5 Essential Steps to Strengthen Kubernetes Egress Security
Securing what comes into your Kubernetes cluster often gets top billing. But what leaves your cluster, outbound or egress traffic, can be just as risky. A single compromised pod can exfiltrate data, connect to malicious servers, or propagate threats across your network. Without proper egress controls, workloads can reach untrusted destinations, creating serious security and compliance risks. This guide breaks down five practical steps to strengthen Kubernetes egress security, helping teams protect data, enforce policies, and maintain visibility across clusters.
Why Egress Controls Matter
|

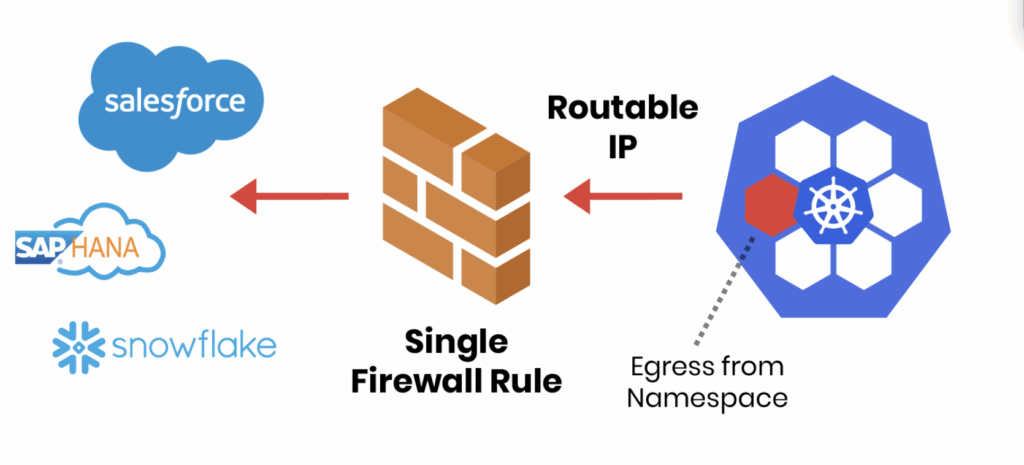
Your Kubernetes Egress Security Checklist
To help teams tackle this challenge, we’ve put together a Kubernetes Egress Security Checklist, based on best practices from real-world Continue reading


 which brings a wave of new features and improvements.
which brings a wave of new features and improvements.