Day Two Cloud 189: The Cloud Network Engineer Career Path With Kam Agahian
Today on Day Two Cloud we explore what it takes to transition from traditional networking to a career as a cloud network engineer. Guest Kam Agahian shares insights from his own career journey about what's the same and what's different between on-prem and cloud networking, what skills might you want to pick up to make the transition, recommended certifications, and more.
The post Day Two Cloud 189: The Cloud Network Engineer Career Path With Kam Agahian appeared first on Packet Pushers.
Why AI Inference Will Remain Largely On The CPU
Sponsored Feature: Training an AI model takes an enormous amount of compute capacity coupled with high bandwidth memory. …
Why AI Inference Will Remain Largely On The CPU was written by Martin Courtney at The Next Platform.
Introducing Calico Runtime Threat Defense—The most extensive security coverage for containers and Kubernetes
Containerized applications are complex, which is why an effective container security strategy is difficult to design and execute. As digitalization continues to push applications and services to the cloud, bad actors’ attack techniques have also become more sophisticated, which further challenges container security solutions available on the market.
Despite the discussion around agent vs agentless in the cloud security landscape and which type of solution is better, the most valuable solution is one that provides a wide breadth of coverage. Calico is unique as it is already installed as part of the underlying platform and provides the dataplane for a Kubernetes cluster. When Calico Cloud or Calico Enterprise is deployed, security and observability capabilities can be enabled on top of these core components. We provide a simple plug-and-play active security solution that focuses on securing workloads and the Kubernetes platform with the least amount of complexity and configuration.
Runtime attack vectors
Cloud-native applications are susceptible to many attack vectors. We have broken them down to eight, as seen in the following illustration:

In previous blogs, we have explained how the use of vulnerability management, zero-trust workload security, and microsegmentation can help reduce the Continue reading
New: High Availability Clusters in Networking
Years ago I loved ranting about the stupidities of building stretched VLANs to run high-availability network services clusters with two nodes (be it firewalls, load balancers, or data center switches with centralized control plane) across multiple sites.
I collected pointers to those blog posts and other ipSpace.net HA cluster resources on the new High Availability Service Clusters page.
New: High Availability Clusters in Networking
Years ago I loved ranting about the stupidities of building stretched VLANs to run high-availability network services clusters with two nodes (be it firewalls, load balancers, or data center switches with centralized control plane) across multiple sites.
I collected pointers to those blog posts and other ipSpace.net HA cluster resources on the new High Availability Service Clusters page.
Avoiding the Risks of Unmanaged Networks
Enterprises can reduce their risks from unmanaged networks by gaining visibility to the complete network path that delivers their users' experiences.RISC-V In The Datacenter Is No Risky Proposition
It was only a matter of time, perhaps, but the skyrocketing costs of designing chips is colliding with the ever-increasing need for performance, price/performance, and performance per watt. …
RISC-V In The Datacenter Is No Risky Proposition was written by Timothy Prickett Morgan at The Next Platform.
Cloudflare’s view of the Virgin Media outage in the UK
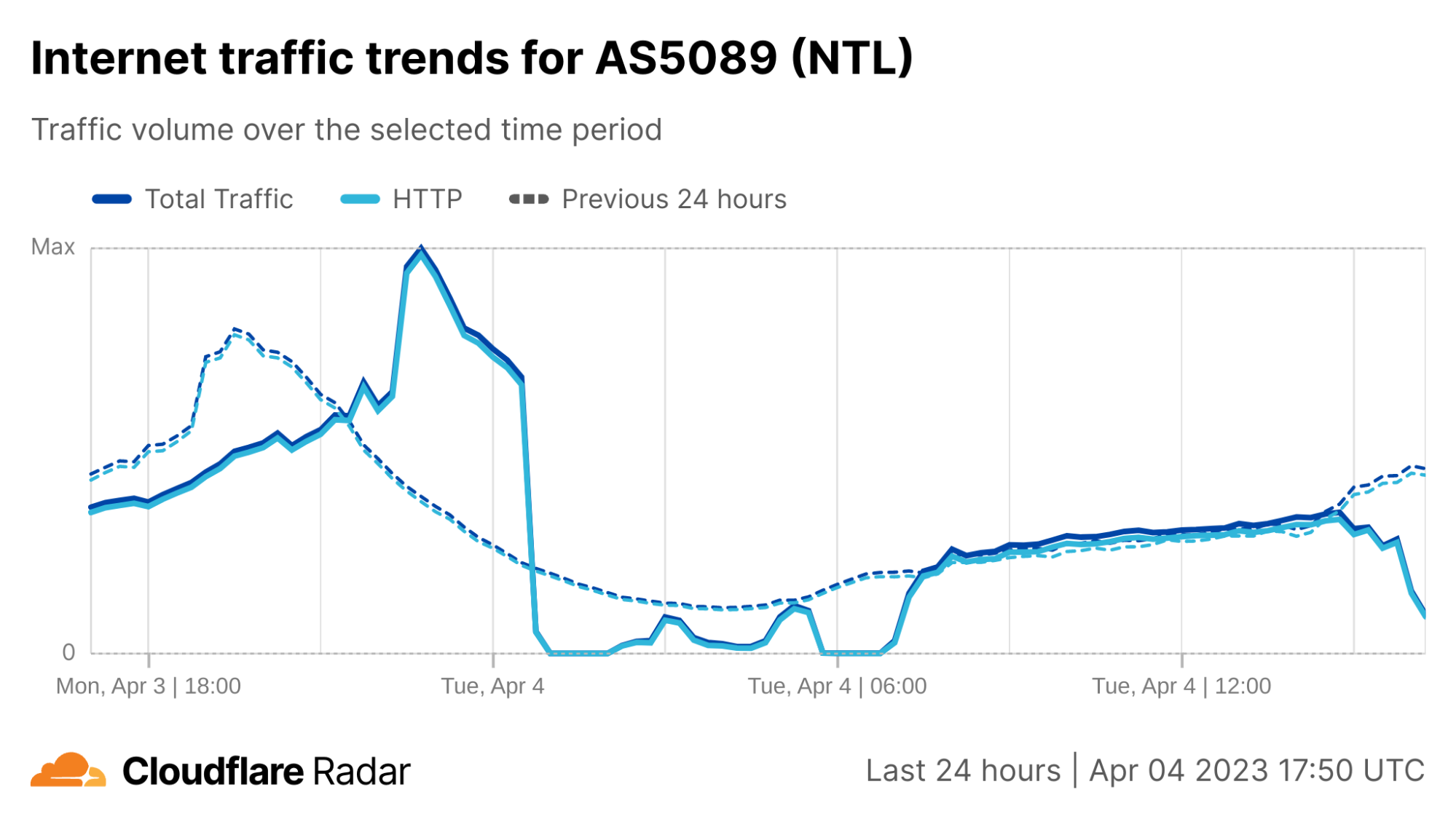
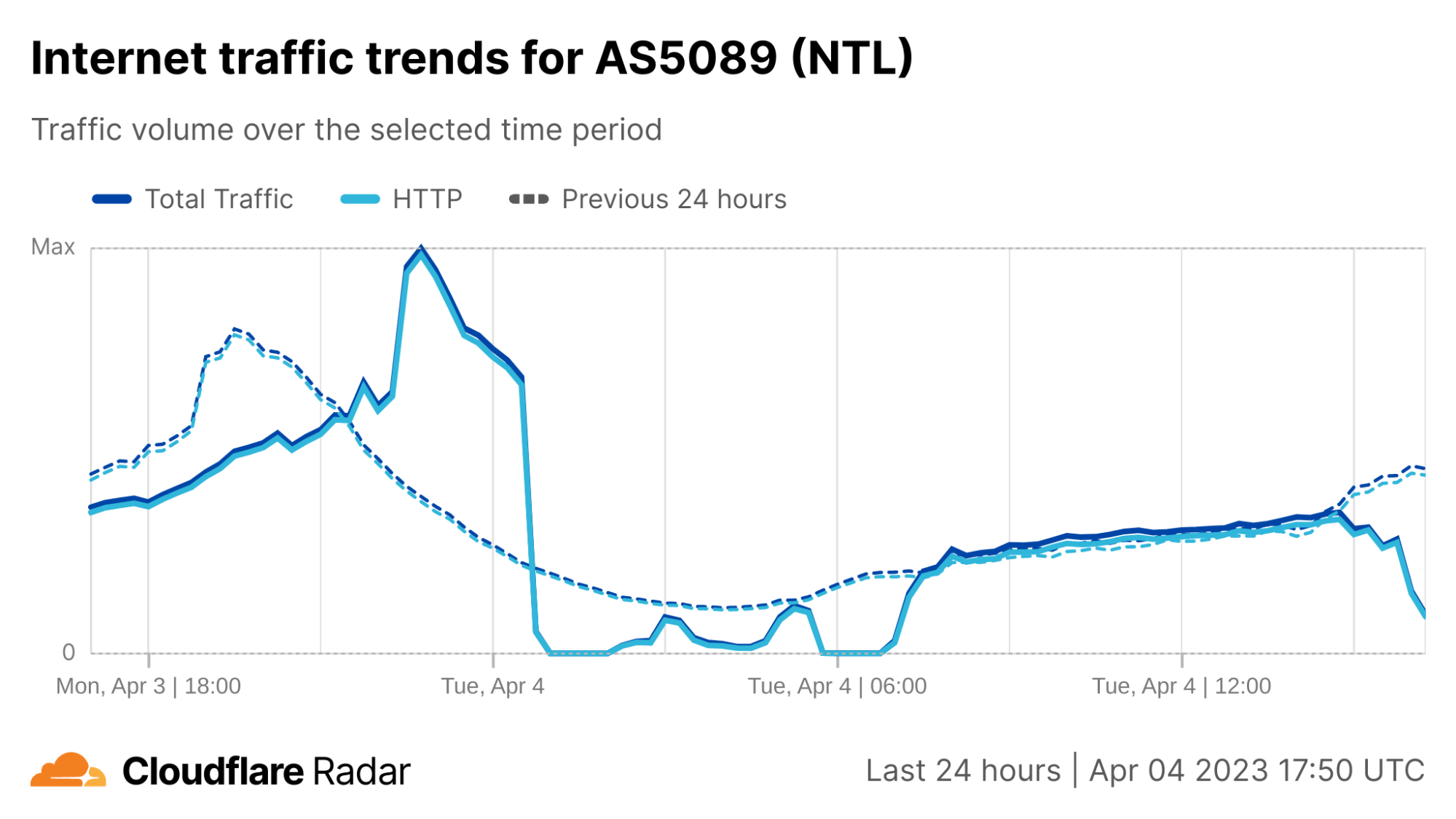
Just after midnight (UTC) on April 4, subscribers to UK ISP Virgin Media (AS5089) began experiencing an Internet outage, with subscriber complaints multiplying rapidly on platforms including Twitter and Reddit.
Cloudflare Radar data shows Virgin Media traffic dropping to near-zero around 00:30 UTC, as seen in the figure below. Connectivity showed some signs of recovery around 02:30 UTC, but fell again an hour later. Further nominal recovery was seen around 04:45 UTC, before again experiencing another complete outage between around 05:45-06:45 UTC, after which traffic began to recover, reaching expected levels around 07:30 UTC.
After the initial set of early-morning disruptions, Virgin Media experienced another round of issues in the afternoon. Cloudflare observed instability in traffic from Virgin Media’s network (called an autonomous system in Internet jargon) AS5089 starting around 15:00 UTC, with a significant drop just before 16:00 UTC. However in this case, it did not appear to be a complete outage, with traffic recovering approximately a half hour later.
Virgin Media’s Twitter account acknowledged the early morning disruption several hours after it began, posting responses stating “We’re aware of an issue that is affecting broadband services for Virgin Media customers as well as our contact centres. Our teams Continue reading
4 Ways to Prevent Data Loss In the Cloud
For businesses to maximize cloud’s potential and use it efficiently for data management, they will have to take data protection seriously.HPE Converges 3PAR Block And Vast Data File Onto One Alletra MP Platform
If incumbent storage suppliers want to have a business in the hybrid cloud world, they have to find ways to erase the line between what’s in the cloud and what’s on-premises – and increasingly what’s at the edge. …
HPE Converges 3PAR Block And Vast Data File Onto One Alletra MP Platform was written by Jeffrey Burt at The Next Platform.
The Most Complex Chip Ever Made?
Historically Intel put all its cumulative chip knowledge to work advancing Moore’s Law and applying those learnings to its future CPUs. …
The Most Complex Chip Ever Made? was written by Timothy Prickett Morgan at The Next Platform.
Real-time flow analytics on VyOS

vyos@vyos:~$ add container image sflow/ddos-protectFirst, download the sflow/ddos-protect image.
vyos@vyos:~$ mkdir -m 777 /config/sflow-rtCreate a directory to store persistent container state.
set container name sflow-rt image sflow/ddos-protect set container name sflow-rt allow-host-networks set container name sflow-rt arguments '-Dhttp.hostname=10.0.0.240' set container name sflow-rt environment RTMEM value 200M set container name sflow-rt memory 0 set container name sflow-rt volume store source /config/sflow-rt set container name sflow-rt volume store destination /sflow-rt/storeConfigure a container to run the image. The RMEM environment variable setting limits the amount of memory that the container will use to 200M bytes. The -Dhttp.hostname argument sets the internal web server to listen on management address, 10.0.0.240, assigned to eth0 on this router. The container has is no built-in authentication, so access needs to be limited using an ACL or through a reverse proxy - see Download and install.
set system sflow interface eth0 set system sflow interface eth1 set system sflow interface Continue reading
What’s New: Cloud Automation with amazon.cloud 0.3.0

Last year, we made available an experimental alpha Ansible Content Collection of generated modules using the AWS Cloud Control API to interact with AWS services. Although the Collection is not intended for production, we are constantly trying to improve and extend its functionality and achieve its supportability in the future.
In this blog post, we will go over what else has changed and highlight what’s new in the 0.3.0 release of this Ansible Content Collection.
Forward-looking Changes
Much of our work in release 0.3.0 focused on releasing several new enhancements, clarifying supportability policies, and extending the automation umbrella by generating new modules. Let’s deep dive into it!
New boto3/botocore Versioning
The amazon.cloud Collection has dropped support for botocore<1.28.0 and boto3<1.25.0. Most modules will continue to work with older versions of the AWS Software Development Kit (SDK), however, compatibility with older versions of the AWS SDK is not guaranteed and will not be tested.
New Ansible Support Policy
This Collection release drops support for ansible-core<2.11. In particular, Ansible Core 2.10 and Ansible 2.9 are not supported. For more information, visit Ansible release documentation.