Heavy Networking 661: Home Labbing With EVE-NG And Juniper
Today on Heavy Networking, home labs. Specifically, we’re going to discuss building and using a lab with virtualized Juniper gear in EVE-NG. Our guest is Christian Scholz, who has written and presented quite a bit on this topic.
The post Heavy Networking 661: Home Labbing With EVE-NG And Juniper appeared first on Packet Pushers.
Heavy Networking 661: Home Labbing With EVE-NG And Juniper
Today on Heavy Networking, home labs. Specifically, we’re going to discuss building and using a lab with virtualized Juniper gear in EVE-NG. Our guest is Christian Scholz, who has written and presented quite a bit on this topic. ve probably heard about HTTP resource prioritization. This is especially true since last year, as Chromium added so-called “Priority Hints†with the new fetchpriority attribute, which allow you to tweak said prioritizations.
ve probably heard about HTTP resource prioritization. This is especially true since last year, as Chromium added so-called “Priority Hints†with the new fetchpriority attribute, which allow you to tweak said prioritizations.Cloud CNI privately connects your clouds to Cloudflare

This post is also available in 简体中文, 日本語 and Español.

For CIOs, networking is a hard process that is often made harder. Corporate networks have so many things that need to be connected and each one of them needs to be connected differently: user devices need managed connectivity through a Secure Web Gateway, offices need to be connected using the public Internet or dedicated connectivity, data centers need to be managed with their own private or public connectivity, and then you have to manage cloud connectivity on top of it all! It can be exasperating to manage connectivity for all these different scenarios and all their privacy and compliance requirements when all you want to do is enable your users to access their resources privately, securely, and in a non-intrusive manner.
Cloudflare helps simplify your connectivity story with Cloudflare One. Today, we’re excited to announce that we support direct cloud interconnection with our Cloudflare Network Interconnect, allowing Cloudflare to be your one-stop shop for all your interconnection needs.
Customers using IBM Cloud, Google Cloud, Azure, Oracle Cloud Infrastructure, and Amazon Web Services can now open direct connections from their private cloud instances into Cloudflare. In this blog, we’re going Continue reading
CIO Week 2023 recap

This post is also available in 日本語, 简体中文, and Español.

In our Welcome to CIO Week 2023 post, we talked about wanting to start the year by celebrating the work Chief Information Officers do to keep their organizations safe and productive.
Over the past week, you learned about announcements addressing all facets of your technology stack – including new services, betas, strategic partnerships, third party integrations, and more. This recap blog summarizes each announcement and labels what capability is generally available (GA), in beta, or on our roadmap.
We delivered on critical capabilities requested by our customers – such as even more comprehensive phishing protection and deeper integrations with the Microsoft ecosystem. Looking ahead, we also described our roadmap for emerging technology categories like Digital Experience Monitoring and our vision to make it exceedingly simple to route traffic from any source to any destination through Cloudflare’s network.
Everything we launched is designed to help CIOs accelerate their pursuit of digital transformation. In this blog, we organized our announcement summaries based on the three feelings we want CIOs to have when they consider partnering with Cloudflare:
- CIOs now have a simpler roadmap to Zero Trust and SASE: We announced Continue reading
CIO Week 2023の要約

CIO Week 2023へようこその記事で、最高情報責任者が組織の安全性と生産性を維持するために行っている仕事を称えることで、1年をスタートさせたいという話をしました。
この一週間で、新サービス、ベータ版、戦略的パートナーシップ、サードパーティとの統合など、テクノロジースタックのあらゆる側面に関わる発表をご覧いただきました。この要約のブログでは、各発表を要約し、一般公開(GA)、ベータ版にある機能、またはロードマップ上に記載されている機能をラベル付けしています。
私たちは、さらに包括的なフィッシング対策機能やMicrosoftのエコシステムとのより深い統合機能など、お客様からご要望いただいた重要な機能を提供しました。今後については、Digital Experience Monitoringのような新しい技術カテゴリーのロードマップや、Cloudflareのネットワークを通じて任意のソースから任意の宛先へのトラフィックのルーティングを極めて簡単なものにするという私たちのビジョンについても説明しました。
私たちが立ち上げたものはすべて、CIOの方々へDXへの取り組みを加速していただくために設計されたものです。本ブログでは、CIOの方々がCloudflareとの提携を検討する際に抱いてほしい3つの感情を軸に、発表内容を整理しました。
- CIOの皆様によるZero TrustとSASEへのロードマップを策定がより簡単に:組織にZero Trustセキュリティベストプラクティスを採用し、Secure Access Service Edge(SASE)といった意欲的なアーキテクチャに移行しやすくする新機能と緊密な統合を発表しました。
- CIOの皆様が適切なテクノロジーとチャネルパートナーを見つけることを可能に:組織が適切な専門知識にアクセスして、すでに使用しているテクノロジーを使ってITとセキュリティを自分のペースで近代化するための統合とプログラミングを発表しました。
- CIOの皆様によるマルチクラウド戦略の合理化を簡単に:多様性を極めるクラウド環境間におけるトラフィックの接続、保護、高速化の新たな方法を発表しました。
Cloudflareが開催する多くの2023年イノベーションウィークの第1弾CIO Weekをご覧いただき、ありがとうございます。私たちのイノベーションのペースについていくのは時には難しいかもしれませんが、このブログを読み、私たちの要約のウェビナーに登録していただければ幸いです!
ITとセキュリティを近代化し、組織におけるごCIOの業務をより快適にする方法についてご相談されたい方は、こちらのフォームにご記入ください。
Zero TrustとSASEへの旅をシンプルに
アクセスの保護
これらのブログ記事では、Zero Trustの達成に必要な、よりきめ細かな制御と包括的な可視化により、すべてのユーザーがあらゆるアプリケーションに迅速、簡単、かつ安全に接続することに焦点を当てています。
| ブログ | まとめ |
|---|---|
| ベータ版: デジタルエクスペリエンスモニタリングのご紹介 | Cloudflare Digital Experience Monitoringは、CIOが重要なアプリケーションやインターネットサービスが企業ネットワーク全体でどのように機能しているかを理解するためのオールインワンダッシュボードですベータ版アクセスに登録する。 |
| ベータ版: WARP-to-WARPでCloudflare上のグローバルなプライベート仮想Zero Trustネットワーク構築を実現 | WARP(Cloudflareのデバイスクライアント)を実行している組織内のデバイスは、ワンクリックでWARPを実行している他のデバイスにプライベートネットワーク経由で到達することができます。ベータ版アクセスに登録する。 |
| 一般公開: Cloudflare Accessの「ブロックされた」メッセージをトラブルシューティングする新たな方法 | CloudflareのZero TrustプラットフォームでユーザIDのトラブルシューティングと同じレベルの容易さで、接続の経緯に基づいて、「許可」、または「ブロック」の決定を調査します。 |
| ベータ版: 社内およびSaaSアプリケーション向けのワンクリックデータセキュリティ | 分離されたブラウザでアプリケーションセッションを実行してユーザーが機密データを操作する方法を制御することで、機密データを保護しましょう – たったのワンクリックです。ベータ版アクセスに登録する。 |
| 一般公開: Cloudflare Access & Gatewayに対するSCIMの対応を発表 | CloudflareのZTNA(Access)およびSWG(Gateway)サービスは、System for Cross-domain Identity Management(SCIM)プロトコルをサポートするようになったことで、管理者はシステム間でIDレコードを管理しやすくなりました。 |
| 一般公開: Cloudflare Zero Trust:1983年以来最もエキサイティングなPingのリリース | Cloudflare Zero Trustの管理者は、ICMPプロトコルを使用する使い慣れたデバッグツール(Ping、Traceroute、MTRなど)を使用して、プライベートネットワークの宛先への接続をテストすることができます。 |
脅威防御
これらのブログ記事では、組織がフィッシング、ランサムウェア、その他のインターネットの脅威からユーザーを保護するために、トラフィックをフィルタリング、検査、分離することに焦点を当てています。
| ブログ | まとめ |
|---|---|
| 一般公開: メールリンク分離:最新のフィッシング攻撃に対するセーフティネット | 「メールリンク分離」は、ユーザーがクリックしてしまう可能性のある受信箱に届いた不審なリンクに対するセーフティネットです。この保護が追加されることで、Cloudflare Area 1は、フィッシング攻撃から守る最も包括的な電子メールセキュリティソリューションとなります。 |
| 一般公開: Cloudflare Gatewayに自社による証明書を導入 | 管理者は、独自のカスタム証明書を使用して、HTTP、DNS、CASB、DLP、RBI、その他のフィルタリングポリシーを適用することができます。 |
| 一般公開: カスタムDLPプロファイルを発表 | Cloudflareのデータ喪失防止(DLP)サービスは、カスタム検出を作成する機能を提供したことで、組織はトラフィックを検査して最も機密性の高いデータを検出できるようになりました。 |
| 一般公開: マネージドサービスプロバイダー向けCloudflare Zero Trust | 米国連邦政府をはじめとする大規模なマネージドサービスプロバイダ(MSP)が、CloudflareのテナントAPIを利用して、管理する組織全体にDNSフィルタリングなどのセキュリティポリシーを適用している事例をご紹介します。 |
セキュアなSaaS環境
これらのブログ記事では、SaaSアプリケーション環境において一貫したセキュリティと可視性を維持し、特に機密データの漏洩を防止することに焦点を当てています。
| ブログ | まとめ |
|---|---|
| ロードマップ: Cloudflare CASB とDLPが連携してデータを保護する仕組み | Cloudflare Zero Trustは、CASBサービスとDLPサービス間で、管理者がSaaSアプリケーションに保存されているファイルを覗き見して、その中の機密データを特定できる機能を導入する予定です。 |
| ロードマップ: Cloudflare Area 1 とDLPが連携してメール内のデータを保護する仕組み | Cloudflareでは、Area 1 Email Securityとデータ喪失防止(DLP)の機能を組み合わせ、企業のEメールに完全なデータ保護を提供します。 |
| 一般公開: Cloudflare CASB:SalesforceとBoxのセキュリティ上の問題をスキャン | Cloudflare CASBは、SalesforceおよびBoxと統合し、ITおよびセキュリティチームがこれらのSaaS環境に潜むセキュリティリスクのスキャンを可能にします。 |
接続の高速化と保護
Iこのセクションのブログ記事では、製品の機能に加えて、組織がCloudflareを利用して実現している速度やその他の戦略的なメリットについて紹介しています。
China Express: Cloudflare partners to boost performance in China for corporate networks


Cloudflare has been helping global organizations offer their users a consistent experience all over the world. This includes mainland China, a market our global customers cannot ignore but that continues to be challenging for infrastructure teams trying to ensure performance, security and reliability for their applications and users both in and outside mainland China. We are excited to announce China Express — a new suite of capabilities and best practices in partnership with our partners China Mobile International (CMI) and CBC Tech — that help address some of these performance challenges and ensure a consistent experience for customers and employees everywhere.
Cloudflare has been providing Application Services to users in mainland China since 2015, improving performance and security using in-country data centers and caching. Today, we have a presence in 30 cities in mainland China thanks to our strategic partnership with JD Cloud. While this delivers significant performance improvements, some requests still need to go back to the origin servers which may live outside mainland China. With limited international Internet gateways and restrictive cross-border regulations, international traffic has a very high latency and packet drop rate in and out of China. This results in inconsistent cached content within China and Continue reading
Cloudflare Application Services for private networks: do more with the tools you already love


Cloudflare’s Application Services have been hard at work keeping Internet-facing websites and applications secure, fast, and reliable for over a decade. Cloudflare One provides similar security, performance, and reliability benefits for your entire corporate network. And today, we’re excited to announce new integrations that make it possible to use these services together in new ways. These integrations unlock operational and cost efficiencies for IT teams by allowing them to do more with fewer tools, and enable new use cases that are impossible without Cloudflare’s “every service everywhere” architecture.
“Just as Canva simplifies graphic design, Cloudflare simplifies performance and security. Thanks to Cloudflare, we can focus on growing our product and expanding into new markets with confidence, knowing that our platform is fast, reliable, and secure.” - Jim Tyrrell, Head of Infrastructure, Canva
Every service everywhere, now for every network
One of Cloudflare’s fundamental architectural principles has always been to treat our network like one homogeneous supercomputer. Rather than deploying services in specific locations - for example, using some of our points of presence to enforce WAF policies, others for Zero Trust controls, and others for traffic optimization - every server runs a virtually identical stack of all of Continue reading
Cloudflare Zero Trust for managed service providers
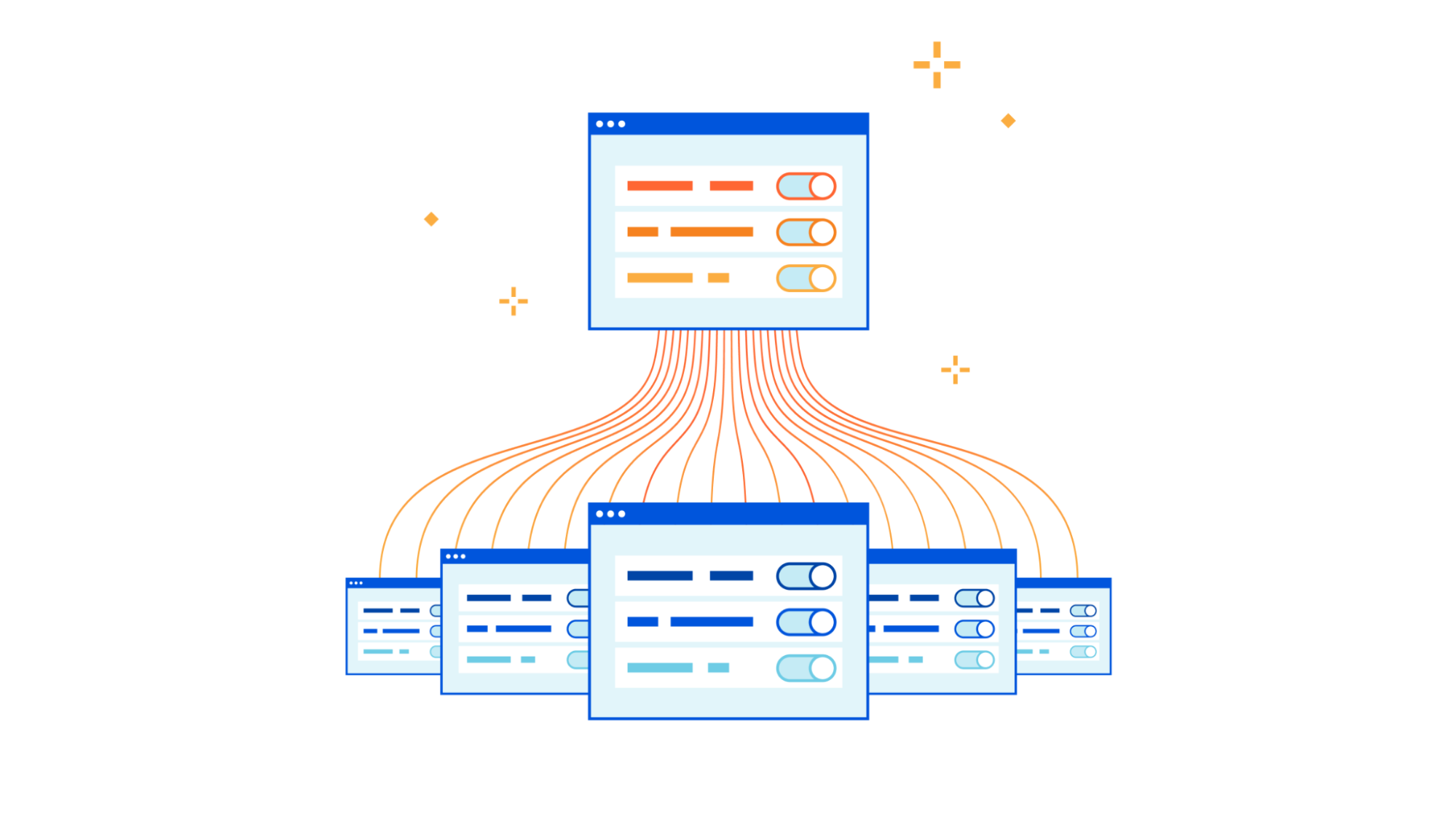
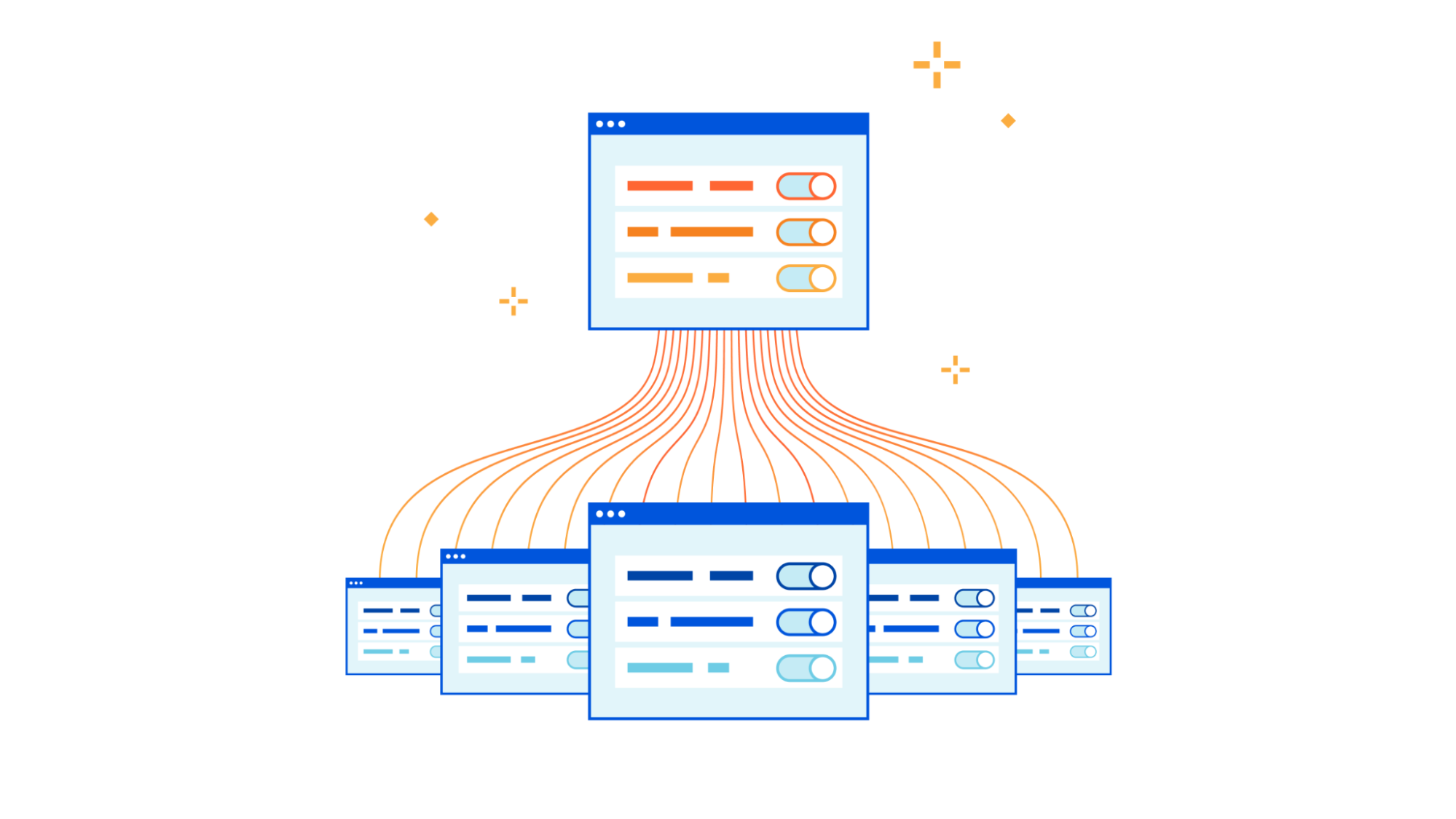
As part of CIO week, we are announcing a new integration between our DNS Filtering solution and our Partner Tenant platform that supports parent-child policy requirements for our partner ecosystem and our direct customers. Our Tenant platform, launched in 2019, has allowed Cloudflare partners to easily integrate Cloudflare solutions across millions of customer accounts. Cloudflare Gateway, introduced in 2020, has grown from protecting personal networks to Fortune 500 enterprises in just a few short years. With the integration between these two solutions, we can now help Managed Service Providers (MSPs) support large, multi-tenant deployments with parent-child policy configurations and account-level policy overrides that seamlessly protect global employees from threats online.
Why work with Managed Service Providers?
Managed Service Providers (MSPs) are a critical part of the toolkit of many CIOs. In the age of disruptive technology, hybrid work, and shifting business models, outsourcing IT and security operations can be a fundamental decision that drives strategic goals and ensures business success across organizations of all sizes. An MSP is a third-party company that remotely manages a customer's information technology (IT) infrastructure and end-user systems. MSPs promise deep technical knowledge, threat insights, and tenured expertise across a variety Continue reading
Give us a ping. (Cloudflare) One ping only.


Ping was born in 1983 when the Internet needed a simple, effective way to measure reachability and distance. In short, ping (and subsequent utilities like traceroute and MTR) provides users with a quick way to validate whether one machine can communicate with another. Fast-forward to today and these network utility tools have become ubiquitous. Not only are they now the de facto standard for troubleshooting connectivity and network performance issues, but they also improve our overall quality of life by acting as a common suite of tools almost all Internet users are comfortable employing in their day-to-day roles and responsibilities.
Making network utility tools work as expected is very important to us, especially now as more and more customers are building their private networks on Cloudflare. Over 10,000 teams now run a private network on Cloudflare. Some of these teams are among the world's largest enterprises, some are small crews, and yet others are hobbyists, but they all want to know - can I reach that?
That’s why today we’re excited to incorporate support for these utilities into our already expansive troubleshooting toolkit for Cloudflare Zero Trust. To get started, sign up to receive beta access and start using the Continue reading
Video: MLAG with EVPN Deep Dive
In November 2022 I described some of the intricacies of using EVPN to implement MLAG control plane. You might have noticed that I didn’t dive deep into EVPN details, and I had a good reason for that – Lukas Krattiger did a wonderful job describing how MLAG works with EVPN in the EVPN Deep Dive webinar.
You need Free ipSpace.net Subscription to watch the video. To watch the whole webinar, buy Standard or Expert ipSpace.net Subscription.
Video: MLAG with EVPN Deep Dive
In November 2022 I described some of the intricacies of using EVPN to implement MLAG control plane. You might have noticed that I didn’t dive deep into EVPN details, and I had a good reason for that – Lukas Krattiger did a wonderful job describing how MLAG works with EVPN in the EVPN Deep Dive webinar.
You need Free ipSpace.net Subscription to watch the video. To watch the whole webinar, buy Standard or Expert ipSpace.net Subscription.
Hedge 161: Going Dark with Geoff Huston
 Encrypt everything! Now! We don’t often do well with absolutes like this in the engineering world–we tend to focus on “get it down,” and not to think very much about the side effects or unintended consequences. What are the unintended consequences of encrypting all traffic all the time? Geoff Huston joins Tom Ammon and Russ White to discuss the problems with going dark.
Encrypt everything! Now! We don’t often do well with absolutes like this in the engineering world–we tend to focus on “get it down,” and not to think very much about the side effects or unintended consequences. What are the unintended consequences of encrypting all traffic all the time? Geoff Huston joins Tom Ammon and Russ White to discuss the problems with going dark.
Using Pynetbox to Create Netbox API Tokens
As a warning to everyone, I am not a developer. I am a network engineer who is trying to do some automation stuff. Some of what I’m doing sounds logical to me, but I would not trust my own opinions for production work. I’m sure you can find a Slack channel or Mastodon instance with people who can tell you how to do things properly.
The last time, I talked about using pynetbox to make queries to Netbox. This was a very simple example, and one of the things that bugged me the most about it was the API token. In that post, we used a statically-assigned API token where I went into the Netbox GUI and generated one for myself. I think I may have even noted that this was definitely not the best way to handle those things. A possibly-better way to do it is to use your username and password on Netbox to generate a token for yourself. This would a token that you then delete when you’re done.
How is this better? The static tokens are just that — they’re static. If you generate your token, then anyone who has it can use it to Continue reading