NB529: HPE Debuts 8Tbps Switch with Onboard DPUs; NVIDIA Revenues Run Wild
Take a Network Break! We start with a Red Alert for the IBM Tivoli Monitoring Tool, which has an unpatched (as of recording time) vulnerability that could allow remote attackers to execute arbitrary code. On the news front, Salesforce ponies up $8 billion for Informatica to improve data governance capabilities, Google researchers revise estimates of... Read more »Tech Bytes: NetFlow Optimizer: More Insights, Less Flow Volume (Sponsored)
Today on the Tech Bytes podcast, we talk about how to get more out of your NetFlow records with sponsor NetFlow Logic. NetFlow’s been around for a long time, and if you’re already including flow records as part of your monitoring and management arsenal, you may think you’re extracting all the value you can from... Read more »Cumulus Linux (As We Know It) Is Gone
A reader of my blog pointed out the following minutiae hidden at the very bottom of the Cumulus Linux 5.13 What’s New document:
NVIDIA no longer releases Cumulus VX as a standalone image. To simulate a Cumulus Linux switch, use NVIDIA AIR.
And what is NVIDIA AIR?
Are Smart Glasses the Future of AI? My Hands-On Review of Meta AI Glasses
Honestly, I never believed smart glasses would become a mainstream AI form factor—until I bought the Meta Ray-Ban Smart Glasses two weeks ago! 😎 This gadget had been on my wishlist for a while, but it wasn’t available in India, and even if you managed to get one from abroad, the app didn’t work well … Continue reading Are Smart Glasses the Future of AI? My Hands-On Review of Meta AI GlassesHN783: BGP Routing Policy for Enterprise Networkers: Unpacking IRR and RPSL
If you participate in the public Internet by announcing your own netblocks, you should be familiar with Internet Routing Registries (IRRs) and the Routing Policy Specification Language (RPSL). These are tools that help you be a good network citizen. In a world of BGP hijacks and other problems, these tools matter more than ever. We... Read more »Cloudflare named a Strong Performer in Email Security by Forrester
Today, we are excited to announce that Forrester has recognized Cloudflare Email Security as a Strong Performer and among the top three providers in the ‘current offering’ category in “The Forrester Wave™: Email, Messaging, And Collaboration Security Solutions, Q2 2025” report. Get a complimentary copy of the report here. According to Forrester:
“Cloudflare is a solid choice for organizations looking to augment current email, messaging, and collaboration security tooling with deep content analysis and processing and malware detection capabilities.”
In this evaluation, Forrester analyzed 10 Email Security vendors across 27 different criteria. Cloudflare received the highest scores possible in nine key evaluation criteria, and also scored among the top three in the current offering category. We believe this recognition is due to our ability to deliver stronger security outcomes across email and collaboration tools. These highlights showcase the strength and maturity of our Email Security solution:
Antimalware & sandboxing
Cloudflare’s advanced sandboxing engine analyzes files, whether directly attached or linked via cloud storage, using both static and dynamic analysis. Our AI-powered detectors evaluate attachment structure and behavior in real time, enabling protection not only against known malware but also emerging threats.
Malicious URL detection & web Continue reading
TNO031: Attracting New Talent to Networking, Pairing Dev With NetOps, and More With Justin Ryburn
Total Networks Operations sits down with Justin Ryburn for a wide-ranging discussion on the state of the networking industry. Topics including how to attract new talent to network engineering and network operations; getting literate in DevOps/infrastructure tools such as GitHub, Terraform, and Python; pairing Dev and NetOps to maximize domain expertise; integrating tools and trying... Read more »Multi-Layer Switching and Tunneling
When deep-diving into the confusing terminology of switching, routing, and bridging, I mentioned you could perform packet forwarding at different layers of a networking stack. In this blog post, we’ll explore what happens when we combine packet forwarding on multiple layers within a single network, resulting in multi-layer switching, where edge devices perform Layer n forwarding (usually Layer 3), and core devices perform Layer n-1 forwarding (typically Layer 2).
Each layer can use any forwarding paradigm you choose. However, since we generally use IP at Layer 3, edge devices typically perform hop-by-hop destination-based forwarding, while core devices can use alternative methods.
IPB176: How to Number Point-to-Point Links
Let’s chat about point-to-point links. On today’s episode we cover what should and shouldn’t be done, and discuss why following RFC’s doesn’t always get you to the right place. We dig into questions including: Don’t we just use link-local addresses for point-to-points? Shouldn’t we assign a /127, just like we do a /31 in IPv4?... Read more »Hedge 269: Web 3.0
Yes, we took an (unintentional) three-week break for medical reasons … but we’re back with a new episode.
What is Web 3.0, and how is it different from Web 2.0? What about XR, AI, and Quantum, and their relationship to Web 3.0? Jamie Schwartz joins Tom Ammon and Russ White to try to get to a solid definition of what Web 3.0 and how it impacts the future of the Internet.
Let’s DO this: detecting Workers Builds errors across 1 million Durable Objects
Cloudflare Workers Builds is our CI/CD product that makes it easy to build and deploy Workers applications every time code is pushed to GitHub or GitLab. What makes Workers Builds special is that projects can be built and deployed with minimal configuration. Just hook up your project and let us take care of the rest!
But what happens when things go wrong, such as failing to install tools or dependencies? What usually happens is that we don’t fix the problem until a customer contacts us about it, at which point many other customers have likely faced the same issue. This can be a frustrating experience for both us and our customers because of the lag time between issues occurring and us fixing them.
We want Workers Builds to be reliable, fast, and easy to use so that developers can focus on building, not dealing with our bugs. That’s why we recently started building an error detection system that can detect, categorize, and surface all build issues occurring on Workers Builds, enabling us to proactively fix issues and add missing features.
It’s also no secret that we’re big fans of being “Customer Zero” at Cloudflare, and Workers Builds is itself a Continue reading
BGP and MTU Deep Dive
A long long time ago, BGP implementations would use a Maximum Segment Size (MSS) of 536 bytes for BGP peerings. Why 536? Because in RFC 791, the original IP RFC, the maximum length of a datagram is defined as follows:
Total Length: 16 bits
Total Length is the length of the datagram, measured in octets,
including internet header and data. This field allows the length of
a datagram to be up to 65,535 octets. Such long datagrams are
impractical for most hosts and networks. All hosts must be prepared
to accept datagrams of up to 576 octets (whether they arrive whole
or in fragments). It is recommended that hosts only send datagrams
larger than 576 octets if they have assurance that the destination
is prepared to accept the larger datagrams.
The number 576 is selected to allow a reasonable sized data block to
be transmitted in addition to the required header information. For
example, this size allows a data block of 512 octets plus 64 header
octets to fit in a datagram. The maximal internet header is 60
octets, and a typical internet header is 20 octets, allowing a
margin for headers of higher level protocols.
The idea was to Continue reading
N4N028: The Wide World of WANs
We wanted to do an episode on SD-WAN, but realized we needed to set the stage for how wide-area networking developed. That’s why today’s episode is a history lesson of the Wide Area Network (WAN). We talk about how WANs emerged, public and private WANs, how WANs connect to LANs and data centers, the care... Read more »Dear ArubaCX, VXLAN VNI Has 24 Bits
I thought I’ve seen it all, but the networking vendors (and their lack of testing) never cease to amaze me. Today’s special: ArubaCX software VXLAN implementation.
We decided it’s a good idea to rewrite the VXLAN integration tests to use one target device and one FRR container to test inter-vendor VXLAN interoperability. After all, what could possibly go wrong with a simple encapsulation format that could be described on a single page?
Everything worked fine (as expected), except for the ArubaCX VM (running release Virtual.10.15.1005, build ID AOS-CX:Virtual.10.15.1005:9d92f5caa6b6:202502181604), which failed every single test.
HW053: Ubiquiti in the Enterprise
Ubiquiti is known primarily for wireless equipment for residential and small business use, but it can be a player in the enterprise world. On today’s show, we talk with Darrell DeRosia, Sr. Director, Network & Infrastructure Services with the Memphis Grizzlies, about how he provides that connectivity for the FedExForum, home to the Memphis Grizzlies... Read more »D2DO273: Azure VNets Don’t Exist
Cloud networks aren’t like traditional data center networks, so applying a traditional network design to the cloud probably isn’t the best idea. On today’s Day Two Cloud, guest Aidan Finn guides us through significant differences between Microsoft Azure networking and on-prem data center networks. For instance, subnets don’t segment hosts, network security groups do; every... Read more »Worth Reading: Practical Advice for Engineers
Sean Goedecke published an interesting compilation of practical advice for engineers. Not surprisingly, they include things like “focus on fundamentals” and “spend your working time doing things that are valuable to the company and your career” (OMG, does that really have to be said?).
Bonus point: a link to an article by Patrick McKenzie (of the Bits About Money fame) explaining why you SHOULD NOT call yourself a programmer (there goes the everyone should be a programmer gospel 😜).
Understanding Shortest Path First
Link state protocols like OSPF and IS-IS use the Shortest Path First (SPF) algorithm developed by Edsger Dijkstra. Edsger was a Dutch computer scientist, programmer, software engineer, mathematician, and science essayist. He wanted to solve the problem of finding the shortest distance between two cities such as Rotterdam and Groningen. The solution came to him when sitting in a café and the rest is history. SPF is used in many applications, such as GPS, but also in routing protocols, which I’ll cover today.
To explain SPF, I’ll be working with the following topology:
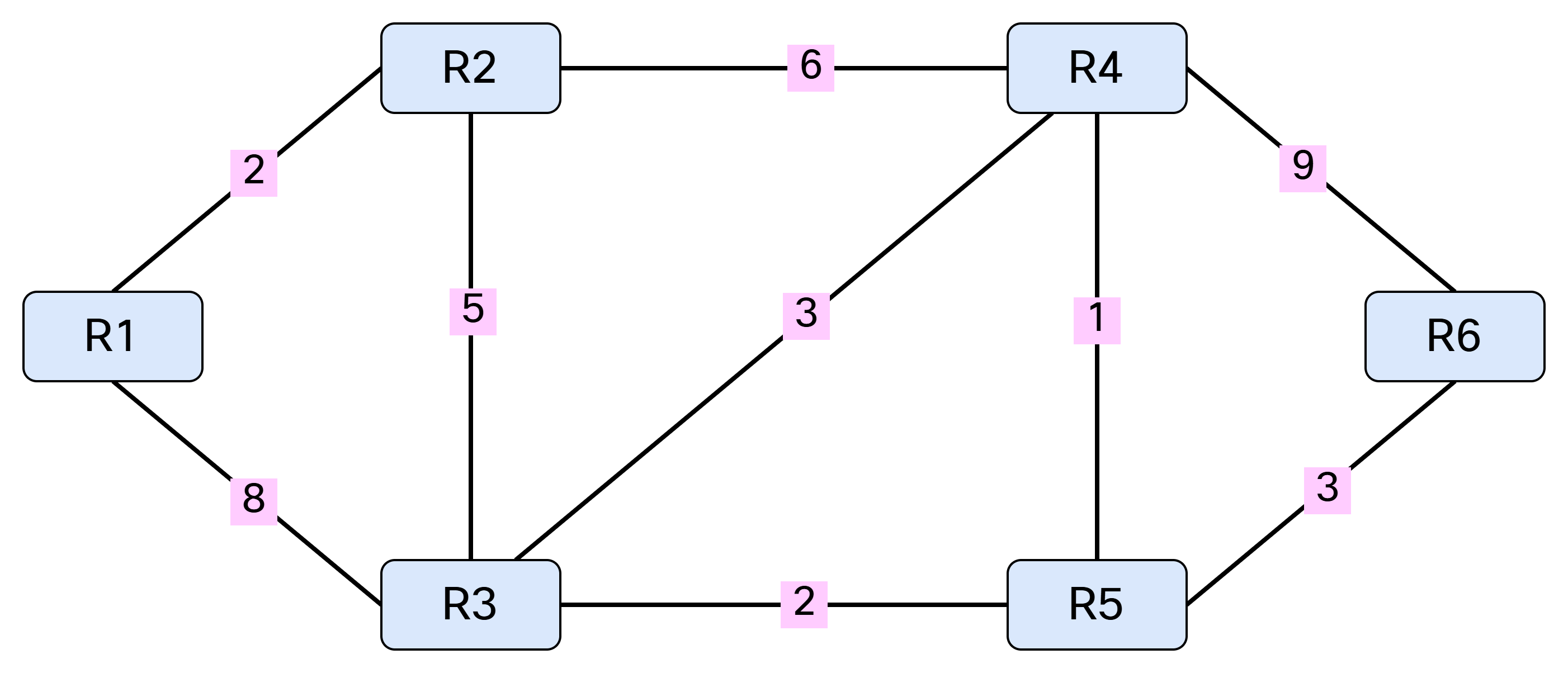
Note that SPF only works with a weighted graph where we have positive weights. I’m using symmetrical costs, although you could have different costs in each direction. Before running SPF, we need to build our Link State Database (LSDB) and I’ll be using IS-IS in my lab for this purpose. Based on the topology above, we can build a table showing the cost between the nodes:
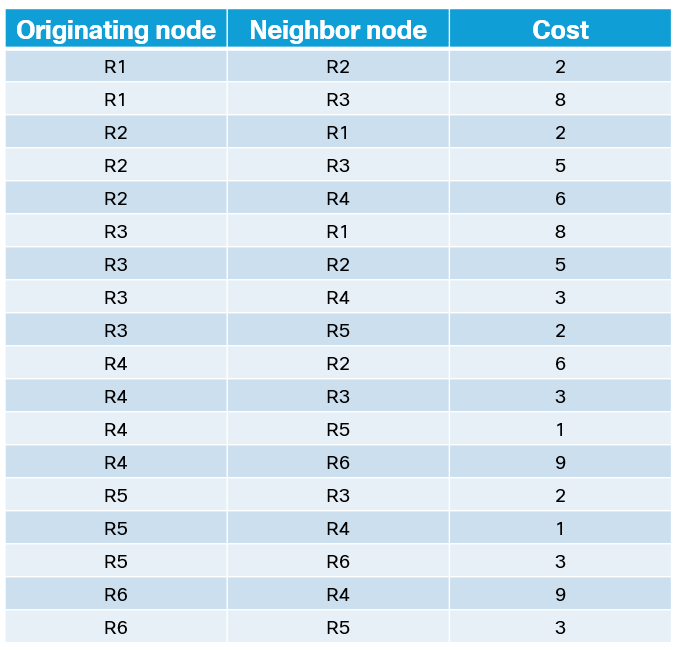
This triplet of information consists of originating node, neighbor node, and cost. It can also be represented as [R1, R2, 2], [R1, R3, 8], [R2, R1, 2], [R2, R3, 5], [R2, R4, 6], [R3, R1, 8], [R3, R2, 5], [R3, R4, Continue reading
BGP handling bug causes widespread internet routing instability
BGP handling bug causes widespread internet routing instability
At 7AM (UTC) on Wednesday May 20th 2025 a BGP message was propagated that triggered surprising (to many) behaviours with two major B