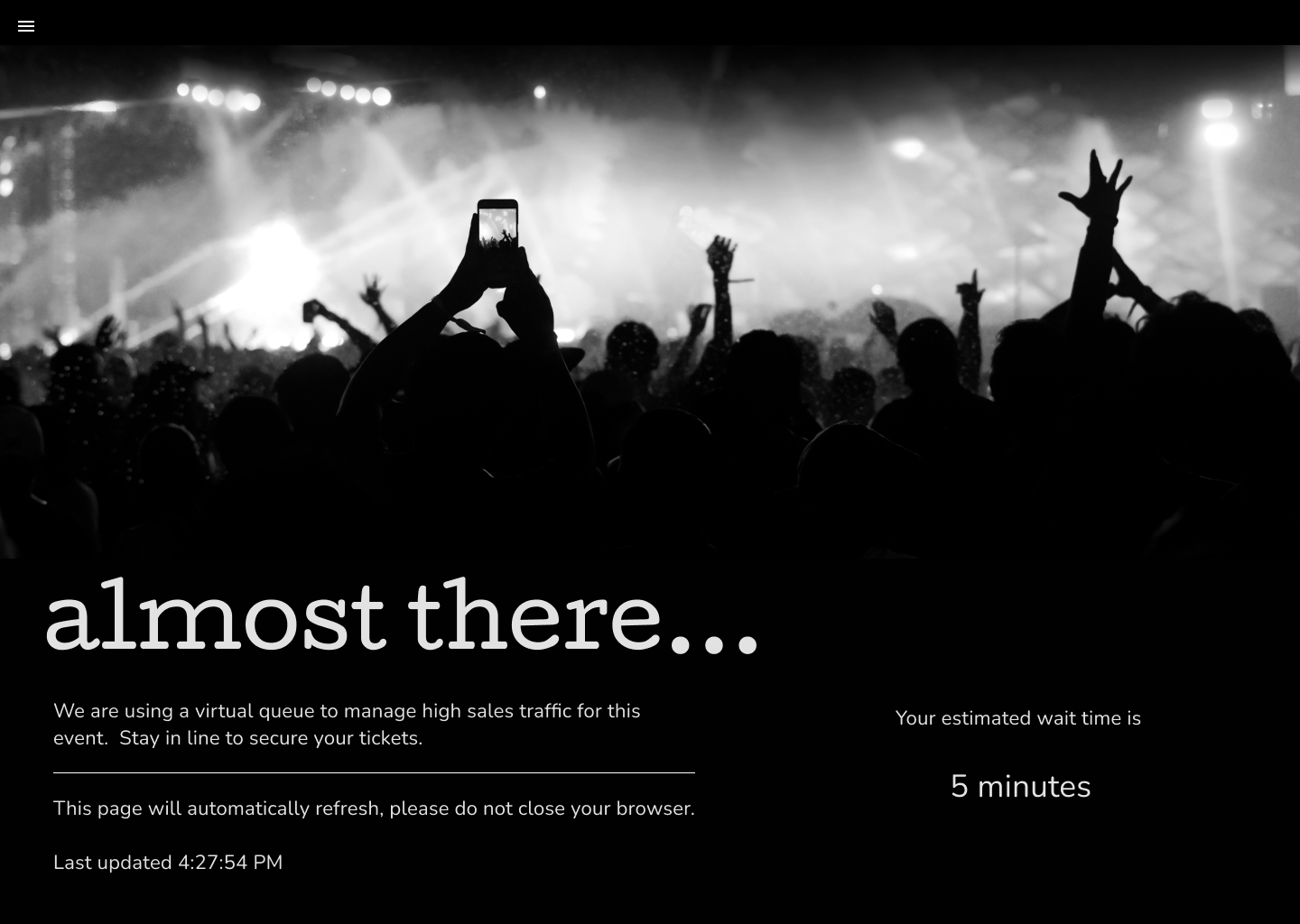
Additionally, customers use Waiting Room Event Scheduling to manage user flow and ensure reliable site performance before, during, and after online events such as product restocks, seasonal sales, and ticket sales. With Event Scheduling, customers schedule changes to their waiting rooms' settings and custom queuing page ahead of time, with options to pre-queue early arrivers and offload event traffic from their origins after the event has concluded.
As part of Continue reading
Why are so many recruiters looking for ‘on-site’ workers ?
Relationships between Layer-2 (VLAN) and Layer-3 (Subnet) Segments
Sometimes it takes me years to answer interesting questions, like the one I got in a tweet in 2021:
Do you have a good article describing the one-to-one relation of layer-2 and layer-3 networks? Why should every VLAN contain one single L3 segment?
There is no mandatory relationship between multi-access layer-2 networks and layer-3 segments, and secondary IP addresses (and subnets) were available in Cisco IOS in early 1990s. The rules-of-thumb1 claiming there should be a 1:1 relationship usually derive from the oft-forgotten underlying requirements. Let’s start with those.
Relationships between Layer-2 (VLAN) and Layer-3 (Subnet) Segments
Sometimes it takes me years to answer interesting questions, like the one I got in a tweet in 2021:
Do you have a good article describing the one-to-one relation of layer-2 and layer-3 networks? Why should every VLAN contain one single L3 segment?
There is no mandatory relationship between multi-access layer-2 networks and layer-3 segments, and secondary IP addresses (and subnets) were available in Cisco IOS in early 1990s. The rules-of-thumb1 claiming there should be a 1:1 relationship usually derive from the oft-forgotten underlying requirements. Let’s start with those.
Terraform Cloud Version Controlled Workflows with Github
https://codingpackets.com/blog/terraform-cloud-version-controlled-workflows-with-github
Day Two Cloud 178: Implementing Zero Standing Privilege (Sponsored)
On today's sponsored Day Two Cloud podcast we talk about zero standing privilege with strongDM. Zero standing privilege goes beyond just-in-time credentials to a model where no credentials pre-exist, but are created in real-time and paired with appropriate permissions built from policy, also created in real-time. Can such a thing be accomplished technically---and without irritating all your end users? StrongDM's Sebastian Mankowski is here to make the case.
The post Day Two Cloud 178: Implementing Zero Standing Privilege (Sponsored) appeared first on Packet Pushers.
Day Two Cloud 178: Implementing Zero Standing Privilege (Sponsored)
On today's sponsored Day Two Cloud podcast we talk about zero standing privilege with strongDM. Zero standing privilege goes beyond just-in-time credentials to a model where no credentials pre-exist, but are created in real-time and paired with appropriate permissions built from policy, also created in real-time. Can such a thing be accomplished technically---and without irritating all your end users? StrongDM's Sebastian Mankowski is here to make the case.Connected Power: An Emerging Cybersecurity Priority
When leveraging connected power devices, network managers should consider several factors that can offer assurance that those devices were built with cybersecurity as a top priority.Feedback: Docker Networking Deep Dive
While the pundits keeps telling me Docker is dead (looking at its documentation I would say they’re right) and Kubernetes it the way to go (yay!), some people still have to deal with Docker networking, and at least some of them found the Docker Networking Deep Dive webinar useful. Here’s a recent review:
You can scroll over internet pages as long as you can, you will rarely find this kind of specialized knowledge. This is the next level in term of knowledge about Docker.
If you belong to the “Kubernetes will rule the world” camp, we have you covered as well: Stuart Charlton created a phenomenal Kubernetes Networking Deep Dive webinar (approximately half of it is already accessible with free subscription).
Feedback: Docker Networking Deep Dive
While the pundits keeps telling me Docker is dead (looking at its documentation I would say they’re right) and Kubernetes it the way to go (yay!), some people still have to deal with Docker networking, and at least some of them found the Docker Networking Deep Dive webinar useful. Here’s a recent review:
You can scroll over internet pages as long as you can, you will rarely find this kind of specialized knowledge. This is the next level in term of knowledge about Docker.
If you belong to the “Kubernetes will rule the world” camp, we have you covered as well: Stuart Charlton created a phenomenal Kubernetes Networking Deep Dive webinar (approximately half of it is already accessible with free subscription).