Canonical Sharpens Focus on Red Hat, VMware; IPO Plans Remain
 The company has simplified its service offerings in an attempt to lower cost and attract more...
The company has simplified its service offerings in an attempt to lower cost and attract more...
The company has simplified its service offerings in an attempt to lower cost and attract more...
 SDxCentral Weekly Wrap for May 3, 2019: Dell EMC and Big Switch team up; Orange taps Dell for 5G...
SDxCentral Weekly Wrap for May 3, 2019: Dell EMC and Big Switch team up; Orange taps Dell for 5G...
 A year after HPE CEO Antonio Neri said “Dell doesn’t have an edge-to-cloud approach,” Dell...
A year after HPE CEO Antonio Neri said “Dell doesn’t have an edge-to-cloud approach,” Dell...

You’ve probably heard by now of the big launch of Cisco’s new 802.11ax (neé Wi-Fi 6) portfolio of devices. Cisco did a special roundtable with a group of influencers from the community called Just The Tech. Here’s a video from that event covering the APs that were released, the 9120:
Fred always does a great job of explaining the technical bits behind the APs. But one thing that caught my eye here is the name of the AP – Catalyst. Cisco has been using Aironet for their AP line since they purchased Aironet Wireless Communications back in 1999. The name was practically synonymous with wireless technologies for many people in the industry that worked exclusively with Cisco technologies.
So, is the name change something we should be concerned about?
Cisco moving toward a unified naming convention for their edge solutions makes a lot of sense. Ten years ago, wireless was still primarily 802.11g-based with 802.11n still a few months away from being proposed and ratified. Connectivity hadn’t quite yet reached the ubiquitous levels of wireless that we see today. The iPhone was only about to be on its third Continue reading
Wake up! It's HighScalability time:
Do you like this sort of Stuff? I'd greatly appreciate your support on Patreon. I wrote Explain the Cloud Like I'm 10 for people who need to understand the cloud. And who doesn't these days? On Amazon it has 45 mostly 5 star reviews (105 on Goodreads). They'll learn a lot and hold you in awe.
 VPN flaw uncovered in Cisco, F5, and more; Google Anthos soars to the clouds; and AT&T avoids...
VPN flaw uncovered in Cisco, F5, and more; Google Anthos soars to the clouds; and AT&T avoids...
 Vodafone Spain is to work with Huawei on a pilot in Andalusia, while Telefónica teams up with...
Vodafone Spain is to work with Huawei on a pilot in Andalusia, while Telefónica teams up with...
List of technical features that matter
The post A List Of What Makes WiFi 6 Technically Better ? appeared first on EtherealMind.
It is unlikely we can tell you anything new about the extended Berkeley Packet Filter, eBPF for short, if you've read all the great man pages, docs, guides, and some of our blogs out there.
But we can tell you a war story, and who doesn't like those? This one is about how eBPF lost its ability to count for a while1.
They say in our Austin, Texas office that all good stories start with "y'all ain't gonna believe this… tale." This one though, starts with a post to Linux netdev mailing list from Marek Majkowski after what I heard was a long night:
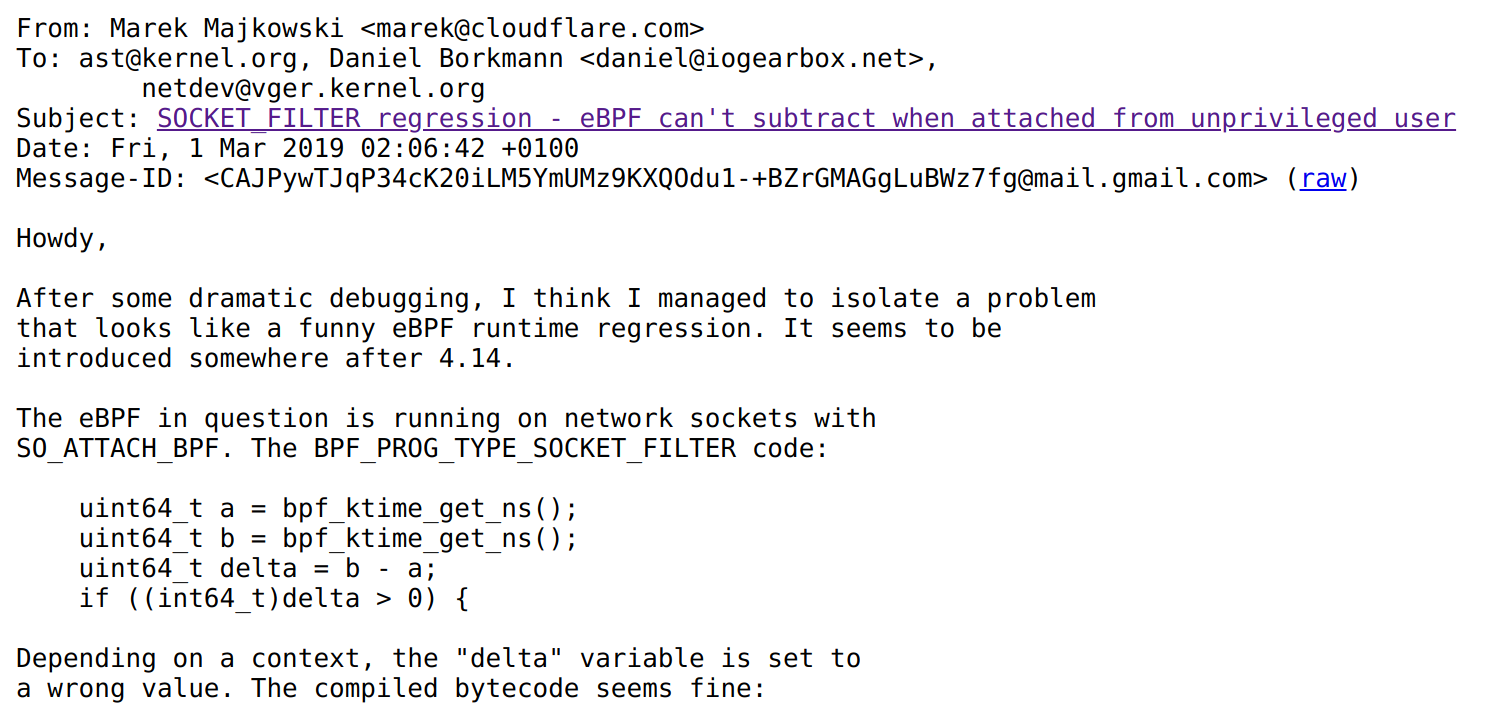
Marek's findings were quite shocking - if you subtract two 64-bit timestamps in eBPF, the result is garbage. But only when running as an unprivileged user. From root all works fine. Huh.
If you've seen Marek's presentation from the Netdev 0x13 conference, you know that we are using BPF socket filters as one of the defenses against simple, volumetric DoS attacks. So potentially getting your packet count wrong could be a Bad Thing™, and affect legitimate traffic.
Let's try to reproduce this bug with Continue reading
Welcome to Technology Short Take #113! I hope the collection of links and articles I’ve gathered for you contains something useful for you. I think I have a pretty balanced collection this time around; there’s a little bit of something for almost everyone. Who says you can’t please everyone all the time?
kube-iptables-tailer, which turns packet drops from iptables into Kubernetes events that can be logged for easier troubleshooting. The GitHub repository for the project is here.You know we like to stay busy here at Cumulus Networks, and April was no exception! We’ve rounded up some of our favorite podcasts, blog posts, and articles in case you missed them. So settle in and get ready for all things open networking!
From Cumulus Networks:
RIP up your dynamic routing with OSPF: Let’s RIP right into the ins and outs of Routing Information Protocol and Open Shortest Path First in this blog post by Keith Ward. Here we’ll discuss all things IGPs, history of RIPS and what you need to know about OSPFs.
Kernel of Truth season 2 episode 5: The power of community: Grab a pair of headphones and tune into Season 2 Episode 5 of our podcast, Kernel of Truth. In this episode, Brian O’ Sullivan talks with Angelo Luciani from Nutanix and our own Pete Lumbis about the power of community and self-service. Learn about the resources available surrounding building community and the importance of it all.
Cumulus NetQ Reinvented
Did you hear the news? We are pleased to announce the launch of our newest product, Cumulus NetQ! Cumulus NetQ is a highly-scalable, modern network operations toolset that provides visibility into and troubleshooting Continue reading
 The tech giant announced several new Azure cloud services ahead of its annual Build developers’...
The tech giant announced several new Azure cloud services ahead of its annual Build developers’...
This week at DockerCon 2019, we shared our strategy for helping companies realize the benefits of digital transformation through new enterprise solution offerings that address the most common application profile in their portfolio. Our new enterprise solution offerings include the Docker platform, new tooling and services needed to migrate your applications. Building on the success and the experience from the Modernize Traditional Applications (MTA) program and Docker Enterprise 3.0, we are excited to expand our solutions and play an even greater role in our customers’ innovation strategy by offering a complete and comprehensive path to application containerization.
When you hear about different application profiles, you may think about different languages or frameworks or even different application architectures like microservices and monoliths. But one of the benefits of containerization is that all application dependencies are abstracted away and what you have is a container that can be deployed consistently across different infrastructure.
In our work with many enterprise organizations, we’ve validated that the successful adoption of a container strategy is just as much about the people and processes as it is about the technology. There are 3 behavioral patterns that matter and that is dependent on what Continue reading
One reason China has a good chance of hitting its ambitious goal to reach exascale computing in 2020 is that the government is funding three separate architectural paths to attain that milestone. …
China Fleshes Out Exascale Design for Tianhe-3 Supercomputer was written by Michael Feldman at .
 Networking startup Stateless rolled out its first product: a software-defined interconnection...
Networking startup Stateless rolled out its first product: a software-defined interconnection...
 The carrier is looking to the OSF's Kata container project to solve multi-tenancy concerns with...
The carrier is looking to the OSF's Kata container project to solve multi-tenancy concerns with...

{kind=link}