HW044: Unpacking NETGEAR’s Enterprise Wireless and Wired Portfolio (Sponsored)
NETGEAR is known for consumer networking products, but it also offers a robust porfolio of wireless and wired networking products designed for the enterprise. On today’s Heavy Wireless, sponsored by NETGEAR, we take a close look at the hardware, software, and services that NETGEAR offers to enterprise customers. That includes Wi-Fi 7 APs, a full... Read more »The Coming Age Of The Internet Of Agents
Almost a year ago, executives, researchers, and developers within the Outshift group of Cisco Systems – an incubation unit focused on such advanced technologies as AI and quantum computing – began batting about the idea of a network infrastructure connecting vast numbers of AI agents from multiple vendors or organizations, allowing those AI agents to automatically communicate, work together, and solve complex problems for enterprises. …
The Coming Age Of The Internet Of Agents was written by Jeffrey Burt at The Next Platform.
A diversity of downtime: the Q4 2024 Internet disruption summary
Cloudflare’s network spans more than 330 cities in over 120 countries, where we interconnect with over 13,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions at both a local and national level, as well as at a network level.
As we have noted in the past, this post is intended as a summary overview of observed and confirmed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter. A larger list of detected traffic anomalies is available in the Cloudflare Radar Outage Center.
In the third quarter we covered quite a few government-directed Internet shutdowns, including many intended to prevent cheating on exams. In the fourth quarter, however, we only observed a single government-directed shutdown, this one related to protests. Terrestrial cable cuts impacted connectivity in two African countries. As we have seen multiple times before, both unexpected power outages and rolling power outages following military action resulted in Internet disruptions. Violent storms and an earthquake Continue reading
Deepseek-r1 – reasoning and Chain of thought – Network Engineers
https://www.deepseek.com/ – DeepSeek has taken the AI world by storm. Their new reasoning model, which is open source, achieves results comparable to OpenAI’s O1 model but at a fraction of the cost. Many AI companies are now studying DeepSeek’s white paper to understand how they achieved this.
This post analyses reasoning capabilities from a Network Engineer’s perspective, using a simple BGP message scenario. Whether you’re new to networking or looking to refresh your reasoning skills for building networking code, DeepSeek’s model is worth exploring. The model is highly accessible – it can run on Google Colab or even a decent GPU/MacBook, thanks to DeepSeek’s focus on efficiency.
For newcomers: The model is accessed through a local endpoint, with queries and responses handled through a Python program. Think of it as a programmatic way to interact with a chat interface.
Code block
Simple code. One function block has prompt set to LLM to be a expert Network engineer. We are more interested in the thought process. The output of the block is a sample BGP output from a industry standard device, nothing fancy here.
import requests
import json
def analyze_bgp_output(device_output: str) -> str:
url = "<http://localhost:11434/api/chat>"
# Craft prompt Continue readingWorth Reading: Drunken Plagiarists
George V. Neville-Neil published a fantastic, must-read summary of the various code copilots’ usefulness on ACM Queue: The Drunken Plagiarists.
It pretty much mirrors my experience (plus, I got annoyed when the semi-relevant suggestions kept kicking me out of the flow) and reminds me of the early days of OpenFlow, when nobody wanted to listen to old grunts like myself telling the world it was all hype and little substance.
Cloudflare meets new Global Cross-Border Privacy standards
Cloudflare proudly leads the way with our approach to data privacy and the protection of personal information, and we’ve been an ardent supporter of the need for the free flow of data across jurisdictional borders. So today, on Data Privacy Day (also known internationally as Data Protection Day), we’re happy to announce that we’re adding our fourth and fifth privacy validations, and this time, they are global firsts! Cloudflare is the first organisation to announce that we have been successfully audited against the brand new Global Cross-Border Privacy Rules (Global CBPRs) for data controllers and the Global Privacy Rules for Processors (Global PRP). These validations demonstrate our support and adherence to global standards that provide for privacy-respecting data flows across jurisdictions. Organizations that have been successfully audited will be formally certified when the certifications officially launch, which we expect to happen later in 2025.
Our participation in the Global CBPRs and Global PRP joins our roster of privacy validations: we were one of the first cybersecurity organizations to certify to the international privacy standard ISO 27701:2019 when it was published, and in 2022 we also certified to the cloud privacy certification, ISO 27018:2019. In 2023, we added our third Continue reading
Cloudflare thwarts over 47 million cyberthreats against Jewish and Holocaust educational websites
January 27 marks the International Holocaust Remembrance Day — a solemn occasion to honor the memory of the six million Jews who perished in the Holocaust, along with countless others who fell victim to the Nazi regime's campaign of hatred and intolerance. This tragic chapter in human history serves as a stark reminder of the catastrophic consequences of prejudice and extremism.
The United Nations General Assembly designated January 27 — the anniversary of the liberation of Auschwitz-Birkenau — as International Holocaust Remembrance Day. This year, we commemorate the 80th anniversary of the liberation of this infamous extermination camp.
As the world reflects on this dark period, a troubling resurgence of antisemitism underscores the importance of vigilance. This growing hatred has spilled into the digital realm, with cyberattacks increasingly targeting Jewish and Holocaust remembrance and educational websites — spaces dedicated to preserving historical truth and fostering awareness.
For this reason, here at Cloudflare, we began to publish annual reports covering cyberattacks that target these organizations. These cyberattacks include DDoS attacks as well as bot and application attacks. The insights and trends are based on websites protected by Cloudflare. This is our fourth report, and you can view our previous Holocaust Continue reading
How Did DeepSeek Train Its AI Model On A Lot Less – And Crippled – Hardware?
Maybe they should have called it DeepFake, or DeepState, or better still Deep Selloff. …
How Did DeepSeek Train Its AI Model On A Lot Less – And Crippled – Hardware? was written by Timothy Prickett Morgan at The Next Platform.
Running Containerlab in macOS (Cisco IOL/cEOS)

Let me start by saying that I usually run Containerlab on a dedicated Ubuntu 22.04 VM, which sits on top of Proxmox. All my labs run on this setup. However, I recently wanted to try running Containerlab directly on my MacBook (M3 Pro with 18GB of RAM) for a few reasons. For example, I might need to run labs while I’m away, work offline, or use a MacBook at work where I can’t access my home network. So, I decided to test whether I could run Cisco IOL and Arista EOS on macOS. The answer is yes, and here’s how you can do it.
As always, if you find this post helpful, press the ‘clap’ button on the left. It means a lot to me and helps me know you enjoy this type of content.
If you’re new to Containerlab and trying to understand what it is, I highly recommend checking out my introductory post, which is linked below. It covers the basics and will help you get started.
Containerlab - Creating Network Labs Can’t be Any Easier
What if I tell you that all you need is just a YAML file with just a bunch Continue reading
Tech Bytes: Unifying Cloud, On-Prem Security with Lacework FortiCNAPP (Sponsored)
CNAPP, or Cloud Native Application Protection Platform, is an integrated suite of tools for cloud-native apps that aims to help organizations manage cloud app risks and identify and respond to threats. Today on the Tech Bytes podcast we talk with sponsor Fortinet about its Lacework FortiCNAPP offering and how it integrates CNAPP for unified security... Read more »Over 700 million events/second: How we make sense of too much data
Cloudflare's network provides an enormous array of services to our customers. We collect and deliver associated data to customers in the form of event logs and aggregated analytics. As of December 2024, our data pipeline is ingesting up to 706M events per second generated by Cloudflare's services, and that represents 100x growth since our 2018 data pipeline blog post.
At peak, we are moving 107 GiB/s of compressed data, either pushing it directly to customers or subjecting it to additional queueing and batching.
All of these data streams power things like Logs, Analytics, and billing, as well as other products, such as training machine learning models for bot detection. This blog post is focused on techniques we use to efficiently and accurately deal with the high volume of data we ingest for our Analytics products. A previous blog post provides a deeper dive into the data pipeline for Logs.
The pipeline can be roughly described by the following diagram.
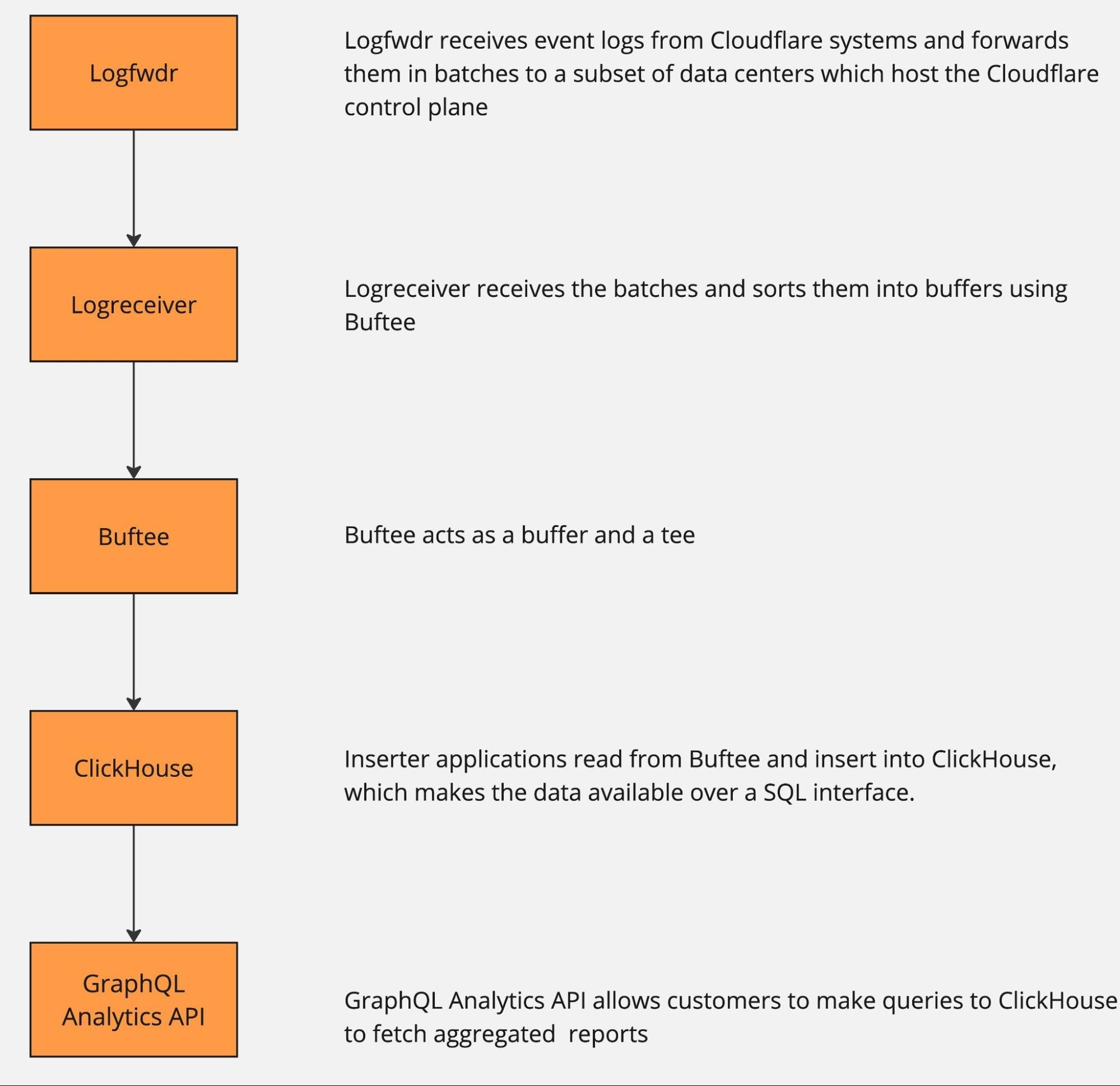
The data pipeline has multiple stages, and each can and will naturally break or slow down because of hardware failures or misconfiguration. And when that happens, there is just too much data to be able to Continue reading
Cisco VRRPv3 IPv6 Configuration Sucks
I spent way too much time ironing out the VRRPv3 quirks on the dozen (or so) platforms supported by netlab. This is the second blog post describing some of the ridiculous stuff I had to deal with.
This is how you configure the basic VRRPv3 parameters for IPv4 on a Cisco IOS/XE device:
VRRPv3 IPv4 configuration on Cisco IOS
interface GigabitEthernet0/1
vrrp 217 address-family ipv4
address 172.16.33.42
You would expect something similar for IPv6, right? You’d be right if you were working with Arista EOS:
From Python to Go 012. Processing User Input From CLI Arguments And Standard Input.
Hello my friend,
Whenever we develop any network and IT infrastructure automation applications, we need to have some options to provide user input. In previous blog posts in these series we already covered how to provide user input via environment variables and files. Whilst these two approaches can cover majority of your use cases, especially if you develop containerized applications running in autonomy, there are still two options we would like to talk today about.
Why To Bother Learning Automation?
For many years I was doing network design and operation without automating it (or at least without structured approach to automate it). And there are still loads of such job positions out there. And I see it based on the audience of my blog: majority of people here for networking knowledge, much less are for automation topics. From pure pragmatic standpoint of writing popular blogs, I should stick to network technologies, especially something fancy as SD-WAN and others. However, from the direction of the technologies development, I see that value (including jobs) comes from intersection of domains: networking, compute, storage, software development, data bases, Kubernetes, observability, etc. I’m of a strong opinion that engineers these days must be aware of Continue reading
Palo Alto How to Configure SSL Decryption?

Most websites we access today use HTTPS, and to fully leverage a Next-Generation Firewall (NGFW) like Palo Alto, inspecting encrypted HTTPS sessions is crucial. Configuring SSL decryption isn't just a set-it-and-forget-it task. It requires careful consideration and ongoing improvements. In this blog post, we'll explore how to configure SSL decryption in Palo Alto firewalls and highlight some pitfalls to be aware of. So, let's get to it.
As always, if you find this post helpful, press the ‘clap’ button on the left. It means a lot to me and helps me know you enjoy this type of content.
Palo Alto How to Block Specific URLs?
In this blog post, we’ll explore how to block specific sites using a Palo Alto firewall. There are two ways to achieve this, and we’ll cover both options.

SSL Decryption Considerations
As I mentioned earlier, configuring SSL decryption isn’t as simple as flipping a switch. Decryption allows your firewall to inspect the contents of encrypted sessions. Normally, HTTPS traffic is encrypted from your browser to the server, ensuring the sessions are private. However, with SSL decryption, the firewall acts as a man-in-the-middle, inspecting the traffic in plain text. It’s crucial Continue reading
Brad McCredie Is The Pedal To AMD’s Datacenter GPU Metal
Brad McCredie like engines, and more importantly, he likes to make them go fast. …
Brad McCredie Is The Pedal To AMD’s Datacenter GPU Metal was written by Timothy Prickett Morgan at The Next Platform.
HN765: Telecom In the Bahamas: Lessons In Resiliency
Many of us have had network design discussions relating to natural disasters. What if a fire comes through? Or a flood? For most of us, those discussions don’t feel overly worthy of our attention. Yes, we should think about it. Yes, we should plan for it. If we’re really serious, we’ll even dust off the... Read more »Hedge 256: The Impact of Your First Language
Richard Wexelblat published an article in 1980 titled: “The consequences of one’s first programming language.” We’ve all seen C code written like Python, or Python code written like C, so it’s obvious a coder’s first language has a long lasting effect on their style. What about network engineers? Are there times and places where the first of anything a network engineers encounters has a long lasting impact on the way they think and work? In this roundtable, Tom, Eyvonne, and Russ consider different ways this might apply to network engineering.