Palo Alto App-ID – How Does It Work?

If you've ever worked with traditional Layer 4 firewalls, you might be familiar with configuring security policies based on TCP or UDP port numbers. For instance, to allow DNS, you'd create a policy for UDP/53, or for LDAP, a policy for TCP/389.
This approach is normal with firewalls like Cisco ASA. But it's 2024, and Next-Generation Firewalls (NGFWs) have become the standard, offering a more sophisticated way to manage security. Instead of relying solely on port numbers, NGFWs like those from Palo Alto Networks encourage defining security policies based on the actual applications termed 'App-ID'. For example, instead of specifying port numbers, a policy could simply be defined to allow 'DNS' and 'LDAP', focusing on the applications themselves.
Palo Alto App-ID Introduction
Okay, that sounds simple, so why continue reading you may ask? Well, while Palo Alto’s App-ID does work well most of the time, there are nuances that you need to understand. For applications like DNS, NTP, and LDAP, App-ID works very well. However, the most common applications involve SSL or web browsing, typically associated with ports 80 and 443.
Palo Alto provides App-IDs for both SSL and Web-Browsing (called ssl and web-browsing Continue reading
HN751: Top Tips for Building A CCIE-EI Lab
The Packet Pushers and guest Mason Reimert discuss strategies he’s using to prepare for the Cisco CCIE Enterprise Infrastructure lab exam. Mason shares practical tips for hands-on labbing for both established and emerging technologies like SD-WAN and SD-Access, resource management, virtualization tools, and automation. He also highlights the importance of understanding APIs, data formats, and... Read more »AI Everywhere with the WAF Rule Builder Assistant, Cloudflare Radar AI Insights, and updated AI bot protection
The continued growth of AI has fundamentally changed the Internet over the past 24 months. AI is increasingly ubiquitous, and Cloudflare is leaning into the new opportunities and challenges it presents in a big way. This year for Cloudflare’s birthday, we’ve extended our AI Assistant capabilities to help you build new WAF rules, added AI bot traffic insights on Cloudflare Radar, and given customers new AI bot blocking capabilities.
AI Assistant for WAF Rule Builder

At Cloudflare, we’re always listening to your feedback and striving to make our products as user-friendly and powerful as possible. One area where we've heard your feedback loud and clear is in the complexity of creating custom and rate-limiting rules for our Web Application Firewall (WAF). With this in mind, we’re excited to introduce a new feature that will make rule creation easier and more intuitive: the AI Assistant for WAF Rule Builder.
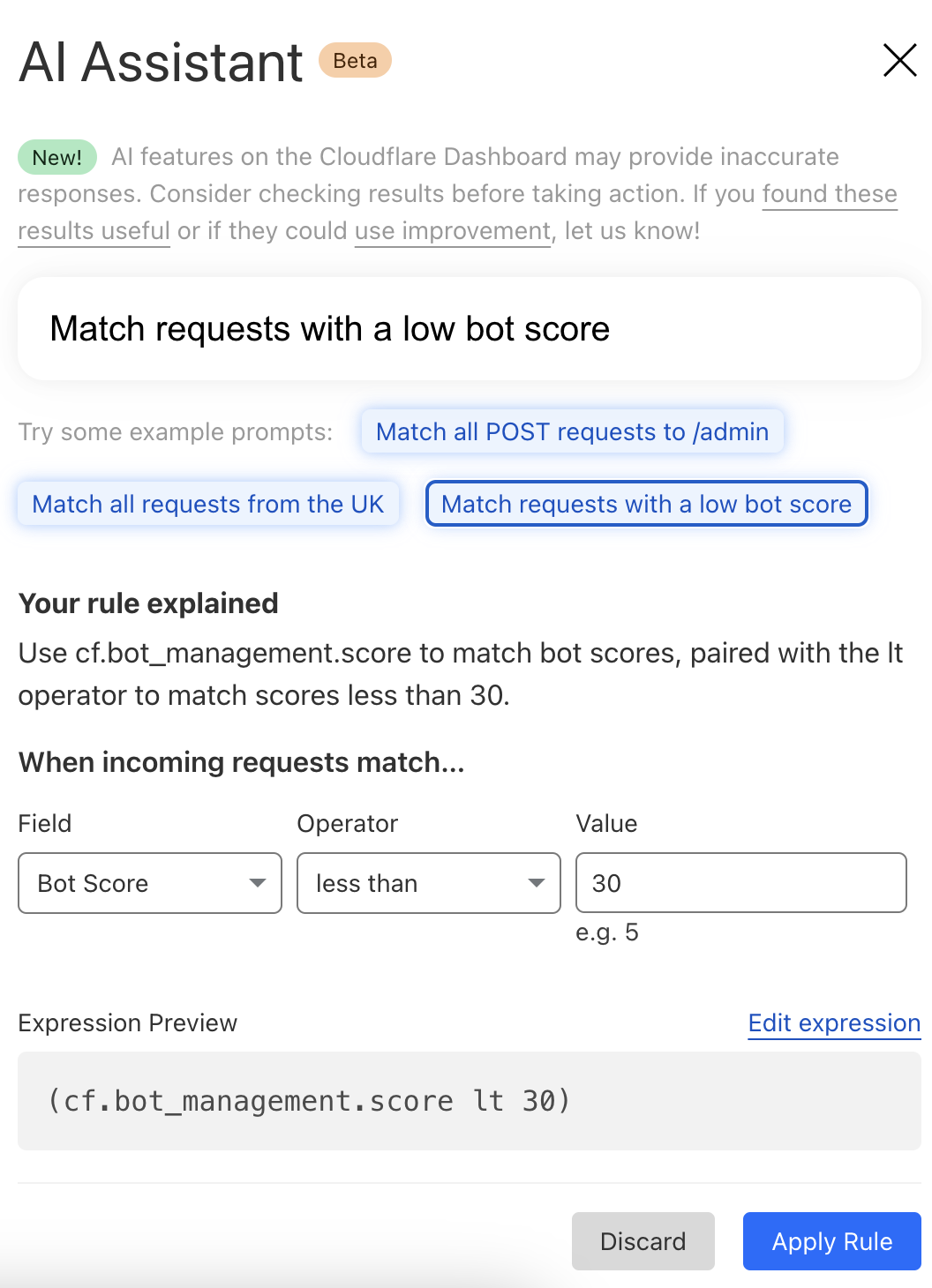
By simply entering a natural language prompt, you can generate a custom or rate-limiting rule tailored to your needs. For example, instead of manually configuring a complex rule matching criteria, you can now type something like, "Match requests with low bot score," and the assistant will generate the rule for Continue reading
Our container platform is in production. It has GPUs. Here’s an early look
We’ve been working on something new — a platform for running containers across Cloudflare’s network. We already use it in production for Workers AI, Workers Builds, Remote Browsing Isolation, and the Browser Rendering API. Today, we want to share an early look at how it’s built, why we built it, and how we use it ourselves.
In 2024, Cloudflare Workers celebrates its 7th birthday. When we first announced Workers, it was a completely new model for running compute in a multi-tenant way — on isolates, as opposed to containers. While, at the time, Workers was a pretty bare-bones functions-as-a-service product, we took a big bet that this was going to become the way software was going to be written going forward. Since introducing Workers, in addition to expanding our developer products in general to include storage and AI, we have been steadily adding more compute capabilities to Workers:
2020 | |
2021 | |
2022 | |
2023 | |
2024 |
With each of these, we’ve faced a question — can Continue reading
Reaffirming our commitment to free
Cloudflare launched our free tier at the same time our company launched — fourteen years ago, on September 27, 2010. Of course, a bit has changed since then — there are now millions of Internet properties behind Cloudflare. As we’ve grown in size and amassed millions of free customers, one of the questions we often get asked is: how can Cloudflare afford to do this at such scale?
Cloudflare always has, and always will, offer a generous free version for public-facing applications (Application Services), internal private networks and people (Cloudflare One), and developer tools (Developer Platform). Counterintuitively: our free service actually helps us keep our costs lower. Not only is it mission-aligned, our free tier is business-aligned. We want to make abundantly clear: our free plan is here to stay, and we reaffirmed that commitment this week with 15 releases across our product portfolio that make the Free plan even better.
Understanding our Cost of Goods Sold
To understand the economics of Free, you need to understand our Cost of Goods Sold (COGS). Cloudflare hasn’t outsourced its network — we built it ourselves, and it spans more than 330 cities. We design and ship Continue reading
Network trends and natural language: Cloudflare Radar’s new Data Explorer & AI Assistant
Cloudflare Radar showcases global Internet traffic patterns, attack activity, and technology trends and insights. It is powered by data from Cloudflare's global network, as well as aggregated and anonymized data from Cloudflare's 1.1.1.1 public DNS Resolver, and is built on top of a rich, publicly accessible API. This API allows users to explore Radar data beyond the default set of visualizations, for example filtering by protocol, comparing metrics across multiple locations or autonomous systems, or examining trends over two different periods of time. However, not every user has the technical know-how to make a raw API query or process the JSON-formatted response.
Today, we are launching the Cloudflare Radar Data Explorer, which provides a simple Web-based interface to enable users to easily build more complex API queries, including comparisons and filters, and visualize the results. And as a complement to the Data Explorer, we are also launching an AI Assistant, which uses Cloudflare Workers AI to translate a user’s natural language statements or questions into the appropriate Radar API calls, the results of which are visualized in the Data Explorer. Below, we introduce the AI Assistant and Data Explorer, and also dig into how we Continue reading
Empowering builders: introducing the Dev Alliance and Workers Launchpad Cohort #4
Today we’re announcing the Dev Starter Pack, an alliance of innovative tools for developers to get started with discounts and free services. We’re also excited to share an update on our Workers Launchpad Program.
Creating from the ground up often means spending countless hours piecing together the right development stack, navigating different pricing models, and managing growing costs — all of which can take your focus away from what truly matters: building your product and growing your business.
Introducing Dev Starter Pack: the tools you need to start building your startup
Hey! Dani Grant here, one of the first PMs at Cloudflare and co-founder of Jam.dev. Ten years ago (during 2014’s Birthday Week), Cloudflare launched Universal SSL, making SSL free on the Internet for the first time, and in one night doubling the size of the encrypted web.
I was a college student back then, and I immediately became enraptured by Cloudflare’s mission: helping build a better Internet. As part of this mission, Cloudflare has developed powerful tools typically accessible only to Internet giants, oftentimes offering them for free to developers and individuals alike. Heck yeah! I joined Cloudflare in January 2015, and 5 years after that, co-founded Continue reading
Advancing cybersecurity: Cloudflare implements a new bug bounty VIP program as part of CISA Pledge commitment
As our digital world becomes increasingly more complex, the importance of cybersecurity grows ever more critical. As a result, Cloudflare is proud to promote our commitment to the Cybersecurity and Infrastructure Security Agency (CISA) ‘Secure by Design’ pledge. The commitment is built around seven security goals, aimed at enhancing the safety of our products and delivering the most secure solutions to our customers.
Cloudflare’s commitment to the CISA pledge reflects our dedication to transparency and accountability to our customers, and to cybersecurity best practices. Furthermore, Cloudflare is committed to being a trusted partner by sharing our strategies to ensure the highest priority is placed on safeguarding our customers’ security.
Bug bounty VIP program
Cloudflare has successfully managed a public Vulnerability Disclosure Program (VDP) for years; our belief is that collaboration is the cornerstone of effective cybersecurity. We are excited to announce a major milestone in our journey to meet Goal #5 of the pledge: our program will now include a bug bounty VIP program in conjunction with our bug bounty public program.
Continuous investment in maturing our bug bounty program is a vital tool for the success of any security organization. By encouraging broader participation in vulnerability testing, Continue reading
Expanding Cloudflare’s support for open source projects with Project Alexandria
At Cloudflare, we believe in the power of open source. It’s more than just code, it’s the spirit of collaboration, innovation, and shared knowledge that drives the Internet forward. Open source is the foundation upon which the Internet thrives, allowing developers and creators from around the world to contribute to a greater whole.
But oftentimes, open source maintainers struggle with the costs associated with running their projects and providing access to users all over the world. We’ve had the privilege of supporting incredible open source projects such as Git and the Linux Foundation through our open source program and learned first-hand about the places where Cloudflare can help the most.
Today, we're introducing a streamlined and expanded open source program: Project Alexandria. The ancient city of Alexandria is known for hosting a prolific library and a lighthouse that was one of the Seven Wonders of the Ancient World. The Lighthouse of Alexandria served as a beacon of culture and community, welcoming people from afar into the city. We think Alexandria is a great metaphor for the role open source projects play as a beacon for developers around the world and a source of knowledge that is core to making a Continue reading
Running a Simple HTTP Server with Python

I think this is going to be the shortest blog post of all time because running a Python HTTP server is incredibly straightforward. Python's HTTP server module lets you create a basic web server using just a single command. This server can serve files from a directory over the network, making it an excellent tool for quick testing and file sharing without the complexity of setting up a full-fledged web server.
You can start the Python HTTP server with the command python -m http.server 8000, which serves files from the current directory on port 8000. You can choose any port number by replacing 8000 with your preferred port. However, if you select a lower port number, such as 80, you might need administrator privileges to run the server.
💡
You don't even need to have a Python file or any code to run this, just this single command does the trick.
In this example, I have two files in a directory - one is a text file with a list of domains and the second is a simple YAML file.

If I run the command python -m http.server 8000, it starts a web server and I Continue reading
Builder Day 2024: 18 big updates to the Workers platform
To celebrate Builder Day 2024, we’re shipping 18 updates inspired by direct feedback from developers building on Cloudflare. Choosing a platform isn't just about current technologies and services — it's about betting on a partner that will evolve with your needs as your project grows and the tech landscape shifts. We’re in it for the long haul with you.
Starting today, you can:
Persist logs from your Worker and query them directly on the Cloudflare dashboard
Connect your Worker to private databases (isolated in VPCs) using Hyperdrive
Use a wider set of NPM packages on Cloudflare Workers, via improved Node.js compatibility
Deploy Next.js apps that use the Node.js runtime to Cloudflare, via OpenNext
Read from and write to SQLite with zero-latency from every Durable Object
We’ve brought key features from Pages to Workers, allowing you to:
Upload and serve static assets as part of your Worker, and use popular frameworks with Workers
Automatically build and deploy each pull request to your Worker’s git repository
Get back a preview deployment URL for each version of your Worker
Four things are going GA and are officially production-ready:
TL004: Fostering Psychological Safety for Tech Teams
The concept of psychological safety originated from research on surgical teams. Psychological safety is essential as it allows team members to voice concerns without fear of retaliation. As a leadership tool, it can help people perform at their highest levels. In this episode of Technically Leadership, guest Wesley Faulkner talks with host Laura Santamaria about... Read more »We made Workers KV up to 3x faster — here’s the data
Speed is a critical factor that dictates Internet behavior. Every additional millisecond a user spends waiting for your web page to load results in them abandoning your website. The old adage remains as true as ever: faster websites result in higher conversion rates. And with such outcomes tied to Internet speed, we believe a faster Internet is a better Internet.
Customers often use Workers KV to provide Workers with key-value data for configuration, routing, personalization, experimentation, or serving assets. Many of Cloudflare’s own products rely on KV for just this purpose: Pages stores static assets, Access stores authentication credentials, AI Gateway stores routing configuration, and Images stores configuration and assets, among others. So KV’s speed affects the latency of every request to an application, throughout the entire lifecycle of a user session.
Today, we’re announcing up to 3x faster KV hot reads, with all KV operations faster by up to 20ms. And we want to pull back the curtain and show you how we did it.
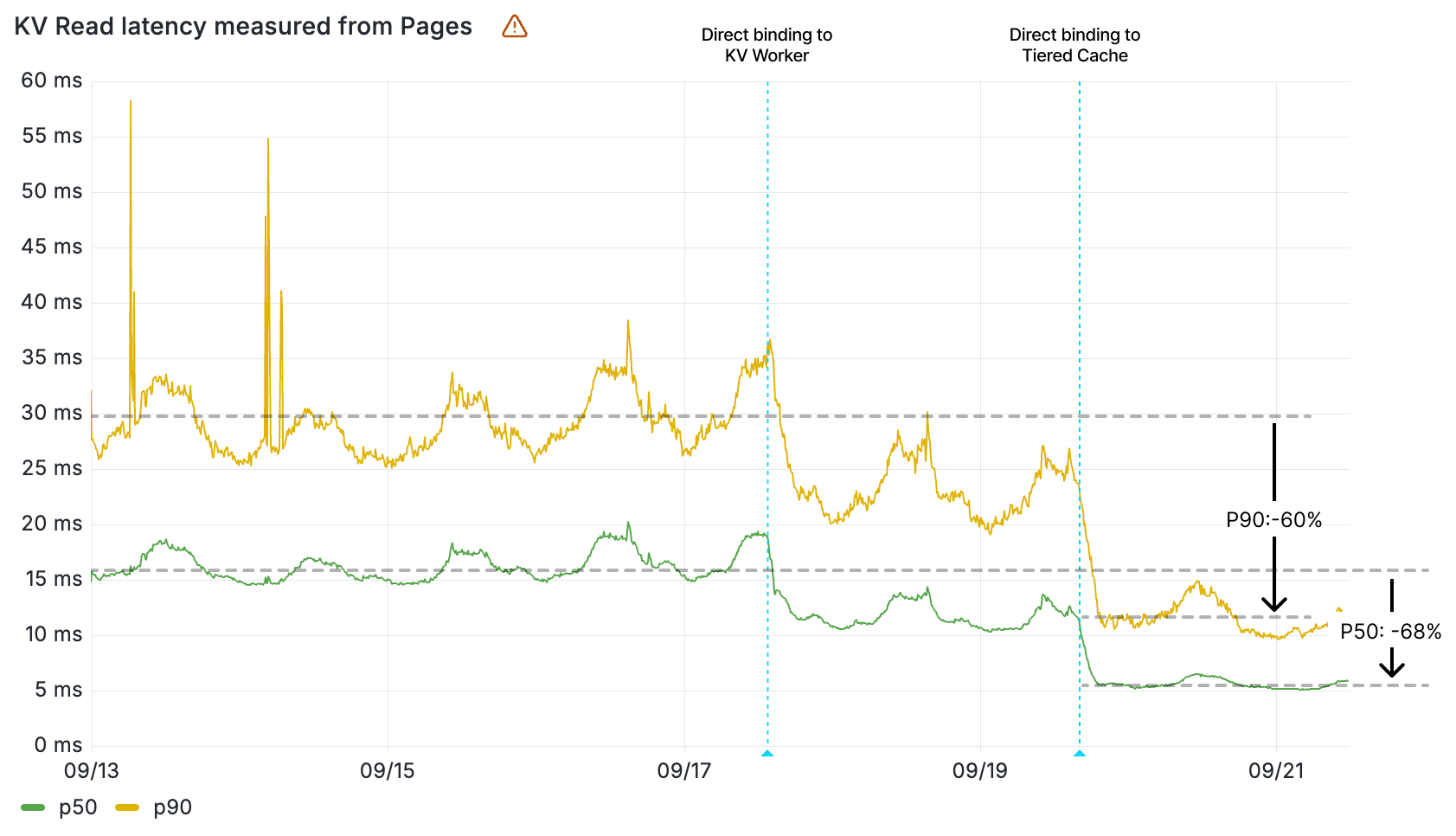
Workers KV read latency (ms) by percentile measured from Pages
Optimizing Workers KV’s architecture to minimize latency
At a high level, Workers KV is itself a Worker that makes requests to central Continue reading
Zero-latency SQLite storage in every Durable Object
Traditional cloud storage is inherently slow, because it is normally accessed over a network and must carefully synchronize across many clients that could be accessing the same data. But what if we could instead put your application code deep into the storage layer, such that your code runs directly on the machine where the data is stored, and the database itself executes as a local library embedded inside your application?
Durable Objects (DO) are a novel approach to cloud computing which accomplishes just that: Your application code runs exactly where the data is stored. Not just on the same machine: your storage lives in the same thread as the application, requiring not even a context switch to access. With proper use of caching, storage latency is essentially zero, while nevertheless being durable and consistent.
Until today, DOs only offered key/value oriented storage. But now, they support a full SQL query interface with tables and indexes, through the power of SQLite.
SQLite is the most-used SQL database implementation in the world, with billions of installations. It’s on practically every phone and desktop computer, and many embedded devices use it as well. It's known to be blazingly fast and rock solid. But Continue reading
Making Workers AI faster and more efficient: Performance optimization with KV cache compression and speculative decoding
During Birthday Week 2023, we launched Workers AI. Since then, we have been listening to your feedback, and one thing we’ve heard consistently is that our customers want Workers AI to be faster. In particular, we hear that large language model (LLM) generation needs to be faster. Users want their interactive chat and agents to go faster, developers want faster help, and users do not want to wait for applications and generated website content to load. Today, we’re announcing three upgrades we’ve made to Workers AI to bring faster and more efficient inference to our customers: upgraded hardware, KV cache compression, and speculative decoding.
Thanks to Cloudflare’s 12th generation compute servers, our network now supports a newer generation of GPUs capable of supporting larger models and faster inference. Customers can now use Meta Llama 3.2 11B, Meta’s newly released multi-modal model with vision support, as well as Meta Llama 3.1 70B on Workers AI. Depending on load and time of day, customers can expect to see two to three times the throughput for Llama 3.1 and 3.2 compared to our previous generation Workers AI hardware. More performance information for these models can be found Continue reading
Cloudflare’s bigger, better, faster AI platform
Birthday Week 2024 marks our first anniversary of Cloudflare’s AI developer products — Workers AI, AI Gateway, and Vectorize. For our first birthday this year, we’re excited to announce powerful new features to elevate the way you build with AI on Cloudflare.
Workers AI is getting a big upgrade, with more powerful GPUs that enable faster inference and bigger models. We’re also expanding our model catalog to be able to dynamically support models that you want to run on us. Finally, we’re saying goodbye to neurons and revamping our pricing model to be simpler and cheaper. On AI Gateway, we’re moving forward on our vision of becoming an ML Ops platform by introducing more powerful logs and human evaluations. Lastly, Vectorize is going GA, with expanded index sizes and faster queries.
Whether you want the fastest inference at the edge, optimized AI workflows, or vector database-powered RAG, we’re excited to help you harness the full potential of AI and get started on building with Cloudflare.
The fast, global AI platform
The first thing that you notice about an application is how fast, or in many cases, how slow it is. This is especially true of AI applications, Continue reading
Startup Program revamped: build and grow on Cloudflare with up to $250,000 in credits
Today, we’re pleased to offer startups up to $250,000 in credits to use on Cloudflare’s Developer Platform. This new credits system will allow you to clearly see usage and associated fees to plan for a predictable future after the $250,000 in credits have been used up or after one year, whichever happens first.
You can see eligibility criteria and apply to the start-up program here.
What can you use the credits for?
Credits can be applied to all Developer Platform products, as well as Argo and Cache Reserve. Moreover, we provide participants with up to three Enterprise-level domains, which includes CDN, DDoS, DNS, WAF, Zero Trust, and other security and performance products that a participant can enable for their website.
Developer tools and building on Cloudflare
You can use credits for Cloudflare Developer Platform products, including those listed in the table below.
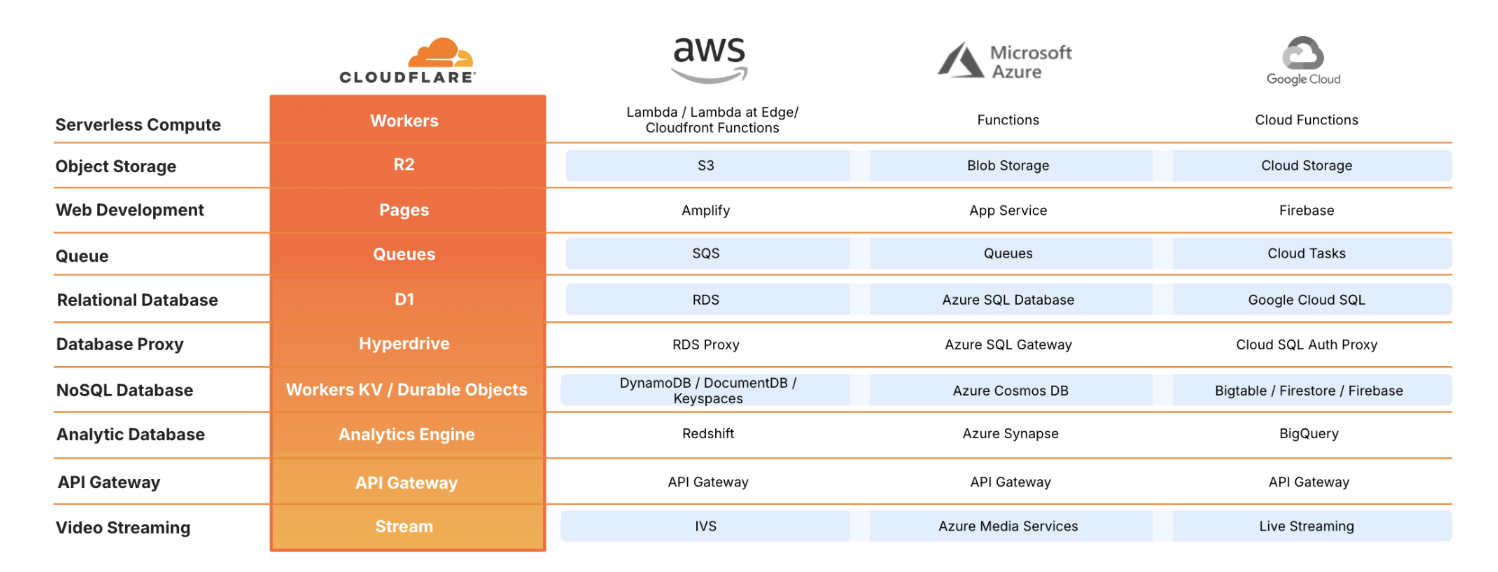
Note: credits for the Cloudflare Startup Program apply to Cloudflare products only, this table is illustrative of similar products in the market.
Speed and performance with Cloudflare
We know that founders need all the help they can get when starting their businesses. Beyond the Developer Platform, you can also use the Startup Program for our speed Continue reading
Flexing the Windows RRAS BGP implementation
Flexing the Windows RRAS BGP implementation
At this point I am a bit of a BGP protocol implementation connoisseur thanks to
NAN074: Integrate and Collaborate with Codespaces and Containerlab
GitHub Codespaces aims to simplify spinning up a developer environment in the cloud. Containerlab, which provides virtual lab environments for network engineers, is now integrated with Codespaces to make it easy to set up and share network labs. On today’s Network Automation Nerds show, we delve into this innovative use of GitHub Codespaces and containerlab... Read more »Cloudflare’s 12th Generation servers — 145% more performant and 63% more efficient
Cloudflare is thrilled to announce the general deployment of our next generation of servers — Gen 12 powered by AMD EPYC 9684X (code name “Genoa-X”) processors. This next generation focuses on delivering exceptional performance across all Cloudflare services, enhanced support for AI/ML workloads, significant strides in power efficiency, and improved security features.
Here are some key performance indicators and feature improvements that this generation delivers as compared to the prior generation:
Beginning with performance, with close engineering collaboration between Cloudflare and AMD on optimization, Gen 12 servers can serve more than twice as many requests per second (RPS) as Gen 11 servers, resulting in lower Cloudflare infrastructure build-out costs.
Next, our power efficiency has improved significantly, by more than 60% in RPS per watt as compared to the prior generation. As Cloudflare continues to expand our infrastructure footprint, the improved efficiency helps reduce Cloudflare’s operational expenditure and carbon footprint as a percentage of our fleet size.
Third, in response to the growing demand for AI capabilities, we've updated the thermal-mechanical design of our Gen 12 server to support more powerful GPUs. This aligns with the Workers AI objective to support larger large language models and increase throughput for smaller Continue reading