New Day, New Role
I’m thrilled to announce that I’ve recently stepped into a new role as Solutions Architect at Sweetwater Technology Services! This opportunity marks a significant milestone in my career, allowing me to deepen my expertise and broaden my impact in designing and delivering IT solutions for clients across diverse sectors. What This Means In this role, …
The post New Day, New Role first appeared on StaticNAT.
Leadership vs Management
Leadership and management these two are often used interchangeably but are they interchangeable? Do we consider all managers to also be leaders and are all leaders managers? While the best managers will have traits of a good leader and visa-versa these two roles are not always synonymous. First thing we will want to do is […]AI for Network Engineers: Chapter 2 – Backpropagation Algorithm: Introduction
This chapter introduces the training model of a neural network based on the Backpropagation algorithm. The goal is to provide a clear and solid understanding of the process without delving deeply into the mathematical formulas, while still explaining the fundamental operations of the involved functions. The chapter also briefly explains why, and in which phases the training job generates traffic to the network, and why lossless packet transport is required. The Backpropagation algorithm is composed of two phases: the Forward pass (computation phase) and the Backward pass (adjustment and communication phase).
In the Forward pass, neurons in the first hidden layer calculate the weighted sum of input parameters received from the input layer, which is then passed to the neuron's activation function. Note that neurons in the input layer are not computational units; they simply pass the input variables to the connected neurons in the first hidden layer. The output from the activation function of a neuron is then used as input for the connected neurons in the next layer, whether it is another hidden layer or the output layer. The result of the activation function in the output layer represents the model's prediction, which is compared to the expected Continue reading
Wrapping up another Birthday Week celebration
2024 marks Cloudflare’s 14th birthday. Birthday Week each year is packed with major announcements and the release of innovative new offerings, all focused on giving back to our customers and the broader Internet community. Birthday Week has become a proud tradition at Cloudflare and our culture, to not just stay true to our mission, but to always stay close to our customers. We begin planning for this week of celebration earlier in the year and invite everyone at Cloudflare to participate.
Months before Birthday Week, we invited teams to submit ideas for what to announce. We were flooded with submissions, from proposals for implementing new standards to creating new products for developers. Our biggest challenge is finding space for it all in just one week — there is still so much to build. Good thing we have a birthday to celebrate each year, but we might need an extra day in Birthday Week next year!
In case you missed it, here’s everything we announced during 2024’s Birthday Week:
Monday
|
What |
In a sentence… |
|
Start auditing and controlling the AI models accessing your content |
Understand which AI-related bots and crawlers can access your website, and which content you choose to allow Continue reading |
IS-IS Labs: Configure IS-IS Routing for IPv4
In the first exercise in the IS-IS labs series, you’ll configure IS-IS routing for IPv4. The basic configuration is trivial, but you’ll also have to tweak the defaults that most vendors got wrong (we’ll discuss why those defaults are wrong in the next lab exercises).

I also tried to make the IS-IS labs more than just lab exercises. Each exercise includes a bit of background information or IS-IS theory; this one describes generic OSI addresses (NSAPs) and router addresses (NETs).
Consolidating WAN Backbone with EVPN
Recently I was exploring how to consolidate layer-2 & layer-3 connectivity across WAN backbone network. In this write I have covered (IP-Prefixes handling as EVPN Type 5 Routes) and in subsequent writeup I will cover E-LAN and E-Line use cases as well.
https://github.com/kashif-nawaz/Consolidating_WAN_Backbone_with_EVPN

Palo Alto App-ID – How Does It Work?

If you've ever worked with traditional Layer 4 firewalls, you might be familiar with configuring security policies based on TCP or UDP port numbers. For instance, to allow DNS, you'd create a policy for UDP/53, or for LDAP, a policy for TCP/389.
This approach is normal with firewalls like Cisco ASA. But it's 2024, and Next-Generation Firewalls (NGFWs) have become the standard, offering a more sophisticated way to manage security. Instead of relying solely on port numbers, NGFWs like those from Palo Alto Networks encourage defining security policies based on the actual applications termed 'App-ID'. For example, instead of specifying port numbers, a policy could simply be defined to allow 'DNS' and 'LDAP', focusing on the applications themselves.
Palo Alto App-ID Introduction
Okay, that sounds simple, so why continue reading you may ask? Well, while Palo Alto’s App-ID does work well most of the time, there are nuances that you need to understand. For applications like DNS, NTP, and LDAP, App-ID works very well. However, the most common applications involve SSL or web browsing, typically associated with ports 80 and 443.
Palo Alto provides App-IDs for both SSL and Web-Browsing (called ssl and web-browsing Continue reading
HN751: Top Tips for Building A CCIE-EI Lab
The Packet Pushers and guest Mason Reimert discuss strategies he’s using to prepare for the Cisco CCIE Enterprise Infrastructure lab exam. Mason shares practical tips for hands-on labbing for both established and emerging technologies like SD-WAN and SD-Access, resource management, virtualization tools, and automation. He also highlights the importance of understanding APIs, data formats, and... Read more »Expanding Cloudflare’s support for open source projects with Project Alexandria
At Cloudflare, we believe in the power of open source. It’s more than just code, it’s the spirit of collaboration, innovation, and shared knowledge that drives the Internet forward. Open source is the foundation upon which the Internet thrives, allowing developers and creators from around the world to contribute to a greater whole.
But oftentimes, open source maintainers struggle with the costs associated with running their projects and providing access to users all over the world. We’ve had the privilege of supporting incredible open source projects such as Git and the Linux Foundation through our open source program and learned first-hand about the places where Cloudflare can help the most.
Today, we're introducing a streamlined and expanded open source program: Project Alexandria. The ancient city of Alexandria is known for hosting a prolific library and a lighthouse that was one of the Seven Wonders of the Ancient World. The Lighthouse of Alexandria served as a beacon of culture and community, welcoming people from afar into the city. We think Alexandria is a great metaphor for the role open source projects play as a beacon for developers around the world and a source of knowledge that is core to making a Continue reading
Advancing cybersecurity: Cloudflare implements a new bug bounty VIP program as part of CISA Pledge commitment
As our digital world becomes increasingly more complex, the importance of cybersecurity grows ever more critical. As a result, Cloudflare is proud to promote our commitment to the Cybersecurity and Infrastructure Security Agency (CISA) ‘Secure by Design’ pledge. The commitment is built around seven security goals, aimed at enhancing the safety of our products and delivering the most secure solutions to our customers.
Cloudflare’s commitment to the CISA pledge reflects our dedication to transparency and accountability to our customers, and to cybersecurity best practices. Furthermore, Cloudflare is committed to being a trusted partner by sharing our strategies to ensure the highest priority is placed on safeguarding our customers’ security.
Bug bounty VIP program
Cloudflare has successfully managed a public Vulnerability Disclosure Program (VDP) for years; our belief is that collaboration is the cornerstone of effective cybersecurity. We are excited to announce a major milestone in our journey to meet Goal #5 of the pledge: our program will now include a bug bounty VIP program in conjunction with our bug bounty public program.
Continuous investment in maturing our bug bounty program is a vital tool for the success of any security organization. By encouraging broader participation in vulnerability testing, Continue reading
Empowering builders: introducing the Dev Alliance and Workers Launchpad Cohort #4
Today we’re announcing the Dev Starter Pack, an alliance of innovative tools for developers to get started with discounts and free services. We’re also excited to share an update on our Workers Launchpad Program.
Creating from the ground up often means spending countless hours piecing together the right development stack, navigating different pricing models, and managing growing costs — all of which can take your focus away from what truly matters: building your product and growing your business.
Introducing Dev Starter Pack: the tools you need to start building your startup
Hey! Dani Grant here, one of the first PMs at Cloudflare and co-founder of Jam.dev. Ten years ago (during 2014’s Birthday Week), Cloudflare launched Universal SSL, making SSL free on the Internet for the first time, and in one night doubling the size of the encrypted web.
I was a college student back then, and I immediately became enraptured by Cloudflare’s mission: helping build a better Internet. As part of this mission, Cloudflare has developed powerful tools typically accessible only to Internet giants, oftentimes offering them for free to developers and individuals alike. Heck yeah! I joined Cloudflare in January 2015, and 5 years after that, co-founded Continue reading
Network trends and natural language: Cloudflare Radar’s new Data Explorer & AI Assistant
Cloudflare Radar showcases global Internet traffic patterns, attack activity, and technology trends and insights. It is powered by data from Cloudflare's global network, as well as aggregated and anonymized data from Cloudflare's 1.1.1.1 public DNS Resolver, and is built on top of a rich, publicly accessible API. This API allows users to explore Radar data beyond the default set of visualizations, for example filtering by protocol, comparing metrics across multiple locations or autonomous systems, or examining trends over two different periods of time. However, not every user has the technical know-how to make a raw API query or process the JSON-formatted response.
Today, we are launching the Cloudflare Radar Data Explorer, which provides a simple Web-based interface to enable users to easily build more complex API queries, including comparisons and filters, and visualize the results. And as a complement to the Data Explorer, we are also launching an AI Assistant, which uses Cloudflare Workers AI to translate a user’s natural language statements or questions into the appropriate Radar API calls, the results of which are visualized in the Data Explorer. Below, we introduce the AI Assistant and Data Explorer, and also dig into how we Continue reading
Reaffirming our commitment to free
Cloudflare launched our free tier at the same time our company launched — fourteen years ago, on September 27, 2010. Of course, a bit has changed since then — there are now millions of Internet properties behind Cloudflare. As we’ve grown in size and amassed millions of free customers, one of the questions we often get asked is: how can Cloudflare afford to do this at such scale?
Cloudflare always has, and always will, offer a generous free version for public-facing applications (Application Services), internal private networks and people (Cloudflare One), and developer tools (Developer Platform). Counterintuitively: our free service actually helps us keep our costs lower. Not only is it mission-aligned, our free tier is business-aligned. We want to make abundantly clear: our free plan is here to stay, and we reaffirmed that commitment this week with 15 releases across our product portfolio that make the Free plan even better.
Understanding our Cost of Goods Sold
To understand the economics of Free, you need to understand our Cost of Goods Sold (COGS). Cloudflare hasn’t outsourced its network — we built it ourselves, and it spans more than 330 cities. We design and ship Continue reading
Our container platform is in production. It has GPUs. Here’s an early look
We’ve been working on something new — a platform for running containers across Cloudflare’s network. We already use it in production for Workers AI, Workers Builds, Remote Browsing Isolation, and the Browser Rendering API. Today, we want to share an early look at how it’s built, why we built it, and how we use it ourselves.
In 2024, Cloudflare Workers celebrates its 7th birthday. When we first announced Workers, it was a completely new model for running compute in a multi-tenant way — on isolates, as opposed to containers. While, at the time, Workers was a pretty bare-bones functions-as-a-service product, we took a big bet that this was going to become the way software was going to be written going forward. Since introducing Workers, in addition to expanding our developer products in general to include storage and AI, we have been steadily adding more compute capabilities to Workers:
2020 | |
2021 | |
2022 | |
2023 | |
2024 |
With each of these, we’ve faced a question — can Continue reading
AI Everywhere with the WAF Rule Builder Assistant, Cloudflare Radar AI Insights, and updated AI bot protection
The continued growth of AI has fundamentally changed the Internet over the past 24 months. AI is increasingly ubiquitous, and Cloudflare is leaning into the new opportunities and challenges it presents in a big way. This year for Cloudflare’s birthday, we’ve extended our AI Assistant capabilities to help you build new WAF rules, added AI bot traffic insights on Cloudflare Radar, and given customers new AI bot blocking capabilities.
AI Assistant for WAF Rule Builder

At Cloudflare, we’re always listening to your feedback and striving to make our products as user-friendly and powerful as possible. One area where we've heard your feedback loud and clear is in the complexity of creating custom and rate-limiting rules for our Web Application Firewall (WAF). With this in mind, we’re excited to introduce a new feature that will make rule creation easier and more intuitive: the AI Assistant for WAF Rule Builder.
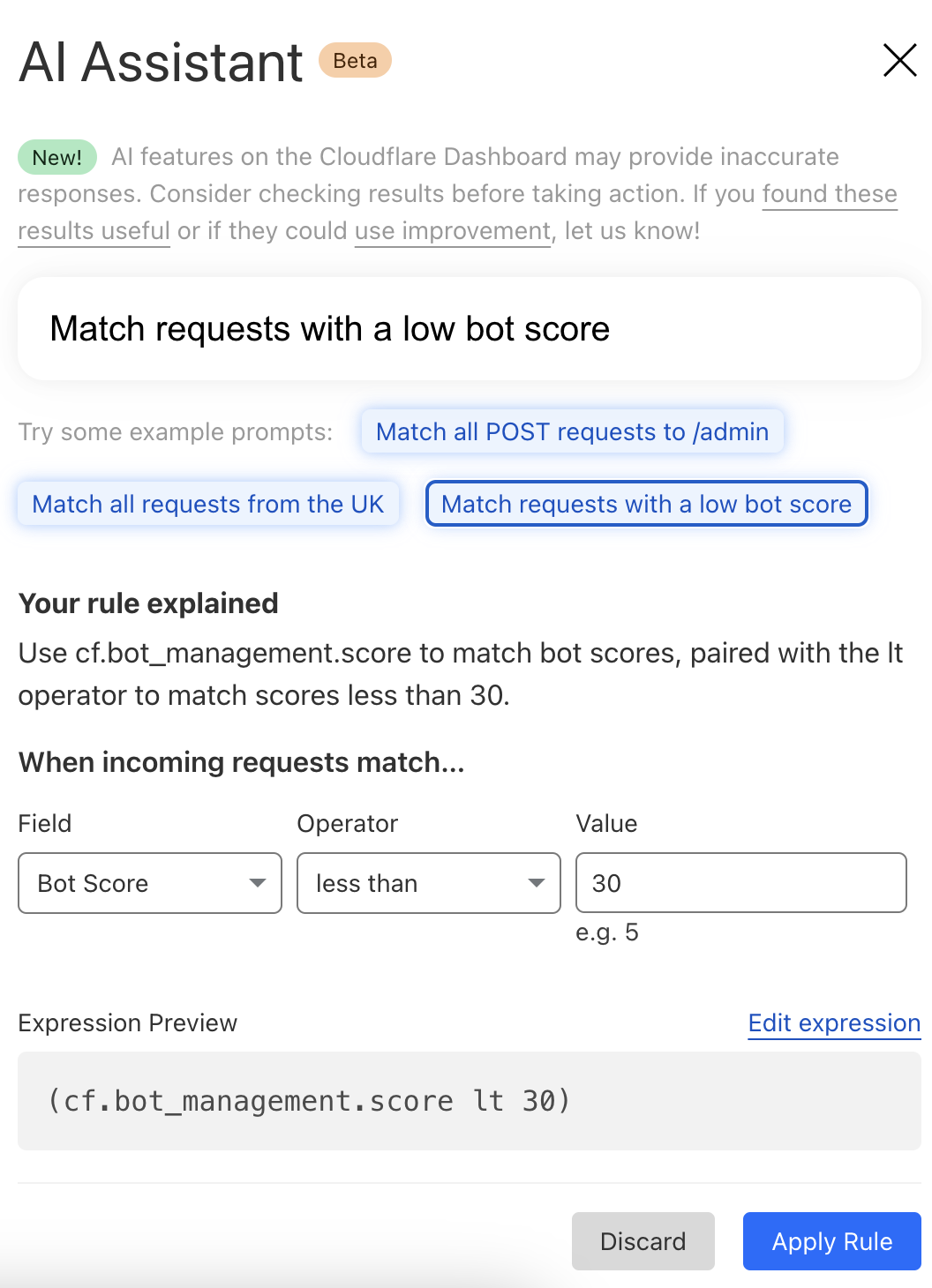
By simply entering a natural language prompt, you can generate a custom or rate-limiting rule tailored to your needs. For example, instead of manually configuring a complex rule matching criteria, you can now type something like, "Match requests with low bot score," and the assistant will generate the rule for Continue reading
Altera Is Being Realistic About FPGA Compute In The Datacenter
Like many a decade ago, we were enthusiastic about the prospect of triple-hybrid systems in the datacenter. …
Altera Is Being Realistic About FPGA Compute In The Datacenter was written by Timothy Prickett Morgan at The Next Platform.