Ultra Ethernet: Network-Signaled Congestion Control (NSCC) – Overview
Network-Signaled Congestion Control (NSCC)
The Network-Signaled Congestion Control (NSCC) algorithm operates on the principle that the network fabric itself is the best source of truth regarding congestion. Rather than waiting for packet loss to occur, NSCC relies on proactive feedback from switches to adjust transmission rates in real time. The primary mechanism for this feedback is Explicit Congestion Notification (ECN) marking. When a switch interface's egress queue begins to build up, it employs a Random Early Detection (RED) logic to mark specific packets. Once the buffer’s Minimum Threshold is crossed, the switch begins randomly marking packets by setting the last two bits of the IP header’s Type of Service (ToS) field to the CE (11) state. If the congestion worsens and the Maximum Threshold is reached, every packet passing through that interface is marked, providing a clear and urgent signal to the endpoints.
The practical impact of this mechanism is best illustrated by a hash collision event, such as the one shown in Figure 6-10. In this scenario, multiple GPUs on the left-hand side of the fabric transmit data at line rate. Due to the specific entropy of these flows, the ECMP hashing algorithms on leaf switches 1A-1 and 1A-2 Continue reading
Building a serverless, post-quantum Matrix homeserver
* This post was updated at 11:45 a.m. Pacific time to clarify that the use case described here is a proof of concept and a personal project. Some sections have been updated for clarity.
Matrix is the gold standard for decentralized, end-to-end encrypted communication. It powers government messaging systems, open-source communities, and privacy-focused organizations worldwide.
For the individual developer, however, the appeal is often closer to home: bridging fragmented chat networks (like Discord and Slack) into a single inbox, or simply ensuring your conversation history lives on infrastructure you control. Functionally, Matrix operates as a decentralized, eventually consistent state machine. Instead of a central server pushing updates, homeservers exchange signed JSON events over HTTP, using a conflict resolution algorithm to merge these streams into a unified view of the room's history.
But there is a "tax" to running it. Traditionally, operating a Matrix homeserver has meant accepting a heavy operational burden. You have to provision virtual private servers (VPS), tune PostgreSQL for heavy write loads, manage Redis for caching, configure reverse proxies, and handle rotation for TLS certificates. It’s a stateful, heavy beast that demands to be fed time and money, whether you’re using it a lot Continue reading
Lab: VXLAN Bridging with EVPN Control Plane
In the previous VXLAN labs, we covered the basics of Ethernet bridging over VXLAN and a more complex scenario with multiple VLANs.
Now let’s add the EVPN control plane into the mix. The data plane (VLANs mapped into VXLAN-over-IPv4) will remain unchanged, but we’ll use EVPN (a BGP address family) to build the ingress replication lists and MAC-to-VTEP mappings.
IP Address to Organisation Name Map
The whois query tool is useful to identify which organisation holds an IP Address Prefix or an Autonomous System Number, but not so useful in performing the reverse query, listing all IP Addresses and Autonomous System Numbers held by an organisation. Here is a resource that can help with such queries.Nvidia’s $2 Billion Investment In CoreWeave Is A Drop In A $250 Billion Bucket
With the hyperscalers and the cloud builders all working on their own CPU and AI XPU designs, it is no wonder that Nvidia has been championing the neoclouds that can’t afford to try to be everything to everyone – this is the very definition of enterprise computing – and that, frankly, are having trouble coming up with the trillions of dollars to cover the 150 gigawatts to more than 200 gigawatts of datacenter capacity that is estimated to be on the books between 2025 and 2030 for AI workloads. …
Nvidia’s $2 Billion Investment In CoreWeave Is A Drop In A $250 Billion Bucket was written by Timothy Prickett Morgan at The Next Platform.
Tech Bytes: How AI Raises the Stakes for Data Protection (Sponsored)
Today on the podcast, data protection. There’s always been a tension between the need for companies to share data, whether among coworkers, partners, or customers; and the need to protect data, whether it’s for security, privacy, compliance, and so on. That tension existed before AI, but the rise of third-party and external AI tools has... Read more »NB559: Cisco Builds Nexus Switch for Intel AI Chips; TeraWave Promises 6Tbps from Space
Take a Network Break! We start with a Red Alert in Oracle’s WebLogic Server Proxy Plugin for Apache or IIS, which has a severity score of 10. In the news, Fortinet warns that attackers have found a new exploit path against previously-patched vulnerabilities, Microsoft 365 services suffered an outage, and ServiceNow inks a deal with... Read more »Nvidia Takes The Open Road In AI Weather Forecasting
Amid the myriad discussions about AI – from the astounding amount of money being spent by vendors and enterprises and the debate about actual ROI those businesses are getting to the technology’s effect on cybersecurity, jobs, and the fear of disinformation and resulting distrust – it’s easy to forget its usefulness in particular industries. …
Nvidia Takes The Open Road In AI Weather Forecasting was written by Jeffrey Burt at The Next Platform.
AI Is Coming To Solve Your System Outages
SPONSORED Your phone buzzes at 2 AM. The website is down. …
AI Is Coming To Solve Your System Outages was written by Timothy Prickett Morgan at The Next Platform.
The Heat is On

One of the things I like to do in my twenty-eight minutes of spare time per week is play Battletech. It’s a table top wargame that involves big robots and lots of weapons. Some of them are familiar, like missiles and artillery. Because it’s science fiction there are also lasers and other crazy stuff. It’s a game of resource allocation. Can my ammunition last through this fight? You might be asking yourself “why not just carry lots of lasers?” After all, they don’t need ammo. Except the game designers thought of that too. Lasers produce heat. And heat, like ammunition, must be managed. Generate too much and you will shut down. Or boil your pilot alive in the cockpit. Rewind a thousand years and the modern network in a data center is facing a similar issue.
Watt Are You Talking About?
The average AI rack is expected to consume 600 kilowatts of power by next year. GPUs and CPUs are hungry beasts. They need to be fed as much power as possible in order to do whatever math makes AI happen. They have to come up with creative ways to cool those devices as well. We’re quickly reaching the Continue reading
Cable cuts, storms, and DNS: a look at Internet disruptions in Q4 2025
In 2025, we observed over 180 Internet disruptions spurred by a variety of causes – some were brief and partial, while others were complete outages lasting for days. In the fourth quarter, we tracked only a single government-directed Internet shutdown, but multiple cable cuts wreaked havoc on connectivity in several countries. Power outages and extreme weather disrupted Internet services in multiple places, and the ongoing conflict in Ukraine impacted connectivity there as well. As always, a number of the disruptions we observed were due to technical problems – with some acknowledged by the relevant providers, while others had unknown causes. In addition, incidents at several hyperscaler cloud platforms and Cloudflare impacted the availability of websites and applications.
This post is intended as a summary overview of observed and confirmed disruptions and is not an exhaustive or complete list of issues that have occurred during the quarter. These anomalies are detected through significant deviations from expected traffic patterns observed across our network. Check out the Cloudflare Radar Outage Center for a full list of verified anomalies and confirmed outages.
The Internet was shut down in Tanzania on October 29 as violent protests took place during the country’s Continue reading
Deploy Partially-Configured Training Labs with netlab
Imagine you want to use netlab to build training labs, like the free BGP labs I created. Sometimes, you want to give students a device to work on while the other lab devices are already configured, just waiting for the students to get their job done.
My BGP labs were designed for self-study. You might also want to listen to how Sander Steffann uses netlab in classroom training.
For example, in the initial BGP lab, I didn’t want any BGP-related configuration on RTR while X1 would already be fully configured – when the student configures BGP on RTR, everything just works.
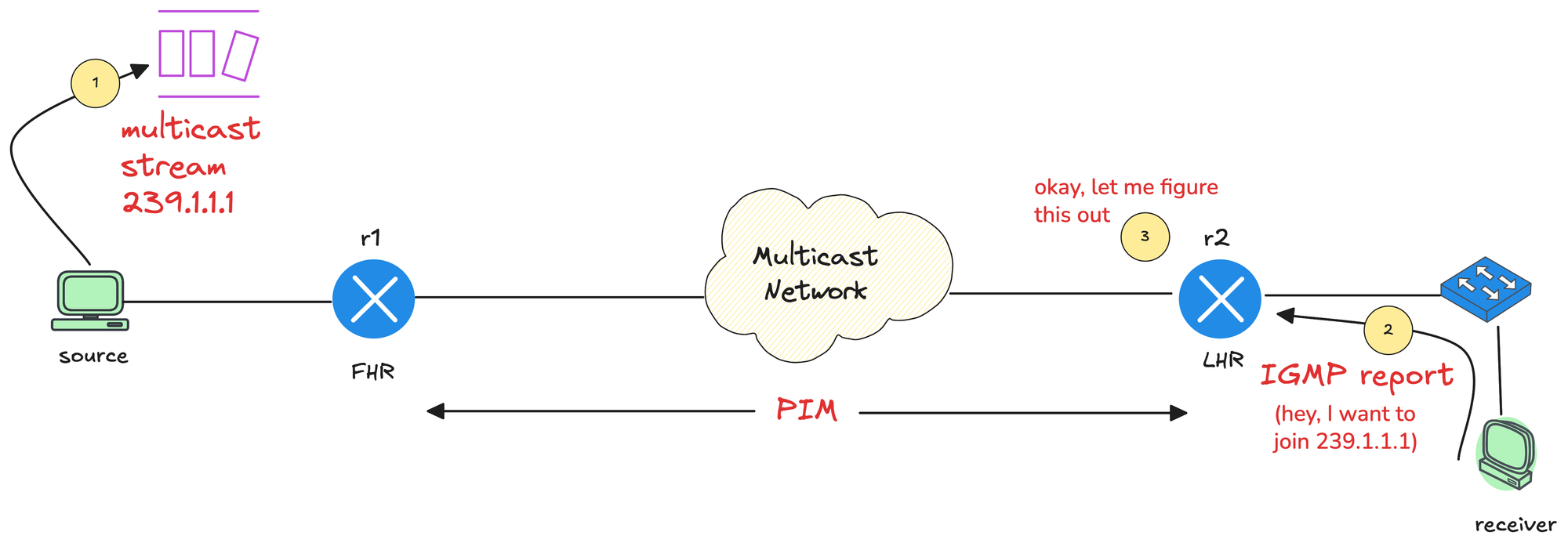
Multicast IGMP – Internet Group Management Protocol (II)

In the previous post, we covered the basics of multicast. In this post, we will focus on IGMP, Internet Group Management Protocol.
Just as a quick recap, in multicast, the source application (sender) sends multicast traffic to a multicast group address. Somewhere in the network, a receiver wants that traffic stream, so the receiver needs a way to signal that interest.
The router closest to the source is called the First Hop Router (FHR), and the router closest to the receiver is called the Last Hop Router (LHR). Between these two points, the multicast network, meaning all multicast-enabled routers, needs to build a loop-free tree that connects the sender to all interested receivers. IGMP plays a key role in making that happen.
Multicast Introduction (I)
With multicast, the source sends only a single copy of the traffic into the network. As that traffic moves through the network, it is replicated

IGMP Introduction
IGMP is the protocol used by receivers to signal their interest in multicast traffic. When a host wants to receive a multicast stream, it sends an IGMP Membership Report, also known as an IGMP join, to the multicast group address.
Multicast Introduction (I)

Multicast is one of those topics I have been meaning to learn properly for a long time. When I did my JNCIS-ENT about eight years ago, I studied multicast, but I honestly do not remember much of it now.
I recently started doing some revision and decided to write a series of blog posts as I go through it again. I want something I can come back to in the future without having to relearn everything from scratch. Hopefully, as a reader, you will also find it useful and easy to follow. If you want to learn multicast, I am going to assume you are already familiar with unicast and broadcast.
As always, if you find this post helpful, press the ‘clap’ button. It means a lot to me and helps me know you enjoy this type of content. If I get enough claps for this series, I’ll make sure to write more on this specific topic.
Unicast
Unicast is the most common method of IP communication. It is simply a one-to-one conversation between two devices. One device sends traffic, and one specific device receives it. Most of what we do on a network every day is unicast. Continue reading