PP068: Common Kubernetes Risks and What to Do About Them
Today’s Packet Protector digs into risks and threats you might encounter in a Kubernetes environment, what to do about them, and why sometimes a paved path (or boring technology) is the smartest option. My guest is Natalie Somersall, Principal Solutions Engineer for the Public Sector at Chainguard. We talk about risks including identity and access... Read more »Containers are available in public beta for simple, global, and programmable compute
We’re excited to announce that Cloudflare Containers are now available in beta for all users on paid plans.
You can now run new kinds of applications alongside your Workers. From media and data processing at the edge, to backend services in any language, to CLI tools in batch workloads — Containers open up a world of possibilities.
Containers are tightly integrated with Workers and the rest of the developer platform, which means that:
Your workflow stays simple: just define a Container in a few lines of code, and run
wrangler deploy, just like you would with a Worker.Containers are global: as with Workers, you just deploy to Region:Earth. No need to manage configs across 5 different regions for a global app.
You can use the right tool for the job: routing requests between Workers and Containers is easy. Use a Worker when you need to be ultra light-weight and scalable. Use a Container when you need more power and flexibility.
Containers are programmable: container instances are spun up on-demand and controlled by Workers code. If you need custom logic, just write some JavaScript instead of spending time chaining together API calls or writing Kubernetes operators.
HW055: Improving Wireless Design With AI
AI is already widely used for wireless network operations. On today’s show, we look at how AI and machine learning are also being applied to wireless design and site surveys. My guest is Jussi Kiviniemi, Founder and CEO of Hamina Wireless. We talk about how Hamina is developing and implementing AI tools to help designers... Read more »Ossification and the Internet
The Internet was deliberately designed as a simple common substrate packet-switched network that could be able to support a huge variety of digital service profiles. The Internet's service profile was defined in the connecting devices at the edge, and not in the switching equipment in the middle of the network. The network model was intentionally so sparse that it was incapable of becoming ossified! How's that turned out?Quality of OSPFv2 NSSA Implementations
A few weeks ago, we added OSPF areas functionality to netlab. In the next release1, you’ll be able to configure stub areas, NSSA areas, inter-area route summarization and filtering (OSPF ranges), and summarization of NSSA type-7 prefixes for OSPFv2 and OSPFv3.
OSPFv2 (defined in RFC 2328) is 27 years old, and NSSA functionality (RFC 3101) was last touched 22 years ago. One would hope the implementations in network devices are mature and feature-complete. Yeah, keep dreaming 🤦♂️.
Autopilot, Muse, Co-author, Editor. How do you use GenAI?
Thoughts on how to use Generative A.I. to write.
If you are not using a GenAI tool, like ChatGPT, you know someone that does.
And you've definitely read hundreds of LinkedIn posts that were entirely written by GenAI.
Did you notice that your colleague who used to write a short update like:
'Met with team for the quarterly review & cupcakes! #yum #teamwork #rockstars #cake'
Suddenly, they seemed to become much more ebullient and flowery in their words, emotional range, and emoji use?
And now, without fail, every post must have a final motivational message to stir the heart (and the Like button).
👩⚖️ Exhibit A:

Yes, that post was written without any input from me, no prompting of what the post should contain other than:
Write a LinkedIn post about a meeting
That's it. That's the prompt!
And you don't even need to go that far!
Why waste your words and typing fingers, just go for it super-brief with:
LinkedIn post for today
And...here it is:

With those few words I've got a pretty inspiring response.
- It's got the earnest, open tone.
- The bland relatable work-bound troubles: 'blockers' everyone!
- Hope for the future: 'moving in the right Continue reading
AWS Security Groups, NACL and ENI

This is the third blog post in the AWS Networking series. If you have been following along, you can continue with the lab we have built so far. For anyone who has just landed on this page, you can still follow along as long as you are already familiar with the basics of AWS networking. If you are completely new, however, I highly recommend checking out the introductory posts linked below to get up to speed.
In this blog post, we will look at AWS Security Groups, Network ACL (NACL) and Elastic Network Interfaces (ENI).
AWS Networking Fundamentals
If you’re brand new to AWS, don’t worry. This post focuses on the basics of AWS networking. General networking knowledge is helpful but not required - I’ll try to explain things clearly so everyone can follow along.

AWS NAT Gateway and Private/Public Subnets
When working with AWS networking, you will often hear the terms ‘public subnet’ and ‘private subnet’. However, if you go into the AWS console to create a subnet, you won’t find any option to explicitly make it one or the other.

AWS Security Groups
So far, we have briefly touched on Security Continue reading
Nvidia Passes Cisco And Rivals Arista In Datacenter Ethernet Sales
There is not one Ethernet business, but several, and now, with the evolution of Ethernet switches for back-end AI cluster networks, there is a new one that has the possibility to dominate revenues and profits. …
Nvidia Passes Cisco And Rivals Arista In Datacenter Ethernet Sales was written by Timothy Prickett Morgan at The Next Platform.
AWS NAT Gateway and Private/Public Subnets

When working with AWS networking, you will often hear the terms 'public subnet' and 'private subnet'. However, if you go into the AWS console to create a subnet, you won't find any option to explicitly make it one or the other. So, what exactly makes a subnet public or private?
In this blog post, we will look at the differences between public and private subnets, see how they are defined by their routing, and understand how the AWS NAT Gateway fits into this architecture.
If you are completely new to AWS networking and want to learn the basics of setting up a VPC, feel free to check out my previous post linked below.
AWS Networking Fundamentals
If you’re brand new to AWS, don’t worry. This post focuses on the basics of AWS networking. General networking knowledge is helpful but not required - I’ll try to explain things clearly so everyone can follow along.

Public vs Private Subnets
The key difference between a 'public' and a 'private' subnet is simply its route to the Internet. It is not an inherent setting of the subnet itself, but a behaviour defined by the route table associated Continue reading
Static Routes in netlab Lab Topologies
As much as we’d love everything in our networks to be dynamic, auto-configured, or software-defined, reality often intervenes and forces us to use static routes, so we needed a mechanism to specify them in netlab lab topologies.
A static route has two components: the destination prefix and the next hop – the device that we hope knows how to reach that destination. The next hop is usually specified as an IPv4 or IPv6 address, but may also include outgoing interface information1.
Setting clock source with GNU Radio
I bought a GPS Disciplined Oscillator (GPSDO), because I thought it’d be fun for various projects. Specifically I bought this one.
I started by calibrating my ICOM IC-9700. I made sure it got a GPS lock, and connected it to the 9700 10MHz reference port, with a 20dB attenuator inline, just in case. Ok, the receive frequency moved a bit, but how do I know it was improved? My D75 was still about 200Hz off frequency.
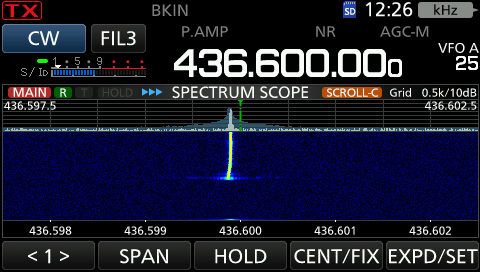
Segal’s law parahrased: “Someone with one radio knows what frequency they’re on. Someone with two radios is never sure”.
Unless, of course, that person has two radios with disciplined oscillators. Which I do. I also have a USRP B200 with an added GPSDO accessory.
Sidenote: wow, that’s gotten expensive. Today I’d probably use the same GPSDO from DXPatrol instead. Note that if you do have the GPSDO installed in the B200, then you cannot use an external 10MHz reference. It’s a known issue. Then again if you paid this much, why would you not use it?
Configuring GNU Radio to use the GPSDO
First I thought that surely the best reference would be the default, so I should be able to just send Continue reading
Software defined KISS modem
I’ve kept working on my SDR framework in Rust called RustRadio, that I’ve blogged about twice before. I’ve been adding a little bit here, a little bit there, with one of my goals being to control a whole AX.25 stack.
As seen in the diagram in this post, we need:
- Applications, client and server — I’ve made those.
- AX.25 connected mode stack (OSI layer 4, basically) — The kernel’s sucks, so I made that too.
- A modem (OSI layer 2), turning digital packets into analog radio — The topic of this post.
The job of the modem
Applications talk in terms of streams. AX.25 implementation turns that into individual data frames. The most common protocol for sending and receiving frames is KISS.
I’ve not been happy with the existing KISS modems for a few reasons. The main one is that they just convert between packets and audio. I don’t want audio, I want I/Q signals suitable for SDRs.
On the transmit side it’s less of a problem for regular 1200bps AX.25, since either the radio will turn audio into a FM-modulated signal, or if using an SDR it’s trivial to add the audio-to-I/Q step.
HN786: From Intent-Based to Autonomous Ops With Cisco Crosswork and Provider Connectivity Assurance (Sponsored)
Service provider networks face a couple of difficult challenges: how to map service level agreements to actual network health and performance, and how to deliver service assurance to customers regardless of what happens on the network. On today’s sponsored Heavy Networking we talk with Cisco Systems about its approach to service assurance, how Cisco is... Read more »TNO033: Maximum Impact: Leverage Your Network to Advance Your Career (Sponsored)
At AutoCon 3 in Prague, Scott Robohn sat down with Ernest Lefner from sponsor Gluware to talk about lessons learned throughout his career: from his early days of pulling cable to becoming Chief Product Officer at Gluware and helping to found ONUG. Ernest talks about being a continuous technology learner, and also about the need... Read more »QuEra Quantum System Leverages Neutral Atoms To Compute
Sitting in an office at QuEra Computing’s Boston headquarters, Yuval Boger was talking about the recent advancements made in quantum computing that are driving the chorus around an accelerated the timeframe the launch of a usable and reliable system. …
QuEra Quantum System Leverages Neutral Atoms To Compute was written by Timothy Prickett Morgan at The Next Platform.
Palo Alto Create Bulk Address Objects using Pan-OS Python SDK

In this blog post, we'll see how to configure bulk Address-Objects at once and then add them to an Address-Group using the pan-os-python Library. If you haven't used the pan-os-python library before, have a look at my other blog post to learn more.
Palo Alto PAN-OS SDK for Python
Let’s start learning the pan-os-python library with a simple script. This script will be our foundation, and it’s as straightforward as it gets, creating a basic firewall rule on a Palo Alto firewall.
 Suresh Vina
Suresh Vina
Methods we will use
Here is the official guide for the useful methods
- add() - This method is used to add an object as a child of another object. In our scenario, it's for adding an Address Object to the firewall or panorama object.
- extend() - This method allows you to add a list of objects as children. In our context, it means adding a 'list' of Address objects to the firewall or panorama object.
- create() - Once you've defined an object in the script, the
create()method is used to push this object to the live device, making the configuration active. - create_similar() - This method pushes objects of the same type to the live Continue reading