SDxCentral’s Weekly Roundup — January 11, 2018
 Huawei persists despite failures in U.S.; T-Mobile launches NB-IoT plan; Verizon acquires threat hunter.
Huawei persists despite failures in U.S.; T-Mobile launches NB-IoT plan; Verizon acquires threat hunter.
DNSFS. Store your files in others DNS resolver caches
DNSFS. Store your files in others DNS resolver caches
A while ago I did a blog post about how long DNS resolvers hold results in cache for, using RIPE Atlas probes testing against their default resolvers (in a lot of cases, the DNS cache on their m
Welcome Salt Lake City and Get Ready for a Massive Expansion


We just turned up Salt Lake City, Utah — Cloudflare's 120th data center. Salt Lake holds a special place in Cloudflare's history. I grew up in the region and still have family there. Back in 2004, Lee Holloway and I lived just up into the mountains in Park City when we built Project Honey Pot, the open source project that inspired the original idea for Cloudflare.
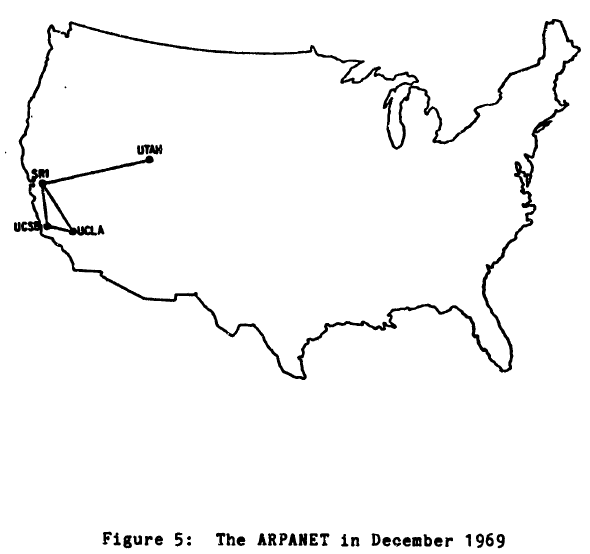
Salt Lake also holds a special place in the history of the Internet. The University of Utah, based there, was one of the original four Arpanet locations (along with UCLA, UC Santa Barbara, and the Stanford Research Institute). The school also educated the founders of great technology companies like Silicon Graphics, Adobe, Atari, Netscape, and Pixar. Many were graduates of the computer graphics department lead by Professors Ivan Sutherland and David Evans.

In 1980, when I was seven years old, my grandmother, who lived a few blocks from the University, gave me an Apple II+ for Christmas. I took to it like a duck to water. My mom enrolled in a continuing education computer course at the University of Utah teaching BASIC programming. I went with her to the classes. Unbeknownst to the Continue reading
Chipping Away At Technical Debt

We’re surrounded by technical debt every day. We have a mountain of it sitting in distribution closets and a yard full of it out behind the data center. We make compromises for budget reasons, for technology reasons, and for political reasons. We tell ourselves every time that this is the last time we’re giving in and the next time it’s going to be different. Yet we find ourselves staring at the landscape of technical debt time and time again. But how can we start chipping away at it?
Time Is On Your Side
You may think you don’t have any time to work on the technical debt problem. This is especially true if you don’t have the time due to fixing problems caused by your technical debt. The hours get longer and the effort goes up exponentially to get simple things done. But it doesn’t have to be that way.
Every minute you spend trying to figure out where a link goes or a how a server is connected to the rest of the pod is a minute that should have been spent documenting it somewhere. In a text document, in a picture, or even on the back of a Continue reading
Don’t Delete PCAP Files – Trim Them! – NETRESEC Blog
Nice tool for people who are crafting an artisanal logging system
IoT-Based DDoS Threats Loom
Hot new tech, including products from CES, add to the growing risk posed by connected devices.
Intent-based Networking explained
The post Intent-based Networking explained appeared first on Noction.
When Did IT Practitioners Lose Their Curiosity?
One of my readers sent me an interestingly sad story as a response to my importance of fundamentals rant. Here it is… enjoy ;)
2017-01-14: Updated with a different viewpoint
Read more ...How Meltdown and Spectre Might Affect x86 Server Usage in SDN
 We could see more ARM-based servers in virtualized networks.
We could see more ARM-based servers in virtualized networks.
NetScout Stock Sinks, Future Blurred on Slashed Guidance
 Rival Viavi viewed as a possible merger partner.
Rival Viavi viewed as a possible merger partner.