Extend Fortinet FortiGate to Kubernetes with Calico Enterprise 2.7
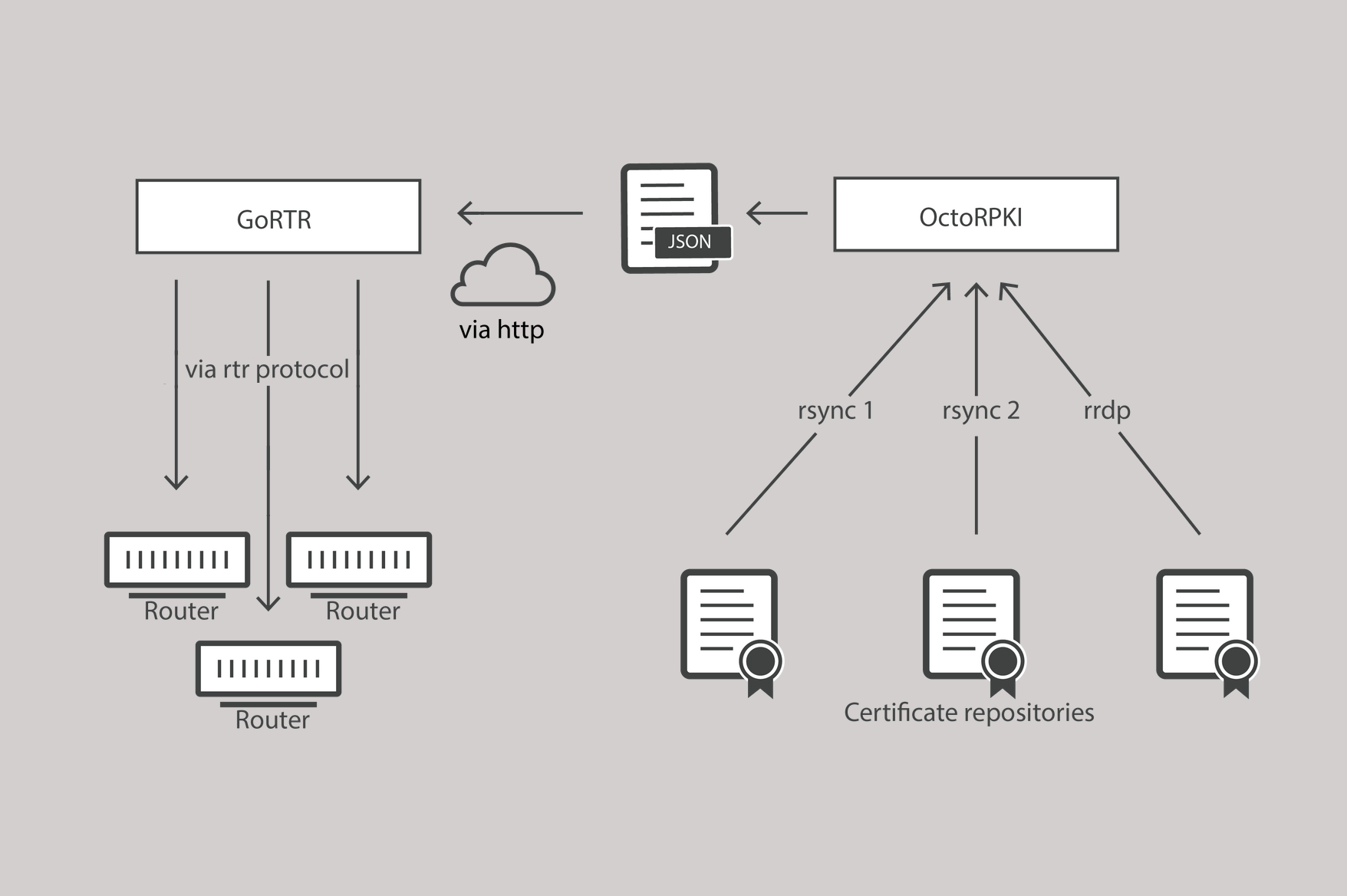
We are excited to announce the general availability of Calico Enterprise 2.7. With this release, Fortinet’s 400,000 customers can use FortiGate to enforce network security policies into and out of the Kubernetes cluster as well as traffic between pods within the cluster.
- Kubernetes workloads populate the Fortigate GUI
- The network team can then create and enforce policies in Fortigate and have them enforced as Calico Policy
- Saves time and money and lets the network team retain the firewall responsibility (which also frees up time for ITOps)

We have also added many new exciting capabilities that help platform engineers blow through barriers blocking their path to production, and advanced cybersecurity capabilities for those already running production workloads.
- Manage Network Security Across Multiple Kubernetes Clusters
- Enforce a Common Set of Security Controls Across Multiple Clusters
- Detect and Alert on Unauthorized Changes and Other Attack Vectors
- Self-Service Troubleshooting for End Users
- Detect and Prevent Malicious Data Exfiltration
Manage Network Security Across Multiple Kubernetes Clusters
As the adoption of Kubernetes continues to accelerate, our customers are seeing the number of clusters in their environments rapidly multiplying. This has created a management challenge for IT Ops teams who are constantly pushed to find ways Continue reading