VyOS 1.4 LTS released
 |
| Protectli Vault - 4 Port |
The VyOS 1.4.0 (Sagitta) LTS release announcement is exciting news! VyOS is an open source router operating system based on Linux that can be installed on commodity PC hardware - for optimal performance at least 1GB RAM and 4GB of storage space is recommended.
The new 1.4 LTS release includes a significantly enhanced implementation of industry standard sFlow telemetry based on the open source Host sFlow agent.
set system sflow interface eth0 set system sflow interface eth1 set system sflow interface eth2 set system sflow interface eth3 set system sflow polling 30 set system sflow sampling-rate 1000 set system sflow drop-monitor-limit 50 set system sflow server 192.0.2.100Enter the commands above to enable sFlow monitoring on interfaces eth0, eth1, eth2, and eth3. Interface counters will be exported every 30 seconds, packets will be sampled with probability 1/1000, and up to 50 packet headers (and drop reasons) per second will collected from packets dropped by the router. The sFlow telemetry stream will be sent to an sFlow collector at 192.0.2.100.
Running Docker on the sFlow collector makes it easy to run a variety of Continue reading
Hedge 214: Hardware Offloading
Network operators increasingly rely on generic hosts, rather than specialized routers (appliances) to forward traffic. Much of the performance on hosts relies on offloading packets switching and processing to specialized hardware on the network interface card. In this episode of the Hedge, Krzysztof Wróbel and Maciej Rabęda join Russ and Tom to talk about hardware offloading.
You can find out more about hardware offloading here.
IPB145: Internet Reconnaissance and IPv6
Are you on the IPv6 hit list? Does your CPE device have Recommended Simple Security Capabilities? Are your ULA prefixes unique, but still manageable? Do you have a protection method structure or are you just hoping that the IPv6 space is so vast the bad guys will never find you? Tom Coffeen and Scott Hogg... Read more »CloudFabrix and Cisco Partner to Enable the Autonomous Enterprise
CloudFabrix’s Data Fabric works with Cisco's Observability Platform to automate data ingestion pipelines and provide insights into inventory and analytics.Enhancing security analysis with Cloudflare Zero Trust logs and Elastic SIEM

Today, we are thrilled to announce new Cloudflare Zero Trust dashboards on Elastic. Shared customers using Elastic can now use these pre-built dashboards to store, search, and analyze their Zero Trust logs.
When organizations look to adopt a Zero Trust architecture, there are many components to get right. If products are configured incorrectly, used maliciously, or security is somehow breached during the process, it can open your organization to underlying security risks without the ability to get insight from your data quickly and efficiently.
As a Cloudflare technology partner, Elastic helps Cloudflare customers find what they need faster, while keeping applications running smoothly and protecting against cyber threats. “I'm pleased to share our collaboration with Cloudflare, making it even easier to deploy log and analytics dashboards. This partnership combines Elastic's open approach with Cloudflare's practical solutions, offering straightforward tools for enterprise search, observability, and security deployment,” explained Mark Dodds, Chief Revenue Officer at Elastic.
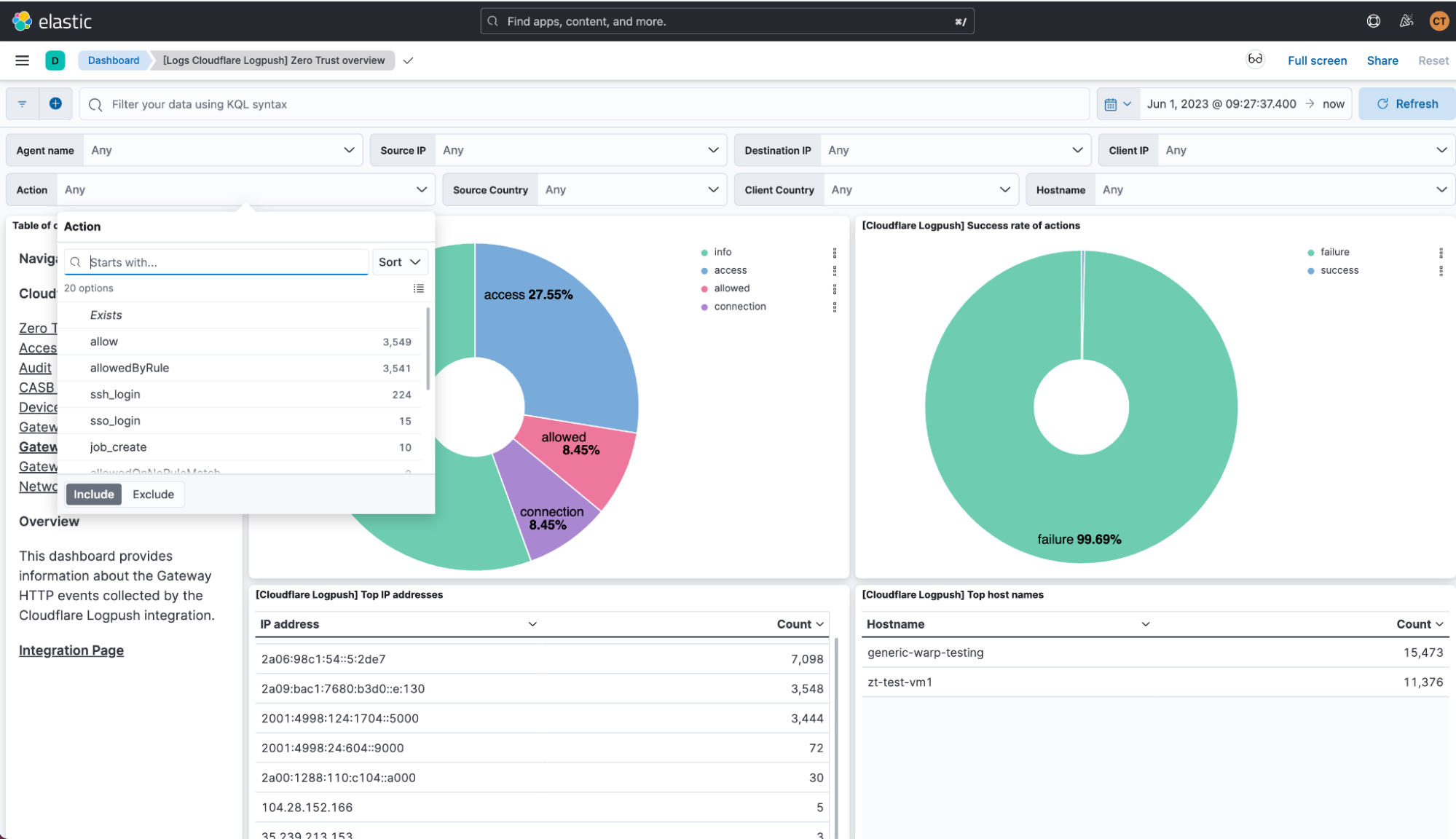
Value of Zero Trust logs in Elastic
With this joint solution, we’ve made it easy for customers to seamlessly forward their Zero Trust logs to Elastic via Logpush jobs. This can be achieved directly via a Restful API or through an intermediary storage solution like Continue reading
BGP Labs: Remove Private AS from AS-Path
In a previous BGP lab exercise, I described how an Internet Service Provider could run BGP with a customer without the customer having a public BGP AS number. The only drawback of that approach: the private BGP AS number gets into the AS path, and everyone else on the Internet starts giving you dirty looks (or drops your prefixes).
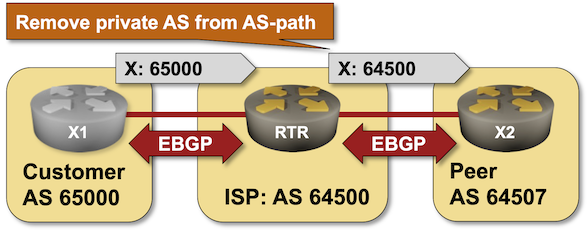
Let’s fix that. Most BGP implementations have some remove private AS functionality that scrubs AS paths during outgoing update processing. You can practice it in the Remove Private BGP AS Numbers from the AS Path lab exercise.
BGP Labs: Remove Private AS from AS-Path
In a previous BGP lab exercise, I described how an Internet Service Provider could run BGP with a customer without the customer having a public BGP AS number. The only drawback of that approach: the private BGP AS number gets into the AS path, and everyone else on the Internet starts giving you dirty looks (or drops your prefixes).
Let’s fix that. Most BGP implementations have some remove private AS functionality that scrubs AS paths during outgoing update processing. You can practice it in the Remove Private BGP AS Numbers from the AS Path lab exercise.
D2C234: What to Do About VMware
Broadcom’s acquisition of VMware has generated a lot of anxiety among VMware customers. In this episode, we closely analyze the situation. First, we look at Broadcom’s past acquisitions in the infrastructure sector. Then we examine the product alignment and possible new product offerings and whether the acquisition will hamper innovation and development. We also cover... Read more »Mobile World Congress 2024 to Focus on 5G, AI, and IoT
Next week's global mobility event also spotlights four connected industries: manufacturing, transportation, FinTech, and sports and entertainment.Supercharging the Smart City with AI-Enhanced Edge Computing
The integration of AI-enhanced edge computing in smart cities revolutionizes urban management, optimizing resource allocation, enhancing security, promoting sustainability, and fostering citizen engagement. That ultimately leads to a higher quality of life for residents.Implementing ‘Undo’ Functionality in Network Automation
Kurt Wauters sent me an interesting challenge: how do we do rollbacks based on customer requests? Here’s a typical scenario:
You might have deployed a change that works perfectly fine from a network perspective but broke a customer application (for example, due to undocumented usage), so you must be able to return to the previous state even if everything works. Everybody says you need to “roll forward” (improve your change so it works), but you don’t always have that luxury and might need to take a step back. So, change tracking is essential.
He’s right: the undo functionality we take for granted in consumer software (for example, Microsoft Word) has totally spoiled us.
Implementing ‘Undo’ Functionality in Network Automation
Kurt Wauters sent me an interesting challenge: how do we do rollbacks based on customer requests? Here’s a typical scenario:
You might have deployed a change that works perfectly fine from a network perspective but broke a customer application (for example, due to undocumented usage), so you must be able to return to the previous state even if everything works. Everybody says you need to “roll forward” (improve your change so it works), but you don’t always have that luxury and might need to take a step back. So, change tracking is essential.
He’s right: the undo functionality we take for granted in consumer software (for example, Microsoft Word) has totally spoiled us.
HW21: The State of the Wi-Fi Industry with Claus Hetting
Wi-Fi increases the GDP of entire countries, yet its tech community still has a grassroots feel. The COVID-19 work-from-home trend grew residential Wi-Fi like never before, yet it is still competing with 5G inside homes. Guest Claus Hetting, CEO of Wi-Fi NOW, joins host Keith Parsons to talk about the paradoxes, successes, and challenges in... Read more »The Internet Exchange of the Future: Scalable, Automated, Secure
As products and services become increasingly digital and our economies ever more dependent on data exchange, high-performance, resilient, and secure interconnection is becoming an increasingly relevant economic success factor.PP002: The Tricky Biz Of Secrets Management
Today we look at secrets management and privileged access management from the perspective of a network engineer. How do you and your team securely store sensitive data including passwords, SSH keys, API keys, and private certificate keys, while still being able to work nimbly? What Privileged Access Management (PAM) practices can help put guardrails in... Read more »Why Is BFD More Light Weight Than Routing Hellos?
There are many articles on BFD. It is well known that BFD has the following advantages over routing protocol hellos/keepalives:
- BFD is more light weight than hellos/keepalives.
- Multiple clients can register to BFD instead of configuring each protocol with aggressive timers.
- On some platforms, BFD can be offloaded to the hardware instead of the CPU.
- BFD provides faster timers than routing protocols.
- BFD is less CPU intensive.
What does light weight mean, though? Does it mean that the packets are smaller? Let’s compare a BFD packet to an OSPF Hello. Starting with the OSPF Hello:
Frame 269: 114 bytes on wire (912 bits), 114 bytes captured (912 bits) on interface ens192, id 1
Ethernet II, Src: 00:50:56:ad:8d:3c, Dst: 01:00:5e:00:00:05
Internet Protocol Version 4, Src: 203.0.113.0, Dst: 224.0.0.5
Open Shortest Path First
OSPF Header
Version: 2
Message Type: Hello Packet (1)
Packet Length: 48
Source OSPF Router: 192.168.128.223
Area ID: 0.0.0.0 (Backbone)
Checksum: 0x7193 [correct]
Auth Type: Null (0)
Auth Data (none): 0000000000000000
OSPF Hello Packet
OSPF LLS Data Block
There’s 114 bytes on the wire consisting of:
- 20 bytes of IP.
- 14 bytes of Ethernet.
- 80 bytes of Continue reading
Applying BGP Policy Templates
I got this question after publishing the BGP Session Templates lab exercise:
Would you apply BGP route maps with a peer/policy template or directly to a BGP neighbor? Of course, it depends; however, I believe in using a template for neighbors with the same general parameters and being more specific per neighbor when it comes to route manipulation.
As my reader already pointed out, the correct answer is It Depends, now let’s dig into the details ;)
Applying BGP Policy Templates
I got this question after publishing the BGP Session Templates lab exercise:
Would you apply BGP route maps with a peer/policy template or directly to a BGP neighbor? Of course, it depends; however, I believe in using a template for neighbors with the same general parameters and being more specific per neighbor when it comes to route manipulation.
As my reader already pointed out, the correct answer is It Depends, now let’s dig into the details ;)
Manage VyOS Devices with SaltStack
https://codingpackets.com/blog/manage-vyos-devices-with-saltstack
Network Layer: Interface or Node Addresses
The fun question about network layer addresses is: are we addressing nodes or individual node interfaces? On the data link layer, we never had this issue because it was obvious that a data link layer endpoint is an interface, so each interface should have a unique data link layer address.
Interestingly, that’s not the case on transparent bridges. Even though they have multiple interfaces, the whole bridge has a single MAC address, so one could claim we’re addressing nodes connected to a single data link layer. The IEEE standard is unambiguous: in every relevant diagram, the MAC address sits on top of multiple interfaces because the MAC address belongs to the control plane.