Network Security Demands Drive SD-WAN and SASE Adoption
Many businesses find they must adopt SD-WAN and SASE to meet the needs of modern connectivity and networking. Does yours? Take our survey.GA Week 2022: what you may have missed

Back in 2019, we worked on a chart for Cloudflare’s IPO S-1 document that showed major releases since Cloudflare was launched in 2010. Here’s that chart:
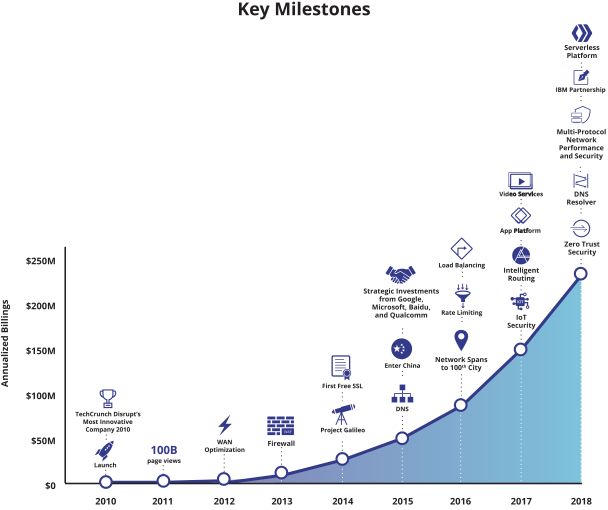
Of course, that chart doesn’t show everything we’ve shipped, but the curve demonstrates a truth about a growing company: we keep shipping more and more products and services. Some of those things start with a beta, sometimes open and sometimes private. But all of them become generally available after the beta period.
Back in, say, 2014, we only had a few major releases per year. But as the years have progressed and the company has grown we have constant updates, releases and changes. This year a confluence of products becoming generally available in September meant it made sense to wrap them all up into GA Week.
GA Week has now finished, and the team is working to put the finishing touches on Birthday Week (coming this Sunday!), but here’s a recap of everything that we launched this week.
| What launched | Summary | Available for? |
|---|---|---|
| Monday (September 19) | ||
| Cloudforce Continue reading |
 s Grace processor will be among the first chips to use its upcoming Neoverse V2 CPU cores.
s Grace processor will be among the first chips to use its upcoming Neoverse V2 CPU cores.EX4400 VC Ports Conversation
This week I am in the Juniper Campus Networks with Mist AI ( JCMA ) course and going over the …
The post EX4400 VC Ports Conversation first appeared on Fryguy's Blog.How to enable Private Access Tokens in iOS 16 and stop seeing CAPTCHAs


You go to a website or service, but before access is granted, there’s a visual challenge that forces you to select bikes, buses or traffic lights in a set of images. That can be an exasperating experience. Now, if you have iOS 16 on your iPhone, those days could be over and are just a one-time toggle enabled away.
CAPTCHA = "Completely Automated Public Turing test to tell Computers and Humans Apart"
In 2021 and 2022, we took direct steps to end the madness that wastes humanity about 500 years per day called CAPTCHAs, that have been making sure you’re human and not a bot. In August 2022, we announced Private Access Tokens. With that, we’re able to eliminate CAPTCHAs on iPhones, iPads and Macs (and more to come) with open privacy-preserving standards.
On September 12, iOS 16 became generally available (iPadOS 16 and macOS 13 should arrive in October) and on the settings of your device there’s a toggle that can enable the Private Access Token (PAT) technology that will eliminate the need for those CAPTCHAs, and automatically validate that you are a real human visiting a site. If you already have iOS 16, here’s what you should Continue reading
Video: Cloud-Native Environments
One of the overused buzzwords of the cloudy days is the Cloud-Native Environment. What should that mean and why could that be better than what we’ve been doing decades ago? Matthias Luft and Florian Barth tried to answer that question in the Introduction to Cloud Computing webinar.
You need Free ipSpace.net Subscription to watch the video.
Video: Cloud-Native Environments
One of the overused buzzwords of the cloudy days is the Cloud-Native Environment. What should that mean and why could that be better than what we’ve been doing decades ago? Matthias Luft and Florian Barth tried to answer that question in the Introduction to Cloud Computing webinar.
You need Free ipSpace.net Subscription to watch the video.
Hedge 148: The SRE with Niall Murphy (part 2)

It seems like only yesterday we started talking about the Site Reliability Engineer, and their place in the IT ecosystem. Over the last several years, the role of the SRE has changed—and it’s bound to continue changing. On this episode of the Hedge, Niall Murphy joins Tom Ammon and Russ White to discuss the changing role of the SRE, and what the SRE could be.
If you want to read more on this topic, check out Niall’s article over a USENIX.
IPv6 Buzz 110: The Peculiar Power Of DHCPv6 Option 108
On today's IPv6 Buzz podcast we explore DHCPv6 Option 108. Option 108 basically allows a DHCP server to use IPv4 to contact a host and tell that host to disable its IPv4 stack and switch to IPv6-only. In other words, you're using IPv4 to turn off IPv4. We examine the use cases for this peculiar capability.
The post IPv6 Buzz 110: The Peculiar Power Of DHCPv6 Option 108 appeared first on Packet Pushers.