Thanksgiving 2023 security incident
On Thanksgiving Day, November 23, 2023, Cloudflare detected a threat actor on our self-hosted Atlassian server. Our security team immediately began an investigation, cut off the threat actor’s access, and on Sunday, November 26, we brought in CrowdStrike’s Forensic team to perform their own independent analysis.
Yesterday, CrowdStrike completed its investigation, and we are publishing this blog post to talk about the details of this security incident.
We want to emphasize to our customers that no Cloudflare customer data or systems were impacted by this event. Because of our access controls, firewall rules, and use of hard security keys enforced using our own Zero Trust tools, the threat actor’s ability to move laterally was limited. No services were implicated, and no changes were made to our global network systems or configuration. This is the promise of a Zero Trust architecture: it’s like bulkheads in a ship where a compromise in one system is limited from compromising the whole organization.
From November 14 to 17, a threat actor did reconnaissance and then accessed our internal wiki (which uses Atlassian Confluence) and our bug database (Atlassian Jira). On November 20 and 21, we saw additional access indicating they may have come back Continue reading
KU047: Back to the Basics: Network Engineering for Platform Engineers
Network engineering is foundational to platform engineering. Michael and Kristina chat with Marino Wijay about tinkering with their home labs to brush up on networking skills and get hands-on practice. The three talk about how in a cloud-based world, it can be easy to forget about the networking nuts and bolts that connect workloads and... Read more »Cadence Sells Custom GPU Supercomputers To Run New CFD Code
If money and time were no object, every workload in every datacenter of the world would have hardware co-designed to optimally run it. …
Cadence Sells Custom GPU Supercomputers To Run New CFD Code was written by Timothy Prickett Morgan at The Next Platform.
Appreciation of automated IX Quarantine LAN testing
Appreciation of automated IX Quarantine LAN testing
Something that bgp.tools (my company) does a great deal is joining internet exchanges.
Dynamic ARP Inspection in DHCP Environment
In ARP Spoofing Attack article, we provided a Python script that an attacker can use […]
The post Dynamic ARP Inspection in DHCP Environment first appeared on Brezular's Blog.
D2C231: Cloud Repatriation: Can Workloads Ever Come Home Again?
Cloud repatriation: Is it a good idea? Guest Marino Wijay, an OSI and networking open source advocate, joins hosts Ethan Banks and Ned Bellavance to discuss the recent interest in cloud repatriation. They cover the intricacies of moving workloads from the cloud back to on-premises or edge environments, and question if it is possible to... Read more »How The “Antares” MI300 GPU Ramp Will Save AMD’s Datacenter Business
It is beginning to look like AMD’s Instinct datacenter GPU accelerator business is going to do a lot better in 2024 than many had expected and that the company’s initial forecasts given back in October anticipated. …
How The “Antares” MI300 GPU Ramp Will Save AMD’s Datacenter Business was written by Timothy Prickett Morgan at The Next Platform.
From Skepticism to Standing Room Only: Liquid Cooling’s Breakout Year
A look back at 2023: The analysts were right. All eyes focused on liquid cooling to meet the greater server densities and higher compute performance of modern data centers.Juniper Networks Announces AI-Native Networking Platform
Bob Friday, Chief AI Officer for Juniper Networks, explains how the advanced technology is transforming operations.LangChain Support for Workers AI, Vectorize and D1
During Developer Week, we announced LangChain support for Cloudflare Workers. Langchain is an open-source framework that allows developers to create powerful AI workflows by combining different models, providers, and plugins using a declarative API — and it dovetails perfectly with Workers for creating full stack, AI-powered applications.
Since then, we’ve been working with the LangChain team on deeper integration of many tools across Cloudflare’s developer platform and are excited to share what we’ve been up to.
Today, we’re announcing five new key integrations with LangChain:
- Workers AI Chat Models: This allows you to use Workers AI text generation to power your chat model within your LangChain.js application.
- Workers AI Instruct Models: This allows you to use Workers AI models fine-tuned for instruct use-cases, such as Mistral and CodeLlama, inside your Langchain.js application.
- Text Embeddings Models: If you’re working with text embeddings, you can now use Workers AI text embeddings with LangChain.js.
- Vectorize Vector Store: When working with a Vector database and LangChain.js, you now have the option of using Vectorize, Cloudflare’s powerful vector database.
- Cloudflare D1-Backed Chat Memory: For longer-term persistence across chat sessions, you can swap out LangChain’s default Continue reading
Precedence of Ansible Extra Variables
I stay as far away from Ansible as possible these days and use it only as a workflow engine to generate device configurations from Jinja2 templates and push them to lab devices. Still, I manage to trigger unexpected behavior even in these simple scenarios.
Ansible has a complex system of variable (fact) precedence, which mostly makes sense considering the dozen places where a variable value might be specified (or overwritten). Ansible documentation also clearly states that the extra variables (specified on the command line with the -e keyword) have the highest precedence.
Now consider these simple playbooks. In the first one, we’ll set a fact (variable) and then print it out:
Precedence of Ansible Extra Variables
I stay as far away from Ansible as possible these days and use it only as a workflow engine to generate device configurations from Jinja2 templates and push them to lab devices. Still, I manage to trigger unexpected behavior even in these simple scenarios.
Ansible has a complex system of variable (fact) precedence, which mostly makes sense considering the dozen places where a variable value might be specified (or overwritten). Ansible documentation also clearly states that the extra variables (specified on the command line with the -e keyword) have the highest precedence.
Now consider these simple playbooks. In the first one, we’ll set a fact (variable) and then print it out:
NX-OS Forwarding Constructs For VXLAN/EVPN
In this post we will look at the forwarding constructs in NX-OS in the context of VXLAN and EVPN. Having knowledge of the forwarding constructs helps both with understanding of the protocols, but also to assist in troubleshooting. BRKDCN-3040 from Cisco Live has a nice overview of the components involved:
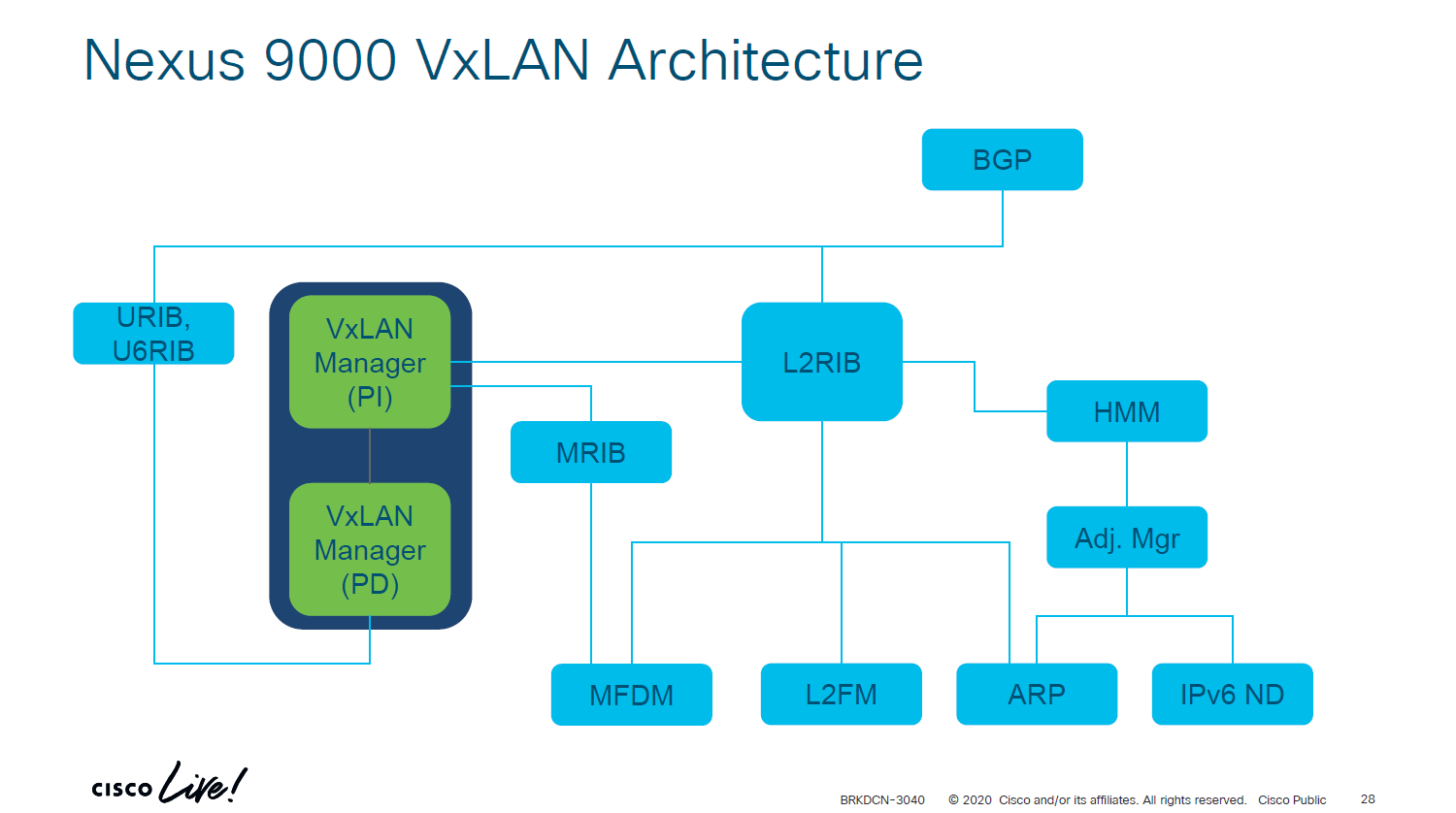
There are components that are platform independent (PI) and platform dependent (PD). Below I’ll explain what each component does:
- ARP – Information from ARP requests/responses is needed to build adjacencies. The information learned from ARP is used to populate IP address field in RT2 and hence also to populate the ARP suppression cache.
- IPv6 ND – ND fills the role of ARP, but for IPv6.
- Adjacency Manager – Resolves directly attached hosts MAC addresses.
- Host Mobility Manager – Tracks the endpoints and their movements.
- L2FM – The Layer2 Forwarding Manager. A platform dependent component that programs ASICs for L2 forwarding. Keeps track of MAC addresses, their placement and moves, and synchronizes this information across ASICS, line cards, and vPC peers when vPC is in use.
- MFDM – Multicast Forwarding Database Manager. A platform dependent component that programs ASICs with information to perform multicast forwarding.
- L2RIB – The component that handles Continue reading
NetFlow data and its fields vs packet capture
The post NetFlow data and its fields vs packet capture appeared first on Noction.
Hull and cabin
When it comes to working with steel it is a bit outside my comfort zone so I got the professionals in to do the blacking of the hull and a few different things to the cabin shell.
Supermicro Racks Up The AI Servers And Rakes In The Big Bucks
It was only six months ago when we were talking about how system maker Supermicro was breaking through a $10 billion annual revenue run rate and was setting its sights on a $20 billion target. …
Supermicro Racks Up The AI Servers And Rakes In The Big Bucks was written by Timothy Prickett Morgan at The Next Platform.
ICANN Launches 10-Year, $200 Million Program to Expand and Protect Internet Ecosystem
The grant program will support the next phase of global Internet growth and will emphasize digital inclusivity.BGP Labs: Override Neighbor AS Number in AS Path
When I described the need to turn off the BGP AS-path loop prevention logic in scenarios where a Service Provider expects a customer to reuse the same AS number across multiple sites, someone quipped, “but that should be fixed by the Service Provider, not offloaded to the customer.”
Not surprisingly, there’s a nerd knob for that (AS override), and you can practice it in the next BGP lab exercise: Fix AS-Path in Environments Reusing BGP AS Numbers.
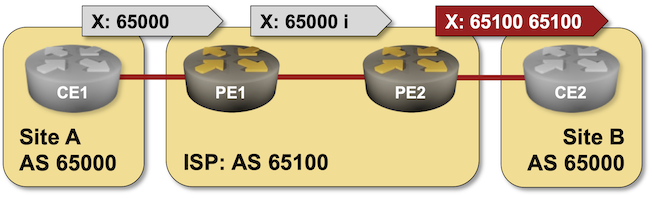
BGP Labs: Override Neighbor AS Number in AS Path
When I described the need to turn off the BGP AS-path loop prevention logic in scenarios where a Service Provider expects a customer to reuse the same AS number across multiple sites, someone quipped, “but that should be fixed by the Service Provider, not offloaded to the customer.”
Not surprisingly, there’s a nerd knob for that (AS override), and you can practice it in the next BGP lab exercise: Fix AS-Path in Environments Reusing BGP AS Numbers.