OSPFv3 Router ID Documentation on Arista EOS
When I published a blog post making fun of the ridiculously incorrect Cisco IOS/XE OSPFv3 documentation, an engineer working for Cisco quickly sent me an email saying, “Well, the other vendors are not much better.”
Let’s see how well Arista EOS is doing; this is their description of the router-id command (taken from EOS 4.35.0F documentation; unchanged for at least a dozen releases):

How to Turbocharge Your Kubernetes Networking With eBPF
When your Kubernetes cluster handles thousands of workloads, every millisecond counts. And that pressure is no longer the exception; it is the norm. According to a recent CNCF survey, 93% of organizations are using, piloting, or evaluating Kubernetes, revealing just how pervasive it has become.
Kubernetes has grown from a promising orchestration tool into the backbone of modern infrastructure. As adoption climbs, so does pressure to keep performance high, networking efficient, and security airtight.
However, widespread adoption brings a difficult reality. As organizations scale thousands of interconnected workloads, traditional networking and security layers begin to strain. Keeping clusters fast, observable, and protected becomes increasingly challenging.
Innovation at the lowest level of the operating system—the kernel—can provide faster networking, deeper system visibility, and stronger security. But developing programs at this level is complex and risky. Teams running large Kubernetes environments need a way to extend the Linux kernel safely and efficiently, without compromising system stability.
Why eBPF Matters for Kubernetes Networking
Enter eBPF (extended Berkeley Packet Filter), a powerful technology that allows small, verified programs to run safely inside the kernel. It gives Kubernetes platforms a way to move critical logic closer to where packets actually flow, providing sharper visibility Continue reading
NAN107: How AI is Changing the Networking Landscape
The world of networking is changing at lightning speed thanks to AI. Today Eric sits down with Chris Kane to explore this new reality for network engineers. Together, they dive deeper into some of the changes that will be coming next, breaking down the technical demands and mindset shifts of intellectual curiosity and humility necessary... Read more »TCG063: Constraint Drives Innovation with John Capobianco
Recorded live at AutoCon4, William Collins and Eyvonne Sharp join forces with John Capobianco for some in the moment thoughts and reflections on the AutoCon experience – from the in-person connections to the workshops to the stage presentations. John gives us the inside story on his very own workshop and the latest version releases in... Read more »Testing IP Multicast with netlab
Aleksandr Albin built a large (almost 20-router) lab topology (based on an example from Jeff Doyle’s Routing TCP/IP Volume 2) that he uses to practice inter-AS IP multicast. He also published the topology file (and additional configuration templates) on GitHub and documented his experience in a LinkedIn post.
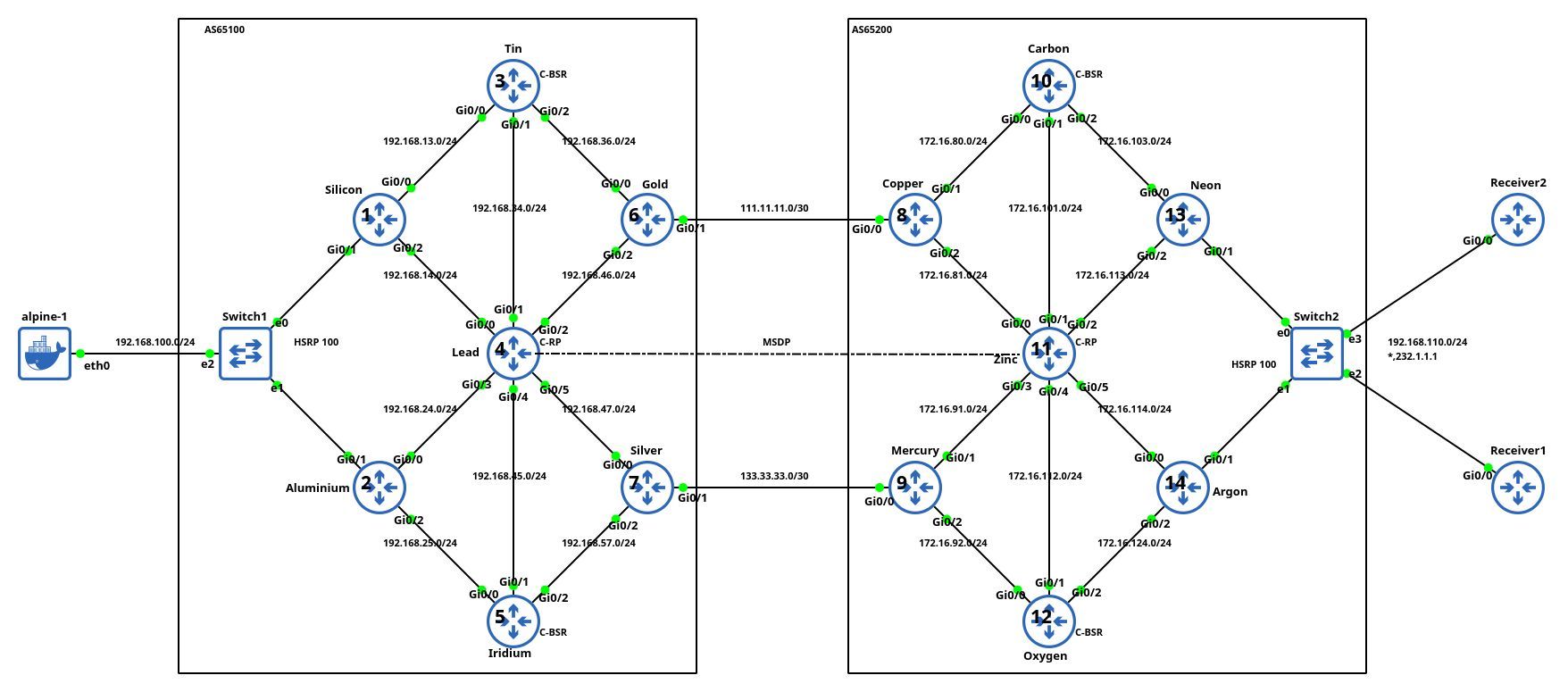
Lab topology, copied with permission by Aleksandr Albin
It’s so nice to see engineers using your tool in real-life scenarios. Thanks a million, Aleksandr, for sharing it.
PP088: How Fortinet Delivers Web App Security in the AI Era (Sponsored)
Web applications have always been tricky to protect. They’re meant to be accessible over the Internet, which exposes them to malicious actors, they’re designed to take end-user inputs, which can be manipulated for malicious purposes, and they often handle sensitive data. Then the rise of public cloud and microservices architectures added new layers of complexity... Read more »HS118: Bricking the Company – Discussing Existential Threats with Leadership
AI and other technologies are increasingly capable of delivering company-ending events. How do you have “the conversation” with senior leadership–the one about the existential risks your organization faces, and the steps needed for remediation–in a way that ensures that your company is maximally protected, and that you get the resources you need? AdSpot Sponsor: Meter ... Read more »A Second Look at Geolocation and Starlink
Civil unrest can often cloud measurement data. Some measurement systems, including the one we use at APNIC Labs, make relatively sweeping assumptions about the stability of both end user behaviour and network service behaviours, and assume that the changes that occur from day-to-day are minor. During times of civil unrest those assumptions are pretty dubious, and this applies to our measurements of ISP market share in Yeman and Myanmar.Multi-Pod EVPN Troubleshooting (Route Targets)
Last week, we fixed the incorrect BGP next hops in our sample multi-pod EVPN fabric. With that fixed, every PE device should see every other PE device as a remote VTEP for ingress replication purposes. However, that’s not the case; let’s see why and fix it.
Note: This is the fourth blog post in the Multi-Pod EVPN series. If you stumbled upon it, start with the design overview and troubleshooting overview posts. More importantly, familiarize yourself with the topology we’ll be using; it’s described in the Multi-Pod EVPN Troubleshooting: Fixing Next Hops.
Ready? Let’s go. Here’s our network topology:
Partnering with Black Forest Labs to bring FLUX.2 [dev] to Workers AI
In recent months, we’ve seen a leap forward for closed-source image generation models with the rise of Google’s Nano Banana and OpenAI image generation models. Today, we’re happy to share that a new open-weight contender is back with the launch of Black Forest Lab’s FLUX.2 [dev] and available to run on Cloudflare’s inference platform, Workers AI. You can read more about this new model in detail on BFL’s blog post about their new model launch here.
We have been huge fans of Black Forest Lab’s FLUX image models since their earliest versions. Our hosted version of FLUX.1 [schnell] is one of the most popular models in our catalog for its photorealistic outputs and high-fidelity generations. When the time came to host the licensed version of their new model, we jumped at the opportunity. The FLUX.2 model takes all the best features of FLUX.1 and amps it up, generating even more realistic, grounded images with added customization support like JSON prompting.
Our Workers AI hosted version of FLUX.2 has some specific patterns, like using multipart form data to support input images (up to 4 512x512 images), and output images up to 4 megapixels. The multipart form Continue reading
5 Reasons to Switch to the Calico Ingress Gateway (and How to Migrate Smoothly)
The End of Ingress NGINX Controller is Coming: What Comes Next?
The Ingress NGINX Controller is approaching retirement, which has pushed many teams to evaluate their long-term ingress strategy. The familiar Ingress resource has served well, but it comes with clear limits: annotations that differ by vendor, limited extensibility, and few options for separating operator and developer responsibilities.
The Gateway API addresses these challenges with a more expressive, standardized, and portable model for service networking. For organizations migrating off Ingress NGINX, the Calico Ingress Gateway, a production-hardened, 100% upstream distribution of Envoy Gateway, provides the most seamless and secure path forward.
If you’re evaluating your options, here are the five biggest reasons teams are switching now followed by a step-by-step migration guide to help you make the move with confidence.
Reason 1: The Future Is Gateway API and Ingress Is Being Left Behind
Ingress NGINX is entering retirement. Maintaining it will become increasingly difficult as ecosystem support slows. The Gateway API is the replacement for Ingress and provides:
- A portable and standardized configuration model
- Consistent behaviour across vendors
- Cleaner separation of roles
- More expressive routing
- Support for multiple protocols
Calico implements the Gateway API directly and gives you an Continue reading
UET Data Transfer Operation: Work Request Entity and Semantic Sublayer
Work Request Entity (WRE)
[SES part updated 7-Decembr 2025: text and figure]
The UET provider constructs a Work Request Entity (WRE) from a fi_write RMA operation that has been validated and passed by the libfabric core. The WRE is a software-level representation of the requested transfer and semantically describes both the source memory (local buffer) and the target memory (remote buffer) for the operation. Using the WRE, the UET provider constructs the Semantic Sublayer (SES) header and the Packet Delivery Context (PDC) header.
From the local memory perspective, the WRE specifies the address of the data in registered local memory, the length of the data, and the local memory key (lkey). This information allows the NIC to fetch the data directly from local memory when performing the transmission.
From the target memory perspective, the WRE describes the Resource Index (RI) table, which contains information about the destination memory region, including its base address and the offset within that region where the data should be written. The RI table also defines the allowed operations on the region. Because an RI table may contain multiple entries, the actual memory region is selected using the rkey, which is also included in the WRE. Continue reading
NB553: Palo Alto Networks Acquires Chronosphere; New Agentic AI Products for Orchestration and Networking
Take a Network Break! We start with a relative path traversal vulnerability in Fortinet’s FortiWeb. We’ll move on to an acquisition by Palo Alto Networks, another hiccup from our friends at Cloudflare, some AI announcements by Itential and Gluware, and finish with first quarter 2026 fiscal results from Palo Alto Networks. AdSpot Sponsor: Itential ... Read more »Tech Bytes: How IBM SevOne Delivers App-Centric Network Observability (Sponsored)
A lot of network monitoring tools allow you to say, “It’s not the network,” but a more useful tool would not only tell you that it’s not the network, but also what the problem actually is. Today our guest is Brandon Hale, CTO at IBM SevOne. He is here to give us an overview of... Read more »Get better visibility for the WAF with payload logging
As the surface area for attacks on the web increases, Cloudflare’s Web Application Firewall (WAF) provides a myriad of solutions to mitigate these attacks. This is great for our customers, but the cardinality in the workloads of the millions of requests we service means that generating false positives is inevitable. This means that the default configuration we have for our customers has to be fine-tuned.
Fine-tuning isn’t an opaque process: customers have to get some data points and then decide what works for them. This post explains the technologies we offer to enable customers to see why the WAF takes certain actions — and the improvements that have been made to reduce noise and increase signal.
Cloudflare’s WAF protects origin servers from different kinds of layer 7 attacks, which are attacks that target the application layer. Protection is provided with various tools like:
Managed rules, which security analysts at Cloudflare write to address common vulnerabilities and exposures (CVE), OWASP security risks, and vulnerabilities like Log4Shell.
Custom rules, where customers can write rules with the expressive Rules language.
Rate limiting rules, malicious uploads detection Continue reading
IOS/XR Route Redistribution Configuration Mess
One would hope that the developers of a network operating system wouldn’t feel the irresistible urge to reinvent what should have been a common configuration feature for every routing protocol. Alas, the IOS/XR developers failed to get that memo.
I decided to implement route redistribution (known as route import in netlab) for OSPFv2/OSPFv3, IS-IS, and BGP on IOS/XR (Cisco 8000v running IOS/XR release 24.4.1) and found that each routing protocol uses a different syntax for the source routing protocol part of the redistribute command.
Hedge 289: Containerlab
If you are struggling with building labs on lighter weight systems–or if you’re just interested in what Containerlab is and does–join Rick, Roman, and Russ for this discussion of what Containerlab is, what it does, and where its going.