New Return-To-Office Policies
The following post originally appeared in Human Infrastructure, a weekly newsletter from the Packet Pushers. You can sign up and see every back issue here. Earlier this year, Google spent a billion dollars on office space in London. As the company orders employees back to its campuses, it’s also restarting amenities “such as cafes, restaurants, […]
The post New Return-To-Office Policies appeared first on Packet Pushers.
Congratulations Cloudflare 2021 Partner Award Winners

We’re thrilled to announce the winners of our annual Channel and Alliance Partner Awards for 2021. Throughout a year of continued global disruptions, Cloudflare’s partners kept innovating, expanding their solutions and services capabilities, and accelerated their growth with us and our platform. It is important that we recognize and award the partners of ours who stood out in staying laser-focused on delivering outstanding business outcomes for customers.

With the ongoing shift in 2021 to remote, flexible work forces and the evolving cyber threat landscape, more than ever organizations across every industry and the public sector were looking to Cloudflare, and to work hand in hand with partners who can deliver a modern, Zero Trust approach to security. Seeing this consistent need, we are continuing to build and support new levels of partner-led growth in the year ahead such as with a new partner services program for SASE and Zero Trust which we launched at the start of 2022.
Please join us in congratulating the impressive achievements of our partner award winners over this past year! They enable the further delivery of Internet security, performance, and reliability for organizations of all sizes and types — and we are thrilled to be Continue reading
Protect all network traffic with Cloudflare
Magic Transit protects customers' entire networks—any port/protocol—from DDoS attacks and provides built-in performance and reliability. Today, we’re excited to extend the capabilities of Magic Transit to customers with any size network, from home networks to offices to large cloud properties, by offering Cloudflare-maintained and Magic Transit-protected IP space as a service.
What is Magic Transit?
Magic Transit extends the power of Cloudflare’s global network to customers, absorbing all traffic destined for your network at the location closest to its source. Once traffic lands at the closest Cloudflare location, it flows through a stack of security protections including industry-leading DDoS mitigation and cloud firewall. Detailed Network Analytics, alerts, and reporting give you deep visibility into all your traffic and attack patterns. Clean traffic is forwarded to your network using Anycast GRE or IPsec tunnels or Cloudflare Network Interconnect. Magic Transit includes load balancing and automatic failover across tunnels to steer traffic across the healthiest path possible, from everywhere in the world.
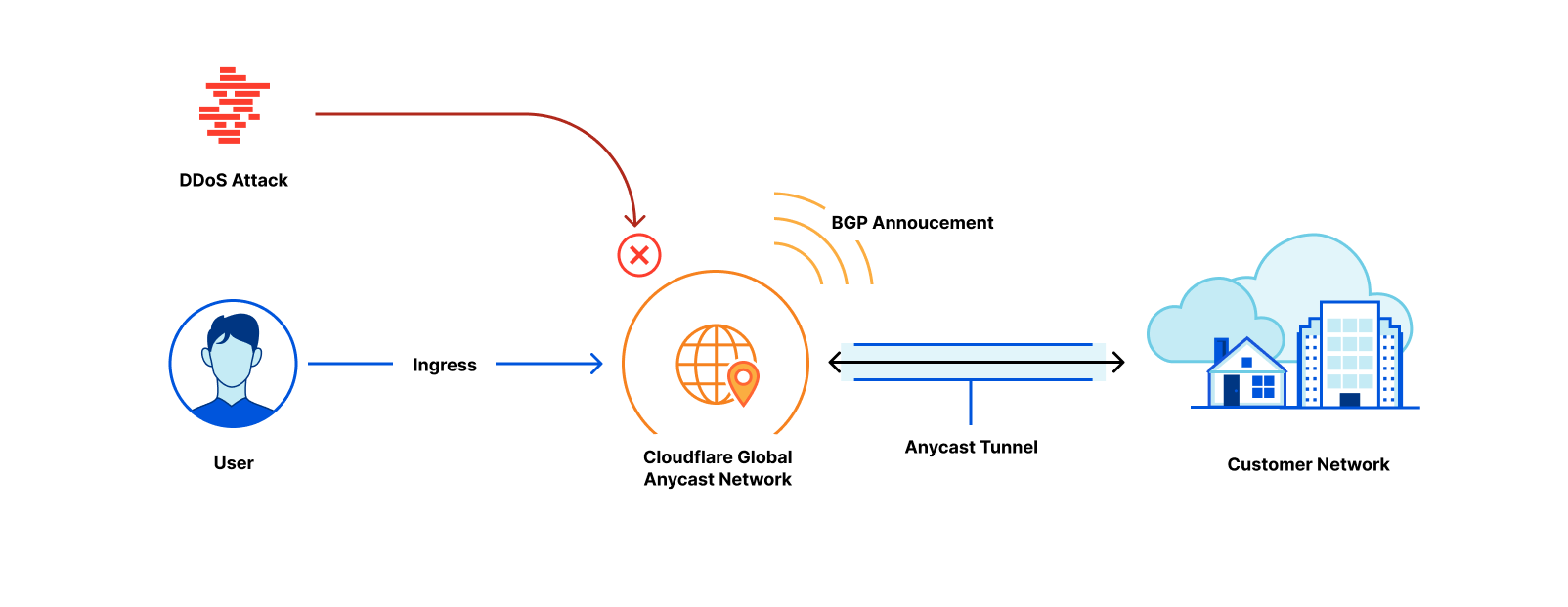
The “Magic” Continue reading
Clientless Web Isolation is now generally available
Today, we’re excited to announce that Clientless Web Isolation is generally available. A new on-ramp for Browser Isolation that natively integrates Zero Trust Network Access (ZTNA) with the zero-day, phishing and data-loss protection benefits of remote browsing for users on any device browsing any website, internal app or SaaS application. All without needing to install any software or configure any certificates on the endpoint device.
Cloudflare’s clientless web isolation simplifies connections to remote browsers through a hyperlink (e.g.: https://<your-auth-domain>.cloudflareaccess.com/browser). We explored use cases in detail in our beta announcement post, but here’s a quick refresher on the use cases that clientless isolated browsing enables:
Share secure browsing across the entire team on any device
Simply navigating to Clientless Web Isolation will land your user such as an analyst, or researcher in a remote browser, ready to securely conduct their research or investigation without exposing their public IP or device to potentially malicious code on the target website.
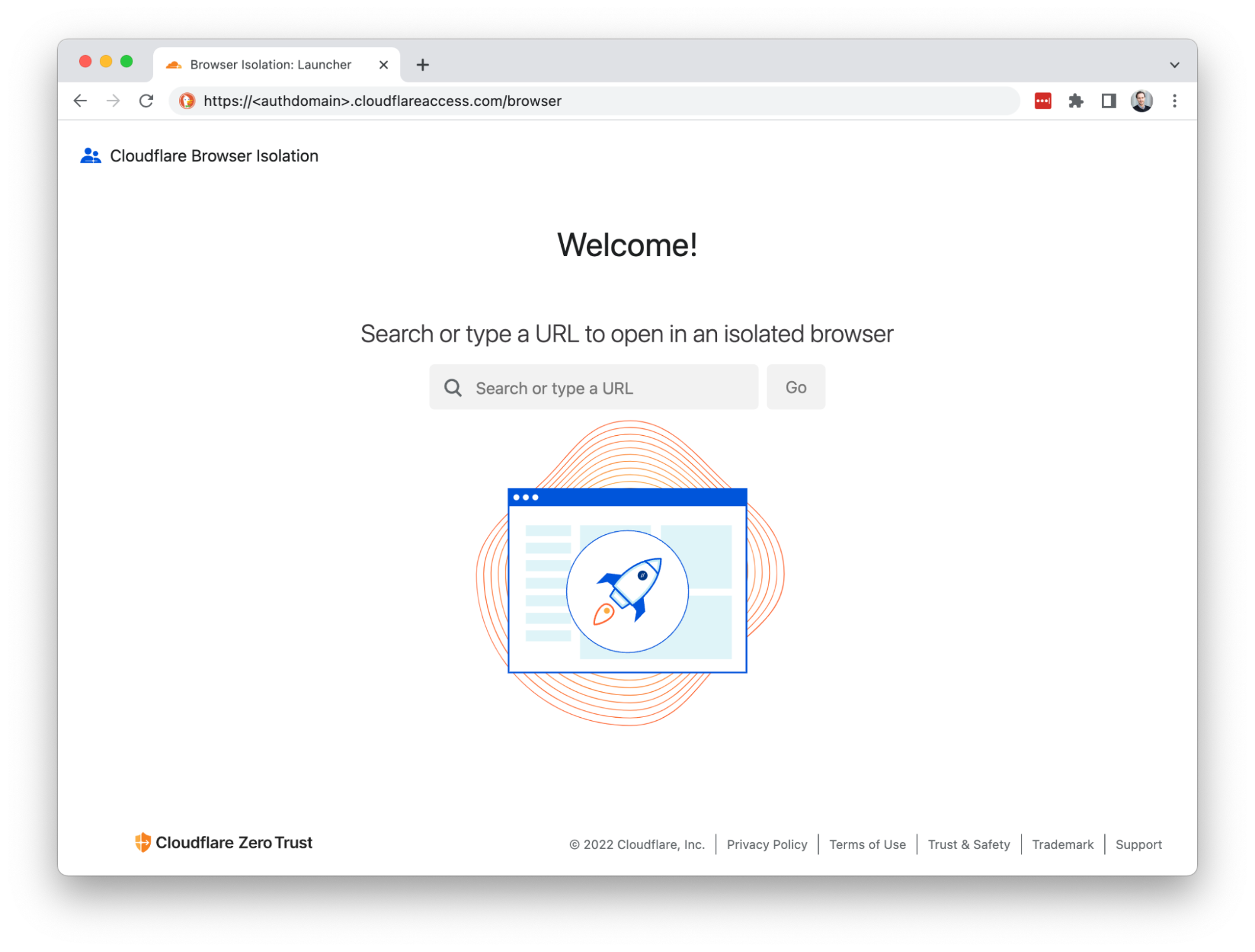
Deep link into isolated browsing
Suspicious hyperlinks and PDF documents from sensitive applications can be opened in a remote browser by rewriting the link with the clientless endpoint. For example:
https://<authdomain>.cloudflareaccess.com/browser/https://www.example.com/suspiciouslink
This is Continue reading
Packet captures at the edge


Packet captures are a critical tool used by network and security engineers every day. As more network functions migrate from legacy on-prem hardware to cloud-native services, teams risk losing the visibility they used to get by capturing 100% of traffic funneled through a single device in a datacenter rack. We know having easy access to packet captures across all your network traffic is important for troubleshooting problems and deeply understanding traffic patterns, so today, we’re excited to announce the general availability of on-demand packet captures from Cloudflare’s global network.
What are packet captures and how are they used?
A packet capture is a file that contains all packets that were seen by a particular network box, usually a firewall or router, during a specific time frame. Packet captures are a powerful and commonly used tool for debugging network issues or getting better visibility into attack traffic to tighten security (e.g. by adding firewall rules to block a specific attack pattern).
A network engineer might use a pcap file in combination with other tools, like mtr, to troubleshoot problems with reachability to their network. For example, if an end user reports intermittent connectivity to a specific application, an engineer Continue reading
Cloudflare and Aruba partner to deliver a seamless global secure network from the branch to the cloud


Today we are excited to announce that Cloudflare and Aruba are working together to develop a solution that will enable Aruba customers to connect EdgeConnect SD-WAN’s with Cloudflare's global network to further secure their corporate traffic with Cloudflare One. Whether organizations need to secure Internet-bound traffic from branch offices using Cloudflare's Secure Web Gateway & Magic Firewall, or enforce firewall policies for east/west traffic between offices via Magic Firewall, we have them covered. This gives customers peace of mind that they have consistent global security from Cloudflare while retaining granular control of their inter-branch and Internet-bound traffic policies from their Aruba EdgeConnect appliances.
SD-WAN solution
A software-defined WAN (SD-WAN) is an evolution of a WAN (wide area network) that simplifies the underlying architecture. Unlike traditional WAN architecture models where expensive leased, and MPLS links are used, SD-WAN can efficiently use a combination of private lines and the public Internet. It brings together the best of both worlds to provide an integrated solution to network administrators in managing and scaling their network and resources with ease.
Aruba’s EdgeConnect SD-WAN solution
We are proud to announce our first enhanced SD-WAN integration. Aruba’s EdgeConnect solution is an industry leader for WAN edge Continue reading
Cloudflare and CrowdStrike partner to give CISOs secure control across devices, applications, and corporate networks

Today, we are very excited to announce multiple new integrations with CrowdStrike. These integrations combine the power of Cloudflare’s expansive network and Zero Trust suite, with CrowdStrike’s Endpoint Detection and Response (EDR) and incident remediation offerings.

At Cloudflare, we believe in making our solutions easily integrate with the existing technology stack of our customers. Through our partnerships and integrations, we make it easier for our customers to use Cloudflare solutions jointly with that of partners, to further strengthen their security posture and unlock more value. Our partnership with CrowdStrike is an apt example of such efforts.
Together, Cloudflare and CrowdStrike are working to simplify the adoption of Zero Trust for IT and security teams. With this expanded partnership, joint customers can identify, investigate, and remediate threats faster through multiple integrations:
First, by integrating Cloudflare’s Zero Trust services with CrowdStrike Falcon Zero Trust Assessment (ZTA), which provides continuous real-time device posture assessments, our customers can verify users’ device posture before granting them access to internal or external applications.
Second, we joined the CrowdXDR Alliance in December 2021 and are partnering with CrowdStrike to share security telemetry and other insights to make it easier for customers to identify and mitigate threats. Continue reading
So-Called Modern VPNs: Marketing and Reality
Someone left a “killer” comment1 after reading the Should We Use LISP blog post. It start with…
I must sadly say that your view on what VPN is all about is pretty rusty and archaic :( Sorry! Modern VPNs are all pub-sub based and are already turning into NaaS.
Nothing new there. I’ve been called old-school guru from an ivory tower when claiming TRILL is the wrong direction and we should use good old layer-3-based design2, but let’s unpack the “pub-sub” bit.
So-Called Modern VPNs: Marketing and Reality
Someone left a “killer” comment1 after reading the Should We Use LISP blog post. It start with…
I must sadly say that your view on what VPN is all about is pretty rusty and archaic :( Sorry! Modern VPNs are all pub-sub based and are already turning into NaaS.
Nothing new there. I’ve been called old-school guru from an ivory tower when claiming TRILL is the wrong direction and we should use good old layer-3-based design2, but let’s unpack the “pub-sub” bit.
Private 5G Networks Sector Surges with New Services, Investments, and User Trials
Enterprises face a fast-expanding array of 5G private network offerings as AWS, Cisco, HPE, and others have joined the fray since December.Hedge 122: The Internet Architecture Board

What is the Internet Architecture Board (IAB) of the IETF? What role does the IAB play in the larger ecosystem of building and deploying standard protocols? In this episode of the Hedge, Tom and Ethan “flip roles” with Russ to ask these questions.
10 Reasons to Implement Network Automation – Low Effort, High Impact
In 2022, nearly 77% of technology professionals see the need for improvement in their data center network automation strategies. Despite years of predictions about applications and data migrating to the public cloud, a consensus has been that data centers remain the indispensable core of any digital infrastructure. While the public cloud has a vital role to play and it continues to grow, enterprises and service providers continue to rely on data centers to power their operations. To remain relevant in a cloud-centric world, data centers must modernize – needing scalable, efficient, and agile operations. Highly manual processes do not scale gracefully, therefore calling for organizations and their data centers to adopt network automation or be left behind.
VMware is proud to have an opportunity to sponsor Enterprise Management Associates (EMA) in producing The Future of Data Center Network Automation research report. This report analyzes cutting-edge technology of data center automation – drawing on quantitative and qualitative research done by EMA analysts – focusing on how tech orgs are planning, implementing, and using data center network automation solutions, the specific technologies they’re using, and the benefits and challenges associated with data center network automation. Using real-time VMware customers Continue reading
Containerlab DDoS testbed

docker run --rm -it --privileged --network host --pid="host" \Start Containerlab.
-v /var/run/docker.sock:/var/run/docker.sock -v /run/netns:/run/netns \
-v ~/clab:/home/clab -w /home/clab \
ghcr.io/srl-labs/clab bash
curl -O https://raw.githubusercontent.com/sflow-rt/containerlab/master/ddos.ymlDownload the Containerlab topology file.
containerlab deploy -t ddos.ymlFinally, deploy the topology.


docker exec -it clab-ddos-attacker hping3 --flood --udp -k -s 53 192.0.2.129Start a simulated DNS amplification attack using hping3.
