The GDPR’s new ally
SPONSORED FEATURE: A convergence of cutting-edge technology, generative AI and advanced server infrastructure has unleashed a wave of innovation in the realm of cyber security. …
The post The GDPR’s new ally first appeared on The Next Platform.
The GDPR’s new ally was written by Martin Courtney at The Next Platform.
Open BGP Daemons: There’s So Many of Them
A while ago, the Networking Notes blog published a link to my “Will Network Devices Reject BGP Sessions from Unknown Sources?” blog post with a hint: use Shodan to find how many BGP routers accept a TCP session from anyone on the Internet.
The results are appalling: you can open a TCP session on port 179 with over 3 million IP addresses.
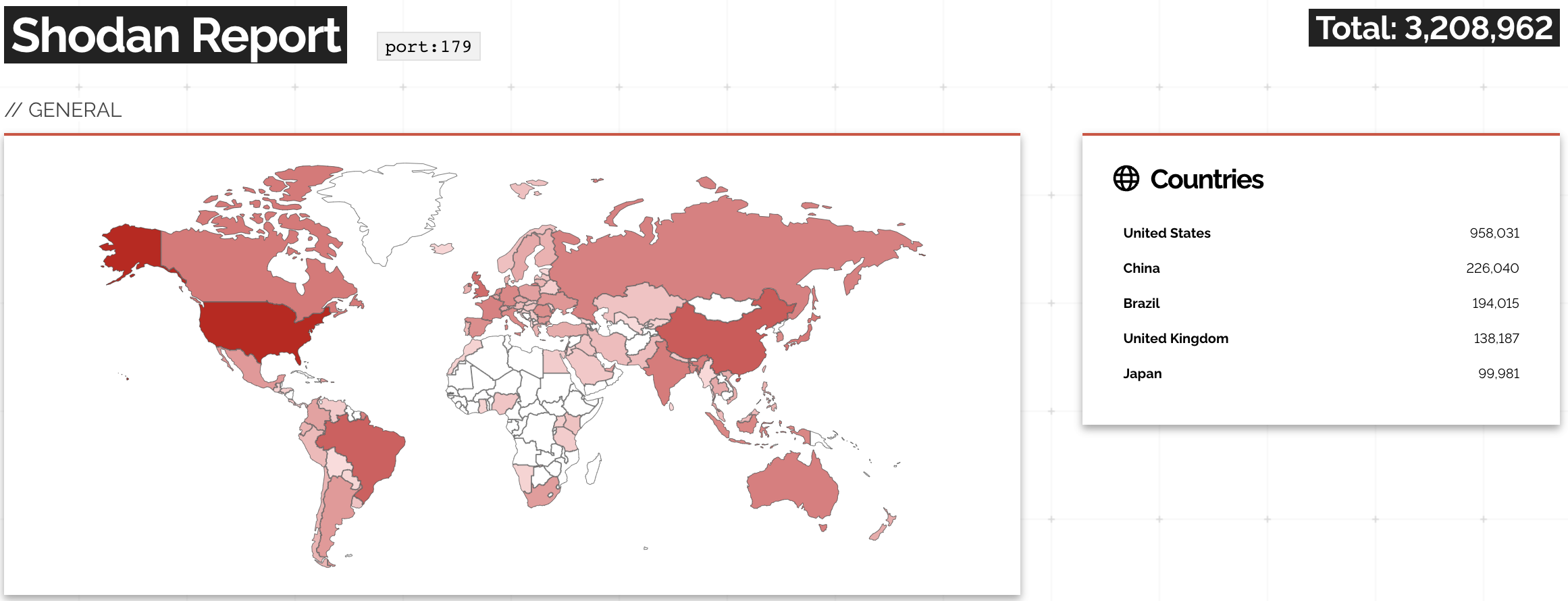
A report on Shodan opening TCP session to port 179
Open BGP Daemons: There’s So Many of Them
A while ago, the Networking Notes blog published a link to my “Will Network Devices Reject BGP Sessions from Unknown Sources?” blog post with a hint: use Shodan to find how many BGP routers accept a TCP session from anyone on the Internet.
The results are appalling: you can open a TCP session on port 179 with over 3 million IP addresses.
A report on Shodan opening TCP session to port 179
MPLS TE Deadlock
The post MPLS TE Deadlock appeared first on Noction.
Ventana Launches Veyron V2 RISC-V Into The Datacenter
It took the X86 architecture fifteen years get an appreciable share of datacenter compute, and it took the Arm architecture about ten years to get a foothold you could measure. …
The post Ventana Launches Veyron V2 RISC-V Into The Datacenter first appeared on The Next Platform.
Ventana Launches Veyron V2 RISC-V Into The Datacenter was written by Timothy Prickett Morgan at The Next Platform.
AI Is Making Data Cost Too Much

You may recall that I wrote a piece almost six years ago comparing big data to nuclear power. Part of the purpose of that piece was to knock the wind out of the “data is oil” comparisons that were so popular. Today’s landscape is totally different now thanks to the shifts that the IT industry has undergone in the past few years. I now believe that AI is going to cause a massive amount of wealth transfer away from the AI companies and cause startup economics to shift.
Can AI Really Work for Enterprises?
In this episode of Packet Pushers, Greg Ferro and Brad Casemore debate a lot of topics around the future of networking. One of the things that Brad brought up that Greg pointed out is that data being used for AI algorithm training is being stored in the cloud. That massive amount of data is sitting there waiting to be used between training runs and it’s costing some AI startups a fortune in cloud costs.
AI algorithms need to be trained to be useful. When someone uses ChatGPT to write a term paper or ask nonsensical questions you’re using the output of the GPT training run. Continue reading
How Data Center Infrastructures Must Change to Support AI
How are enterprises big and small adapting their data center infrastructure to handle AI workloads?5 use cases for automating your infrastructure with Ansible Automation Platform
Infrastructure automation is an area where systems administrators and IT operations teams can see some of the biggest benefits from automation, including time savings, reducing tedious manual work, and improving the overall health of their systems. In this blog, I've identified the top 5 infrastructure automation use cases for Ansible Automation Platform that you can deploy in your own environment, and I've incorporated new capabilities like Event-Driven Ansible to make managing your infrastructure even easier.
- Provisioning Red Hat Enterprise Linux with Ansible Automation Platform
Before you get started with any automation project, we typically recommend using automation analytics to plan and predict the potential cost savings to help prioritize which automation projects will deliver the biggest time and cost savings.
Then you can use Ansible Automation Platform to create a workflow to build or configure a cloud or datacenter instance for RHEL, while using surveys to gather additional user input to enable further customization to meet any system requirements. You can even introduce an IT service management ticketing option, then review the job success and confirm service availability.
Watch this video to see it in action:
- Managing Configuration and Drift with Ansible Automation Platform
Ongoing Continue reading
Understanding the Role of the Network in Sustainability
Extreme Networks is embracing a multi-pronged sustainability strategy to achieve its environmental objectives for the company itself and its networking solutions.Rapid Progress in BGP Route Origin Validation
In 2022, I was invited to speak about Internet routing security at the DEEP conference in Zadar, Croatia. One of the main messages of the presentation was how slow the progress had been even though we had had all the tools available for at least a decade (RFC 7454 was finally published in 2015, and we started writing it in early 2012).
At about that same time, a small group of network operators started cooperating on improving the security and resilience of global routing, eventually resulting in the MANRS initiative – a great place to get an overview of how many Internet Service Providers care about adopting Internet routing security mechanisms.
Rapid Progress in BGP Route Origin Validation
In 2022, I was invited to speak about Internet routing security at the DEEP conference in Zadar, Croatia. One of the main messages of the presentation was how slow the progress had been even though we had had all the tools available for at least a decade (RFC 7454 was finally published in 2015, and we started writing it in early 2012).
At about that same time, a small group of network operators started cooperating on improving the security and resilience of global routing, eventually resulting in the MANRS initiative – a great place to get an overview of how many Internet Service Providers care about adopting Internet routing security mechanisms.

Getting Aggressive with Cloud Cybersecurity
Cloud cybersecurity should be addressed proactively in order to detect lurking vulnerabilities before threat actors can attack. Here’s what IT leaders need to know to get the upper hand on cloud cybersecurity.Big Blue Can Still Catch The AI Wave If It Hurries
It has been two and a half decades since we have seen a rapidly expanding universe of a new kind of compute that rivals the current generative AI boom. …
The post Big Blue Can Still Catch The AI Wave If It Hurries first appeared on The Next Platform.
Big Blue Can Still Catch The AI Wave If It Hurries was written by Timothy Prickett Morgan at The Next Platform.
Tech Bytes: How VMware And HPE Greenlake Tackle AI And Multi-Cloud For Customers (Sponsored)
On today’s Packet Pusher’s Tech Bytes podcast, sponsored by VMware, the conversation delves into HPE’s partnership with VMware, particularly around HPE Greenlake for VMware Cloud Foundation. HPE was recently recognized as VMware’s 2023 partner of the year. Today’s podcast features an interview with Frances Guida, Director, Compute Workload Solutions Product Management at HPE. The podcast... Read more »Tech Bytes: How VMware And HPE Greenlake Tackle AI And Multi-Cloud For Customers (Sponsored)
VMware and HPE are partnering on HPE Greenlake for VMware Cloud Foundation. On today's episode we discuss how the HPE and VMware partnership benefits customers’ multi-cloud initiatives and how VMware and HPE Greenlake can help customers take advantage of AI by providing scalable hardware and software infrastructure for training and inference. VMware is our sponsor.
The post Tech Bytes: How VMware And HPE Greenlake Tackle AI And Multi-Cloud For Customers (Sponsored) appeared first on Packet Pushers.
NB454: Is Bad InfoSec Now Securities Fraud?
We discuss potential repercussions for security executives after the SEC charges Solar Winds’ CISCO with fraud, examine a new SD-LAN offering from Versa Networks that aims to integrate security controls into a campus fabric, and discuss a new open-source tool from Cloudflare for scrubbing sensitive authentication tokens from HAR files. Extreme Networks posts strong revenues... Read more »NB454: Is Bad InfoSec Now Securities Fraud?
On today's Network Break we discuss potential repercussions for security executives after the SEC charges Solar Winds' CISCO with fraud, examine a new SD-LAN offering from Versa Networks that aims to integrate security controls into a campus fabric, and look at a new open-source tool from Cloudflare for scrubbing sensitive authentication tokens from HAR files.
The post NB454: Is Bad InfoSec Now Securities Fraud? appeared first on Packet Pushers.