Using MSSPs to Secure SD-WAN
 MSSPs can address the inherent volatility of digitally transforming the remote edges of the network.
MSSPs can address the inherent volatility of digitally transforming the remote edges of the network.
MSSPs can address the inherent volatility of digitally transforming the remote edges of the network.
Splunk wants to make machine data accessible, usable and valuable to everyone. With over 14,000 customers in 110 countries, providing the best software for visualizing machine data involves hours and hours of testing against multiple supported platforms and various configurations. For Mike Dickey, Sr. Director in charge of engineering infrastructure at Splunk, the challenge was that 13 different engineering teams in California and Shanghai had contributed to test infrastructure sprawl, with hundreds of different projects and plans that were all being managed manually.
At DockerCon Europe, Mike and Harish Jayakumar, Docker Solutions Engineer, shared how Splunk leveraged Docker Enterprise Edition (Docker EE) to dramatically improve build and deployment times on their test infrastructure, converge on a unified Continuous Integration (CI) workflow, and how they’ve now grown to 600 bare-metal servers deploying tens of thousands of Docker containers per day.
You can watch the entire session here:
As Splunk has grown, so has their customers’ use of their software. Many Splunk customers now process petabytes of data, and that has forced Splunk to scale their testing to match. That means more infrastructure needs to be reserved in the shared test environment Continue reading
Emerging technologies like AI and automation will continue to reshape IT infrastructure.
Continuing on the trend started in my previous post about OpenDaylight, I’ll move on to the next open-source product that uses BGP VPNs for optimal North-South traffic forwarding. OpenContrail is one of the most popular SDN solutions for OpenStack. It was one of the first hybrid SDN solutions, offering both pure overlay and overlay/underlay integration. It is the default SDN platform of choice for Mirantis Cloud Platform, it has multiple large-scale deployments in companies like Workday and AT&T. I, personally, don’t have any production experience with OpenContrail, however my impression, based on what I’ve heard and seen in the last 2-3 years that I’ve been following Telco SDN space, is that OpenContrail is the most mature SDN platform for Telco NFVs not least because of its unique feature set.
During the time of production deployment at AT&T, Contrail has added a lot of features required by Telco NFVs like QoS, VLAN trunking and BGP-as-a-service. My first acquaintance with BGPaaS took place when I started working on Telco DCs and I remember being genuinely shocked when I first saw the requirement for dynamic routing exchange with VNFs. To me this seemed to break one of the main rules of cloud Continue reading
In this post I’ll show how to build a dockerized OpenStack and OpenContrail lab, integrate it with Juniper MX80 DC-GW and demonstrate one of Contrail’s most interesting and unique features called BGP-as-a-Service.
Continue reading
Here we are – the first day of 2018 and Im anxious and excited to get 2018 off to a good start. Looking back – it just occurred to me that I didn’t write one of these for last year. Not sure what happened there, but Im glad to be getting back on track. So let’s start with 2017…
2017 was a great year for me. I started the year continuing my work at IBM with the Watson group. About half way through the year (I think) I was offered the opportunity to transition to a role in the Cloud Networking group. It was an opportunity I couldn’t pass up to work with folks whom I had an incredible amount of respect for. So I began the transition and within 3 months had fully transitioned to the new team. Since then, I’ve been heads down working (the reason for the lack of blog posts recently (sorry!)). But being busy at work is a good thing for me. For those of you that know me well you know that “bored Jon” is “not happy Jon” so Im in my own Continue reading
The article is the fifth of the series of the articles discussing the enterprise network configuration. The article focus on the Data Center (DC) configuration. DC consists of the two devices - Server1 and the switch vIOS-Ser-I. Of course, the DC network with a single switch and the server is far away from any known DC network design. Typically, modern horizontally scaled large-size Layer 3 DCs consist of thousands of servers connected to the Top of Rack (ToR) l3 switches and they follow leaf and spine design. The DC of this size can be hardly emulated on a single PC. For this reason I only share the configuration of the Cisco L3 switch that is located in our DC. The switch is running Cisco vIOS-L2, version 15.2 and it has assigned 768MB RAM by GNS3.
The switch vIOS-Ser-I connects Ubuntu Linux Server to DC network. The configuration of the services such as bonding, NTP, DHCP, Syslog-ng, DNS and RADIUS running on the server is explained in more details later.
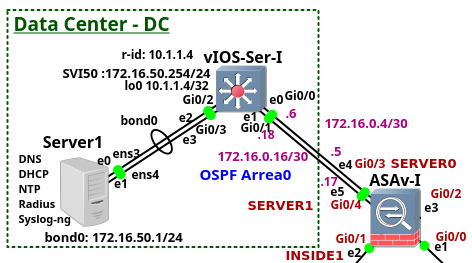
Picture 1 - Data Center
Note: The configuration file of the device vIOS-Serv-I is attached here.
1. Switch vIOS-Ser-I Configuration
Rather than explaining every line of the configuration, we Continue reading
As we start the new year, I started thinking about something. Why do people think it’s acceptable to take shortcuts in their IT career? Is it because people don’t see the true effect of their work? Or is the cheating as prevalent in law and medicine but we working in IT aren’t aware of it?
Trust me, I understand that some people live really tough lives, they want to put food on the table for their family, find a better living, perhaps start a new life in a new country. The competition is fierce. Some countries have more engineers coming out of universities every year than we have people living in Sweden.
The thing is though, if you cheat your way to a CCIE, sooner or later you will be caught. But regardless of that. How would you feel if a power plant goes down due to your mistake? Having a heart monitoring unit fail because of your mistake? Having people’s private information leaked due to your mistake? We all make mistakes but we shouldn’t be making them because we pretend that we are something that we aren’t, experts. Networking is a critical part of everyones life now. Most of Continue reading

Welcome back to a year divisible by 2! 2018 is going to be a good year through the power of positive thinking. It’s going to be a fun year for everyone. And I’m going to do my best to have fun in 2018 as well.
Per my tradition, today is a day to look at what is going to be coming in 2018. I don’t make predictions, even if I take some shots at people that do. I also try not to look back to heavily on the things I’ve done over the past year. Google and blog searches are your friend there. Likely as not, you’ve read what I wrote this year and found one or two things useful, insightful, or amusing. What I want to do is set up what the next 52 weeks are going to look like for everyone that comes to this blog to find content.
The past couple of years has shown me that the written word is starting to lose a bit of luster for content consumers. There’s been a bit push to video. Friends like Keith Townsend, Robb Boardman, and Rowell Dionicio have started making more video Continue reading
 U.S. Air Force soars to the cloud for $1B; Dell EMC bests Nutanix; Machine learning for networks.
U.S. Air Force soars to the cloud for $1B; Dell EMC bests Nutanix; Machine learning for networks.
Some New Year's resolutions are hard to keep, especially when it comes to the network.
Here’s a catalog of all the media I produced (or helped produce) in December 2017.
Here’s a catalog of all the media I produced (or helped produce) in December 2017.