AI Is Coming To Solve Your System Outages
SPONSORED Your phone buzzes at 2 AM. The website is down. …
AI Is Coming To Solve Your System Outages was written by Timothy Prickett Morgan at The Next Platform.
The Heat is On

One of the things I like to do in my twenty-eight minutes of spare time per week is play Battletech. It’s a table top wargame that involves big robots and lots of weapons. Some of them are familiar, like missiles and artillery. Because it’s science fiction there are also lasers and other crazy stuff. It’s a game of resource allocation. Can my ammunition last through this fight? You might be asking yourself “why not just carry lots of lasers?” After all, they don’t need ammo. Except the game designers thought of that too. Lasers produce heat. And heat, like ammunition, must be managed. Generate too much and you will shut down. Or boil your pilot alive in the cockpit. Rewind a thousand years and the modern network in a data center is facing a similar issue.
Watt Are You Talking About?
The average AI rack is expected to consume 600 kilowatts of power by next year. GPUs and CPUs are hungry beasts. They need to be fed as much power as possible in order to do whatever math makes AI happen. They have to come up with creative ways to cool those devices as well. We’re quickly reaching the Continue reading
Cable cuts, storms, and DNS: a look at Internet disruptions in Q4 2025
In 2025, we observed over 180 Internet disruptions spurred by a variety of causes – some were brief and partial, while others were complete outages lasting for days. In the fourth quarter, we tracked only a single government-directed Internet shutdown, but multiple cable cuts wreaked havoc on connectivity in several countries. Power outages and extreme weather disrupted Internet services in multiple places, and the ongoing conflict in Ukraine impacted connectivity there as well. As always, a number of the disruptions we observed were due to technical problems – with some acknowledged by the relevant providers, while others had unknown causes. In addition, incidents at several hyperscaler cloud platforms and Cloudflare impacted the availability of websites and applications.
This post is intended as a summary overview of observed and confirmed disruptions and is not an exhaustive or complete list of issues that have occurred during the quarter. These anomalies are detected through significant deviations from expected traffic patterns observed across our network. Check out the Cloudflare Radar Outage Center for a full list of verified anomalies and confirmed outages.
The Internet was shut down in Tanzania on October 29 as violent protests took place during the country’s Continue reading
Deploy Partially-Configured Training Labs with netlab
Imagine you want to use netlab to build training labs, like the free BGP labs I created. Sometimes, you want to give students a device to work on while the other lab devices are already configured, just waiting for the students to get their job done.
For example, in the initial BGP lab, I didn’t want any BGP-related configuration on RTR while X1 would already be fully configured – when the student configures BGP on RTR, everything just works.
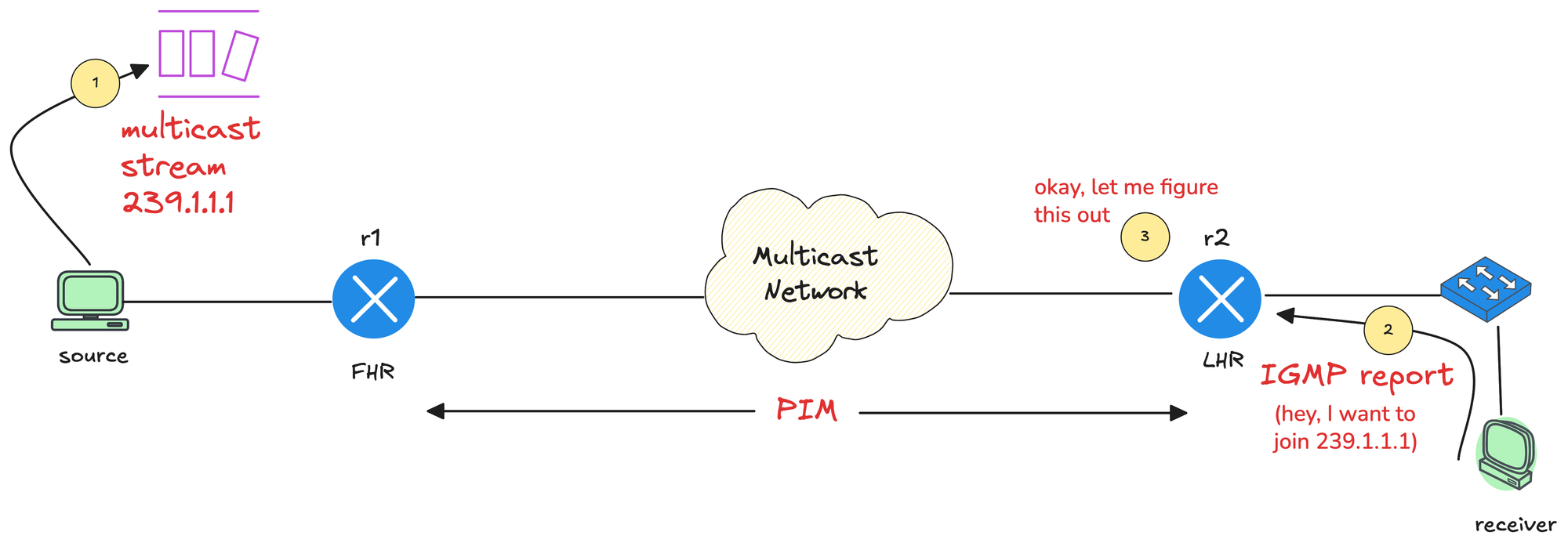
Multicast IGMP – Internet Group Management Protocol (II)

In the previous post, we covered the basics of multicast. In this post, we will focus on IGMP, Internet Group Management Protocol.
Just as a quick recap, in multicast, the source application (sender) sends multicast traffic to a multicast group address. Somewhere in the network, a receiver wants that traffic stream, so the receiver needs a way to signal that interest.
The router closest to the source is called the First Hop Router (FHR), and the router closest to the receiver is called the Last Hop Router (LHR). Between these two points, the multicast network, meaning all multicast-enabled routers, needs to build a loop-free tree that connects the sender to all interested receivers. IGMP plays a key role in making that happen.

IGMP Introduction
IGMP is the protocol used by receivers to signal their interest in multicast traffic. When a host wants to receive a multicast stream, it sends an IGMP Membership Report, also known as an IGMP join, to the multicast group address.
Multicast Introduction (I)

Multicast is one of those topics I have been meaning to learn properly for a long time. When I did my JNCIS-ENT about eight years ago, I studied multicast, but I honestly do not remember much of it now.
I recently started doing some revision and decided to write a series of blog posts as I go through it again. I want something I can come back to in the future without having to relearn everything from scratch. Hopefully, as a reader, you will also find it useful and easy to follow. If you want to learn multicast, I am going to assume you are already familiar with unicast and broadcast.
As always, if you find this post helpful, press the ‘clap’ button. It means a lot to me and helps me know you enjoy this type of content. If I get enough claps for this series, I’ll make sure to write more on this specific topic.
Unicast
Unicast is the most common method of IP communication. It is simply a one-to-one conversation between two devices. One device sends traffic, and one specific device receives it. Most of what we do on a network every day is unicast. Continue reading
Intel Is Still Struggling In The Datacenter, But It Could Get Better
Intel has been pushing its two-core server CPU strategy for so long, in one form or another, that we have become accustomed to differentiating products the way Intel does and then try to figure out what workloads these chips might be useful for. …
Intel Is Still Struggling In The Datacenter, But It Could Get Better was written by Timothy Prickett Morgan at The Next Platform.
HN811: What AI Startups Get Wrong
What is the real-world impact of AI on network operations? Drew and Ethan have a chat with Carlos Pignataro, Founder & Principal at Blue Fern Consulting, to cut through the AI hype machine. Carlos offers a thoughtful, balanced take on where the industry is headed, and where it’s missing the mark. Together they discuss Intent-Based... Read more »Hedge 293: Moore’s Law
Is there an interaction between Moore’s Law and network computing? If so, what is the relationship? How do advances in silicon capabilities and network speeds and feeds rely and drive one another. Geoff Huston joins Russ on this episode of the Hedge to look at a bit of the history.
download
Route leak incident on January 22, 2026
On January 22, 2026, an automated routing policy configuration error caused us to leak some Border Gateway Protocol (BGP) prefixes unintentionally from a router at our data center in Miami, Florida. While the route leak caused some impact to Cloudflare customers, multiple external parties were also affected because their traffic was accidentally funnelled through our Miami data center location.
The route leak lasted 25 minutes, causing congestion on some of our backbone infrastructure in Miami, elevated loss for some Cloudflare customer traffic, and higher latency for traffic across these links. Additionally, some traffic was discarded by firewall filters on our routers that are designed to only accept traffic for Cloudflare services and our customers.
While we’ve written about route leaks before, we rarely find ourselves causing them. This route leak was the result of an accidental misconfiguration on a router in Cloudflare’s network, and only affected IPv6 traffic. We sincerely apologize to the users, customers, and networks we impacted yesterday as a result of this BGP route leak.
We have written multiple times about BGP route leaks, and we even record route leak events on Cloudflare Radar for anyone to view and learn from. To get Continue reading
MUST WATCH: BGP: the First 18 Years
If you’re at all interested in the history of networking, you simply MUST watch the BGP at 18: Lessons In Protocol Design lecture by Dr. Yakov Rekhter recorded in 2007 (as you can probably guess from the awful video quality) (HT: Berislav Todorovic via LinkedIn).
Meta Platforms Metamorphizing Into An AI Cloud For Sovereigns
Meta Platforms is not happy just being the social network for the world anymore. …
Meta Platforms Metamorphizing Into An AI Cloud For Sovereigns was written by Timothy Prickett Morgan at The Next Platform.
IPB192: IPv6 Lab Update
Thinking of setting up an IPv6 lab this year? Our hosts dive into a major update on building and testing modern IPv6 networks, focusing on the game-changing “IPv6-mostly” architecture. They break down the essential components you need to get this working, including DHCP Option 108 and the nitty gritty of client support. In this episode,... Read more »Ingress Security for AI Workloads in Kubernetes: Protecting AI Endpoints with WAF
AI Workloads Have a New Front Door
For years, AI and machine learning workloads lived in the lab. They ran as internal experiments, batch jobs in isolated clusters, or offline data pipelines. Security focused on internal access controls and protecting the data perimeter.
That model no longer holds.
Today, AI models are increasingly part of production traffic, which is driving new challenges around securing AI workloads in Kubernetes. Whether serving a large language model for a customer-facing chatbot or a computer vision model for real-time analysis, these models are exposed through APIs, typically REST or gRPC, running as microservices in Kubernetes.
From a platform engineering perspective, these AI inference endpoints are now Tier 1 services. They sit alongside login APIs and payment gateways in terms of criticality, but they introduce a different and more expensive risk profile than traditional web applications. For AI inference endpoints, ingress security increasingly means Layer 7 inspection and WAF (Web Application Firewall) level controls at the cluster edge. By analyzing the full request payload, a WAF can detect and block abusive or malicious traffic before it ever reaches expensive GPU resources or sensitive data. This sets the stage for protecting AI workloads from both operational Continue reading
N4N047: Virtual Router Redundancy Protocol (VRRP)
Go beyond the basics to understand the mechanics that keep your default gateway from becoming a single point of failure. Ethan and Holly demystify Virtual Router Redundancy Protocol (VRRP), which helps provide network redundancy. They break down everything from the VRRP election protocol to the protocol’s unique communication methods. They also look back at previous... Read more »Why Doesn’t netlab Use X for Device Configuration Templates?
Petr Ankudinov made an interesting remark when I complained about how much time I wasted waiting for Cisco 8000v to boot when developing netlab device configuration templates:
For Arista part - just use AVD with all templates included and ANTA for testing. I was always wondering why netlab is not doing that.
Like any other decent network automation platform, netlab uses a high-level data model (lab topology) to describe the network. That data model is then transformed into a device-level data model, and the device-level data structures are used to generate device configurations.