Huawei Names Vendor Partners for Its Three-Layered SD-WAN
 Huawei is working with several third-party vendors to enhance its SD-WAN. These include Riverbed Technology, F5, and HPE.
Huawei is working with several third-party vendors to enhance its SD-WAN. These include Riverbed Technology, F5, and HPE.
Huawei is working with several third-party vendors to enhance its SD-WAN. These include Riverbed Technology, F5, and HPE.
 The open source Gimbal platform was developed with Heptio to avoid having to rip out OpenStack and legacy backend systems.
The open source Gimbal platform was developed with Heptio to avoid having to rip out OpenStack and legacy backend systems.
 The service allows customers to provision dedicated HCI nodes without buying their own infrastructure.
The service allows customers to provision dedicated HCI nodes without buying their own infrastructure.
 The group is working on several different projects focused on spectrum, 5G standards, regulations, and infrastructure.
The group is working on several different projects focused on spectrum, 5G standards, regulations, and infrastructure.
 Before deploying SD-WAN, the company was using “a spaghetti mess” of handcrafted tunnels with combinations of Sonicwall firewalls, third party tunnels, and Cisco ASA firewalls. The result was “awful and unreliable” connections.
Before deploying SD-WAN, the company was using “a spaghetti mess” of handcrafted tunnels with combinations of Sonicwall firewalls, third party tunnels, and Cisco ASA firewalls. The result was “awful and unreliable” connections.

Photo by Karsten Würth (@inf1783) / Unsplash
Cloudflare's mission is to help build a better Internet. While working toward our goals, we want to make sure our processes are conducted in a sustainable manner.
In an effort to do so, we’ve reduced Cloudflare’s environmental impact by contracting to purchase regional renewable energy certificates, or “RECs,” to match 100% of the electricity used in our North American data centers as well as our U.S. offices. Cloudflare now has servers in 154 unique cities around the world, with 38 located in North America. Cloudflare has opted to support geographically diverse projects in proximity to our office and data center electricity usage. This renewable energy initiative reduces our electricity-based carbon footprint by 5,561 tons of CO2 which has a positive environmental impact. The impact can be compared to growing 144,132 trees seedlings for 10 years, or taking 1,191 cars off the road for one year.
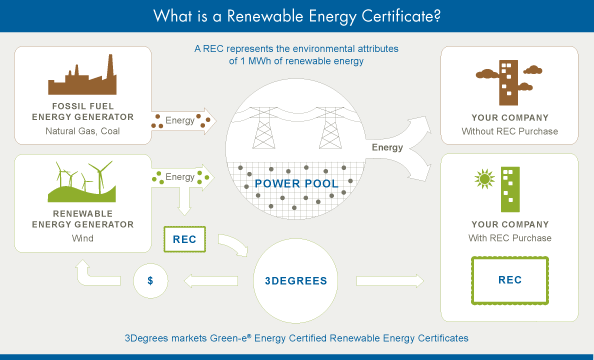
How does buying a REC help reduce Cloudflare's carbon footprint you may ask? When 1MWh of electricity is produced from a renewable generator, such as a wind turbine, there are two products: the energy, which is delivered to the grid and mixes with other forms of energy, Continue reading
Many network engineers find the entire world of telecom to be confusing—especially as papers are peppered with a lot of acronyms. If any part of the networking world is more obsessed with acronyms than any other, the telecom world, where the traditional phone line, subscriber access, and network engineering collide, reigns as the “king of the hill.”
Recently, while looking at some documentation for the CORD project, which stands for Central Office Rearchitected as a Data Center, I ran across an acronym I had not seen before—vOLT-HA. An acronym with a dash in the middle—impressive! But what is, exactly? To get there, we must begin in the beginning, with a PON.
There are two kinds of optical networks in the world, Active Optical Networks (AONs), and Passive Optical Networks (PONs). The primary difference between the two is whether the optical gear used to build the network amplifies (or even electronically rebuilds, or repeats) the optical signal as it passes through. In AONs, optical signals are amplified, while ins PONs, optical signals are not amplified. This means that in a PON, the optical equipment can be said to be passive, in that it does not modify the optical signal in Continue reading
AI Hits the Right Notes: Artificial intelligence-generated music is reshaping the industry, but that’s not such a bad thing, notes Billboard.com. AI won’t replace the artists we love or end creativity, but it could empower creators with new songwriting and other tools, the story suggests.
Drilling for AI: Oil producers are also turning to AI to help them with several tasks, according to an interview with oil executive Philippe Herve of SparkCongnition, published in Houston’s Chron.com. AI can assist oil producers with predictive maintenance of their expensive field equipment and help them make sense of all the data they collect, he said.
Collateral damage for app ban: Russia has attempted to shut down messaging app Telegram, after the service refused to provide authorities encryption keys to its software. It’s not going so well, however. Russian’s attempts to block the app have inadvertently knocked out a bunch of small business websites in the country, reports the New York Times. Telegram attempted to get around the ban by shifting its service to U.S. Web hosts Google Cloud and Amazon Web Services, while repeatedly changing its IP address. In response, Russia shut down huge blocks of subnets instead of trying Continue reading
When looking for all-flash storage arrays, there is no lack of options. Small businesses and hyperscalers alike helped fuel the initial uptake of flash storage several years ago, and since then larger businesses have taken the plunge to help drive savings in such areas as power and cooling costs, floor and rack space, and software licensing.
The increasing demand for the technology – see the rapid growth of Pure Storage, the original flash array upstart over the past nine years – has not only fueled the rise of smaller vendors but also the portfolio expansion of such established …
Vexata Has Its Own Twist On Scaling Flash Storage was written by Jeffrey Burt at The Next Platform.
One of the strategies Jacob Richter describes (How we built a big data platform on AWS for 100 users for under $2 a month) in his relentless drive to lower AWS costs is moving ML from the server to the client.
Moving work to the client is a time honored way of saving on server side costs. Not long ago it might have seemed like moving ML to the browser would be an insane thing to do. What was crazy yesterday often becomes standard practice today, especially when it works, especially when it saves money:
Our post-processing machine learning models are mostly K-means clustering models to identify outliers. As a further step to reduce our costs, we are now running those models on the client side using TensorFlow.js instead of using an autoscaling EC2 container. While this was only a small change using the same code, it resulted in a proportionally massive cost reduction.
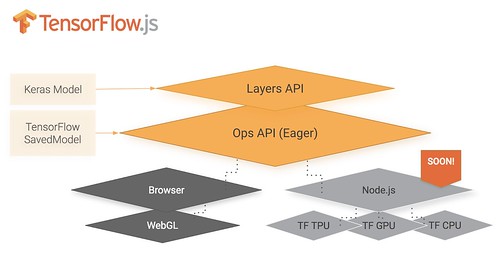
To learn more Alexis Perrier has a good article on Tensorflow with Javascript Brings Deep Learning to the Browser:
Tensorflow.js has four layers: The WebGL API for GPU-supported numerical operations, the web browser for user interactions, and two APIs: Continue reading
Because iptables was never meant to do what it does
Take a Network Break! The US and British governments have accused Russian state actors of compromising routers and other network infrastructure, the United States forbids American companies from selling components to Chinese telecom firm ZTE, and Huawei rethinks its US strategy.
Cisco releases notes on its 9500 switches and UADP silicon, IBM releases a mainframe that takes the same space as a traditional 19-inch server rack, and VMware shares rise on rumors that Dell won’t reverse-merge with it.
Arista’s share price stumbles, and then recovers; Cisco ditches the Spark brand name; a Cisco security exec says we’re all screwed; and the United States is the leading source of botnet attacks in the world.
Find links to all these stories just after our sponsor message.
InterOptic offers high-performance, high-quality optics at a fraction of the cost. Find out more at InterOptic.com, and if you re attending Interop 2018 in Vegas, stop by the InterOptic booth to learn how they can help you spec the right optics for your network.
Russian State-Sponsored Cyber Actors Targeting Network Infrastructure Devices – US-CERT
Huawei, Failing to Crack U.S. Market, Signals a Change in Tactics – The New York Times
 ZTE might look to judicial remedies after the U.S. ban; Huawei lays off its Washington, D.C. liason; and Twitter bans ads from Kaspersky Labs.
ZTE might look to judicial remedies after the U.S. ban; Huawei lays off its Washington, D.C. liason; and Twitter bans ads from Kaspersky Labs.
 As AI and ML begin to reach their full potential, the race is on between network administrators and attackers to implement the technologies into their procedures, for better or for worse.
As AI and ML begin to reach their full potential, the race is on between network administrators and attackers to implement the technologies into their procedures, for better or for worse.
Earlier Cisco dropped the band information, and now we have the bag information too! The bag this year is a …
The post Cisco Live 2018 – The BAG! appeared first on Fryguy's Blog.
Link – https://www.safaribooksonline.com/library/view/how-sre-relates/9781492030645
Quick Read – Few Pages
Other Books which are related to SRE
-> Site Reliability Engineering: How Google Runs Production Systems
Few Points that I liked
– Quick read , hardly an hour
– Intro on how Devops got introduced
– what needs to be improved – Key Idea “No More Silos”
– stress on non-localization of knowledge, lack of collaboration
– New Job Role called SRE – Site Reliability Engineering
– Operations is a Software problem and Work to minimize Toil are some best examples of productivity and how we should view
– Key Idea – “Automate This Year’s Job Away” and “It’s Better to fix-it over-selves than blame someone else”
Good Read to understand the over picture of SRE Role and some of the
work Discipline Ideas.
-Rakesh
