Builder Day 2024: 18 big updates to the Workers platform
To celebrate Builder Day 2024, we’re shipping 18 updates inspired by direct feedback from developers building on Cloudflare. Choosing a platform isn't just about current technologies and services — it's about betting on a partner that will evolve with your needs as your project grows and the tech landscape shifts. We’re in it for the long haul with you.
Starting today, you can:
Persist logs from your Worker and query them directly on the Cloudflare dashboard
Connect your Worker to private databases (isolated in VPCs) using Hyperdrive
Use a wider set of NPM packages on Cloudflare Workers, via improved Node.js compatibility
Deploy Next.js apps that use the Node.js runtime to Cloudflare, via OpenNext
Read from and write to SQLite with zero-latency from every Durable Object
We’ve brought key features from Pages to Workers, allowing you to:
Upload and serve static assets as part of your Worker, and use popular frameworks with Workers
Automatically build and deploy each pull request to your Worker’s git repository
Get back a preview deployment URL for each version of your Worker
Four things are going GA and are officially production-ready:
TL004: Fostering Psychological Safety for Tech Teams
The concept of psychological safety originated from research on surgical teams. Psychological safety is essential as it allows team members to voice concerns without fear of retaliation. As a leadership tool, it can help people perform at their highest levels. In this episode of Technically Leadership, guest Wesley Faulkner talks with host Laura Santamaria about... Read more »We made Workers KV up to 3x faster — here’s the data
Speed is a critical factor that dictates Internet behavior. Every additional millisecond a user spends waiting for your web page to load results in them abandoning your website. The old adage remains as true as ever: faster websites result in higher conversion rates. And with such outcomes tied to Internet speed, we believe a faster Internet is a better Internet.
Customers often use Workers KV to provide Workers with key-value data for configuration, routing, personalization, experimentation, or serving assets. Many of Cloudflare’s own products rely on KV for just this purpose: Pages stores static assets, Access stores authentication credentials, AI Gateway stores routing configuration, and Images stores configuration and assets, among others. So KV’s speed affects the latency of every request to an application, throughout the entire lifecycle of a user session.
Today, we’re announcing up to 3x faster KV hot reads, with all KV operations faster by up to 20ms. And we want to pull back the curtain and show you how we did it.
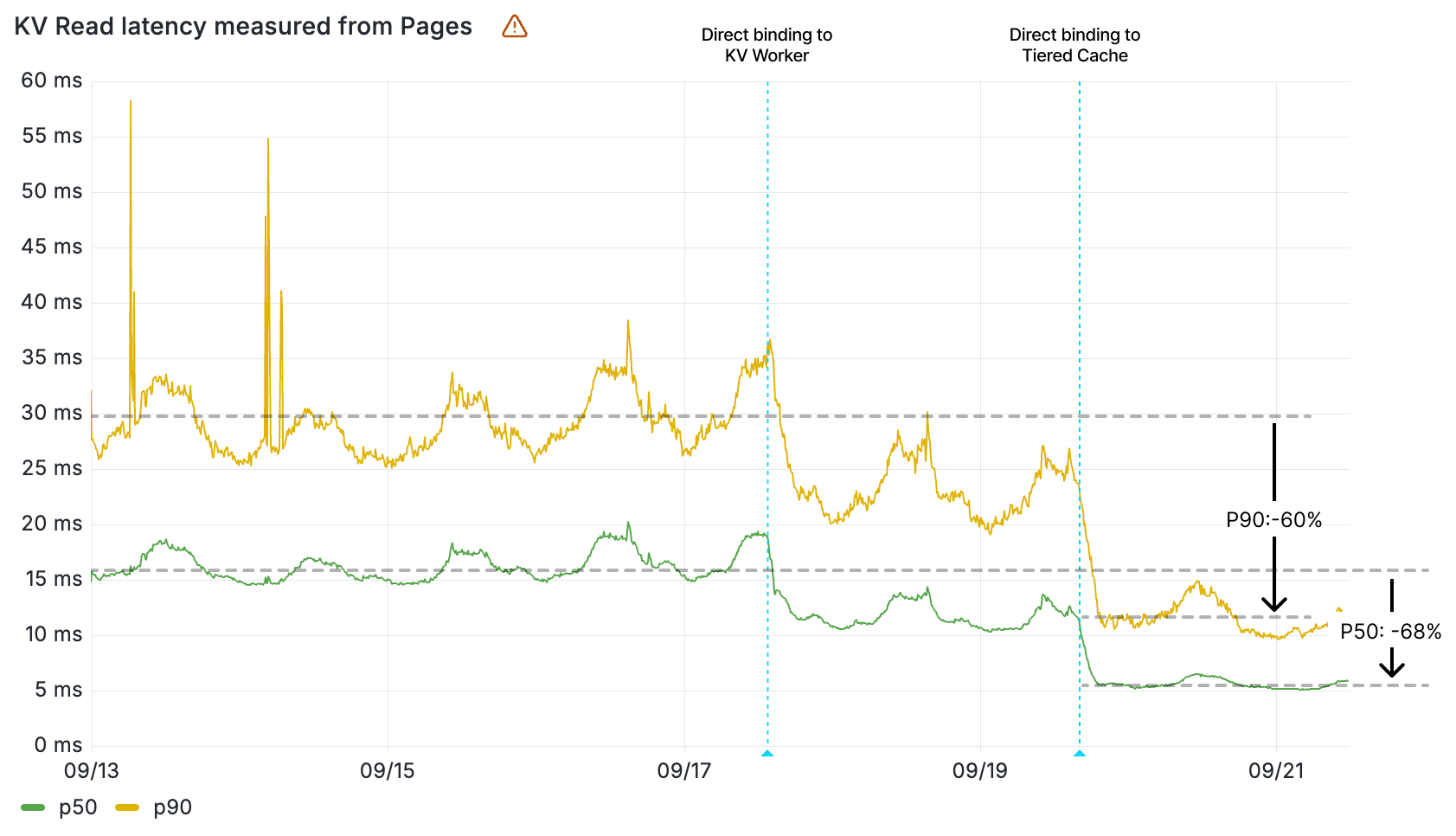
Workers KV read latency (ms) by percentile measured from Pages
Optimizing Workers KV’s architecture to minimize latency
At a high level, Workers KV is itself a Worker that makes requests to central Continue reading
Zero-latency SQLite storage in every Durable Object
Traditional cloud storage is inherently slow, because it is normally accessed over a network and must carefully synchronize across many clients that could be accessing the same data. But what if we could instead put your application code deep into the storage layer, such that your code runs directly on the machine where the data is stored, and the database itself executes as a local library embedded inside your application?
Durable Objects (DO) are a novel approach to cloud computing which accomplishes just that: Your application code runs exactly where the data is stored. Not just on the same machine: your storage lives in the same thread as the application, requiring not even a context switch to access. With proper use of caching, storage latency is essentially zero, while nevertheless being durable and consistent.
Until today, DOs only offered key/value oriented storage. But now, they support a full SQL query interface with tables and indexes, through the power of SQLite.
SQLite is the most-used SQL database implementation in the world, with billions of installations. It’s on practically every phone and desktop computer, and many embedded devices use it as well. It's known to be blazingly fast and rock solid. But Continue reading
Making Workers AI faster and more efficient: Performance optimization with KV cache compression and speculative decoding
During Birthday Week 2023, we launched Workers AI. Since then, we have been listening to your feedback, and one thing we’ve heard consistently is that our customers want Workers AI to be faster. In particular, we hear that large language model (LLM) generation needs to be faster. Users want their interactive chat and agents to go faster, developers want faster help, and users do not want to wait for applications and generated website content to load. Today, we’re announcing three upgrades we’ve made to Workers AI to bring faster and more efficient inference to our customers: upgraded hardware, KV cache compression, and speculative decoding.
Thanks to Cloudflare’s 12th generation compute servers, our network now supports a newer generation of GPUs capable of supporting larger models and faster inference. Customers can now use Meta Llama 3.2 11B, Meta’s newly released multi-modal model with vision support, as well as Meta Llama 3.1 70B on Workers AI. Depending on load and time of day, customers can expect to see two to three times the throughput for Llama 3.1 and 3.2 compared to our previous generation Workers AI hardware. More performance information for these models can be found Continue reading
Cloudflare’s bigger, better, faster AI platform
Birthday Week 2024 marks our first anniversary of Cloudflare’s AI developer products — Workers AI, AI Gateway, and Vectorize. For our first birthday this year, we’re excited to announce powerful new features to elevate the way you build with AI on Cloudflare.
Workers AI is getting a big upgrade, with more powerful GPUs that enable faster inference and bigger models. We’re also expanding our model catalog to be able to dynamically support models that you want to run on us. Finally, we’re saying goodbye to neurons and revamping our pricing model to be simpler and cheaper. On AI Gateway, we’re moving forward on our vision of becoming an ML Ops platform by introducing more powerful logs and human evaluations. Lastly, Vectorize is going GA, with expanded index sizes and faster queries.
Whether you want the fastest inference at the edge, optimized AI workflows, or vector database-powered RAG, we’re excited to help you harness the full potential of AI and get started on building with Cloudflare.
The fast, global AI platform
The first thing that you notice about an application is how fast, or in many cases, how slow it is. This is especially true of AI applications, Continue reading
Startup Program revamped: build and grow on Cloudflare with up to $250,000 in credits
Today, we’re pleased to offer startups up to $250,000 in credits to use on Cloudflare’s Developer Platform. This new credits system will allow you to clearly see usage and associated fees to plan for a predictable future after the $250,000 in credits have been used up or after one year, whichever happens first.
You can see eligibility criteria and apply to the start-up program here.
What can you use the credits for?
Credits can be applied to all Developer Platform products, as well as Argo and Cache Reserve. Moreover, we provide participants with up to three Enterprise-level domains, which includes CDN, DDoS, DNS, WAF, Zero Trust, and other security and performance products that a participant can enable for their website.
Developer tools and building on Cloudflare
You can use credits for Cloudflare Developer Platform products, including those listed in the table below.
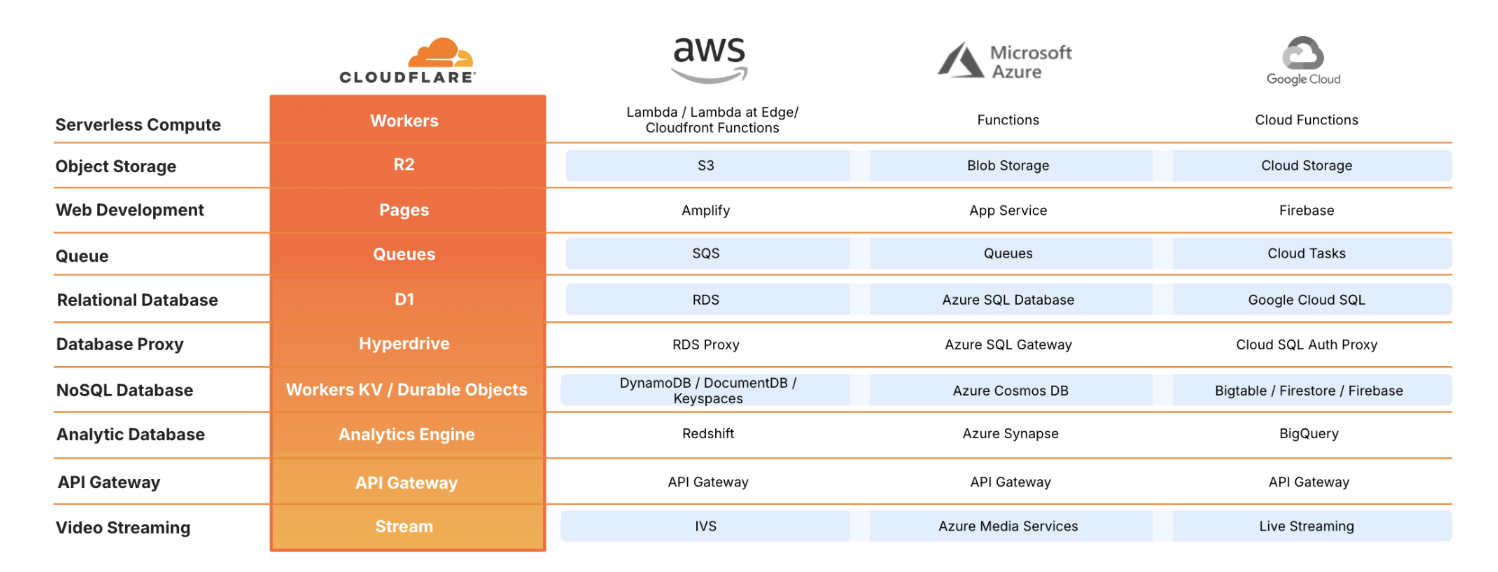
Note: credits for the Cloudflare Startup Program apply to Cloudflare products only, this table is illustrative of similar products in the market.
Speed and performance with Cloudflare
We know that founders need all the help they can get when starting their businesses. Beyond the Developer Platform, you can also use the Startup Program for our speed Continue reading
Flexing the Windows RRAS BGP implementation
Flexing the Windows RRAS BGP implementation
At this point I am a bit of a BGP protocol implementation connoisseur thanks to
NAN074: Integrate and Collaborate with Codespaces and Containerlab
GitHub Codespaces aims to simplify spinning up a developer environment in the cloud. Containerlab, which provides virtual lab environments for network engineers, is now integrated with Codespaces to make it easy to set up and share network labs. On today’s Network Automation Nerds show, we delve into this innovative use of GitHub Codespaces and containerlab... Read more »Cloudflare’s 12th Generation servers — 145% more performant and 63% more efficient
Cloudflare is thrilled to announce the general deployment of our next generation of servers — Gen 12 powered by AMD EPYC 9684X (code name “Genoa-X”) processors. This next generation focuses on delivering exceptional performance across all Cloudflare services, enhanced support for AI/ML workloads, significant strides in power efficiency, and improved security features.
Here are some key performance indicators and feature improvements that this generation delivers as compared to the prior generation:
Beginning with performance, with close engineering collaboration between Cloudflare and AMD on optimization, Gen 12 servers can serve more than twice as many requests per second (RPS) as Gen 11 servers, resulting in lower Cloudflare infrastructure build-out costs.
Next, our power efficiency has improved significantly, by more than 60% in RPS per watt as compared to the prior generation. As Cloudflare continues to expand our infrastructure footprint, the improved efficiency helps reduce Cloudflare’s operational expenditure and carbon footprint as a percentage of our fleet size.
Third, in response to the growing demand for AI capabilities, we've updated the thermal-mechanical design of our Gen 12 server to support more powerful GPUs. This aligns with the Workers AI objective to support larger large language models and increase throughput for smaller Continue reading
New standards for a faster and more private Internet
As the Internet grows, so do the demands for speed and security. At Cloudflare, we’ve spent the last 14 years simplifying the adoption of the latest web technologies, ensuring that our users stay ahead without the complexity. From being the first to offer free SSL certificates through Universal SSL to quickly supporting innovations like TLS 1.3, IPv6, and HTTP/3, we've consistently made it easy for everyone to harness cutting-edge advancements.
One of the most exciting recent developments in web performance is Zstandard (zstd) — a new compression algorithm that we have found compresses data 42% faster than Brotli while maintaining almost the same compression levels. Not only that, but Zstandard reduces file sizes by 11.3% compared to GZIP, all while maintaining comparable speeds. As compression speed and efficiency directly impact latency, this is a game changer for improving user experiences across the web.
We’re also re-starting the rollout of Encrypted Client Hello (ECH), a new proposed standard that prevents networks from snooping on which websites a user is visiting. Encrypted Client Hello (ECH) is a successor to ESNI and masks the Server Name Indication (SNI) that is used to negotiate a TLS handshake. This Continue reading
TURN and anycast: making peer connections work globally
A TURN server helps maintain connections during video calls when local networking conditions prevent participants from connecting directly to other participants. It acts as an intermediary, passing data between users when their networks block direct communication. TURN servers ensure that peer-to-peer calls go smoothly, even in less-than-ideal network conditions.
When building their own TURN infrastructure, developers often have to answer a few critical questions:
“How do we build and maintain a mesh network that achieves near-zero latency to all our users?”
“Where should we spin up our servers?”
“Can we auto-scale reliably to be cost-efficient without hurting performance?”
In April, we launched Cloudflare Calls TURN in open beta to help answer these questions. Starting today, Cloudflare Calls’ TURN service is now generally available to all Cloudflare accounts. Our TURN server works on our anycast network, which helps deliver global coverage and near-zero latency required by real time applications.
TURN solves connectivity and privacy problems for real time apps
When Internet Protocol version 4 (IPv4, RFC 791) was designed back in 1981, it was assumed that the 32-bit address space was big enough for all computers to be able to connect to each other. When IPv4 was Continue reading
Introducing Speed Brain: helping web pages load 45% faster
Each time a user visits your web page, they are initiating a race to receive content as quickly as possible. Performance is a critical factor that influences how visitors interact with your site. Some might think that moving content across the globe introduces significant latency, but for a while, network transmission speeds have approached their theoretical limits. To put this into perspective, data on Cloudflare can traverse the 11,000 kilometer round trip between New York and London in about 76 milliseconds – faster than the blink of an eye.
However, delays in loading web pages persist due to the complexities of processing requests, responses, and configurations. In addition to pushing advancements in connection establishment, compression, hardware, and software, we have built a new way to reduce page load latency by anticipating how visitors will interact with a given web page.
Today we are very excited to share the latest leap forward in speed: Speed Brain. It relies on the Speculation Rules API to prefetch the content of the user's likely next navigations. The main goal of Speed Brain is to download a web page to the browser cache before a user navigates to it, allowing Continue reading
SR Linux Containers Run on Apple Silicon
When looking for the latest SR Linux container image, I noticed images with -arm-preview tags and wondered whether they would run on Apple Silicon.
TL&DR: YES, IT WORKS 🎉 🎉
Update 2024-12-11: Starting with 24.10.1 and 23.10.6 images, the SR Linux container manifest contains AMD and ARM images, making running SR Linux on ARM trivial. This blog post has been updated accordingly.
Here’s what you have to do to make SR Linux work with netlab running on a Ubuntu VM on Apple silicon:
Instant Purge: invalidating cached content in under 150ms
(part 3 of the Coreless Purge series)
Over the past 14 years, Cloudflare has evolved far beyond a Content Delivery Network (CDN), expanding its offerings to include a comprehensive Zero Trust security portfolio, network security & performance services, application security & performance optimizations, and a powerful developer platform. But customers also continue to rely on Cloudflare for caching and delivering static website content. CDNs are often judged on their ability to return content to visitors as quickly as possible. However, the speed at which content is removed from a CDN's global cache is just as crucial.
When customers frequently update content such as news, scores, or other data, it is essential they avoid serving stale, out-of-date information from cache to visitors. This can lead to a subpar experience where users might see invalid prices, or incorrect news. The goal is to remove the stale content and cache the new version of the file on the CDN, as quickly as possible. And that starts by issuing a “purge.”
In May 2022, we released the first part of the series detailing our efforts to rebuild and publicly document the steps taken to improve the system our customers use, Continue reading
PP032: Unpacking RPKI for BGP Security
Today on Packet Protector we get into BGP security. BGP is an essential protocol for directing traffic across the Internet, but it wasn’t designed with bad actors in mind, not to mention plain old configuration mistakes. Without additional controls in place, BGP is susceptible to issues such as route leaks and route hijacks that can... Read more »HS083: Why Protocols Fail: Russ White’s Perspective on Effective Architecture
Network veteran Russ White joins the Heavy Strategy team for a rousing discussion on why protocols fail, how much complexity is too much, why “premature optimization is the root of all evil” (Donald Knuth) and why architects should always remember to think about state. Episode Guest: Russ White, Senior Architect, Akamai Technologies For the last... Read more »Semper Gumby

By now I’m sure you’re familiar with Murphy’s Law: “Anything that can go wrong will go wrong.” If you work in IT or events or even in a trade you’ve seen things go upside down on many occasions. Did you ever ask yourself why this happens? Or even what you can do to fix it? What about avoiding it completely?
I have done a lot in IT over the years. I’ve also been working hard as an event planner and coordinator with Tech Field Day. The best lessons that I’ve learned about anticipating disaster have come from my time in Scouting. I’m often asked by companies “how did you know that would happen?” I almost always answer the same way: “I didn’t know THAT would go wrong, but I knew something would. I just kept my eye out for it.” It almost sounds too simple, right? But if you are familiar with event planning you know it’s almost a law, just like Mr. Murphy’s famous version.
How can you anticipate problems and still manage to make things happen? You can’t always fix everything. However, you can make sure that people don’t notice the issues. You just have Continue reading
Cloudflare helps verify the security of end-to-end encrypted messages by auditing key transparency for WhatsApp
Chances are good that today you’ve sent a message through an end-to-end encrypted (E2EE) messaging app such as WhatsApp, Signal, or iMessage. While we often take the privacy of these conversations for granted, they in fact rely on decades of research, testing, and standardization efforts, the foundation of which is a public-private key exchange. There is, however, an oft-overlooked implicit trust inherent in this model: that the messaging app infrastructure is distributing the public keys of all of its users correctly.
Here’s an example: if Joe and Alice are messaging each other on WhatsApp, Joe uses Alice’s phone number to retrieve Alice’s public key from the WhatsApp database, and Alice receives Joe’s public key. Their messages are then encrypted using this key exchange, so that no one — even WhatsApp — can see the contents of their messages besides Alice and Joe themselves. However, in the unlikely situation where an attacker, Bob, manages to register a different public key in WhatsApp’s database, Joe would try to message Alice but unknowingly be messaging Bob instead. And while this threat is most salient for journalists, activists, and those most vulnerable to cyber attacks, we believe that protecting the privacy and integrity of Continue reading
Automatically generating Cloudflare’s Terraform provider
In November 2022, we announced the transition to OpenAPI Schemas for the Cloudflare API. Back then, we had an audacious goal to make the OpenAPI schemas the source of truth for our SDK ecosystem and reference documentation. During 2024’s Developer Week, we backed this up by announcing that our SDK libraries are now automatically generated from these OpenAPI schemas. Today, we’re excited to announce the latest pieces of the ecosystem to now be automatically generated — the Terraform provider and API reference documentation.
This means that the moment a new feature or attribute is added to our products and the team documents it, you’ll be able to see how it’s meant to be used across our SDK ecosystem and make use of it immediately. No more delays. No more lacking coverage of API endpoints.
You can find the new documentation site at https://developers.cloudflare.com/api-next/, and you can try the preview release candidate of the Terraform provider by installing 5.0.0-alpha1.
Why Terraform?
For anyone who is unfamiliar with Terraform, it is a tool for managing your infrastructure as code, much like you would with your application code. Many of our customers (big and small) rely Continue reading