Ansible For Network Automation Lesson 1: Why Ansible? – Video
Welcome to Ansible For Networking! There are ten video lessons in this course. This course provides a detailed overview of how Ansible works, how to create playbooks and modules, the importance of idempotency, and a walk-through using Ansible to automate tasks in a Meraki WLAN. It’s intended for network administrators and engineers who want to […]
The post Ansible For Network Automation Lesson 1: Why Ansible? – Video appeared first on Packet Pushers.
Waiting Room Event Scheduling protects your site during online events
You've got big plans for your ecommerce strategy in the form of online events — seasonal sales, open registration periods, product drops, ticket sales, and more. With all the hype you've generated, you'll get a lot of site traffic, and that's a good thing! With Waiting Room Event Scheduling, you can protect your servers from being overloaded during your event while delivering a user experience that is unique to the occasion and consistent with your brand. Available now to enterprise customers with an advanced Waiting Room subscription, Event Scheduling allows you to plan changes to your waiting room’s settings and custom queueing page ahead of time, ensuring flawless execution of your online event.
More than always-on protection
We launched Waiting Room to protect our customers' servers during traffic spikes. Waiting Room sends excess visitors to a virtual queue during traffic surges, letting visitors in dynamically as spots become available on your site. By automatically queuing traffic that exceeds your site's capacity, Waiting Room protects your origin servers and your customer experience. Additionally, the Waiting Room's queuing page can be customized to match the look and feel of your site so that your users never feel as though they have left Continue reading
Network Break 389: Alleged IT Fraudsters Indicted; HPE Floats GreenLake Private Cloud
Take a Network Break! This week we cover two separate indictments against alleged schemers who sold counterfeit Cisco gear and pirated Avaya license keys. We also cover new products from Juniper Networks, VMware, and HPE. Meanwhile Starlink targets maritime vessels with a satellite broadband offering.6 Cloud Monitoring Use Cases and Why You Should Care
End-to-end visibility of application and network performance from on-premises to the cloud is critical for efficient and accurate network monitoring.Kubernetes For Network Engineers: Lesson 1 – A Brief Overview Of The Kubernetes Architecture – Video
This video series introduces essential Kubernetes concepts for network engineers who want to learn more about containers and Kubernetes and how to support the networking requirements of Kubernetes-based applications. The series will cover the Kubernetes architecture; services, node ports, and load balancers; ingress and service mesh; and other topics that network engineers should be familiar […]
The post Kubernetes For Network Engineers: Lesson 1 – A Brief Overview Of The Kubernetes Architecture – Video appeared first on Packet Pushers.
Kubernetes For Network Engineers: Lesson 3 – Pod-To-Pod Networking – Video
In lesson 3, instructor Michael Levan explores the basics of connecting Kubernetes pods via kube-proxy. Michael Levan brings his background in system administration, software development, and DevOps to this video series. He has Kubernetes experience as both a developer and infrastructure engineer. He’s also a consultant and Pluralsight author, and host of the “Kubernetes Unpacked” […]
The post Kubernetes For Network Engineers: Lesson 3 – Pod-To-Pod Networking – Video appeared first on Packet Pushers.
Privacy for Providers
While this talk is titled privacy for providers, it really applies to just about every network operator. This is meant to open a conversation on the topic, rather than providing definitive answers. I start by looking at some of the kinds of information network operators work with, and whether this information can or should be considered “private.” In the second part of the talk, I work through some of the various ways network operators might want to consider when handling private information.
Understanding OSPF Router ID (RID) Assignment
This post originally appeared on the Packet Pushers’ Ignition site on March 24, 2020. In both OSPFv2 (IPv4) and OSPFv3 (IPv6), the router ID (RID) is a 32-bit number assigned to the router. The RID must be unique within the OSPF network, as a RID provides a point of origin for link state advertisements (LSAs). […]
The post Understanding OSPF Router ID (RID) Assignment appeared first on Packet Pushers.
Introducing Location-Aware DDoS Protection
We’re thrilled to introduce Cloudflare’s Location-Aware DDoS Protection.
Distributed Denial of Service (DDoS) attacks are cyber attacks that aim to make your Internet property unavailable by flooding it with more traffic than it can handle. For this reason, attackers usually aim to generate as much attack traffic as they can — from as many locations as they can. With Location-Aware DDoS Protection, we take this distributed characteristic of the attack, that is thought of being advantageous for the attacker, and turn it on its back — making it into a disadvantage.
Location-Aware DDoS Protection is now available in beta for Cloudflare Enterprise customers that are subscribed to the Advanced DDoS service.
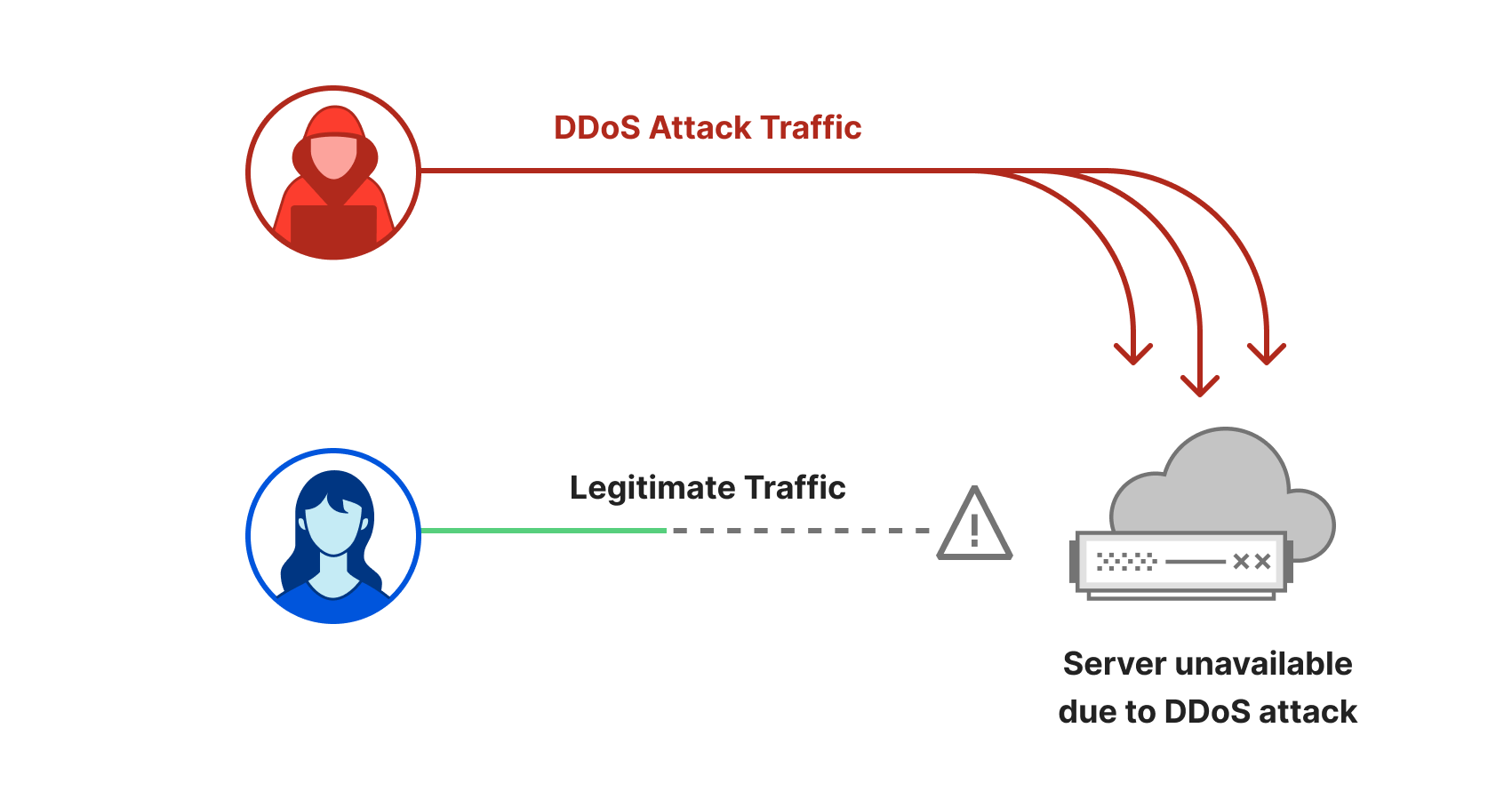
Distributed attacks lose their edge
Cloudflare’s Location-Aware DDoS Protection takes the attacker’s advantage and uses it against them. By learning where your traffic comes from, the system becomes location-aware and constantly asks “Does it make sense for your website?” when seeing new traffic.
For example, if you operate an e-commerce website that mostly serves the German consumer, then most of your traffic would most likely originate from within Germany, some from neighboring European countries, and a decreasing amount as we expand globally to other countries and geographies. If Continue reading
pygnmi 14. Using skip-verify for self-signed certificates
Hello my friend,
lab testing is one of the crucial parts of any new technology introduction. At the same time, we know that in labs we typically have a lower security requirements. For example, we use SSL certificates, but we don’t have proper PKI and, therefore, certificates are self-signed.
2
3
4
5
retrieval system, or transmitted in any form or by any
means, electronic, mechanical or photocopying, recording,
or otherwise, for commercial purposes without the
prior permission of the author.
Is GNMI a Good Interface for Network Automation?
Yes, it is. GNMI is one of the most recent interfaces created for the management plane, which allows you to manage the network devices (i.e., retrieve configuration and operational data, modify configuration) and collect the streaming or event-driven telemetry. Sounds like one-size-fits-all, isn’t it? On top of that, GNMI supports also different transport channels (i.e., encrypted and non-encrypted), which makes it suitable both for lab testing and for production environment. You may feel that we are biased to gNMI, and you are right. Actually, that is a reason why we created pyGNMI library, Open Continue reading
Juniper Apstra Part II – Building a data center rack
In this post, we’ll start designing the building blocks for our data center deployment with Juniper Apstra. We’ll look at how to design a rack.
A look at QUIC Use
QUIC as recently been standardized by the IETF and is now in the initial stages of deployment. Let's take a look at the current state of the use of QUIC in today's Internet.EVPN-VXLAN Explainer 6 – Symmetrical IRB
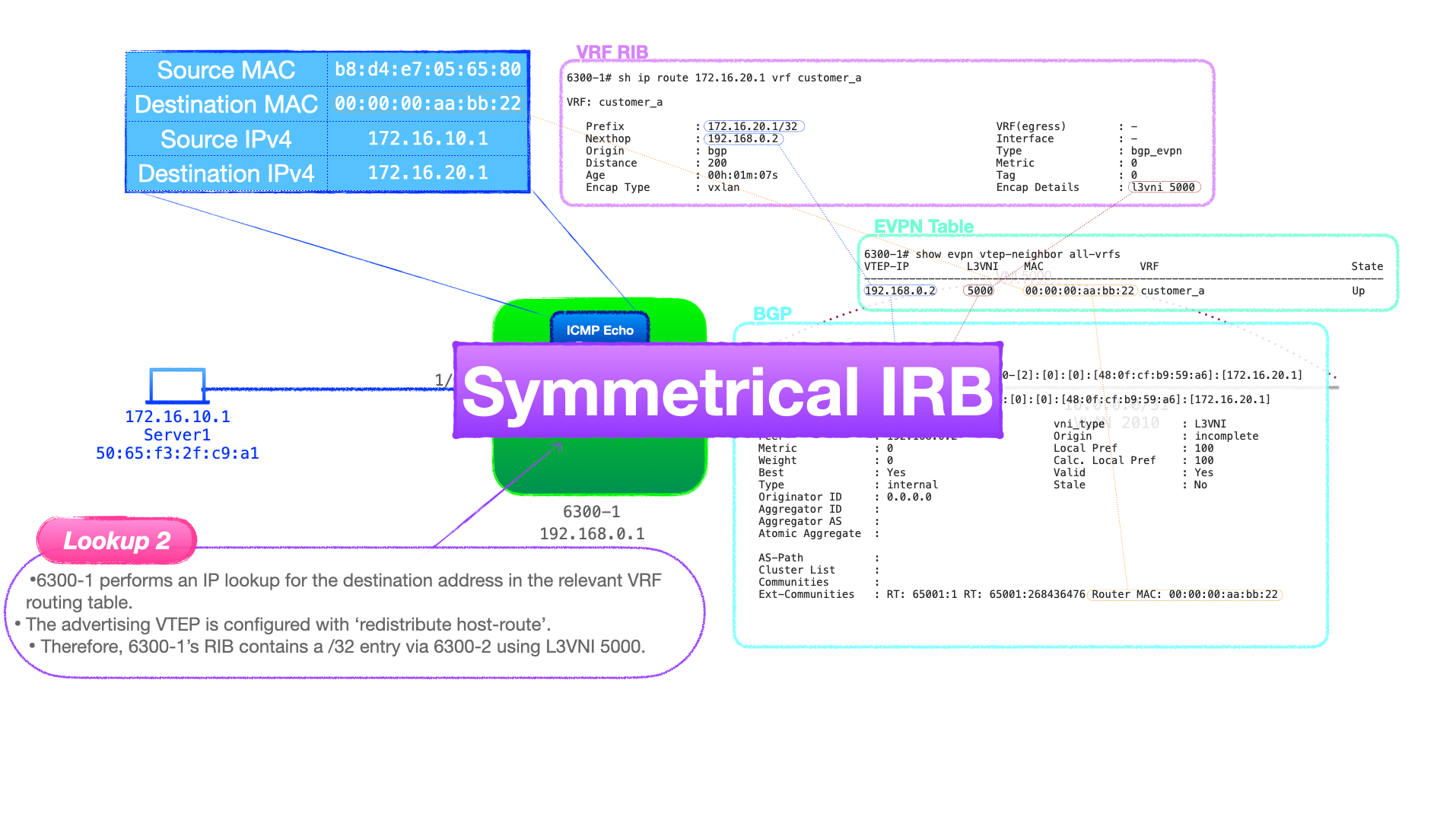
Now let's continue our look at routing with EVPN-VXLAN as we focus on symmetrical IRB.
This post is essentially building upon a lot of what we covered in the previous post. So, if you haven't read that yet, please do, then meet me back here. This post will make a lot more sense if you do.
🔬 Symmetrical IRB in Detail
While symmetrical and asymmetrical IRB have the same functional outcome; to route inter-subnet traffic, there are a number of major differences in the requirements and configuration of each.
Most notably, symmetrical IRB frees us from the requirement to configure all VLANs & L2VNIs on all VTEPs.
Here's an overview of the features and components that we'll be covering:
Symmetrical IRB Architecture Notes
- Symmetrical IRB offers a more scalable approach to routing VXLAN traffic because VTEPs are not required to have knowledge of all destination clients, they do not need to hold an ARP cache entry for a destination, unlike asymmetrical IRB.
- VTEPs are only configured with the VLANs, subnets and VNIs that host locally connected clients.
- To ensure successful end-to-end connectivity for inter-subnet traffic, a number of new requirements and features are deployed with symmetrical IRB:
- A L3VNI for Continue reading
Getting Tough with Cyberinsurance

I’ve been hearing a lot of claims recently about how companies are starting to rely more and more on cyberinsurance policies to cover them in the event of a breach or other form of disaster. While I’m a fan of insurance policies in general I think the companies trying to rely on these payouts to avoid doing any real security work is going to be a big surprise to them in the future.
Due Diligence
The first issue that I see is that companies are so worried about getting breached that they think taking out big insurance policies are the key to avoiding any big liability. Think about an organization that holds personally identifiable information (PII) and how likely it is that they would get sued in the event of a breach. The idea is that cyberinsurance would pay out for the breach and be used as a way to pay off the damages in a lawsuit.
The issue I have with this is that companies are expecting to get paid. They see cyberinsurance as a guaranteed payout instead of a last resort. In the initial days of taking out these big policies the insurers were happy to pay out Continue reading